Esercitazione: Eseguire il training di un modello di classificazione senza codice AutoML in studio di Azure Machine Learning
Questa esercitazione illustra come eseguire il training di un modello di classificazione senza codice automatizzato (Machine Learning) con Azure Machine Learning nel studio di Azure Machine Learning. Questo modello di classificazione stima se un cliente sottoscrive un deposito a termine fisso con un istituto finanziario.
Con Machine Learning automatizzato, è possibile automatizzare le attività a elevato utilizzo di tempo. L'apprendimento automatico automatizzato esegue rapidamente l'iterazione su numerose combinazioni di algoritmi e iperparametri per aiutare a trovare il modello migliore in base a una metrica di riuscita di propria scelta.
Non si scrive codice in questa esercitazione. Usare l'interfaccia studio per eseguire il training. Si apprenderà come eseguire le attività seguenti:
- Creazione di un'area di lavoro di Azure Machine Learning
- Eseguire un esperimento di Machine Learning automatizzato
- Esplorare i dettagli del modello
- Distribuire il modello consigliato
Prerequisiti
Una sottoscrizione di Azure. Se non hai una sottoscrizione di Azure, crea un account gratuito.
Scaricare il file di dati bankmarketing_train.csv. La colonna y indica se un cliente ha effettuato la sottoscrizione di un deposito a termine fisso, che in seguito viene identificata come colonna di destinazione per le stime in questa esercitazione.
Nota
Questo set di dati di marketing bancario viene reso disponibile in Licenza Creative Commons (CCO: Public Domain). Tutti i diritti per i singoli contenuti del database vengono concessi in licenza ai sensi della licenza relativa ai contenuti del database e resi disponibili in Kaggle. Questo set di dati era originariamente disponibile all'interno del database di Machine Learning UCI.
[Moro et al., 2014] S. Moro, P. Cortez e P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, giugno 2014.
Creare un'area di lavoro
Un'area di lavoro di Machine Learning è una risorsa cloud fondamentale usata per eseguire gli esperimenti, il training e la distribuzione di modelli di Machine Learning. Collega la sottoscrizione e il gruppo di risorse di Azure a un oggetto di facile utilizzo nel servizio.
Completare i passaggi seguenti per creare un'area di lavoro e continuare l'esercitazione.
Accedere ad Azure Machine Learning Studio.
Selezionare Crea area di lavoro.
Specificare le informazioni seguenti per configurare la nuova area di lavoro:
Campo Descrizione Nome dell'area di lavoro Immettere un nome univoco che identifichi l'area di lavoro. I nomi devono essere univoci all'interno del gruppo di risorse. Usare un nome facile da ricordare e da distinguere dai nomi delle aree di lavoro create da altri utenti. Il nome dell'area di lavoro non rileva la distinzione tra maiuscole e minuscole. Abbonamento Seleziona la sottoscrizione di Azure da usare. Gruppo di risorse Usare un gruppo di risorse esistente nella sottoscrizione oppure immettere un nome per creare un nuovo gruppo di risorse. Un gruppo di risorse include risorse correlate per una soluzione Azure. Per usare un gruppo di risorse esistente, è necessario avere il ruolo di collaboratore o proprietario. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning. Paese Selezionare l'area di Azure più vicina agli utenti e alle risorse di dati in cui creare l'area di lavoro. Selezionare Crea per creare l'area di lavoro.
Per altre informazioni sulle risorse di Azure, vedere Creare l'area di lavoro.
Per altri modi di creare un'area di lavoro in Azure, vedere Gestire le aree di lavoro di Azure Machine Learning nel portale o con Python SDK (v2).
Creare un processo di Machine Learning automatizzato
Completare la procedura di configurazione ed esecuzione dell'esperimento seguente usando il studio di Azure Machine Learning in https://ml.azure.com. Machine Learning Studio è un'interfaccia Web consolidata che include strumenti di Machine Learning per eseguire scenari di data science per professionisti di data science di tutti i livelli di competenza. Lo studio non è supportato nei browser Internet Explorer.
Selezionare la sottoscrizione e l'area di lavoro create.
Nel riquadro di spostamento selezionare Creazione di>Machine Learning automatizzato.
Poiché questa esercitazione è il primo esperimento di Machine Learning automatizzato, viene visualizzato un elenco vuoto e collegamenti alla documentazione.
Selezionare Nuovo processo di Machine Learning automatizzato.
In Metodo di training selezionare Train automatically (Esegui training automaticamente) e quindi selezionare Start configuring job (Avvia configurazione processo).
In Impostazioni di base selezionare Crea nuovo, quindi per Nome esperimento immettere my-1st-automl-experiment.
Selezionare Avanti per caricare il set di dati.

Creare e caricare un set di dati come asset di dati
Prima di configurare l'esperimento, caricare il file di dati nell'area di lavoro sotto forma di asset di dati di Azure Machine Learning. Per questa esercitazione, è possibile considerare un asset di dati come set di dati per il processo di Machine Learning automatizzato. In questo modo è possibile assicurarsi che i dati siano formattati in modo appropriato per l'esperimento.
In Tipo di attività e dati scegliere Classificazione per Selezionare il tipo di attività.
In Seleziona dati scegliere Crea.
Nel modulo Tipo di dati assegnare un nome all'asset di dati e fornire una descrizione facoltativa.
In Tipo selezionare Tabulare. L'interfaccia di Machine Learning automatizzato supporta attualmente solo tabularDataset.
Selezionare Avanti.
Nel modulo Origine dati selezionare Da file locali. Selezionare Avanti.
In Tipo di archiviazione di destinazione selezionare l'archivio dati predefinito configurato automaticamente durante la creazione dell'area di lavoro: workspaceblobstore. Caricare il file di dati in questo percorso per renderlo disponibile per l'area di lavoro.
Selezionare Avanti.
Nella selezione File o cartella selezionare Carica file o cartella>Carica file.
Scegliere il file bankmarketing_train.csv nel computer locale. Il file è stato scaricato come prerequisito.
Selezionare Avanti.
Al termine del caricamento, l'area Anteprima dati viene popolata in base al tipo di file.
Nel modulo Impostazioni esaminare i valori per i dati. Quindi seleziona Avanti.
Campo Descrizione Valore per l'esercitazione File format Definisce il layout e il tipo di dati archiviati in un file. delimitato Delimitatore Uno o più caratteri per specificare il limite tra aree distinte indipendenti in testo normale o altri flussi di dati. Virgola Codifica Identifica la tabella dello schema bit-carattere da usare per leggere il set di dati. UTF-8 Intestazioni di colonna Indica come verranno considerate le intestazioni del set di dati, se presenti. Tutti i file hanno le stesse intestazioni Ignora righe Indica quante righe vengono eventualmente ignorate nel set di dati. None Il modulo Schema consente di configurare ulteriormente i dati per questo esperimento. Per questo esempio, selezionare l'interruttore relativo a day_of_week in modo da non includerlo. Selezionare Avanti.
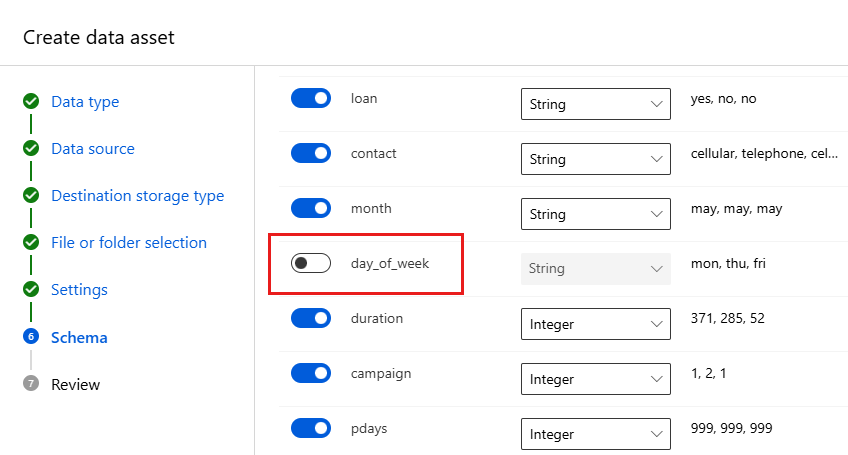
Nel modulo Rivedi verificare le informazioni e quindi selezionare Crea.
Selezionare il set di dati dall'elenco.
Esaminare i dati selezionando l'asset di dati e esaminando la scheda di anteprima . Assicurarsi che non includa day_of_week e selezionare Chiudi.
Selezionare Avanti per passare alle impostazioni dell'attività.
Configurazione del processo
Dopo aver caricato e configurato i dati, è possibile configurare l'esperimento. Questa configurazione include attività di progettazione dell'esperimento, ad esempio la selezione delle dimensioni dell'ambiente di calcolo e la specifica della colonna da stimare.
Popolare il modulo Impostazioni attività come indicato di seguito:
Selezionare y (Stringa) come colonna di destinazione, ovvero ciò che si vuole stimare. Questa colonna indica se il client ha sottoscritto o meno un deposito a termine.
Selezionare View additional configuration settings (Visualizza altre impostazioni di configurazione) e popolare i campi come indicato di seguito. Queste impostazioni consentono un maggior controllo del processo di training. Altrimenti, vengono applicate le impostazioni predefinite in base alla selezione dell'esperimento e ai dati.
Configurazioni aggiuntive Descrizione Valore per l'esercitazione Primary metric (Metrica principale) Metrica di valutazione usata per misurare l'algoritmo di Machine Learning. AUCWeighted Modello esplicativo migliore Mostra automaticamente il modello esplicativo migliore creato da ML automatizzato. Abilitare Modelli bloccati Algoritmi da escludere dal processo di training None Seleziona Salva.
In Convalida e test:
- In Tipo di convalida selezionare k-fold cross-validation.
- In Numero di convalide incrociate selezionare 2.
Selezionare Avanti.
Selezionare Cluster di elaborazione come tipo di risorsa di calcolo.
Una destinazione di calcolo è un ambiente di risorse locale o basato sul cloud usato per eseguire lo script di training o per ospitare la distribuzione del servizio. Per questo esperimento, è possibile provare un ambiente di elaborazione serverless basato sul cloud (anteprima) o creare un ambiente di elaborazione basato sul cloud personalizzato.
Nota
Per usare il calcolo serverless, abilitare la funzionalità di anteprima, selezionare Serverless e ignorare questa procedura.
Per creare una destinazione di calcolo personalizzata, in Selezionare il tipo di calcolo selezionare Cluster di calcolo per configurare la destinazione di calcolo.
Popolare il modulo Macchina virtuale per configurare l'ambiente di calcolo. Selezionare Nuovo.
Campo Descrizione Valore per l'esercitazione Ufficio Area da cui si vuole eseguire il computer West US 2 Livello macchina virtuale Selezionare la priorità dell'esperimento Dedicato Tipo di macchina virtuale Selezionare il tipo di macchina virtuale per il contesto di calcolo. CPU (Central Processing Unit) Dimensioni della macchina virtuale Selezionare le dimensioni della macchina virtuale per il contesto di calcolo. È disponibile un elenco di dimensioni consigliate in base al tipo di dati e di esperimento. Standard_DS12_V2 Selezionare Avanti per passare al modulo Impostazioni avanzate.
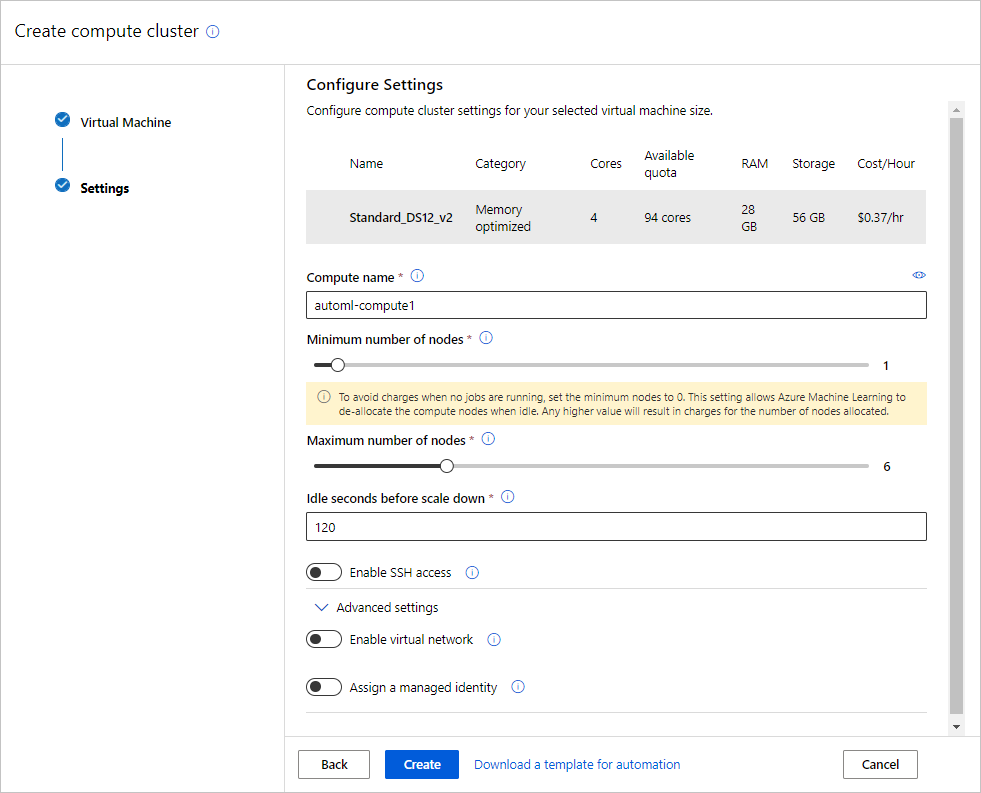
Campo Descrizione Valore per l'esercitazione Nome del calcolo Un nome univoco che identifica il contesto di calcolo. automl-compute Nodi min/max Per profilare i dati, è necessario specificare almeno un nodo. Numero minimo di nodi: 1
Numero massimo di nodi: 6Secondi di inattività prima della riduzione Tempo di inattività prima che il cluster venga ridotto automaticamente al numero minimo di nodi. 120 (impostazione predefinita) Impostazioni avanzate Impostazioni per la configurazione e l'autorizzazione di una rete virtuale per l'esperimento. None Seleziona Crea.
Il completamento della creazione di un ambiente di calcolo può richiedere alcuni minuti.
Dopo la creazione, selezionare la nuova destinazione di calcolo dall'elenco. Selezionare Avanti.
Selezionare Invia processo di training per eseguire l'esperimento. La schermata Panoramica viene visualizzata con lo stato nella parte superiore quando inizia la preparazione dell'esperimento. Questo stato viene aggiornato man mano che l'esperimento procede. Le notifiche vengono visualizzate anche in studio per informare l'utente dello stato dell'esperimento.

Importante
La preparazione dell'esecuzione dell'esperimento richiede 10-15 minuti. Dopo l'avvio, ogni iterazione richiede almeno 2-3 minuti.
In produzione, è probabile che nell'attesa ci si allontani. Per questa esercitazione, tuttavia, è possibile iniziare a esplorare gli algoritmi testati nella scheda Modelli man mano che vengono completati mentre gli altri continuano a essere eseguiti.
Esplorare i modelli
Passare alla scheda Modelli e processi figlio per visualizzare gli algoritmi (modelli) testati. Per impostazione predefinita, il processo ordina i modelli in base al punteggio della metrica al termine. Per questa esercitazione, il modello con il punteggio più alto in base alla metrica AUCWeighted scelta si trova nella parte superiore dell'elenco.
Mentre si aspetta il completamento di tutti i modelli dell'esperimento, selezionare il nome di algoritmo di un modello completato per esplorare i dettagli delle relative prestazioni. Selezionare le schede Panoramica e Metriche per informazioni sul processo.
L'animazione seguente visualizza le proprietà, le metriche e i grafici delle prestazioni del modello selezionati.

Visualizzare le spiegazioni del modello
Mentre si attende il completamento dei modelli, è anche possibile esaminare le spiegazioni del modello e vedere quali funzionalità dei dati (non elaborate o progettate) hanno influenzato le stime di un determinato modello.
Queste spiegazioni del modello possono essere generate su richiesta. Il dashboard delle spiegazioni del modello che fa parte della scheda Spiegazioni (anteprima) riepiloga queste spiegazioni.
Per generare spiegazioni del modello:
Nei collegamenti di spostamento nella parte superiore della pagina selezionare il nome del processo da tornare alla schermata Modelli .
Selezionare la scheda Modelli e processi figlio.
Per questa esercitazione selezionare il primo modello MaxAbsScaler, LightGBM.
Selezionare Spiega modello. A destra viene visualizzato il riquadro Spiegare il modello.
Selezionare il tipo di calcolo e quindi selezionare l'istanza o il cluster automl-compute creato in precedenza. Questo calcolo avvia un processo figlio per generare le spiegazioni del modello.
Seleziona Crea. Viene visualizzato un messaggio verde di operazione riuscita.
Nota
Il completamento del processo di spiegazione richiede circa 2-5 minuti.
Selezionare Spiegazioni (anteprima). Questa scheda viene popolata al termine dell'esecuzione della spiegazione.
A sinistra espandere il riquadro. In Funzionalità selezionare la riga non elaborata.
Selezionare la scheda Aggregare l'importanza della funzionalità. Questo grafico mostra le caratteristiche dei dati che hanno influenzato le stime del modello selezionato.
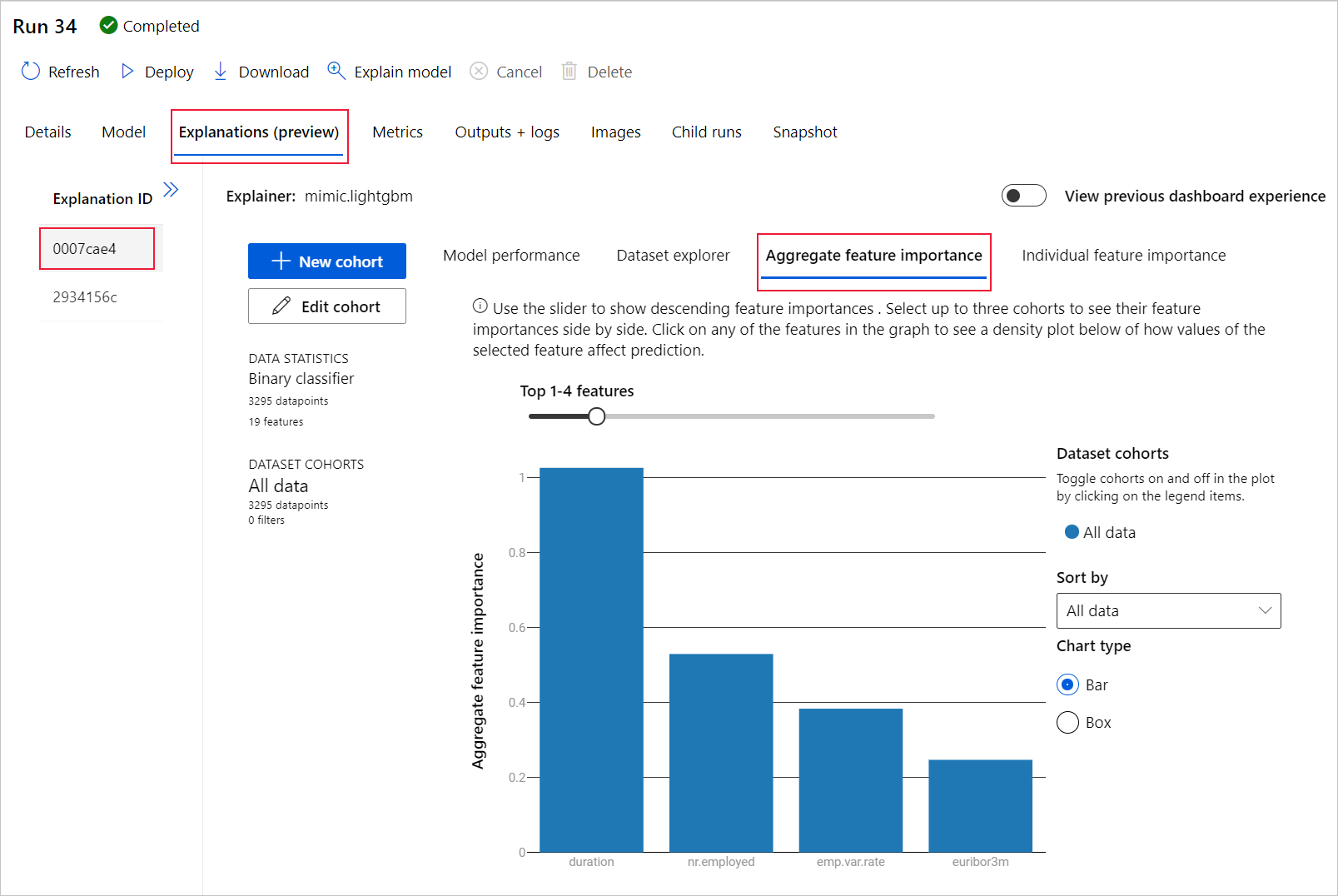
In questo esempio, la durata sembra avere la maggiore influenza sulle stime di questo modello.

Distribuire il modello migliore
L'interfaccia di Machine Learning automatizzato consente di distribuire il modello migliore come servizio Web. La distribuzione è l'integrazione del modello in modo che possa prevedere nuovi dati e identificare potenziali aree di opportunità. Per questo esperimento, attraverso la distribuzione a un servizio Web l'istituto finanziario ha ora una soluzione Web iterativa e scalabile per l'identificazione dei potenziali clienti con deposito a termine fisso.
Verificare se l'esecuzione dell'esperimento è stata completata. A tale scopo, tornare alla pagina del processo padre selezionando il nome del processo nella parte superiore della schermata. Viene visualizzato lo stato Completato nella parte superiore sinistra della schermata.
Al termine dell'esecuzione dell'esperimento, la pagina Dettagli viene popolata con una sezione Riepilogo modello migliore. In questo contesto dell'esperimento VotingEnsemble è considerato il modello migliore, in base alla metrica AUCWeighted .
Distribuire questo modello. Il completamento della distribuzione richiede circa 20 minuti. Il processo di distribuzione comporta diversi passaggi, tra cui la registrazione del modello, la generazione delle risorse e la relativa configurazione per il servizio Web.
Selezionare VotingEnsemble per aprire la pagina specifica del modello.
Selezionare Distribuisci>servizio Web.
Immettere i dati nel riquadro Deploy a model (Distribuisci un modello) in questo modo:
Campo Valore Nome my-automl-deploy Descrizione Distribuzione del primo esperimento automatizzato di apprendimento automatico Tipo di calcolo Selezionare Istanza di Azure Container Abilita autenticazione Disabilita. Usa asset di distribuzione personalizzati Disabilita. Consente di generare automaticamente il file di driver predefinito (script di assegnazione dei punteggi) e il file dell'ambiente. Per questo esempio, usare le impostazioni predefinite specificate nel menu Avanzate .
Seleziona Distribuisci.
Nella parte superiore della schermata Processo viene visualizzato un messaggio verde di operazione riuscita. Nel riquadro Riepilogo modello viene visualizzato un messaggio di stato in Stato distribuzione. Selezionare a intervalli regolari Aggiorna per controllare lo stato della distribuzione.
È disponibile un servizio Web operativo per generare stime.
Passare al contenuto correlato per altre informazioni su come usare il nuovo servizio Web e testare le stime usando il supporto predefinito di Power BI in Azure Machine Learning.
Pulire le risorse
I file di distribuzione sono più grandi dei file di dati e di esperimento e di conseguenza più costosi da archiviare. Per mantenere l'area di lavoro e i file di esperimento, eliminare solo i file di distribuzione per ridurre al minimo i costi per l'account. Se non si prevede di usare alcun file, eliminare l'intero gruppo di risorse.
Eliminare l'istanza di distribuzione
Eliminare solo l'istanza di distribuzione da Azure Machine Learning all'indirizzo https://ml.azure.com/.
Passare ad Azure Machine Learning. Passare all'area di lavoro e nel riquadro Asset selezionare Endpoint.
Selezionare la distribuzione che si vuole eliminare e scegliere Elimina.
Selezionare Continua.
Eliminare il gruppo di risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se le risorse create non servono più, eliminarle per evitare addebiti:
Nella casella di ricerca della portale di Azure immettere Gruppi di risorse e selezionarlo nei risultati.
Nell'elenco selezionare il gruppo di risorse creato.
Nella pagina Panoramica selezionare Elimina gruppo di risorse.
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.
Contenuto correlato
In questa esercitazione di Machine Learning automatizzato è stata usata l'interfaccia di ML automatizzato di Azure Machine Learning per creare e distribuire un modello di classificazione. Per altre informazioni e i passaggi successivi, vedere queste risorse:
- Funzionalità automatizzate di Machine Learning.
- Informazioni sulle metriche e i grafici di classificazione: articolo Valutare i risultati dell'esperimento di Machine Learning automatizzato.
- Altre informazioni su come configurare AutoML per NLP.
Provare Machine Learning automatizzato anche per questi altri tipi di modello:
- Per un esempio di previsione senza codice, vedere Esercitazione: Previsione della domanda con Machine Learning automatizzato senza codice nella studio di Azure Machine Learning.
- Per un esempio code-first di un modello di rilevamento oggetti, vedere l'Esercitazione: Eseguire il training di un modello di rilevamento oggetti con AutoML e Python.