Esercitazione: Rilevare anomalie nelle vendite dei prodotti con ML.NET
Articolo
Informazioni su come creare un'applicazione di rilevamento delle anomalie per i dati di vendita dei prodotti. Questa esercitazione crea un'applicazione console .NET Core usando C# in Visual Studio.
In questa esercitazione verranno illustrate le procedure per:
Caricare i dati
Creare una trasformazione per il rilevamento di anomalie dei picchi
Rilevare le anomalie dei picchi con la trasformazione
Creare una trasformazione per il rilevamento di anomalie dei punti di modifica
Rilevare le anomalie dei punti di modifica con la trasformazione
È possibile trovare il codice sorgente per questa esercitazione nel repository dotnet/samples.
Prerequisiti
Visual Studio 2022 con il carico di lavoro "NET Desktop Development" installato.
Il formato di dati usato in product-sales.csv è basato sul set di dati "Vendite di shampoo in un arco di tre anni" ricavato originariamente da DataMarket e fornito da Time Series Data Library (TSDL), di Rob Hyndman.
Set di dati "Vendite di shampoo in un arco di tre anni" concesso in licenza nell'ambito della licenza aperta predefinita DataMarket.
Creare un'applicazione console
Creare un'applicazione console C# denominata "ProductSalesAnomalyDetection". Fare clic sul pulsante Next (Avanti).
Scegliere .NET 6 come framework da usare. Fare clic sul pulsante Crea.
Creare una directory denominata Data nel progetto per salvare i file del set di dati.
Installare il pacchetto NuGet Microsoft.ML:
Nota
Questo esempio usa la versione stabile più recente dei pacchetti NuGet menzionati a meno che non sia specificato in altro modo.
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e selezionare Gestisci pacchetti NuGet. Scegliere "nuget.org" come origine pacchetto, selezionare la scheda Sfoglia, cercare Microsoft.ML e selezionare il pulsante Installa . Selezionare il pulsante OK nella finestra di dialogo Anteprima modifiche e quindi selezionare il pulsante Accetto nella finestra di dialogo Accettazione della licenza se si accettano le condizioni di licenza per i pacchetti elencati. Ripetere questi passaggi per Microsoft.ML.TimeSeries.
Aggiungere le istruzioni using seguenti all'inizio del file Program.cs:
using Microsoft.ML;
using ProductSalesAnomalyDetection;
Scarica i tuoi dati
Scaricare il set di dati e salvarlo nella cartella Dati precedentemente creata:
Fare clic con il pulsante destro del mouse su product-sales.csv e selezionare "Salva collegamento con nome..." o "Salva oggetto con nome..."
Assicurarsi di salvare il file *.csv nella cartella Dati o dopo averlo salvato altrove, spostare il file *.csv nella cartella Dati .
In Esplora soluzioni fare clic con il pulsante destro del mouse sul file *.csv e selezionare Proprietà. In Avanzate modificare il valore di Copia in Directory di output in Copia se più recente.
La tabella seguente è un'anteprima dei dati dal file *.csv:
Month
VenditeProdotto
1 - gen
271
2 - gen
150.9
.....
.....
1-feb
199.3
.....
.....
Creare le classi e definire i percorsi
Successivamente, definire le strutture dei dati delle classi di input e stima.
Aggiungere una nuova classe al progetto:
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e quindi scegliere Aggiungi > nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e impostare il campo Nome su ProductSalesData.cs. Selezionare quindi il pulsante Aggiungi.
Il file ProductSalesData.cs verrà aperto nell'editor del codice.
Aggiungere l'istruzione using seguente all'inizio di ProductSalesData.cs:
using Microsoft.ML.Data;
Rimuovere la definizione di classe esistente e aggiungere il codice seguente, che contiene le due classi ProductSalesData e ProductSalesPrediction, al file ProductSalesData.cs:
public class ProductSalesData
{
[LoadColumn(0)]
public string? Month;
[LoadColumn(1)]
public float numSales;
}
public class ProductSalesPrediction
{
//vector to hold alert,score,p-value values
[VectorType(3)]
public double[]? Prediction { get; set; }
}
ProductSalesData specifica una classe di dati di input. L'attributo LoadColumn specifica quali colonne (in base all'indice delle colonne) nel set di dati è necessario caricare.
ProductSalesPrediction specifica la classe di dati di stima. Per il rilevamento delle anomalie, la stima consiste in un avviso per indicare l'eventuale presenza di un'anomalia, un punteggio non elaborato e un valore p. Quanto più vicino a 0 è il valore p, tanto maggiore è la probabilità che si sia verificata un'anomalia.
Creare due campi globali per contenere il percorso del file del set di dati scaricato di recente e il percorso del file del modello salvato:
_dataPath contiene il percorso del set di dati usato per il training del modello.
_docsize contiene il numero di record presenti nel file del set di dati. Si userà _docSize per calcolare pvalueHistoryLength.
Aggiungere il codice seguente alla riga seguente sotto le istruzioni using per specificare tali percorsi:
string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv");
//assign the Number of records in dataset file to constant variable
const int _docsize = 36;
Inizializzare le variabili
Sostituire la riga con il codice seguente per dichiarare e inizializzare la Console.WriteLine("Hello World!")mlContext variabile:
MLContext mlContext = new MLContext();
La classe MLContext è un punto di partenza per tutte le operazioni ML.NET e l'inizializzazione di mlContext crea un nuovo ambiente ML.NET che può essere condiviso tra gli oggetti del flusso di lavoro della creazione del modello. Dal punto di vista concettuale è simile a DBContext in Entity Framework.
Caricare i dati
I dati in ML.NET sono rappresentati come interfaccia IDataView. IDataView è un modo flessibile ed efficiente di descrivere i dati tabulari (numerici e di testo). È possibile caricare dati da un file di testo o da altre origini, ad esempio un database SQL o file di log, in un oggetto IDataView.
Aggiungere il codice seguente dopo aver creato la mlContext variabile:
LoadFromTextFile() definisce lo schema dei dati e legge il contenuto del file. Acquisisce le variabili di percorso dei dati e restituisce un oggetto IDataView.
Rilevamento delle anomalie delle serie temporali
Il rilevamento delle anomalie segnala eventi o comportamenti imprevisti o insoliti. Fornisce indizi su dove cercare i problemi e consente di rispondere alla domanda "È strano?".
Il rilevamento delle anomalie è il processo di rilevamento degli outlier dati delle serie temporali; indica una determinata serie temporale di input in cui il comportamento non è quello previsto o è "strano".
Il rilevamento delle anomalie può essere utile in molte situazioni. Ad esempio:
Se hai un'auto, potresti voler sapere: è normale la lettura del misuratore di olio o ho una perdita?
Se si monitora il consumo di energia, si vuole sapere: è presente un'interruzione?
Esistono due tipi di anomalie di serie temporali che possono essere rilevati:
I picchi indicano accessi temporanei di comportamenti anomali nel sistema.
I punti di modifica indicano l'inizio di modifiche persistenti nel corso del tempo nel sistema.
A differenza dei modelli nelle altre esercitazioni, le trasformazioni di rilevamento delle anomalie nelle serie temporali vengono applicate direttamente ai dati di input. Il metodo IEstimator.Fit() non necessita dei dati di training per generare la trasformazione. Ha tuttavia bisogno dello schema dei dati, fornito da una visualizzazione dati generata da un elenco vuoto di ProductSalesData.
Analizzare gli stessi dati di vendita del prodotto per rilevare i picchi e i punti di modifica. Il processo del modello di compilazione e di training è lo stesso per il rilevamento dei picchi e dei punti di modifica; la differenza principale è l'algoritmo di rilevamento specifico usato.
Rilevamento dei picchi
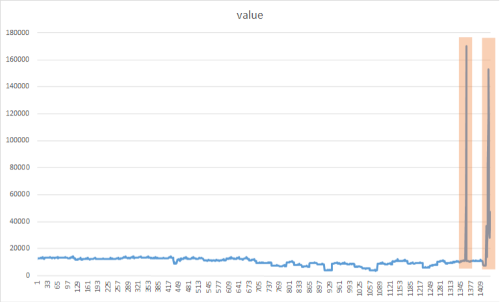
Lo scopo del rilevamento dei picchi consiste nell'identificare i picchi improvvisi ma temporanei che differiscono notevolmente dalla maggior parte dei valori dei dati delle serie temporali. È importante rilevare questi elementi, osservazioni o eventi rari sospetti in modo tempestivo per fare in modo che abbiano un impatto minimo. L'approccio seguente può essere usato per rilevare un'ampia gamma di anomalie, quali: interruzioni del servizio, attacchi informatici o contenuto web virale. L'immagine seguente riporta un esempio di picchi in un set di dati relativo a una serie temporale:
Aggiungere il metodo CreateEmptyDataView()
Aggiungere il metodo seguente a Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Il metodo CreateEmptyDataView() genera un oggetto visualizzazione dati vuoto con lo schema corretto, da usare come input per il metodo IEstimator.Fit().
Creare il metodo DetectSpike()
Il metodo DetectSpike():
Crea la trasformazione dallo strumento di stima.
Rileva picchi in base ai dati cronologici di vendita.
Visualizza i risultati.
Creare il DetectSpike() metodo nella parte inferiore del file Program.cs usando il codice seguente:
DetectSpike(MLContext mlContext, int docSize, IDataView productSales)
{
}
Usare IidSpikeEstimator per eseguire il training del modello per il rilevamento dei picchi. Aggiungerlo al metodo DetectSpike() con il codice seguente:
Creare la trasformazione di rilevamento dei picchi aggiungendo il codice seguente come riga successiva nel metodo DetectSpike():
Suggerimento
I confidence parametri e pvalueHistoryLength influiscono sulla modalità di rilevamento dei picchi. confidence determina la sensibilità del modello ai picchi. Minore è la probabilità che l'algoritmo rilevi picchi più piccoli. Il pvalueHistoryLength parametro definisce il numero di punti dati in una finestra scorrevole. Il valore di questo parametro è in genere una percentuale dell'intero set di dati. Più basso è pvalueHistoryLength, più veloce il modello dimentica i picchi di grandi dimensioni precedenti.
Il codice precedente usa il metodo Transform() per effettuare stime per più righe di input di un set di dati.
Convertire l'oggetto transformedData in un oggetto fortemente tipizzato IEnumerable per una visualizzazione più semplice usando il metodo CreateEnumerable() con il codice seguente:
var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);
Creare una linea dell'intestazione di visualizzazione usando il codice Console.WriteLine() seguente:
Console.WriteLine("Alert\tScore\tP-Value");
Nei risultati relativi al rilevamento di picchi saranno visualizzate le informazioni seguenti:
Alert indica un avviso di picco per un punto dati specificato.
Score è il valore ProductSales per un punto dati specificato nel set di dati.
P-Value "P" è l'acronimo di probabilità. Quanto più vicino a 0 è il valore p, tanto maggiore è la probabilità che il punto dati costituisca un'anomalia.
Usare il codice seguente per eseguire l'iterazione attraverso predictionsIEnumerable e visualizzare i risultati:
foreach (var p in predictions)
{
if (p.Prediction is not null)
{
var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}";
if (p.Prediction[0] == 1)
{
results += " <-- Spike detected";
}
Console.WriteLine(results);
}
}
Console.WriteLine("");
Aggiungere la chiamata al DetectSpike() metodo sotto la chiamata al LoadFromTextFile() metodo :
DetectSpike(mlContext, _docsize, dataView);
Risultati del rilevamento di picchi
I risultati dovrebbero essere simili a quanto riportato di seguito. Durante l'elaborazione, vengono visualizzati alcuni messaggi. Possono essere mostrati avvisi o messaggi relativi all'elaborazione. Per maggiore chiarezza, dai risultati seguenti sono stati rimossi alcuni messaggi.
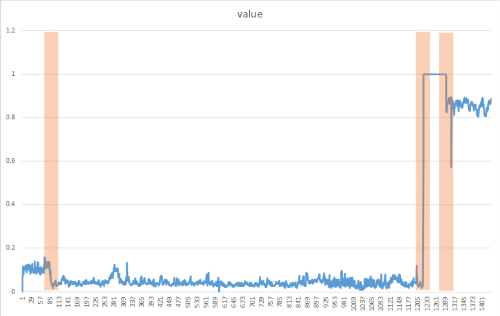
Change points sono modifiche permanenti in una serie temporale di un flusso di distribuzione di valori, come le modifiche di livello e le tendenze. Queste modifiche persistenti durano molto più tempo rispetto ai spikes e potrebbero indicare uno o più eventi catastrofici. I Change points non sono in genere visibili a occhio nudo, ma possono essere rilevati nei dati usando alcuni approcci, come nel metodo seguente. L'immagine seguente rappresenta un esempio di rilevamento di un punto di modifica:
Creare il metodo DetectChangepoint()
Il metodo DetectChangepoint() esegue le attività seguenti:
Crea la trasformazione dallo strumento di stima.
Rileva punti di modifica in base ai dati cronologici di vendita.
Visualizza i risultati.
Creare il DetectChangepoint() metodo subito dopo la dichiarazione del DetectSpike() metodo usando il codice seguente:
void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales)
{
}
Creare l'oggetto iidChangePointEstimator nel metodo DetectChangepoint() con il codice seguente:
Come già fatto in precedenza, creare la trasformazione dallo strumento di stima aggiungendo la riga di codice seguente nel metodo DetectChangePoint():
Suggerimento
Il rilevamento dei punti di modifica si verifica con un lieve ritardo perché il modello deve assicurarsi che la deviazione corrente sia una modifica persistente e non solo alcuni picchi casuali prima di creare un avviso. La quantità di questo ritardo è uguale al changeHistoryLength parametro . Aumentando il valore di questo parametro, gli avvisi di rilevamento delle modifiche in caso di modifiche più persistenti, ma il compromesso sarebbe un ritardo più lungo.
var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));
Usare il metodo Transform() per trasformare i dati aggiungendo il codice seguente a DetectChangePoint():
Come in precedenza, convertire l'oggetto transformedData in un oggetto fortemente tipizzato IEnumerable per semplificare la visualizzazione usando il CreateEnumerable()metodo con il codice seguente:
var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);
Creare un'intestazione di visualizzazione con il codice seguente al metodo DetectChangePoint() come riga successiva:
Nei risultati del rilevamento di punti di modifica saranno visualizzate le informazioni seguenti:
Alert indica un avviso di punto di modifica per un punto dati specificato.
Score è il valore ProductSales per un punto dati specificato nel set di dati.
P-Value "P" è l'acronimo di probabilità. Quanto più vicino a 0 è il valore P, tanto maggiore è la probabilità che il punto dati costituisca un'anomalia.
Martingale value viene usato per identificare il livello di "anomalia" del punto dati, in base alla sequenza di valori di P.
Eseguire l'iterazione attraverso predictionsIEnumerable e visualizzare i risultati con il codice seguente:
foreach (var p in predictions)
{
if (p.Prediction is not null)
{
var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}";
if (p.Prediction[0] == 1)
{
results += " <-- alert is on, predicted changepoint";
}
Console.WriteLine(results);
}
}
Console.WriteLine("");
Aggiungere la chiamata seguente al DetectChangepoint()metodo dopo la chiamata al DetectSpike() metodo :
DetectChangepoint(mlContext, _docsize, dataView);
Risultati del rilevamento dei punti di modifica
I risultati dovrebbero essere simili a quanto riportato di seguito. Durante l'elaborazione, vengono visualizzati alcuni messaggi. Possono essere mostrati avvisi o messaggi relativi all'elaborazione. Per maggiore chiarezza, dai risultati seguenti sono stati rimossi alcuni messaggi.
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.
Feedback su .NET
.NET è un progetto di open source. Selezionare un collegamento per fornire feedback:
In questo modulo si apprenderà come usare ML.NET Model Builder per eseguire il training e di un modello di Machine Learning e utilizzarlo per la manutenzione predittiva.
Gestire l'inserimento e la preparazione dei dati, il training e la distribuzione di modelli e il monitoraggio delle soluzioni di apprendimento automatico con Python, Azure Machine Learning e MLflow.