Che cos'è ML.NET e come funziona?
ML.NET consente di aggiungere Machine Learning alle applicazioni .NET, in scenari online o offline. Con questa funzionalità, è possibile eseguire stime automatiche usando i dati disponibili per l'applicazione. Le applicazioni di Machine Learning usano modelli nei dati per eseguire stime invece di dover essere programmate in modo esplicito.
Central to ML.NET è un modello di Machine Learning . Il modello specifica i passaggi necessari per trasformare i dati di input in una stima. Con ML.NET è possibile eseguire il training di un modello personalizzato specificando un algoritmo oppure è possibile importare modelli TensorFlow e Open Neural Network Exchange (ONNX) con training preliminare.
Dopo aver creato un modello, è possibile aggiungerlo all'applicazione per eseguire le stime.
ML.NET viene eseguito su Windows, Linux e macOS utilizzando .NET, oppure su Windows utilizzando il .NET Framework. 64 bit è supportato in tutte le piattaforme. La modalità a 32 bit è supportata su Windows, ad eccezione delle funzionalità correlate a TensorFlow, LightGBM e ONNX.
La tabella seguente mostra esempi del tipo di stime che è possibile eseguire con ML.NET.
| Tipo di stima | Esempio |
|---|---|
| Classificazione/Categorizzazione | Dividere automaticamente il feedback dei clienti in categorie positive e negative. |
| Regressione/Prevedere valori continui | Stimare il prezzo delle case in base alle dimensioni e alla posizione. |
| rilevamento di anomalie | Rilevare transazioni bancarie fraudolente. |
| Raccomandazioni | Suggerisci prodotti che gli acquirenti online potrebbero voler acquistare, in base ai loro acquisti precedenti. |
| Serie temporale/dati sequenziali | Prevedere il meteo o le vendite dei prodotti. |
| classificazione delle immagini | Classificare le patologie nelle immagini mediche. |
| Classificazione del testo | Classificare i documenti in base al contenuto. |
| Somiglianza di frasi | Misurare la somiglianza di due frasi. |
App ML.NET semplice
Il codice nel frammento di codice seguente illustra l'applicazione ML.NET più semplice. In questo esempio viene creato un modello di regressione lineare per stimare i prezzi delle case usando i dati sulle dimensioni delle case e dei prezzi.
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public record HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public record Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new();
// 1. Import or create training data.
HouseData[] houseData = [
new() { Size = 1.1F, Price = 1.2F },
new() { Size = 1.9F, Price = 2.3F },
new() { Size = 2.8F, Price = 3.0F },
new() { Size = 3.4F, Price = 3.7F }
];
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline.
EstimatorChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> pipeline = mlContext.Transforms.Concatenate("Features", ["Size"])
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model.
TransformerChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> model = pipeline.Fit(trainingData);
// 4. Make a prediction.
HouseData size = new() { Size = 2.5F };
Prediction price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size * 1000} sq ft = {price.Price * 100:C}k");
// Predicted price for size: 2500 sq ft = $261.98k
}
}
Flusso di lavoro del codice
Il diagramma seguente rappresenta la struttura del codice dell'applicazione e il processo iterativo dello sviluppo di modelli:
- Raccogliere e caricare dati di training in un oggetto IDataView
- Specificare una pipeline di operazioni per estrarre le funzionalità e applicare un algoritmo di Machine Learning
- Eseguire il training di un modello chiamando Fit(IDataView) nella pipeline
- Valutare il modello ed eseguire l'iterazione per migliorare
- Salvare il modello in formato binario per l'uso in un'applicazione
- Caricare di nuovo il modello in un oggetto ITransformer
- Eseguire stime chiamando PredictionEngineBase<TSrc,TDst>.Predict
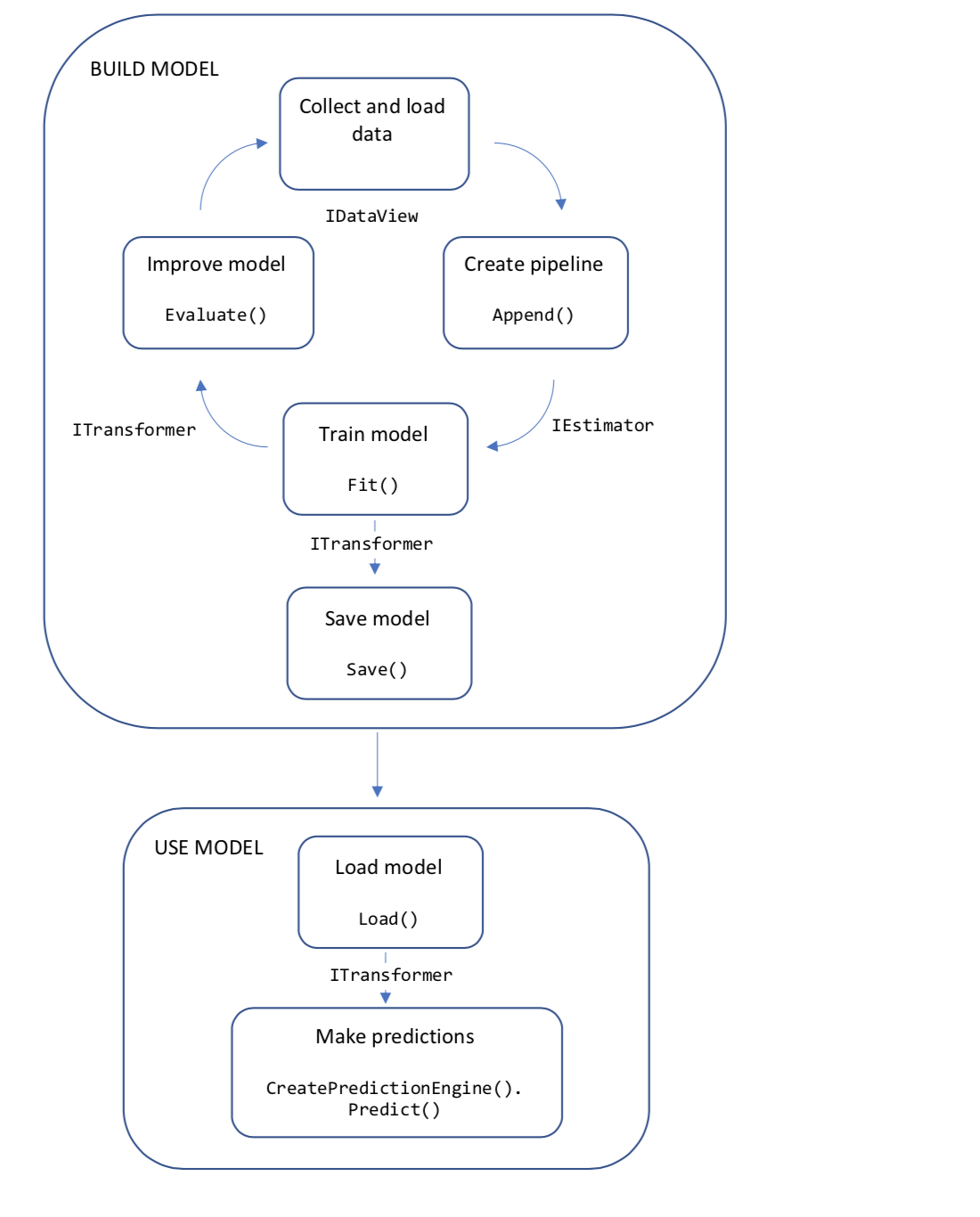
Esaminiamo un po' più in dettaglio questi concetti.
Modello di Machine Learning
Un modello ML.NET è un oggetto che contiene trasformazioni da eseguire sui dati di input per arrivare all'output stimato.
Basico
Il modello più semplice è la regressione lineare bidimensionale, in cui una quantità continua è proporzionale a un'altra, come nell'esempio di prezzo casa illustrato in precedenza.

Il modello è semplicemente: $Price = b + Dimensioni * w$. I parametri $b$ e $w$ vengono stimati tracciando una retta su un insieme di coppie (dimensione, prezzo). I dati usati per trovare i parametri del modello vengono chiamati dati di addestramento. Gli input di un modello di Machine Learning vengono chiamati funzionalità di . In questo esempio $Size$ è l'unica funzionalità. I valori veritieri usati per eseguire il training di un modello di apprendimento automatico vengono chiamati etichette . In questo caso, i valori $Price$ nel set di dati di training sono le etichette.
Più complesso
Un modello più complesso classifica le transazioni finanziarie in categorie usando la descrizione del testo della transazione.
Ogni descrizione della transazione viene suddivisa in un set di funzionalità rimuovendo parole e caratteri ridondanti e conteggiando le combinazioni di parole e caratteri. Il set di funzionalità viene usato per addestrare un modello lineare basato sul set di categorie nei dati di addestramento. Quanto più una nuova descrizione è simile a quelle nel set di training, tanto più probabilmente verrà assegnata alla stessa categoria.

Sia il modello di prezzo della casa che il modello di classificazione del testo sono modelli lineari di. A seconda della natura dei dati e del problema che si sta risolvendo, è anche possibile usare modelli di albero delle decisioni, modelli di additivi generalizzati e altri. Per altre informazioni sui modelli, vedere attività .
Preparazione dei dati
Nella maggior parte dei casi, i dati disponibili non sono adatti per essere usati direttamente per eseguire il training di un modello di Machine Learning. I dati non elaborati devono essere preparati o pre-elaborati prima di poterli usare per trovare i parametri del modello. Potrebbe essere necessario convertire i dati da valori stringa a una rappresentazione numerica. Potrebbero essere presenti informazioni ridondanti nei dati di input. Potrebbe essere necessario ridurre o espandere le dimensioni dei dati di input. Potrebbe essere necessario normalizzare o ridimensionare i dati.
Le esercitazioni ML.NET ti insegnano le diverse pipeline di elaborazione dati per dati di testo, immagine, numerici e serie temporali che vengono usate per attività specifiche di Machine Learning.
Come preparare i dati illustra come applicare la preparazione dei dati in generale.
È possibile trovare un'appendice di tutte le trasformazioni disponibili nella sezione risorse.
Valutazione del modello
Dopo aver addestrato il tuo modello, come puoi sapere quanto bene farà previsioni future? Con ML.NET, è possibile valutare il modello rispetto ad alcuni nuovi dati di test.
Ogni tipo di attività di Machine Learning include metriche usate per valutare l'accuratezza e la precisione del modello rispetto al set di dati di test.
L'esempio di prezzo della casa illustrato in precedenza ha usato il compito di regressione . Per valutare il modello, aggiungere il codice seguente all'esempio originale.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
Le metriche di valutazione indicano che l'errore è piuttosto basso e che la correlazione tra l'output previsto e l'output del test è elevata. È stato facile! Negli esempi reali è necessario ottimizzare di più per ottenere metriche del modello valide.
architettura ML.NET
In questa sezione vengono descritti i modelli architetturali di ML.NET. Se si è uno sviluppatore .NET esperto, alcuni di questi modelli saranno familiari e alcuni saranno meno familiari.
Un'applicazione ML.NET inizia con un oggetto MLContext. Questo oggetto singleton contiene cataloghi. Un catalogo è un sistema per il caricamento e il salvataggio dei dati, le trasformazioni, i trainer e i componenti operativi del modello. Ogni oggetto catalogo dispone di metodi per creare i diversi tipi di componenti.
| Compito | Catalogo |
|---|---|
| Caricamento e salvataggio dei dati | DataOperationsCatalog |
| Preparazione dei dati | TransformsCatalog |
| Classificazione binaria | BinaryClassificationCatalog |
| Classificazione multiclasse | MulticlassClassificationCatalog |
| Rilevamento anomalie | AnomalyDetectionCatalog |
| Raggruppamento | ClusteringCatalog |
| Previsione | ForecastingCatalog |
| Graduatoria | RankingCatalog |
| Regressione | RegressionCatalog |
| Raccomandazione | RecommendationCatalog |
| Serie temporale | TimeSeriesCatalog |
| Utilizzo del modello | ModelOperationsCatalog |
È possibile passare ai metodi di creazione in ognuna delle categorie elencate. Se si usa Visual Studio, i cataloghi vengono visualizzati anche tramite IntelliSense.
Costruire la pipeline
All'interno di ogni catalogo è disponibile un set di metodi di estensione che è possibile usare per creare una pipeline di training.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
Nel frammento di codice, Concatenate e Sdca sono entrambi metodi nel catalogo. Ognuno crea un oggetto IEstimator che viene aggiunto alla pipeline.
A questo punto, gli oggetti sono stati creati, ma non è stata eseguita alcuna esecuzione.
Addestrare il modello
Dopo aver creato gli oggetti nella pipeline, è possibile usare i dati per eseguire il training del modello.
var model = pipeline.Fit(trainingData);
La chiamata Fit() usa i dati di training di input per stimare i parametri del modello. Questa operazione è nota come addestrare il modello. Tenere presente che il modello di regressione lineare illustrato in precedenza aveva due parametri del modello: distorsione e peso. Dopo la chiamata Fit(), i valori dei parametri sono noti. La maggior parte dei modelli avrà molti più parametri di questo.
Altre informazioni sul training dei modelli sono disponibili in Come eseguire il training del modello.
L'oggetto modello risultante implementa l'interfaccia ITransformer. Ovvero, il modello trasforma i dati di input in stime.
IDataView predictions = model.Transform(inputData);
Usa il modello
È possibile trasformare i dati di input in previsioni in blocco o un input alla volta. L'esempio del prezzo delle case ha eseguito entrambe le operazioni: in blocco per valutare il modello e una alla volta per fare una nuova previsione. Esaminiamo come fare singole previsioni.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
Il metodo CreatePredictionEngine() accetta una classe di input e una classe di output. I nomi dei campi o gli attributi di codice determinano i nomi delle colonne di dati usate durante il training e la stima del modello. Per ulteriori informazioni, vedere Fare previsioni con un modello allenato.
Modelli di dati e schema
Al centro di una pipeline di Machine Learning di ML.NET ci sono gli oggetti DataView.
Ogni trasformazione nella pipeline ha uno schema di input (nomi dei dati, tipi e dimensioni che la trasformazione si aspetta di vedere nel suo input); e uno schema di output (nomi dei dati, tipi e dimensioni prodotti dalla trasformazione dopo la trasformazione).
Se lo schema di output di una trasformazione nella pipeline non corrisponde allo schema di input della trasformazione successiva, ML.NET genererà un'eccezione.
Un oggetto vista dati contiene colonne e righe. Ogni colonna ha un nome e un tipo e una lunghezza. Ad esempio, le colonne di input nell'esempio di prezzo della casa sono Dimensione e Prezzo. Sono entrambi tipi Single e sono quantità scalari anziché vettoriali.
esempio di vista dati 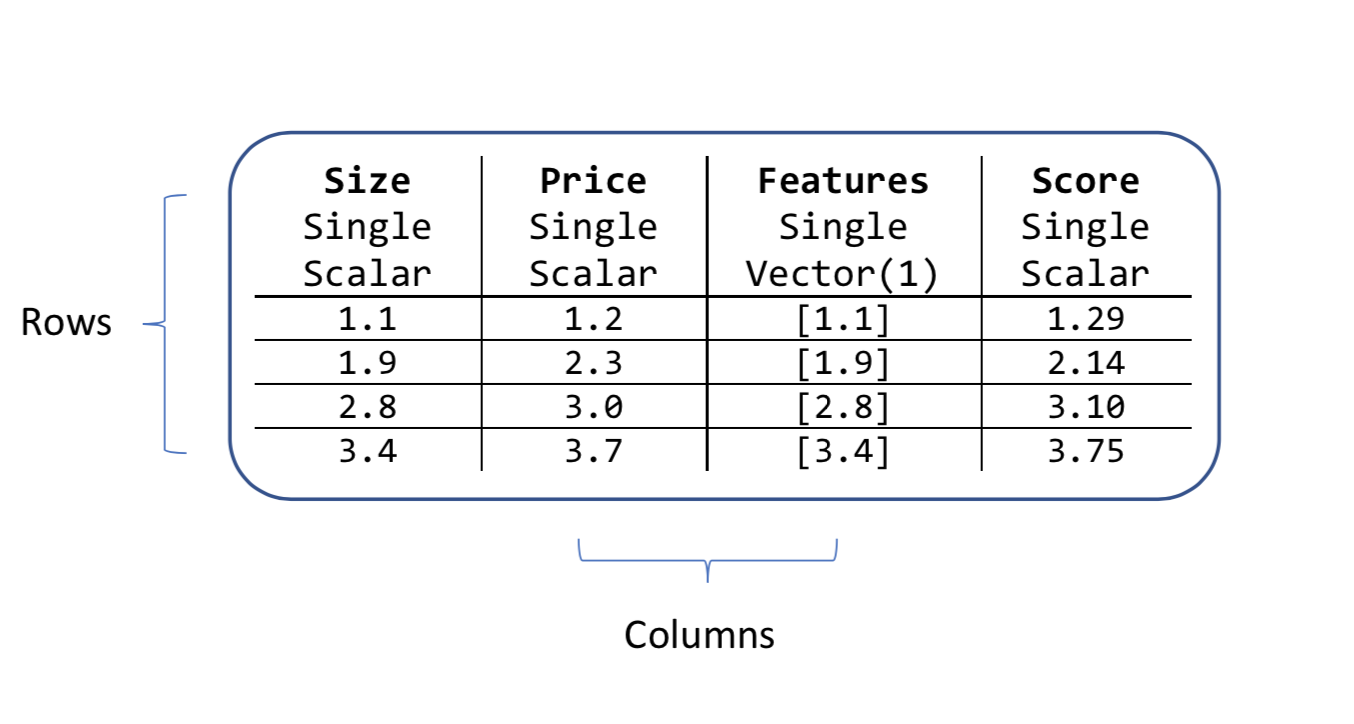
Tutti gli algoritmi ML.NET cercano una colonna di input che rappresenta un vettore. Per impostazione predefinita, questa colonna vettoriale viene chiamata Features. Ecco perché l'esempio di prezzo delle case concatena la colonna Size in una nuova colonna chiamata Features.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Tutti gli algoritmi creano anche nuove colonne dopo aver eseguito una stima. I nomi fissi di queste nuove colonne dipendono dal tipo di algoritmo di Machine Learning. Per l'attività di regressione, una delle nuove colonne viene chiamata Score, come illustrato nell'attributo dei dati sui prezzi.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Ulteriori informazioni sulle colonne di output di diverse attività di Machine Learning sono disponibili nella guidaattività di Machine Learning.
Una proprietà importante degli oggetti DataView consiste nel fatto che vengono valutati in modo differito. Le viste dei dati vengono caricate e gestite solo durante l'addestramento e la valutazione del modello e la previsione dei dati. Durante la scrittura e il test dell'applicazione ML.NET, è possibile usare il debugger di Visual Studio per esaminare qualsiasi oggetto di vista dati chiamando il metodo Preview.
var debug = testPriceDataView.Preview();
È possibile controllare la variabile debug nel debugger ed esaminarne il contenuto.
Nota
Non usare il metodo Preview(IDataView, Int32) nel codice di produzione, perché riduce significativamente le prestazioni.
Distribuzione del modello
Nelle applicazioni reali, il codice di addestramento e valutazione del modello sarà separato dalla previsione. Infatti, queste due attività vengono spesso eseguite da team separati. Il team di sviluppo del modello può salvare il modello da usare nell'applicazione di stima.
mlContext.Model.Save(model, trainingData.Schema, "model.zip");