Aggregazioni automatiche
Le aggregazioni automatiche usano l'apprendimento automatico (ML) all'avanguardia per ottimizzare continuamente i modelli semantici DirectQuery e ottenere prestazioni massime delle query dei report. Le aggregazioni automatiche si basano sull'infrastruttura esistente delle aggregazioni definite dall'utente introdotta per la prima volta con i modelli compositi per Power BI. A differenza delle aggregazioni definite dall'utente, le aggregazioni automatiche non richiedono ampie capacità di modellazione dei dati e di ottimizzazione delle query per la configurazione e la gestione. Le aggregazioni automatiche sono soggette a ottimizzazione e training automatici. Consentono ai proprietari di modelli con qualsiasi livello di competenza di migliorare le prestazioni delle query, offrendo visualizzazioni dei report più veloci per modelli di grandi dimensioni.
Con le aggregazioni automatiche:
- Le visualizzazioni dei report sono più veloci: una percentuale ottimale di query di report viene restituita da una cache di aggregazioni in memoria gestita automaticamente anziché da sistemi di origine dati back-end. Le query outlier che non sono restituite dalla cache in memoria vengono passate direttamente all'origine dati usando DirectQuery.
- Architettura bilanciata: rispetto alla pura modalità DirectQuery, la maggior parte dei risultati delle query viene restituita dal motore di query di Power BI e dalla cache delle aggregazioni in memoria. Il carico di elaborazione delle query nei sistemi di origine dati nei periodi di picco di creazione di report può essere notevolmente ridotto, il che significa una maggiore scalabilità nel back-end di origine dati.
- Configurazione semplificata: i proprietari dei modelli possono abilitare il training delle aggregazioni automatiche e pianificare uno o più aggiornamenti per il modello. Con il primo training e aggiornamento, le aggregazioni automatiche iniziano a creare un framework di aggregazioni e aggregazioni ottimali. Il sistema si ottimizza automaticamente nel tempo.
- Ottimizzazione: grazie a un'interfaccia utente semplice e intuitiva nelle impostazioni del modello, è possibile stimare i miglioramenti delle prestazioni per una percentuale diversa di query restituite dalla cache delle aggregazioni in memoria e apportare modifiche per ottenere miglioramenti ancora maggiori. Un singolo controllo della barra di scorrimento consente di ottimizzare facilmente l'ambiente.
Requisiti
Piani supportati
Le aggregazioni automatiche sono supportate per i modelli di Power BI Premium per capacità, Premium per utente e Power BI Embedded.
Origini dati supportate
Le aggregazioni automatiche sono supportate per le origini dati seguenti:
- Database SQL di Azure
- Pool SQL dedicato di Azure Synapse
- SQL Server 2019 o versione successiva
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Modalità supportate
Le aggregazioni automatiche sono supportate per i modelli in modalità DirectQuery. Sono supportati i modelli compositi con tabelle di importazione e connessioni DirectQuery. Le aggregazioni automatiche sono supportate soltanto per la connessione DirectQuery.
Autorizzazioni
Per abilitare e configurare le aggregazioni automatiche, è necessario essere il proprietario del modello. Gli amministratori dell'area di lavoro possono assumere il ruolo di proprietari per configurare le impostazioni delle aggregazioni automatiche.
Configurazione delle aggregazioni automatiche
Le aggregazioni automatiche vengono configurate in Impostazioni del modello. La configurazione è semplice: basta abilitare il training delle aggregazioni automatiche e pianificare uno o più aggiornamenti. Prima di configurare le aggregazioni automatiche per il modello, leggere interamente questo articolo, che spiega bene il funzionamento delle aggregazioni automatiche e consente di decidere se le aggregazioni automatiche sono appropriate per l'ambiente in uso. Quando si è pronti per istruzioni dettagliate su come abilitare il training delle aggregazioni automatiche, configurare una pianificazione degli aggiornamenti e ottimizzare l'ambiente, vedere Configurare le aggregazioni automatiche.
Vantaggi
Con DirectQuery, ogni volta che un utente del modello apre un report o interagisce con una visualizzazione del report, le query Data Analysis Expressions (DAX) vengono passate al motore di query e quindi all'origine dati back-end come query SQL. L'origine dati deve calcolare e restituire risultati per ogni query. Rispetto ai modelli in modalità di importazione archiviati in memoria, i round trip dell'origine dati DirectQuery possono essere a elevato impiego di tempo e processi, causando spesso tempi di risposta delle query lenti nelle visualizzazioni dei report.
Se abilitate per un modello DirectQuery, le aggregazioni automatiche possono migliorare le prestazioni delle query del report evitando round trip delle query di origine dati. I risultati preaggregati delle query vengono restituiti automaticamente da una cache di aggregazioni in memoria anziché essere inviati e restituiti dall'origine dati. La quantità di dati preaggregati nella cache delle aggregazioni in memoria è una piccola parte della quantità di dati mantenuti effettivamente e delle tabelle di dettaglio nell'origine dati. Il risultato non è solo un miglioramento delle prestazioni delle query del report, ma anche la riduzione del carico nei sistemi di origine dati back-end. Con le aggregazioni automatiche, solo una piccola parte di report e query ad hoc che richiedono aggregazioni non incluse nella cache in memoria viene passata all'origine dati back-end, proprio come con la pura modalità DirectQuery.
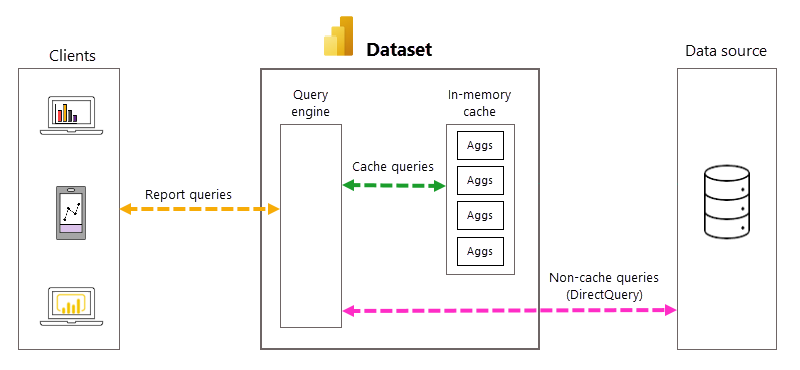
Gestione automatica di query e aggregazioni
Anche se le aggregazioni automatiche eliminano la necessità di creare tabelle di aggregazione definite dall'utente e semplificano notevolmente l'implementazione di una soluzione di dati preaggregata, una maggiore familiarità con i processi e le dipendenze sottostanti è utile per comprendere il funzionamento delle aggregazioni automatiche. Power BI si basa sulle operazioni seguenti per creare e gestire le aggregazioni automatiche.
Log di query
Power BI tiene traccia delle query di modelli e report utente in un log delle query. Per ogni modello, Power BI conserva i dati del log delle query di sette giorni. Ogni giorno viene eseguito il roll forward dei dati del log delle query. Il log delle query è sicuro e non è visibile agli utenti o tramite l'endpoint XMLA.
Operazioni di training
Durante la prima operazione di aggiornamento pianificato del modello per la frequenza selezionata (giorno o settimana), Power BI avvia prima un'operazione di training che valuta il log delle query per garantire che le aggregazioni presenti nella cache delle aggregazioni in memoria si adattino ai criteri di query che cambiano. Le tabelle delle aggregazioni in memoria vengono create, aggiornate o rimosse e le query speciali vengono inviate all'origine dati per determinare le aggregazioni da includere nella cache. I dati delle aggregazioni calcolate, tuttavia, non vengono caricati nella cache in memoria durante il training, ma vengono caricati durante l'operazione di aggiornamento successiva.
Ad esempio, se si sceglie una frequenza Giorno e la pianificazione viene aggiornata alle 4:00, alle 9:00, alle 14:00 e alle 19:00, solo l'aggiornamento delle 4:00 di ogni giorno includerà sia un'operazione di training che un'operazione di aggiornamento. Gli aggiornamenti pianificati successivi delle 9:00, delle 14:00 e delle 19:00 per quel giorno sono operazioni di solo aggiornamento che aggiornano le aggregazioni esistenti nella cache.
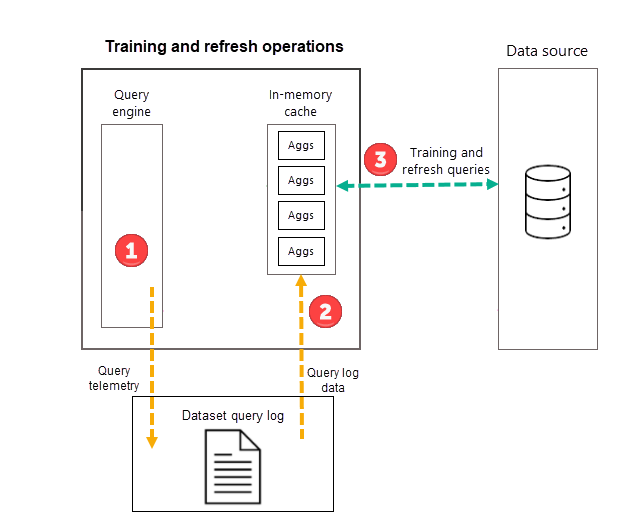
Mentre le operazioni di training valutano le query scadute dal log delle query, i risultati sono sufficientemente accurati per garantire il trattamento delle query future. Non esiste alcuna garanzia, tuttavia, che le query future verranno restituite dalla cache delle aggregazioni in memoria perché tali nuove query potrebbero essere diverse da quelle derivate dal log delle query. Le query che non sono restituite dalla cache delle aggregazioni in memoria vengono passate all'origine dati tramite DirectQuery. A seconda della frequenza e della priorità delle nuove query, le relative aggregazioni possono essere incluse nella cache delle aggregazioni in memoria con l'operazione di training successiva.
L'operazione di training ha un limite di tempo di 60 minuti. Se il training non è in grado di elaborare l'intero log delle query entro il limite di tempo, viene registrata una notifica nella cronologia degli aggiornamenti del modello e il training riprende all'avvio successivo. Il ciclo di training viene completato e sostituisce le aggregazioni automatiche esistenti quando viene elaborato l'intero log delle query.
Operazioni di aggiornamento
Come descritto in precedenza, dopo il completamento dell'operazione di training durante il primo aggiornamento pianificato per la frequenza selezionata, Power BI effettua un'operazione di aggiornamento che esegue query e carica i dati delle aggregazioni nuove e aggiornate nella cache delle aggregazioni in memoria e rimuove tutte le aggregazioni che non hanno più una priorità sufficiente (secondo quanto stabilito dall'algoritmo di training). Tutti gli aggiornamenti successivi per la frequenza Giorno o Settimana scelta sono operazioni di solo aggiornamento che eseguono query sull'origine dati per aggiornare i dati delle aggregazioni esistenti nella cache. Usando l'esempio precedente, gli aggiornamenti pianificati delle 9:00, delle 14:00 e delle 19:00 per quel giorno sono operazioni di solo aggiornamento.
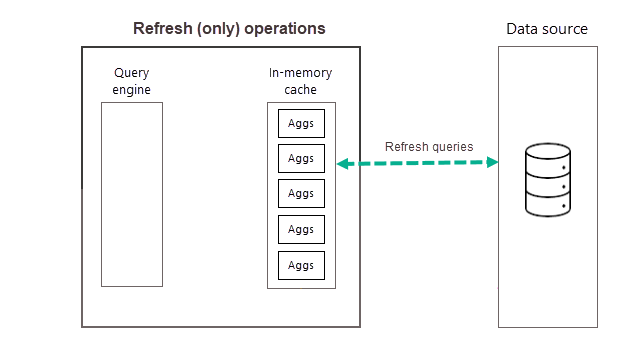
Aggiornamenti pianificati regolarmente durante il giorno (o la settimana) assicurano che i dati delle aggregazioni nella cache siano più aggiornati con i dati nell'origine dati back-end. Tramite Impostazioni del modello, è possibile pianificare fino a 48 aggiornamenti al giorno per garantire che le query dei report restituite dalla cache delle aggregazioni ottengano risultati in base ai dati aggiornati più recenti dell'origine dati back-end.
Attenzione
Le operazioni di training e aggiornamento sono a elevato utilizzo di processi e risorse sia per il servizio Power BI che per i sistemi di origine dati. Aumentando la percentuale di query che usano le aggregazioni, è necessario eseguire query e calcolare più aggregazioni dalle origini dati durante le operazioni di training e aggiornamento, aumentando la probabilità di un uso eccessivo delle risorse di sistema, causando potenziali timeout. Per altre informazioni, vedere Ottimizzazione.
Training su richiesta
Come accennato in precedenza, un ciclo di training potrebbe non essere completato entro i limiti di tempo di un singolo ciclo di aggiornamento dati. Per non attendere fino al successivo ciclo di aggiornamento pianificato che include il training, è anche possibile attivare il training delle aggregazioni automatiche su richiesta selezionando Esegui il training e aggiorna ora in Impostazioni del modello. Usando Esegui il training e aggiorna ora si attiva sia un'operazione di training che un'operazione di aggiornamento. Se necessario, controllare la cronologia degli aggiornamenti del modello per verificare se l'operazione corrente è stata completata prima di eseguire un'altra operazione di training e aggiornamento su richiesta.
Cronologia aggiornamenti
Ogni operazione di aggiornamento viene registrata nella cronologia degli aggiornamenti del modello. Vengono visualizzate informazioni importanti su ogni aggiornamento, incluso il numero di aggregazioni di memoria nella cache utilizzate per la percentuale di query configurata. Per visualizzare la cronologia degli aggiornamenti, nella pagina Impostazioni del modello selezionare Cronologia aggiornamenti. Per eseguire il drill-down in modo più approfondito, selezionare Mostra dettagli.
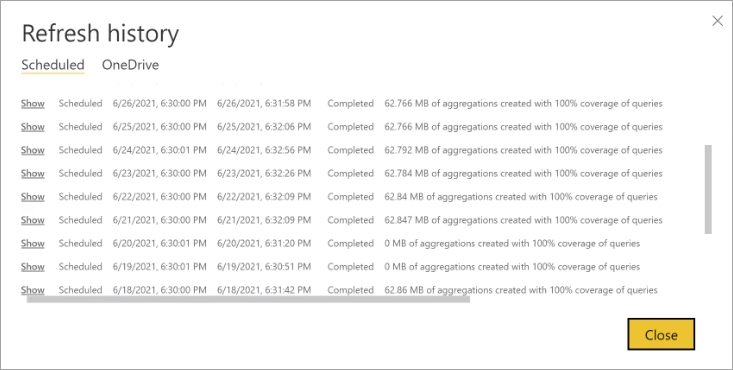
Controllando regolarmente la cronologia degli aggiornamenti, è possibile assicurarsi che le operazioni di aggiornamento pianificate vengano completate entro un periodo accettabile. Assicurarsi che le operazioni di aggiornamento vengano completate correttamente prima dell'inizio dell'aggiornamento pianificato successivo.
Errori di training e di aggiornamento
Mentre Power BI esegue le operazioni di training e aggiornamento durante il primo aggiornamento pianificato per la frequenza di giorno o settimana scelta, queste operazioni vengono implementate come transazioni separate. Se un'operazione di training non è in grado di elaborare completamente il log delle query entro i limiti di tempo, Power BI procederà all'aggiornamento delle aggregazioni esistenti (e delle tabelle normali in un modello composito) usando lo stato di training precedente. In questo caso la cronologia degli aggiornamenti indicherà che l'aggiornamento ha avuto esito positivo e il training riprenderà l'elaborazione del log delle query al successivo avvio del training. Le prestazioni delle query potrebbero essere meno ottimizzate se i criteri delle query dei report client sono stati modificati e le aggregazioni non sono state ancora regolate, ma il livello di prestazioni raggiunto dovrebbe comunque essere molto migliore rispetto a un puro modello DirectQuery senza aggregazioni.
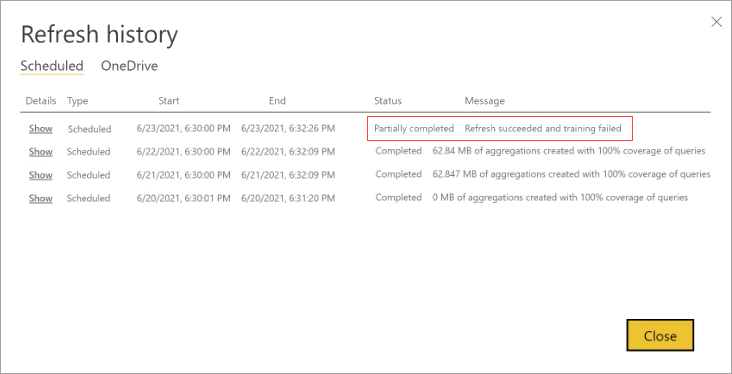
Se un'operazione di training richiede troppi cicli per completare l'elaborazione del log delle query, è consigliabile ridurre la percentuale di query che usano la cache delle aggregazioni in memoria in Impostazioni del modello. In questo modo si ridurrà il numero di aggregazioni create nella cache, ma verrà concesso più tempo per completare le operazioni di training e aggiornamento. Per altre informazioni, vedere Ottimizzazione.
Se il training ha esito positivo ma l'aggiornamento ha esito negativo, l'intero aggiornamento viene contrassegnato come Non riuscito perché il risultato è una cache delle aggregazioni in memoria non disponibile.
Quando si pianifica l'aggiornamento, è possibile specificare notifiche tramite posta elettronica in caso di errori di aggiornamento.
Aggregazioni automatiche e definite dall'utente
Le aggregazioni definite dall'utente in Power BI possono essere configurate manualmente in base alle tabelle aggregate nascoste nel modello. La configurazione delle aggregazioni definite dall'utente è spesso complessa e richiede un livello maggiore di capacità di modellazione dei dati e ottimizzazione delle query. Le aggregazioni automatiche, d'altra parte, eliminano questa complessità all'interno di un sistema basato sull'intelligenza artificiale. A differenza delle aggregazioni definite dall'utente che rimangono statiche, Power BI gestisce continuamente i log delle query e da tali log determina i modelli di query basati su algoritmi di modellazione predittiva di apprendimento automatico (ML). I dati preaggregati vengono calcolati e archiviati in memoria in base all'analisi dei criteri delle query. Con le aggregazioni automatiche, i modelli sono soggetti a ottimizzazione e training automatici. Man mano che i criteri delle query dei report client cambiano, le aggregazioni automatiche si regolano, assegnando priorità e memorizzando nella cache le aggregazioni usate più spesso.
Poiché le aggregazioni automatiche si basano sull'infrastruttura esistente di aggregazioni definite dall'utente, è possibile usare le aggregazioni sia definite dall'utente che automatiche nello stesso modello. Gli esperti di modellazione di dati qualificati possono definire le aggregazioni per le tabelle usando DirectQuery, Importa (con o senza Aggiornamento incrementale) o modalità Doppia archiviazione e allo stesso tempo ricevere i vantaggi di più aggregazioni automatiche per le query sulle connessioni DirectQuery che non raggiungono le tabelle delle aggregazioni definite dall'utente. Questa flessibilità consente di creare architetture bilanciate in grado di ridurre i carichi di query ed evitare i colli di bottiglia.
Le aggregazioni create nella cache in memoria dall'algoritmo di training delle aggregazioni automatiche vengono identificate come aggregazioni System. L'algoritmo di training crea ed elimina soltanto tali aggregazioni System mentre vengono analizzate le query di reporting e vengono apportate modifiche per mantenere le aggregazioni ottimali per il modello. Sia le aggregazioni definite dall'utente che quelle automatiche si aggiornano in occasione dell'aggiornamento. Solo le aggregazioni create dalle aggregazioni automatiche e contrassegnate come aggregazioni generate dal sistema sono incluse nell'elaborazione delle aggregazioni automatiche.
Memorizzazione delle query nella cache e aggregazioni automatiche
Power BI Premium supporta anche la memorizzazione delle query nella cache in Power BI Premium/Embedded per mantenere i risultati delle query. La memorizzazione delle query nella cache è una funzionalità diversa dalle aggregazioni automatiche. Con la memorizzazione delle query nella cache, Power BI Premium usa il suo servizio di memorizzazione nella cache locale per implementare la memorizzazione nella cache, mentre le aggregazioni automatiche vengono implementate a livello di modello. Con la memorizzazione delle query nella cache, il servizio memorizza nella cache solo le query per il caricamento iniziale della pagina del report, pertanto le prestazioni delle query non vengono migliorate quando gli utenti interagiscono con un report. Al contrario, le aggregazioni automatiche ottimizzano la maggior parte delle query del report tramite la pre-memorizzazione nella cache dei risultati delle query aggregate, incluse quelle generate quando gli utenti interagiscono con i report. Sia la memorizzazione delle query nella cache che le aggregazioni automatiche possono essere abilitate per un modello, ma probabilmente non è necessario.
Eseguire il monitoraggio con Azure Log Analytics
Azure Log Analytics (LA) è un servizio del Monitoraggio di Azure che Power BI può usare per salvare i log delle attività. Con la famiglia di prodotti del Monitoraggio di Azure è possibile raccogliere e analizzare i dati di telemetria e agire su di loro dagli ambienti Azure e locali. Offre l'archiviazione a lungo termine, un'interfaccia ad hoc per le query e l'accesso alle API per consentire l'esportazione e l'integrazione dei dati con altri sistemi. Per altre informazioni, vedere Uso di Azure Log Analytics in Power BI.
Se Power BI è configurato con un account Azure LA, come descritto in Configurazione di Azure Log Analytics per Power BI, è possibile analizzare la percentuale di riuscita delle aggregazioni automatiche. Tra le altre cose, è possibile determinare se le query del report ricevono una risposta dalla cache in memoria.
Per usare questa funzionalità, scaricare il modello PBIT e connetterlo all'account di analisi dei log, come descritto in questo post di blog di Power BI. Nel report è possibile visualizzare i dati in tre livelli diversi: vista Riepilogo, vista a livello di query DAX e vista a livello di query SQL.
L'immagine seguente mostra la pagina di riepilogo per tutte le query. Come si può notare, il grafico contrassegnato mostra la percentuale di query totali soddisfatte dalle aggregazioni e quelle che hanno dovuto utilizzare l'origine dati.
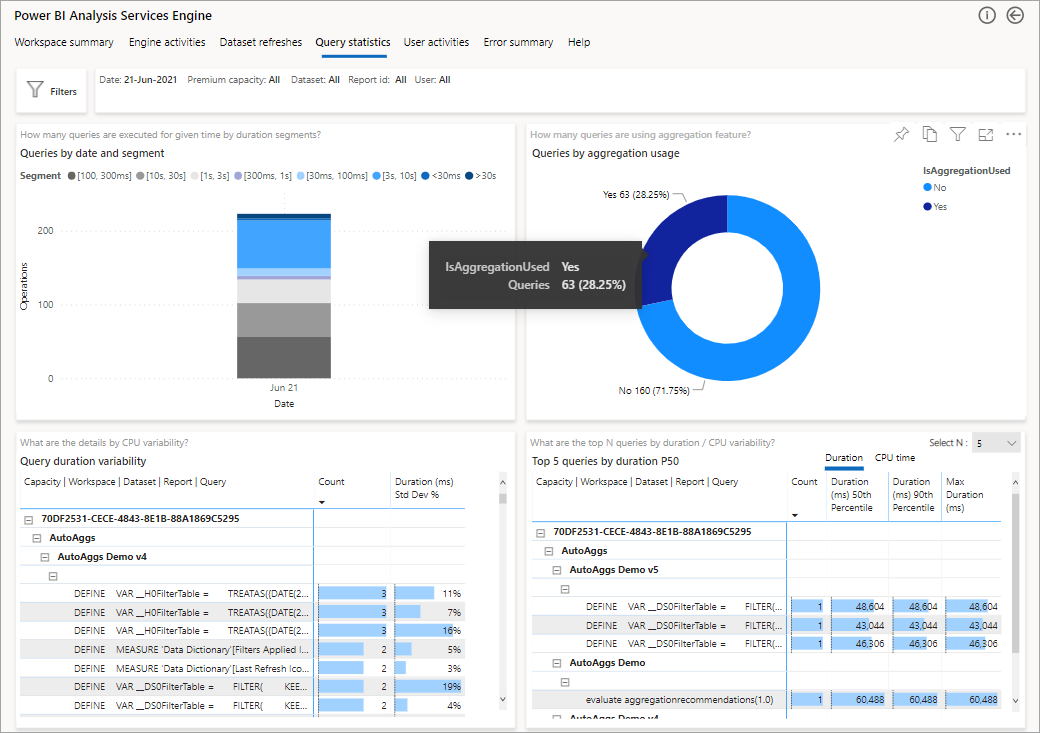
Il passaggio successivo di approfondimento consiste nell'esaminare l'uso delle aggregazioni a livello di query DAX. Fare clic con il pulsante destro del mouse su una query DAX nell'elenco (in basso a sinistra) >Drill-through>Cronologia delle query.
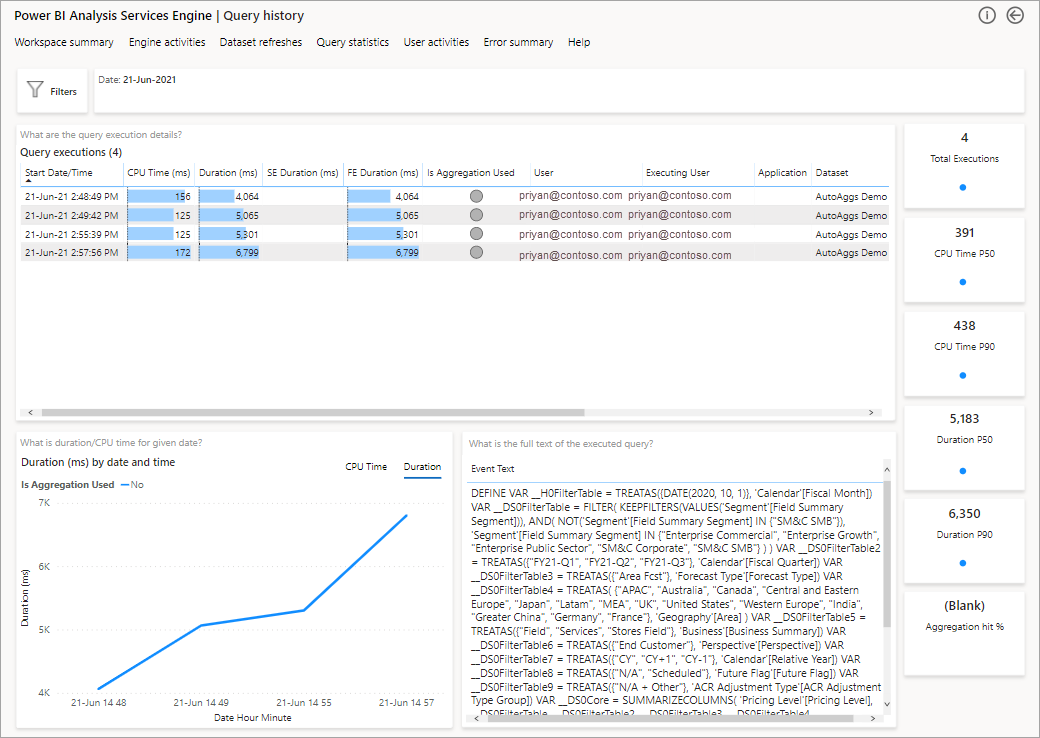
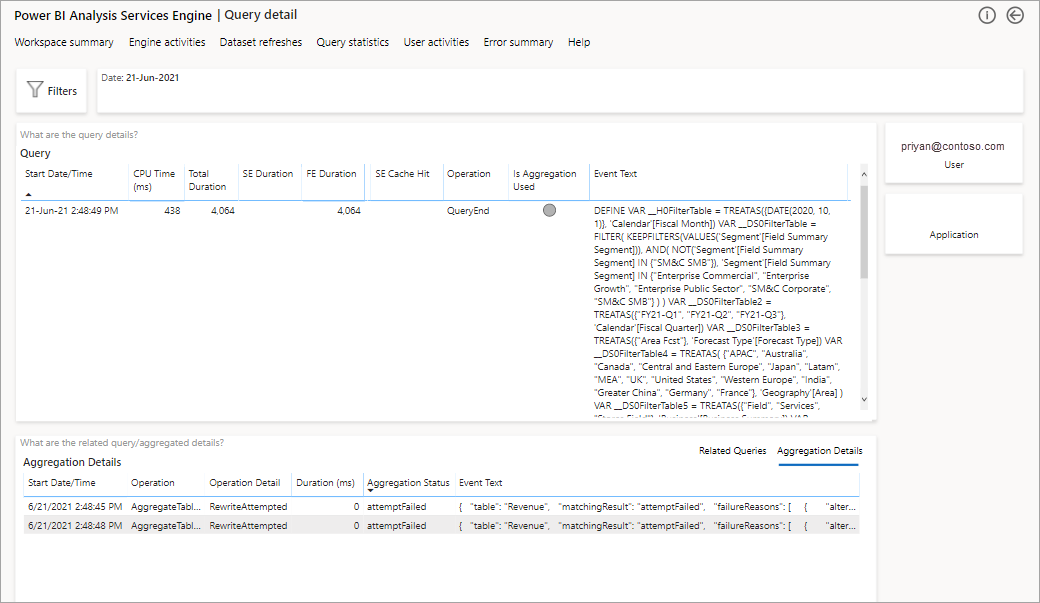
In questo modo verrà fornito un elenco di tutte le query pertinenti. Eseguire il drill-through al livello successivo per mostrare altri dettagli di aggregazione.
Application Lifecycle Management
Dallo sviluppo al test e dal test alla produzione, i modelli con aggregazioni automatiche abilitate hanno requisiti speciali per le soluzioni ALM.
Pipeline di distribuzione
Con le pipeline di distribuzione, Power BI può copiare i modelli con la relativa configurazione del modello dalla fase corrente alla fase di destinazione. Tuttavia, le aggregazioni automatiche devono essere reimpostate nella fase di destinazione perché le impostazioni non vengono trasferite dalla fase corrente a quella di destinazione. È anche possibile distribuire il contenuto a livello di codice usando le API REST delle pipeline di distribuzione. Per altre informazioni su questo processo, vedere Automatizzare la pipeline di distribuzione usando le API e DevOps.
Soluzioni ALM personalizzate
Se si usa una soluzione ALM personalizzata basata su endpoint XMLA, tenere presente che tale soluzione potrebbe essere in grado di copiare le tabelle delle aggregazioni generate dal sistema e create dall'utente nell'ambito dei metadati del modello. Tuttavia, nella fase di destinazione è necessario abilitare manualmente le aggregazioni automatiche dopo ogni passaggio della distribuzione. Power BI manterrà la configurazione se si sovrascrive un modello esistente.
Nota
Se si carica o si ripubblica un modello nell'ambito di un file di Power BI Desktop (con estensione pbix), le tabelle delle aggregazioni create dal sistema vengono perse perché Power BI sostituisce il modello esistente con tutti i relativi metadati e i dati nell'area di lavoro di destinazione.
Modifica di un modello
Dopo la modifica di un modello con aggregazioni automatiche abilitate tramite endpoint XMLA, ad esempio l'aggiunta o la rimozione di tabelle, Power BI mantiene tutte le eventuali aggregazioni esistenti e rimuove quelle che non sono più necessarie o pertinenti. Le prestazioni delle query potrebbero essere interessate fino all'attivazione della fase di training successiva.
Elementi dei metadati
I modelli con aggregazioni automatiche abilitate contengono tabelle di aggregazioni univoche generate dal sistema. Le tabelle delle aggregazioni non sono visibili agli utenti negli strumenti di creazione di report. Sono visibili tramite l'endpoint XMLA usando strumenti con librerie client di Analysis Services versione 19.22.5 e successive. Quando si usano modelli con aggregazioni automatiche abilitate, assicurarsi di aggiornare gli strumenti di amministrazione e modellazione dei dati all'ultima versione delle librerie client. Per SQL Server Management Studio (SSMS), eseguire l'aggiornamento alla versione di SSMS 18.9.2 o successiva. Le versioni precedenti di SSMS non sono in grado di enumerare le tabelle o di creare script per questi modelli.
Le tabelle delle aggregazioni automatiche sono identificate da una proprietà tabella SystemManaged, che è una novità del modello a oggetti tabulare (TOM) nelle librerie client di Analysis Services versione 19.22.5 e successive. Il frammento di codice seguente mostra la proprietà SystemManaged impostata su true per le tabelle delle aggregazioni automatiche e su false per le tabelle normali.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
L'esecuzione di questo frammento di codice genera le tabelle delle aggregazioni automatiche attualmente incluse nel modello in una console.
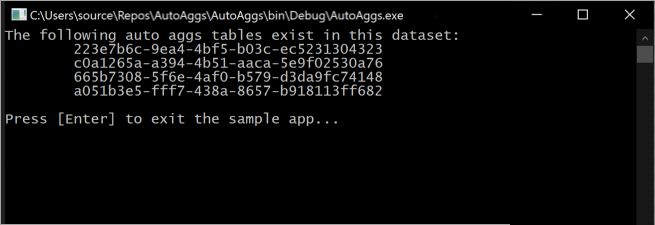
Tenere presente che le tabelle delle aggregazioni cambiano costantemente man mano che le operazioni di training determinano le aggregazioni ottimali da includere nella cache delle aggregazioni in memoria.
Importante
Power BI gestisce completamente gli oggetti delle tabelle delle aggregazioni automatiche generate dal sistema. Non eliminare e non modificare manualmente queste tabelle. Questa operazione può causare una riduzione delle prestazioni.
Power BI gestisce la configurazione del modello all'esterno del modello. La presenza di una tabella delle aggregazioni gestite dal sistema in un modello non significa necessariamente che il modello sia abilitato per il training delle aggregazioni automatiche. In altre parole, se si crea uno script da una definizione di modello completa per un modello con aggregazioni automatiche abilitate e si crea una nuova copia del modello (con nome/area di lavoro/capacità diversi), il nuovo modello risultante non è abilitato per il training delle aggregazioni automatiche. È comunque necessario abilitare il training delle aggregazioni automatiche per il nuovo modello in Impostazioni del modello.
Considerazioni e limitazioni
Quando si usano le aggregazioni automatiche, tenere presente quanto segue:
- Le aggregazioni non supportano il parametro di query M dinamico.
- Le query SQL generate durante la fase di training iniziale possono generare un carico significativo per il data warehouse. Se il training rimane incompleto ed è possibile verificare sul lato del data warehouse che le query vadano in timeout, valutare la possibilità di aumentare temporaneamente le prestazioni del data warehouse per soddisfare la domanda di training.
- Le aggregazioni archiviate nella cache delle aggregazioni in memoria potrebbero non essere calcolate sui dati più recenti dell'origine dati. A differenza del puro DirectQuery e più similmente alle normali tabelle di importazione, esiste una latenza tra gli aggiornamenti nell'origine dati e i dati delle aggregazioni archiviati nella cache delle aggregazioni in memoria. Anche se sarà sempre presente un certo grado di latenza, può essere mitigato tramite una pianificazione efficace degli aggiornamenti.
- Per ottimizzare ulteriormente le prestazioni, impostare tutte le tabelle delle dimensioni su Modalità doppia e lasciare le tabelle fact in modalità DirectQuery.
- Le aggregazioni automatiche non sono disponibili con Power BI Pro, Azure Analysis Services o SQL Server Analysis Services.
- Power BI non supporta il download di modelli con le aggregazioni automatiche abilitate. Se è stato caricato o pubblicato un file di Power BI Desktop (con estensione pbix) in Power BI e quindi sono state abilitate le aggregazioni automatiche, non è più possibile scaricare il file PBIX. Assicurarsi di mantenere una copia del file PBIX in locale.
- Le aggregazioni automatiche con tabelle esterne in Azure Synapse Analytics non sono supportate. È possibile enumerare le tabelle esterne in Synapse usando la query SQL seguente:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Le aggregazioni automatiche sono disponibili solo per i modelli che usano metadati avanzati. Per abilitare le aggregazioni automatiche per un modello meno recente, aggiornare prima il modello a metadati avanzati. Per altre informazioni, vedere Uso dei metadati avanzati del modello.
- Non abilitare le aggregazioni automatiche se l'origine dati DirectQuery è configurata per il Single Sign-On e usa visualizzazioni dati dinamiche o controlli di sicurezza per limitare i dati a cui un utente può accedere. Le aggregazioni automatiche non sono a conoscenza di questi controlli a livello di origine dati, il che rende impossibile garantire la correttezza dei dati forniti per ogni singolo utente. Il training registra un avviso nella cronologia degli aggiornamenti spiegando che è stata rilevata un'origine dati configurata per il Single Sign-On e che sono state ignorate le tabelle che usano questa origine dati. Se possibile, disabilitare l'SSO per queste origini dati per sfruttare appieno le prestazioni ottimizzate delle query che le aggregazioni automatiche possono fornire.
- Non abilitare le aggregazioni automatiche se il modello contiene solo tabelle ibride per evitare un sovraccarico di elaborazione non necessario. Una tabella ibrida usa sia le partizioni di importazione che una partizione DirectQuery. Uno scenario comune è l'aggiornamento incrementale con dati in tempo reale in cui una partizione DirectQuery recupera le transazioni dall'origine dati che si sono verificate dopo l'ultimo aggiornamento dei dati. Tuttavia, Power BI importa le aggregazioni durante l'aggiornamento. Le aggregazioni automatiche non possono includere le transazioni che si sono verificate dopo l'ultimo aggiornamento dei dati. Il training registra un avviso nella cronologia degli aggiornamenti spiegando che sono state rilevate e ignorate tabelle ibride.
- Le colonne calcolate non vengono considerate per le aggregazioni automatiche. Se si usa una colonna calcolata in modalità DirectQuery, ad esempio usando la funzione
COMBINEVALUESDAX per creare una relazione basata su più colonne di due tabelle DirectQuery, le query del report corrispondenti non raggiungeranno la cache delle aggregazioni in memoria. - Le aggregazioni automatiche sono disponibili solo nel servizio Power BI. Power BI Desktop non crea tabelle di aggregazioni generate dal sistema.
- Se si modificano i metadati di un modello con aggregazioni automatiche abilitate, le prestazioni delle query potrebbero peggiorare fino all'attivazione del processo di training successivo. Come procedura consigliata, rimuovere le aggregazioni automatiche, apportare le modifiche e quindi ripetere il training.
- Non modificare e non eliminare le tabelle di aggregazioni generate dal sistema, a meno che non siano state disattivate le aggregazioni automatiche e non si stia ripulendo il modello. Il sistema si assume la responsabilità di gestire questi oggetti.
Community
Power BI ha una vivace community in cui MVP, professionisti BI e colleghi condividono competenze in gruppi di discussione, video, blog e altro ancora. Quando si apprendono informazioni sulle aggregazioni automatiche, assicurarsi di consultare queste altre risorse: