Rilevanza nella ricerca con parole chiave (punteggio BM25)
Questo articolo illustra l'algoritmo di assegnazione dei punteggi per pertinenza BM25 usato per calcolare i punteggi di ricerca per la ricerca full-text. La pertinenza di BM25 è esclusiva per la ricerca full-text. Le query di filtro, il completamento automatico e le query suggerite, la ricerca con caratteri jolly o le query di ricerca fuzzy non vengono segnate o classificate per pertinenza.
Algoritmi di assegnazione dei punteggi usati nella ricerca full-text
Ricerca di intelligenza artificiale di Azure offre gli algoritmi di assegnazione dei punteggi seguenti per la ricerca full-text:
| Algoritmo | Utilizzo | Intervallo |
|---|---|---|
BM25Similarity |
Correzione dell'algoritmo in tutti i servizi di ricerca creati dopo luglio 2020. È possibile configurare questo algoritmo, ma non è possibile passare a una versione precedente (classica). | Illimitato. |
ClassicSimilarity |
Presente nei servizi di ricerca meno recenti. È possibile acconsentire esplicitamente a BM25 e scegliere un algoritmo per indice. | 0 < 1.00 |
Sia BM25 che Classic sono funzioni di recupero simili a TF-IDF che usano la frequenza dei termini (TF) e la frequenza dei documenti inversa (IDF) come variabili per calcolare i punteggi di pertinenza per ogni coppia di query di documenti, che viene quindi usata per i risultati di classificazione. Sebbene concettualmente simile al classico, il BM25 è radicato nel recupero di informazioni probabilistiche che produce corrispondenze più intuitive, come misurato dalla ricerca degli utenti.
BM25 offre opzioni di personalizzazione avanzate, ad esempio consentendo all'utente di decidere in che modo il punteggio di pertinenza viene ridimensionato con la frequenza del termine dei termini corrispondenti. Per altre informazioni, vedere Configurare l'algoritmo di assegnazione dei punteggi.
Nota
Se si usa un servizio di ricerca creato prima di luglio 2020, l'algoritmo di assegnazione dei punteggi è probabilmente l'impostazione predefinita precedente, ClassicSimilarity, che è possibile aggiornare in base all'indice. Per informazioni dettagliate, vedere Abilitare il punteggio BM25 nei servizi meno recenti.
Il segmento video seguente inoltra rapidamente a una spiegazione degli algoritmi di classificazione disponibili a livello generale usati in Ricerca di intelligenza artificiale di Azure. È possibile guardare il video completo per informazioni più dettagliate.
Funzionamento della classificazione BM25
Il punteggio di pertinenza si riferisce al calcolo di un punteggio di ricerca (@search.score) che funge da indicatore della pertinenza di un elemento nel contesto della query corrente. L'intervallo non è associato. Tuttavia, più alto è il punteggio, più rilevante è l'elemento.
Il punteggio di ricerca viene calcolato in base alle proprietà statistiche dell'input della stringa e alla query stessa. Ricerca di intelligenza artificiale di Azure trova documenti che corrispondono ai termini di ricerca (alcuni o tutti, in base a searchMode), preferendo i documenti che includono molte istanze del termine di ricerca. Il punteggio di ricerca aumenta ancora di più se il termine risulta raro nell'indice di dati, ma comune all'interno del documento. La base di questo approccio al calcolo della rilevanza è nota come TF-IDF (Term Frequency-Inverse Document Frequency).
I punteggi di ricerca possono essere ripetuti in un set di risultati. Quando più occorrenze hanno lo stesso punteggio di ricerca, l'ordine degli stessi elementi con punteggio non è definito e non è quindi stabile. Eseguire di nuovo la query. È possibile che la posizione degli elementi cambi, soprattutto se si usa il servizio gratuito o un servizio fatturabile con più repliche. Se due elementi hanno punteggio identico, non vi è alcuna garanzia su quale elemento verrà visualizzato per primo.
Per interrompere il legame tra i punteggi ripetuti, è possibile aggiungere una clausola $orderby al primo ordine per punteggio, quindi eseguire l'ordinamento in base a un altro campo ordinabile, ad esempio $orderby=search.score() desc,Rating desc. Per altre informazioni, vedere $orderby.
Per la ricerca e l’assegnazione dei punteggi vengono usati solo i campi contrassegnati come searchable nell'indice o come searchFields nella query. Nei risultati della ricerca vengono restituiti solo i campi contrassegnati come retrievable o specificati in select nella query insieme al punteggio di ricerca.
Nota
Un elemento @search.score = 1 indica un set di risultati senza punteggio o non classificato. Il punteggio è uniforme in tutti i risultati. I risultati senza punteggio si verificano quando il modulo di query è una ricerca fuzzy, query con caratteri jolly o regex o una ricerca vuota (search=*, talvolta abbinata ai filtri, dove il filtro è il mezzo principale per la restituzione di una corrispondenza).
Punteggi in un risultato di testo
In ogni classificazione dei risultati la proprietà @search.score contiene il valore utilizzato per ordinare i risultati.
La tabella seguente identifica la proprietà di assegnazione dei punteggi restituita per ogni corrispondenza, algoritmo e intervallo.
| Metodo di ricerca | Parametro | Algoritmo di assegnazione dei punteggi | Intervallo |
|---|---|---|---|
| ricerca full-text | @search.score |
Algoritmo BM25, che utilizza i parametri specificati nell'indice. | Illimitato. |
Variazione punteggio
I punteggi di ricerca trasmettono il senso generale della pertinenza, riflettendo la forza della corrispondenza rispetto ad altri documenti nello stesso set di risultati. Tuttavia, i punteggi non sono sempre coerenti da una query alla successiva, quindi quando si lavora con le query, è possibile notare delle piccole discrepanze nella modalità di ordinamento dei documenti di ricerca. Esistono diverse spiegazioni per il motivo per cui questo problema può verificarsi.
| Causa | Descrizione |
|---|---|
| Punteggi identici | Se più documenti hanno lo stesso punteggio, è possibile che uno di essi venga visualizzato per primo. |
| Volatilità dei dati | Il contenuto dell'indice varia in base all'aggiunta, alla modifica o all'eliminazione di documenti. Le frequenze dei termini cambieranno man mano che gli aggiornamenti degli indici vengono elaborati nel tempo, con effetti sui punteggi di ricerca dei documenti corrispondenti. |
| Più repliche | Per i servizi che usano più repliche, le query vengono eseguite su ogni replica in parallelo. Le statistiche di indice usate per calcolare un punteggio di ricerca vengono calcolate in base alla replica, con risultati uniti e ordinati nella risposta della query. Le repliche sono principalmente mirror l'una dell'altra, ma le statistiche possono differire a causa di piccole differenze nello stato. Ad esempio, una replica potrebbe aver eliminato dei documenti che contribuiscono alle statistiche, che sono stati uniti da altre repliche. In genere, le differenze nelle statistiche per replica sono più evidenti negli indici più piccoli. Nella sezione seguente vengono fornite altre informazioni su questa condizione. |
Effetti di partizionamento orizzontale sui risultati della query
Una partizione è un blocco di un indice. Ricerca di intelligenza artificiale di Azure suddivide un indice in partizioni per velocizzare il processo di aggiunta di partizioni (spostando le partizioni in nuove unità di ricerca). In un servizio di ricerca, la gestione delle partizioni è un dettaglio di implementazione e non configurabile, ma sapendo che un indice è partizionato consente di comprendere le anomalie occasionali nei comportamenti di classificazione e completamento automatico:
Anomalie di classificazione: i punteggi di ricerca vengono calcolati prima a livello di partizione e quindi aggregati in un singolo set di risultati. A seconda delle caratteristiche del contenuto della partizione, le corrispondenze di una partizione potrebbero essere classificate più in alto rispetto alle corrispondenze in un'altra. Se si notano classificazioni intuitive dei contatori nei risultati della ricerca, è probabilmente dovuto agli effetti del partizionamento orizzontale, soprattutto se gli indici sono di piccole dimensioni. È possibile evitare queste anomalie di classificazione scegliendo di calcolare i punteggi a livello globale nell'intero indice, ma in questo modo si verifica una riduzione delle prestazioni.
Anomalie di completamento automatico: le query di completamento automatico, in cui le corrispondenze vengono eseguite sui primi caratteri di un termine parzialmente immesso, accettano un parametro fuzzy che perdona piccole deviazioni nell'ortografia. Per il completamento automatico, la corrispondenza fuzzy è vincolata ai termini all'interno della partizione corrente. Ad esempio, se una partizione contiene "Microsoft" e viene immesso un termine parziale di "micro", il motore di ricerca corrisponderà a "Microsoft" in tale partizione, ma non in altre partizioni che contengono le parti rimanenti dell'indice.
Il diagramma seguente illustra la relazione tra repliche, partizioni, partizioni e unità di ricerca. Mostra un esempio di come un singolo indice viene esteso tra quattro unità di ricerca in un servizio con due repliche e due partizioni. Ognuna delle quattro unità di ricerca archivia solo la metà delle partizioni dell'indice. Le unità di ricerca nella colonna sinistra archiviano la prima metà delle partizioni, che comprendono la prima partizione, mentre quelle nella colonna destra archiviano la seconda metà delle partizioni, che comprendono la seconda partizione. Poiché sono presenti due repliche, sono presenti due copie di ogni partizione di indice. Le unità di ricerca nella riga superiore archiviano una copia, che comprende la prima replica, mentre quelle nella riga inferiore archiviano un'altra copia, che comprende la seconda replica.
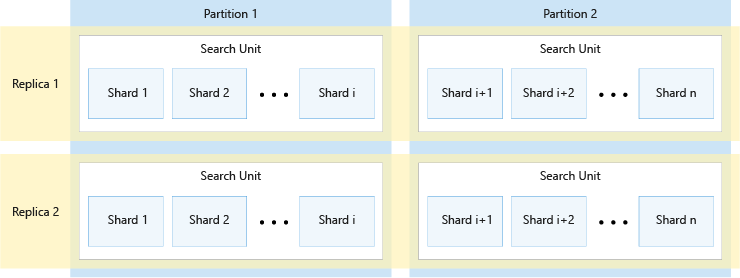
Il diagramma precedente è solo un esempio. Sono possibili molte combinazioni di partizioni e repliche, fino a un massimo di 36 unità di ricerca totali.
Nota
Il numero di repliche e partizioni divide equamente per 12 (in particolare 1, 2, 3, 4, 6, 12). Ricerca di intelligenza artificiale di Azure divide ogni indice in 12 partizioni in modo che possa essere distribuito in parti uguali in tutte le partizioni. Ad esempio, se il servizio ha tre partizioni e si crea un indice, ogni partizione conterrà quattro partizioni dell'indice. Il modo in cui Ricerca di intelligenza artificiale di Azure suddivide un indice in partizioni è un dettaglio di implementazione ed è soggetto a modifiche nelle versioni successive. Sebbene il numero attualmente sia 12, tale numero potrebbe non essere 12 in futuro.
Statistiche di punteggio e sessioni permanenti
Ai fini della scalabilità, Ricerca di intelligenza artificiale di Azure distribuisce ogni indice orizzontalmente tramite un processo di partizionamento orizzontale, il che significa che le parti di un indice sono fisicamente separate.
Per impostazione predefinita, il punteggio di un documento viene calcolato in base alle proprietà statistiche dei dati all'interno di una partizione. Questo approccio in genere non rappresenta un problema per un set di dati di grandi dimensioni e offre prestazioni migliori rispetto ai casi in cui è necessario calcolare il punteggio in base alle informazioni su tutte le partizioni. Ciò premesso, usando questa ottimizzazione delle prestazioni è possibile che due documenti molto simili (o addirittura identici) abbiano punteggi della rilevanza diversi qualora si trovino in partizioni diverse.
Se si preferisce calcolare il punteggio in base alle proprietà statistiche in tutte le partizioni, è possibile farlo aggiungendo scoringStatistics=global come parametro di query (o aggiungendo "scoringStatistics": "global" come parametro corpo della richiesta di query).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
L'uso di scoringStatistics garantirà che tutte le partizioni nella stessa replica restituiscano gli stessi risultati. Detto questo, le varie repliche possono essere leggermente diverse l'una dall'altra perché vengono sempre aggiornate in base alle ultime modifiche apportate all'indice. In alcuni scenari potrebbe essere necessario che gli utenti ottengano risultati più coerenti durante una "sessione di query". In tal caso, è possibile fornire un elemento sessionId come parte delle query. Tale elemento sessionId è una stringa univoca creata per fare riferimento a una sessione utente univoca.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Purché venga usato lo stesso elemento sessionId, viene eseguito un tentativo di ricerca per la stessa replica, aumentando la coerenza dei risultati che verranno visualizzati dagli utenti.
Nota
Il riutilizzo ripetuto degli stessi valori sessionId può interferire con il bilanciamento del carico delle richieste tra le repliche e influire negativamente sulle prestazioni del servizio di ricerca. Il valore usato come sessionId non può iniziare con un carattere '_'.
Ottimizzazione della pertinenza
In Ricerca di intelligenza artificiale di Azure è possibile configurare i parametri dell'algoritmo BM25 e ottimizzare la pertinenza della ricerca e migliorare i punteggi di ricerca tramite questi meccanismi:
| Approccio | Implementazione | Descrizione |
|---|---|---|
| Configurazione dell'algoritmo di assegnazione dei punteggi | Indice di ricerca | |
| Profili di punteggio | Indice di ricerca | Specificare i criteri per aumentare il punteggio di ricerca di una corrispondenza in base alle caratteristiche del contenuto. Ad esempio, è possibile aumentare la corrispondenze in base al rispettivo potenziale di profitto, alzare di livello elementi più recenti o evidenziare elementi che sono rimasti troppo a lungo in magazzino. Un profilo di punteggio fa parte della definizione dell'indice, costituita da campi ponderati, funzioni e parametri. È possibile aggiornare un indice esistente con modifiche al profilo di punteggio, senza incorrere in una ricompilazione dell'indice. |
| Classificazione semantica | Richiesta di query | Applica la comprensione della lettura automatica ai risultati della ricerca, promuovendo risultati più pertinenti semanticamente all'inizio. |
| Parametro featuresMode | Richiesta di query | Questo parametro viene usato principalmente per decomprimere un punteggio BM25 classificato, ma può essere usato per nel codice che fornisce una soluzione di assegnazione dei punteggi personalizzata. |
parametro featuresMode (anteprima)
Le richieste di ricerca documenti supportano un parametro featuresMode che fornisce maggiori dettagli su un punteggio di pertinenza BM25 a livello di campo. Mentre viene effettuato il calcolo di @searchScore per il documento all-up (quanto è pertinente questo documento nel contesto di questa query), featuresMode rivela informazioni sui singoli campi, come espresso in una struttura @search.features. La struttura contiene tutti i campi utilizzati nella query (campi specifici tramite searchFields in una query o tutti i campi attribuiti come ricercabili in un indice).
Per ogni campo, @search.features forniscono i valori seguenti:
- Numero di token univoci trovati nel campo
- Punteggio di somiglianza o misura della somiglianza del contenuto del campo, rispetto al termine della query
- Frequenza dei termini, o numero di volte in cui il termine di query è stato trovato nel campo
Per una query destinata ai campi "descrizione" e "titolo", una risposta che include @search.features potrebbe essere simile alla seguente:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
È possibile utilizzare questi punti dati nelle soluzioni di assegnazione dei punteggi personalizzate o usare le informazioni per eseguire il debug dei problemi di pertinenza della ricerca.
Il parametro featuresMode non è documentato nelle API REST, ma è possibile usarlo in una chiamata dell'API REST di anteprima alla ricerca di testo (parola chiave) nei documenti classificati come BM25.
Numero di risultati classificati in una risposta di query full-text
Per impostazione predefinita, se non si usa la paginazione, il motore di ricerca restituisce le prime 50 corrispondenze di classificazione più alte per la ricerca full-text. È possibile usare il parametro top per restituire un numero minore o maggiore di elementi (fino a 1000 in una singola risposta). La ricerca full-text è soggetta a un limite massimo di 1.000 corrispondenze (vedere Limiti di risposta API). Appena vengono trovate 1.000 corrispondenze, il motore di ricerca interrompe la ricerca.
Per restituire più o meno risultati, usare i parametri di paging top, skip e next. Il paging è il modo in cui si determina il numero di risultati in ogni pagina logica e si passa attraverso il payload completo. Per altre informazioni, vedere Come usare i risultati della ricerca.