Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara oraQuesto browser non è più supportato.
Esegui l'aggiornamento a Microsoft Edge per sfruttare i vantaggi di funzionalità più recenti, aggiornamenti della sicurezza e supporto tecnico.
Azure Synapse è un servizio di analisi illimitate che unisce il data warehousing aziendale e l'analisi dei Big Data. Questa esercitazione illustra come connettersi a OneLake usando Azure Synapse Analytics.
Seguire questa procedura per usare Apache Spark per scrivere dati di esempio in OneLake da Azure Synapse Analytics.
Aprire l'area di lavoro di Synapse e creare un pool di Apache Spark con i parametri preferiti.
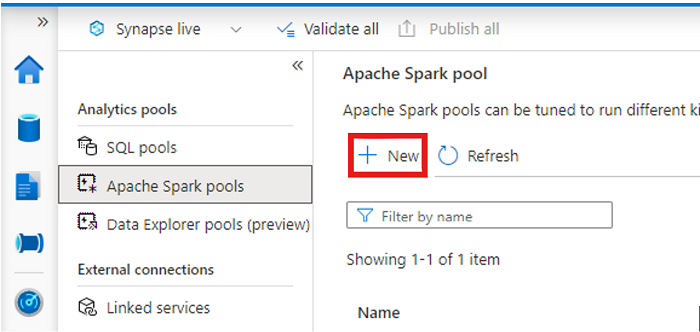
Creare un nuovo notebook Apache Spark.
Aprire il notebook, impostare il linguaggio su PySpark (Python) e connetterlo al pool di Spark appena creato.
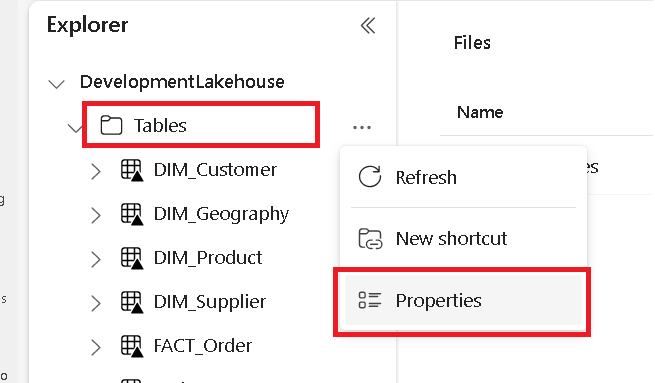
In una scheda separata passare al lakehouse di Microsoft Fabric e trovare la cartella Tabelle di primo livello.
Fare clic con il pulsante destro del mouse sulla cartella Tabelle e selezionare Proprietà.
Copiare il percorso ABFS dal riquadro delle proprietà.
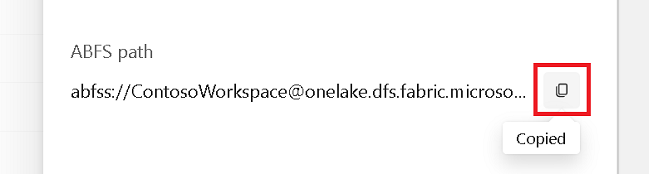
Tornare al notebook di Azure Synapse, nella prima nuova cella di codice, specificare il percorso del lakehouse. Questo lakehouse è dove vengono scritti i dati in un secondo momento. Eseguire la cella.
# Replace the path below with the ABFS path to your lakehouse Tables folder.
oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'
In una nuova cella di codice caricare i dati da un set di dati aperto di Azure in un dataframe. Questo set di dati è quello che viene caricato nel lakehouse. Eseguire la cella.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet')
display(yellowTaxiDf.limit(10))
In una nuova cella di codice, filtrare, trasformare o preparare i dati. Per questo scenario, è possibile ridurre il set di dati per un caricamento più rapido, unirlo ad altri set di dati o filtrare in base a risultati specifici. Eseguire la cella.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1)
display(filteredTaxiDf.limit(10))
In una nuova cella di codice, usando il percorso OneLake, scrivere il dataframe filtrato in una nuova tabella Delta-Parquet nel lakehouse di Fabric. Eseguire la cella.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')
Infine, in una nuova cella di codice, verificare che i dati siano stati scritti correttamente leggendo il file appena caricato da OneLake. Eseguire la cella.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/')
display(lakehouseRead.limit(10))
Congratulazioni. È ora possibile leggere e scrivere dati in OneLake usando Apache Spark in Azure Synapse Analytics.
Seguire questa procedura per usare SQL serverless per leggere i dati da OneLake da Azure Synapse Analytics.
Aprire un lakehouse di Fabric e identificare una tabella su cui eseguire una query da Synapse.
Fare clic con il pulsante destro del mouse sulla tabella e selezionare Proprietà.
Copiare il percorso ABFS per la tabella.
Aprire l’area di lavoro di Synapse in Synapse Studio.
Creare un nuovo script SQL.
Nell'editor di query SQL, immettere la query seguente, sostituendo ABFS_PATH_HERE con il percorso copiato in precedenza.
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'ABFS_PATH_HERE',
FORMAT = 'delta') as rows;
Eseguire la query per visualizzare le prime 10 righe della tabella.
Congratulazioni. È ora possibile leggere i dati da OneLake usando SQL serverless in Azure Synapse Analytics.
Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara ora