Modelli di soluzioni di Analisi di flusso di Azure
Come molti altri servizi in Azure, Analisi di flusso viene usato meglio con altri servizi per creare una soluzione end-to-end più grande. Questo articolo illustra semplici soluzioni di Analisi di flusso di Azure e vari modelli architetturali. È possibile sviluppare questi modelli per sviluppare soluzioni più complesse. I modelli descritti in questo articolo possono essere usati in un'ampia gamma di scenari. Esempi di modelli specifici dello scenario sono disponibili nelle architetture di soluzioni di Azure.
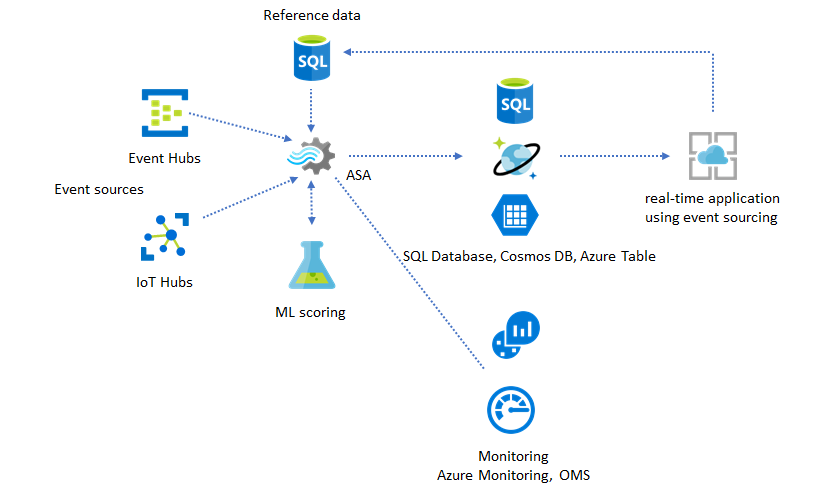
Creare un processo di Analisi di flusso di Azure per potenziare l'esperienza dashboard in tempo reale
Con Analisi di flusso di Azure è possibile creare rapidamente dashboard e avvisi in tempo reale. Una soluzione semplice inserisce eventi da Hub eventi o hub IoT e invia al dashboard di Power BI un set di dati di streaming. Per altre informazioni, vedere l'esercitazione dettagliata Analizzare i dati delle chiamate fraudolente con Analisi di flusso e visualizzare i risultati nel dashboard di Power BI.
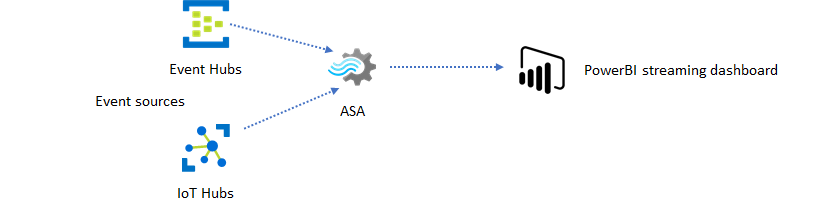
Nel portale di Azure è possibile creare questa soluzione in pochi minuti. Non è richiesta nessuna codifica estesa e per esprimere la logica di business viene usato il linguaggio SQL.
Questo modello di soluzione offre la latenza più bassa dall'origine evento al dashboard di Power BI in un browser. Analisi di flusso di Azure è l'unico servizio di Azure che offre questa funzionalità predefinita.
Usare SQL per il dashboard
Il dashboard di Power BI offre bassa latenza, ma non può essere usato per produrre report di Power BI completi. Un modello di creazione report comune consiste nell'restituire i dati in database SQL prima. Usare quindi il connettore SQL di Power BI per eseguire query su SQL per ottenere i dati più recenti.
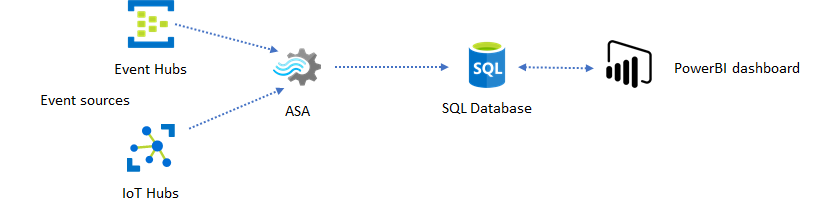
L'uso di database SQL offre maggiore flessibilità, ma a scapito di una latenza leggermente superiore. Questa soluzione è ottimale per i processi con requisiti di latenza superiori a un secondo. Con questo metodo, è possibile ottimizzare le funzionalità di Power BI per filtrare ulteriormente i dati per i report e molto più opzioni di visualizzazione. Si ottiene anche la flessibilità dell'uso di altre soluzioni dashboard, ad esempio Tableau.
SQL non è un archivio dati con velocità effettiva elevata. La velocità effettiva massima da database SQL da Analisi di flusso di Azure è attualmente di circa 24 MB/s. Se le origini eventi nella soluzione producono dati a una velocità superiore, è necessario usare la logica di elaborazione in Analisi di flusso per ridurre la frequenza di output a SQL. È possibile usare tecniche quali filtri, aggregazioni con finestre, criteri di ricerca con join temporali e funzioni analitiche. La frequenza di output in SQL può essere ulteriormente ottimizzata usando le tecniche descritte nell'output di Analisi di flusso di Azure per Azure SQL database.
Incorporare informazioni dettagliate in tempo reale nell'applicazione con la messaggistica degli eventi
Il secondo utilizzo più diffuso di Analisi di flusso di Azure consiste nella generazione di avvisi in tempo reale. In questo modello di soluzione, la logica di business in Analisi di flusso può essere usata per rilevare modelli temporali e spaziali o anomalie, quindi generare segnali di avviso. Tuttavia, a differenza della soluzione dashboard in cui Analisi di flusso usa Power BI come endpoint preferito, è possibile usare diversi sink di dati intermedi. Questi sink includono Hub eventi, bus di servizio e Funzioni di Azure. Lo sviluppatore dell'applicazione deve decidere quale sink di dati è più adatto allo scenario.
Per generare avvisi nel flusso di lavoro aziendale esistente, è necessario implementare la logica consumer di eventi downstream. Funzioni di Azure consente di implementare logica personalizzata e rappresenta il modo più rapido per eseguire l'integrazione. Un'esercitazione sull'uso di Funzioni di Azure come output per un processo di Analisi di flusso è disponibile in Eseguire Funzioni di Azure da processi di Analisi di flusso di Azure. Funzioni di Azure supporta anche vari tipi di notifiche, tra cui SMS ed e-mail. L'app per la logica può essere usata anche per tale integrazione con Hub eventi tra Analisi di flusso di Azure e App per la logica.
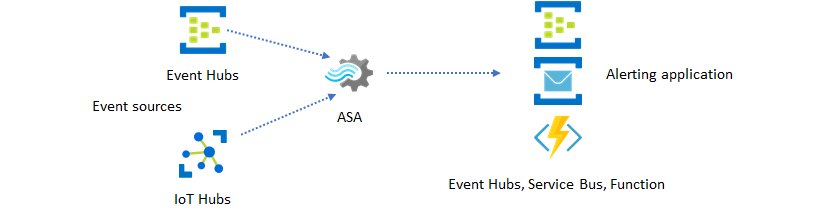
Hub eventi offre invece il punto di integrazione più flessibile. Molti altri servizi, ad esempio Esplora dati e Time Series Insights di Azure possono usare eventi di Hub eventi. Per completare la soluzione, è possibile connettere i servizi direttamente al sink di Hub eventi da Analisi di flusso di Azure. Hub eventi è anche il broker di messaggistica con velocità effettiva più elevata disponibile in Azure per scenari di integrazione di questo tipo.
Applicazioni dinamiche e siti Web
È possibile creare visualizzazioni personalizzate in tempo reale, ad esempio dashboard o visualizzazione mappa, usando Analisi di flusso di Azure e Servizio Azure SignalR. Usando SignalR, i client Web possono essere aggiornati e visualizzare il contenuto dinamico in tempo reale.
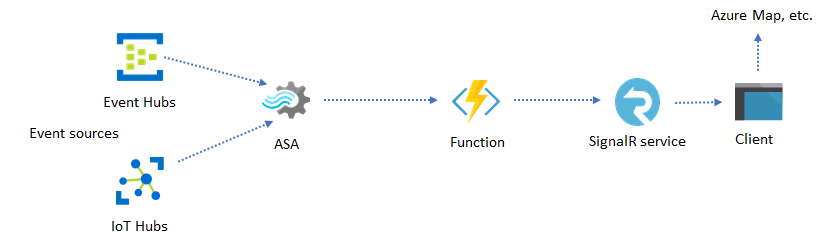
Incorporare informazioni dettagliate in tempo reale nell'applicazione tramite archivi dati
La maggior parte dei servizi Web e delle applicazioni Web attualmente usa un modello di richiesta/risposta per soddisfare il livello di presentazione. Il modello di richiesta/risposta è semplice da compilare e può essere facilmente ridimensionato con tempi di risposta ridotti usando un front-end senza stato e archivi scalabili, ad esempio Azure Cosmos DB.
Un volume di dati elevato spesso crea colli di bottiglia delle prestazioni in un sistema basato su CRUD. Il modello di soluzione di origine eventi viene usato per risolvere i colli di bottiglia delle prestazioni. Anche i modelli temporali e le informazioni dettagliate sono difficili e inefficienti da estrarre da un archivio dati tradizionale. Le moderne applicazioni basate sui dati a volume elevato spesso adottano un'architettura basata su flussi di dati. Analisi di flusso di Azure come motore di calcolo per i dati in movimento è un'analisi di flusso di Azure.
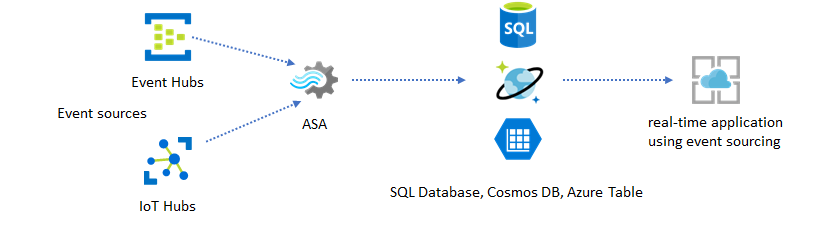
In questo modello di soluzione gli eventi vengono elaborati e aggregati in archivi dati da Analisi di flusso di Azure. Il livello applicazione interagisce con gli archivi dati usando il modello di richiesta/risposta tradizionale. A causa della capacità di Analisi di flusso di elaborare un numero elevato di eventi in tempo reale, l'applicazione è altamente scalabile senza la necessità di eseguire il bulk del livello di archivio dati. Il livello dell'archivio dati è essenzialmente una vista materializzata nel sistema. L'output di Analisi di flusso di Azure in Azure Cosmos DB descrive come viene usato Azure Cosmos DB come output di Analisi di flusso.
Nelle applicazioni reali in cui la logica di elaborazione è complessa ed è necessario aggiornare determinate parti della logica in modo indipendente, più processi di Analisi di flusso possono essere composti insieme a Hub eventi come broker eventi intermedio.
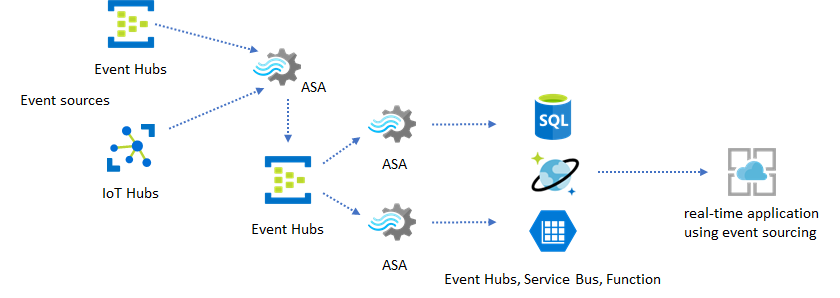
Questo modello migliora la resilienza e la gestibilità del sistema. Tuttavia, anche se Analisi di flusso garantisce esattamente una volta l'elaborazione, esiste una piccola possibilità che gli eventi duplicati vengano inseriti nell'hub eventi intermedio. È importante che il processo downstream di Analisi di flusso deduplica gli eventi usando le chiavi logiche in una finestra di ricerca. Per altre informazioni sul recapito degli eventi, vedere Informazioni di riferimento sulle garanzie di recapito degli eventi.
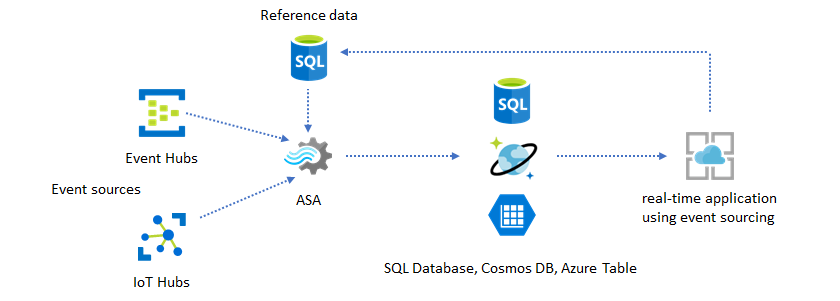
Usare i dati di riferimento per la personalizzazione dell'applicazione
La funzionalità di riferimento di Analisi di flusso di Azure è progettata specificamente per la personalizzazione dell'utente finale, ad esempio soglia di avviso, regole di elaborazione e recinti virtuali. Il livello applicazione può accettare modifiche ai parametri e archiviarle in database SQL. Il processo di Analisi di flusso esegue periodicamente una query per le modifiche dal database e rende accessibili i parametri di personalizzazione tramite un join di dati di riferimento. Per altre informazioni su come usare i dati di riferimento per la personalizzazione dell'applicazione, vedere Dati di riferimento SQL e join dei dati di riferimento.
Questo modello può essere usato anche per implementare un motore regole in cui le soglie delle regole vengono definite dai dati di riferimento. Per altre informazioni sulle regole, vedere Elaborare regole basate su soglie configurabili in Analisi di flusso di Azure.
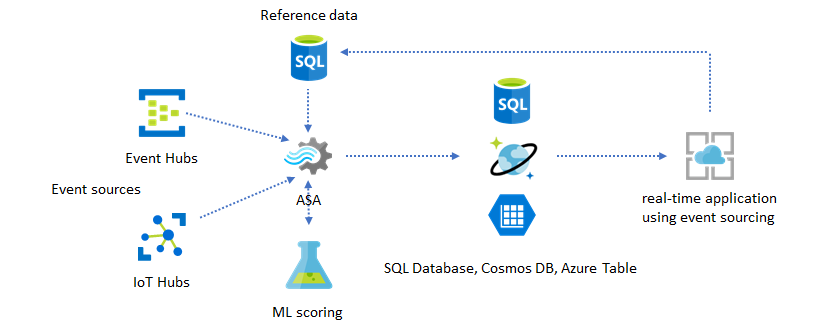
Aggiungere Machine Learning alle informazioni dettagliate in tempo reale
Il modello di rilevamento anomalie predefinito di Analisi di flusso di Azure è un modo pratico per introdurre Machine Learning nell'applicazione in tempo reale. Per un'ampia gamma di esigenze di Machine Learning, vedere Analisi di flusso di Azure si integra con il servizio di assegnazione dei punteggi di Azure Machine Learning.
Per gli utenti avanzati che vogliono incorporare il training online e l'assegnazione dei punteggi nella stessa pipeline di Analisi di flusso, vedere questo esempio di come eseguire questa operazione con la regressione lineare.
Data warehousing in tempo reale
Un altro modello comune è il data warehousing in tempo reale, detto anche data warehouse di streaming. Oltre agli eventi in arrivo in Hub eventi e hub IoT dall'applicazione, Analisi di flusso di Azure in esecuzione in IoT Edge può essere usato per soddisfare le esigenze di pulizia dei dati, riduzione dei dati e archiviazione dei dati e inoltro. Analisi di flusso in esecuzione in IoT Edge può gestire normalmente le limitazioni della larghezza di banda e i problemi di connettività nel sistema. Analisi di flusso può supportare la velocità effettiva fino a 200 MB/sec durante la scrittura in Azure Synapse Analytics.
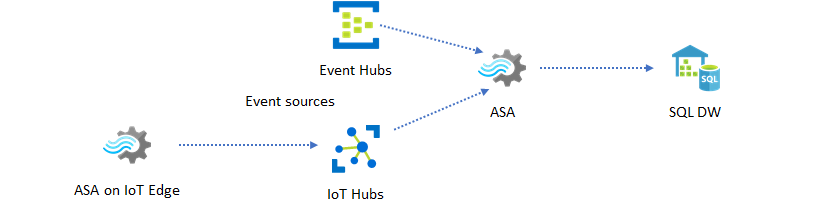
Archiviazione dei dati in tempo reale per l'analisi
La maggior parte delle attività di data science e analisi continua a essere offline. I dati possono essere archiviati da Analisi di flusso di Azure tramite i formati di output di Azure Data Lake Store Gen2 e Parquet. Questa funzionalità rimuove l'attrito per inserire i dati direttamente in Azure Data Lake Analytics, Azure Databricks e Azure HDInsight. Analisi di flusso di Azure viene usato come motore ETL quasi in tempo reale in questa soluzione. È possibile esplorare i dati archiviati in Data Lake usando vari motori di calcolo.
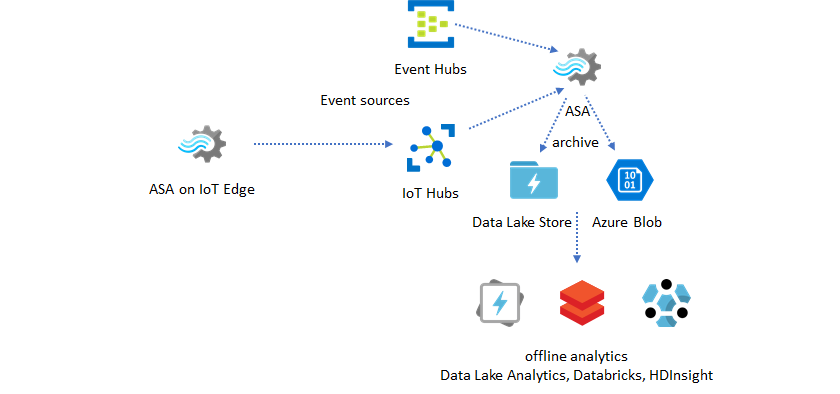
Usare i dati di riferimento per l'arricchimento
L'arricchimento dei dati è spesso un requisito per i motori ETL. Analisi di flusso di Azure supporta l'arricchimento dei dati con dati di riferimento da database SQL e archiviazione BLOB di Azure. L'arricchimento dei dati può essere eseguito per l'atterraggio dei dati in Azure Data Lake e Azure Synapse Analytics.
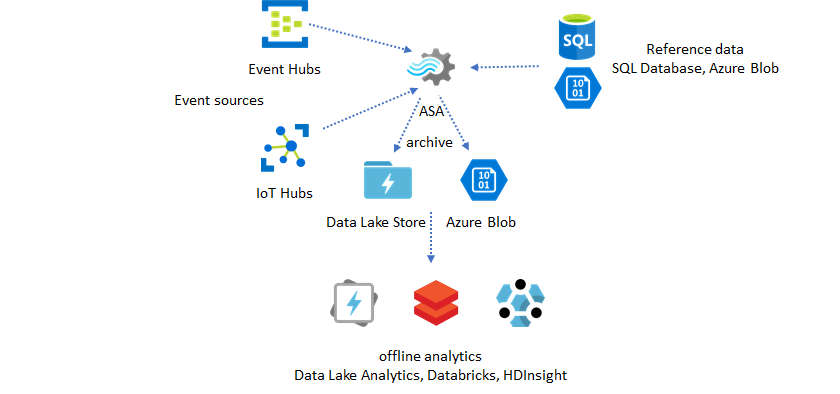
Rendere operativi le informazioni dettagliate dai dati archiviati
Se si combina il modello di analisi offline con il modello di applicazione quasi in tempo reale, è possibile creare un ciclo di feedback. Il ciclo di feedback consente all'applicazione di modificare automaticamente i modelli nei dati. Questo ciclo di feedback può essere semplice come modificare il valore soglia per l'avviso o come complesso come ripetere il training dei modelli di Machine Learning. La stessa architettura della soluzione può essere applicata a entrambi i processi ASA in esecuzione nel cloud e in IoT Edge.
Come monitorare i processi ASA
Per elaborare in tempo reale gli eventi in ingresso in modo continuo, è possibile eseguire un processo di Analisi di flusso di Azure 24 ore su 24, 7 giorni su 7. La garanzia del tempo di attività è fondamentale per l'integrità dell'applicazione complessiva. Anche se Analisi di flusso è l'unico servizio di analisi di streaming nel settore che offre una garanzia di disponibilità del 99,9%, è comunque possibile che si verifichi un certo livello di tempo inattivo. Nel corso degli anni, Analisi di flusso di Azure ha introdotto metriche, log e stati del processo per monitorare l'integrità dei processi. Tutte le informazioni vengono visualizzate tramite il servizio Monitoraggio di Azure e possono essere ulteriormente esportate in Microsoft Operations Management Suite. Per altre informazioni, vedere Monitorare il processo di Analisi di flusso con portale di Azure.
Gli aspetti fondamentali da monitorare sono due, come indicato di seguito.
-
Prima di tutto, è necessario assicurarsi che il processo sia in esecuzione. Se il processo non è in uno stato di esecuzione, non vengono generate nuove metriche o log. I processi possono cambiare in uno stato non riuscito per vari motivi, tra cui un livello di utilizzo elevato su (ad esempio, l'esecuzione di risorse).
Metriche di ritardo della filigrana
Questa metrica riflette quanto lontano dalla pipeline di elaborazione è in tempo di orologio a muro (secondi). Parte del ritardo è attribuito alla logica di elaborazione intrinseca. Di conseguenza, il monitoraggio della tendenza crescente è molto più importante rispetto al monitoraggio del valore assoluto. Il ritardo dello stato stazionario dovrebbe essere risolto nella progettazione dell'applicazione, non tramite il monitoraggio o gli avvisi.
In caso di errore, i log attività e i log di diagnostica sono i luoghi migliori per iniziare a cercare errori.
Creare applicazioni resilienti e cruciali
Indipendentemente dal contratto di servizio di Analisi di flusso di Azure e dal modo in cui si esegue attentamente l'applicazione end-to-end, si verificano interruzioni. Se l'applicazione è fondamentale, è necessario essere preparati per le interruzioni per recuperare in modo corretto.
Per le applicazioni di avviso, la cosa più importante consiste nel rilevare l'avviso successivo. È possibile scegliere di riavviare il processo dall'ora corrente durante il ripristino, ignorando gli avvisi passati. La semantica dell'ora di inizio del processo è in base alla prima ora di output, non alla prima ora di input. L'input viene riavvolto indietro un periodo di tempo appropriato per garantire il primo output al momento specificato è completo e corretto. Non si otterranno aggregazioni parziali e avvisi attivati in modo imprevisto.
È anche possibile scegliere di avviare l'output da un certo periodo di tempo in passato. I criteri di conservazione di Hub eventi e hub IoT contengono una quantità ragionevole di dati per consentire l'elaborazione dal passato. Il compromesso è il modo in cui è possibile recuperare fino all'ora corrente e iniziare a generare nuovi avvisi tempestivi. I dati perdono rapidamente il valore nel tempo, quindi è importante recuperare rapidamente il tempo corrente. Esistono due modi per recuperare rapidamente:
- Eseguire il provisioning di più risorse (SU) quando si recupera.
- Riavviare dall'ora corrente.
Il riavvio dal momento corrente è semplice da fare, con il compromesso di lasciare un vuoto durante l'elaborazione. Il riavvio di questo modo potrebbe essere ok per gli scenari di avviso, ma può essere problematico per gli scenari del dashboard ed è un non starter per gli scenari di archiviazione e archiviazione dei dati.
Il provisioning di più risorse può velocizzare il processo, ma l'effetto di un aumento della frequenza di elaborazione è complesso.
Verificare che il processo sia scalabile a un numero maggiore di UR. Non tutte le query sono scalabili. È necessario assicurarsi che la query sia parallelizzata.
Assicurarsi che siano presenti partizioni sufficienti nell'hub eventi upstream o hub IoT che è possibile aggiungere più unità di velocità effettiva per ridimensionare la velocità effettiva di input. Tenere presente che ogni TU di Hub eventi è massimo a una velocità di output di 2 MB/s.
Assicurarsi di aver effettuato il provisioning di risorse sufficienti nei sink di output (ad esempio, database SQL, Azure Cosmos DB), in modo da non limitare l'aumento dell'output, che a volte può causare il blocco del sistema.
La cosa più importante è prevedere la modifica della frequenza di elaborazione, testare questi scenari prima di passare all'ambiente di produzione e essere pronti per ridimensionare correttamente l'elaborazione durante il tempo di ripristino degli errori.
Nello scenario estremo in cui gli eventi in ingresso sono tutti ritardati, è possibile che tutti gli eventi ritardati vengano eliminati se è stata applicata una finestra di arrivo in ritardo al processo. L'eliminazione degli eventi può sembrare un comportamento misterioso all'inizio; Tuttavia, considerando analisi di flusso è un motore di elaborazione in tempo reale, si prevede che gli eventi in ingresso siano vicini all'ora dell'orologio a muro. Deve eliminare gli eventi che violano questi vincoli.
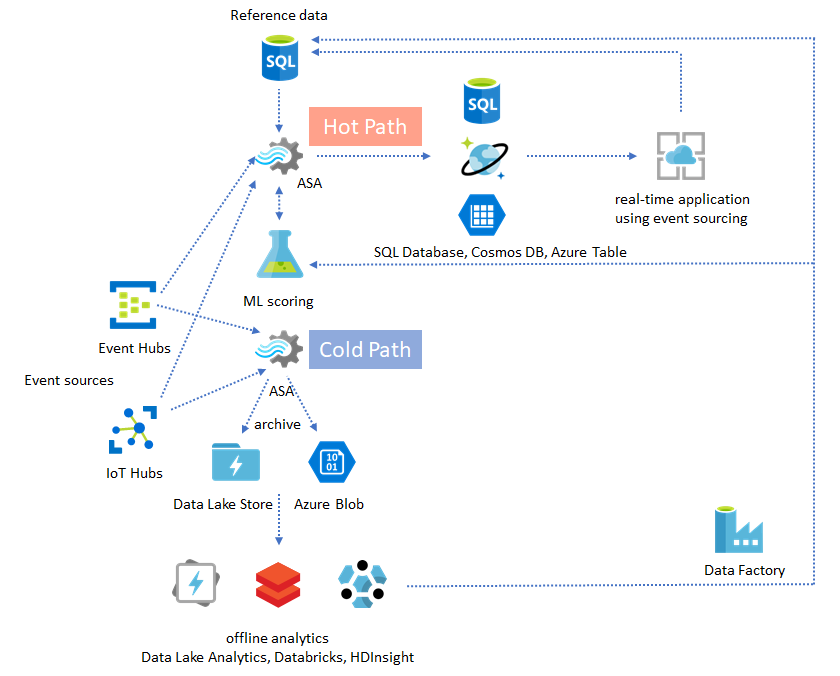
Architettura lambda o processo di riempimento backfill
Fortunatamente, il modello di archiviazione dei dati precedente può essere usato per elaborare questi eventi tardivamente. L'idea è che il processo di archiviazione elabora gli eventi in ingresso nell'ora di arrivo e archivia gli eventi nel bucket di tempo giusto nel BLOB di Azure o in Azure Data Lake Store con il relativo orario di evento. Non importa quanto arriva un evento in ritardo, non verrà mai eliminato. Verrà sempre atterrato nel bucket del momento giusto. Durante il ripristino, è possibile rielaborare gli eventi archiviati e riempire di nuovo i risultati nell'archivio preferito. Questo è simile al modo in cui vengono implementati i modelli lambda.
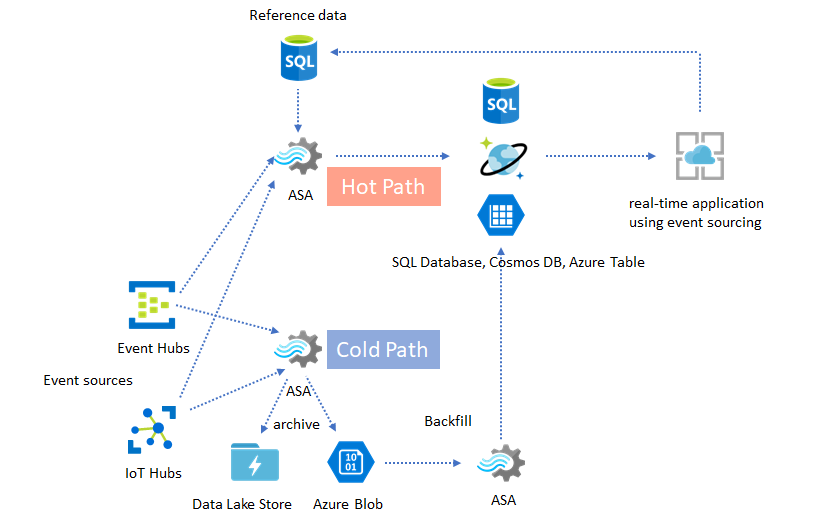
Il processo di riempimento del backfill deve essere eseguito con un sistema di elaborazione batch offline, che probabilmente ha un modello di programmazione diverso rispetto ad Analisi di flusso di Azure. Ciò significa che è necessario implementare nuovamente l'intera logica di elaborazione.
Per il riempimento di backfilling, è comunque importante effettuare almeno temporaneamente il provisioning di più risorse nei sink di output per gestire una velocità effettiva maggiore rispetto alle esigenze di elaborazione dello stato costante.
| Scenari | Riavviare solo da ora | Riavviare l'ultima ora arrestata | Riavviare da ora + riempimento con eventi archiviati |
|---|---|---|---|
| Creazione di dashboard | Crea gap | OK per un'interruzione breve | Usare per un'interruzione prolungata |
| Invio di avvisi | Accettabile | OK per un'interruzione breve | Non necessario |
| App di origine eventi | Accettabile | OK per un'interruzione breve | Usare per un'interruzione prolungata |
| Data warehousing | Perdita di dati | Accettabile | Non necessario |
| Analisi offline | Perdita di dati | Accettabile | Non necessario |
Riassumendo
Non è difficile immaginare che tutti i modelli di soluzione menzionati in precedenza possano essere combinati in un sistema end-to-end complesso. Il sistema combinato può includere dashboard, avvisi, applicazioni di origine eventi, data warehousing e funzionalità di analisi offline.
La chiave consiste nel progettare il sistema in modelli componibili, in modo che ogni sottosistema possa essere compilato, testato, aggiornato e ripristinato in modo indipendente.
Passaggi successivi
Sono stati ora visualizzati diversi modelli di soluzione usando Analisi di flusso di Azure. È ora possibile approfondire ulteriormente l'argomento e creare il primo processo di Analisi di flusso: