Aggregazioni definite dall'utente
Le aggregazioni in Power BI possono migliorare le prestazioni delle query su modelli semantici DirectQuery di grandi dimensioni. Usando le aggregazioni, i dati vengono memorizzati nella cache a livello aggregato in memoria. Le aggregazioni in Power BI possono essere configurate manualmente nel modello di dati, come descritto in questo articolo. Per le sottoscrizioni Premium, abilitando automaticamente la funzionalità Aggregazioni automatiche nelle impostazioni del modello.
Creazione di tabelle di aggregazione
A seconda del tipo di origine dati, è possibile creare una tabella di aggregazione nell'origine dati come tabella o vista, query nativa. Per ottenere prestazioni ottimali, creare una tabella di aggregazione come tabella di importazione creata in Power Query. Usare quindi la finestra di dialogo Gestisci aggregazioni in Power BI Desktop per definire le aggregazioni per colonne di aggregazione con riepilogo, tabella dei dettagli e proprietà delle colonne di dettaglio.
Le origini dati dimensionali, ad esempio data warehouse e data mart, possono usare le aggregazioni basate su relazioni. Le origini Big Data basate su Hadoop spesso basano le aggregazioni su colonne GroupBy. Questo articolo descrive le comuni differenze di modellazione dei dati di Power BI per ogni tipo di origine dati.
Gestire le aggregazioni
Nel riquadro Dati di qualsiasi visualizzazione di Power BI Desktop, fare clic con il pulsante destro del mouse sulla tabella delle aggregazioni, quindi selezionare Gestisci aggregazioni.
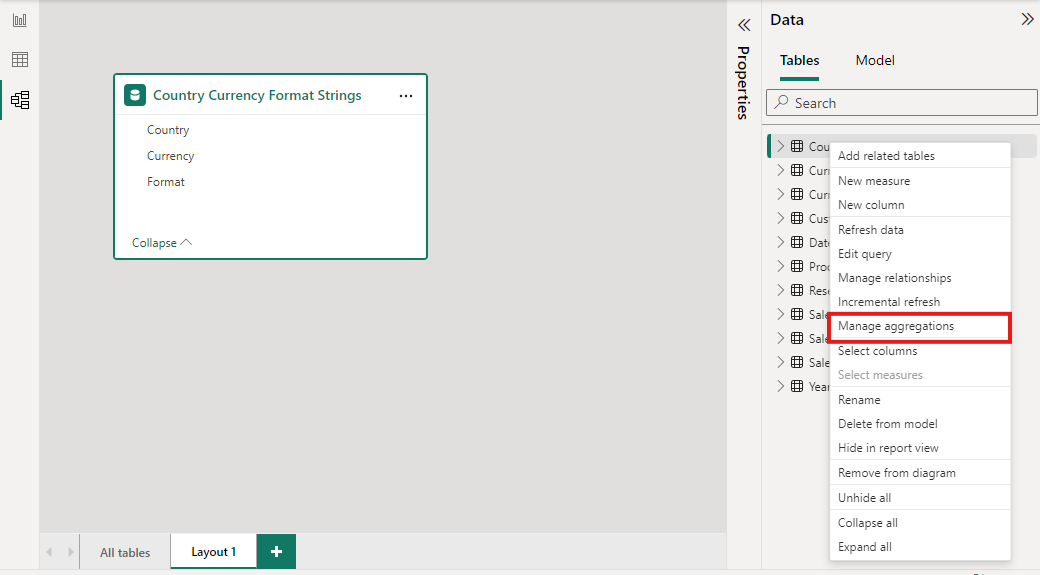
La finestra di dialogo Gestisci aggregazioni mostra una riga per ogni colonna della tabella, in cui è possibile specificare il comportamento di aggregazione. Nell'esempio seguente le query sulla tabella dei dettagli Sales vengono reindirizzate internamente alla tabella delle aggregazioni Sales Agg.
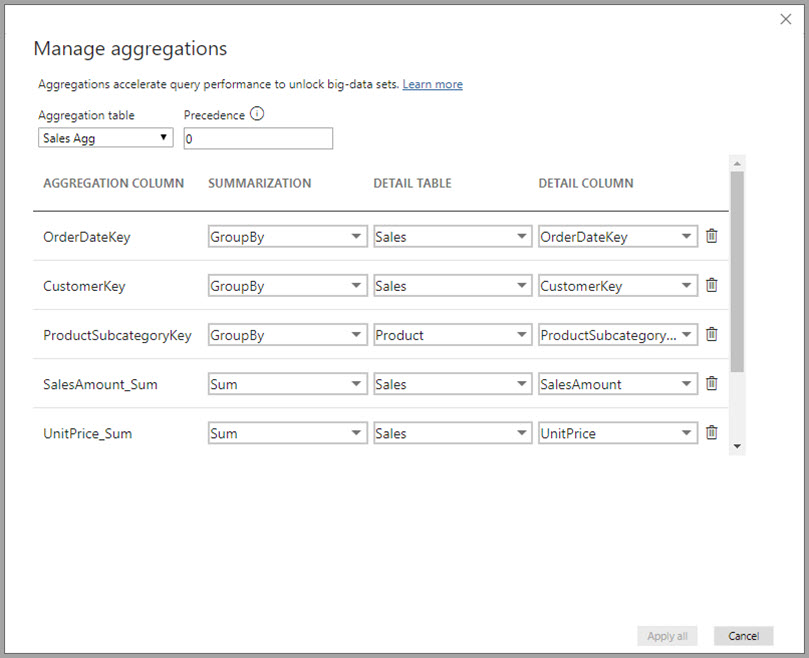
In questo esempio di aggregazione basata su relazioni le voci GroupBy sono facoltative. A eccezione di DISTINCTCOUNT, non influiscono sul comportamento di aggregazione e servono soprattutto a migliorare la leggibilità. Senza le voci GroupBy, le aggregazioni verrebbero comunque raggiunte in base alle relazioni, a differenza di quanto accade nell'esempio dei Big Data più avanti in questo articolo, in cui le voci GroupBy sono necessarie.
Validations
La finestra di dialogo Gestisci aggregazioni applica le convalide:
- Colonna dettagli deve avere lo stesso tipo di dati di Colonna aggregazioni, eccettuato per le funzioni Conteggio e Conta righe della tabella in Riepilogo. Conteggio e Conta righe della tabella sono disponibili solo per le colonne delle aggregazioni di tipo Integer e non richiedono un tipo di dati corrispondente.
- Le aggregazioni concatenate che coprono tre o più tabelle non sono consentite. Ad esempio, le aggregazioni in Tabella A non possono fare riferimento a una Tabella B contenente aggregazioni che fanno riferimento a una Tabella C.
- Le aggregazioni duplicate, in cui due voci usano la stessa funzione di Riepilogo e fanno riferimento alla stessa Tabella dettagli e Colonna dettagli, non sono consentite.
- La Tabella dettagli deve usare la modalità di archiviazione DirectQuery, non Import.
- Il raggruppamento in base a una colonna di chiave esterna usata da una relazione inattiva e l'uso della funzione USERELATIONSHIP per i riscontri di aggregazione non sono supportati.
- Le aggregazioni basate sulle colonne GroupBy possono usare relazioni tra tabelle di aggregazione, ma la creazione di relazioni tra tabelle di aggregazione non è supportata in Power BI Desktop. Se necessario, è possibile creare relazioni tra tabelle di aggregazione usando uno strumento di terze parti o una soluzione di scripting tramite endpoint XML for Analysis (XMLA).
La maggior parte delle convalide vengono applicate disabilitando i valori dell'elenco a discesa e visualizzando il testo esplicativo nella descrizione comando.
Le tabelle di aggregazione sono nascoste
Gli utenti con accesso in sola lettura al modello non possono eseguire query sulle tabelle di aggregazione. L’accesso di sola lettura evita problemi di sicurezza quando viene usato con la sicurezza a livello di riga. Gli utenti finali e le query fanno riferimento alla tabella dei dettagli, non alla tabella delle aggregazioni e non è necessario che siano a conoscenza della tabella delle aggregazioni.
Per questo motivo, le tabelle delle aggregazioni sono nascoste nella visualizzazione Report. Se la tabella non è già nascosta, la finestra di dialogo Gestisci aggregazioni la imposta come nascosta quando si seleziona Applica tutto.
Modalità di archiviazione
La funzionalità di aggregazione interagisce con le modalità di archiviazione a livello di tabella. Le tabelle di Power BI possono usare le modalità di archiviazione DirectQuery, Import o Dual. DirectQuery esegue una query direttamente sul back-end, mentre Import memorizza nella cache i dati in memoria e invia le query ai dati memorizzati nella cache. Tutte le origini dati Import e DirectQuery non multidimensionali di Power BI possono usare le aggregazioni.
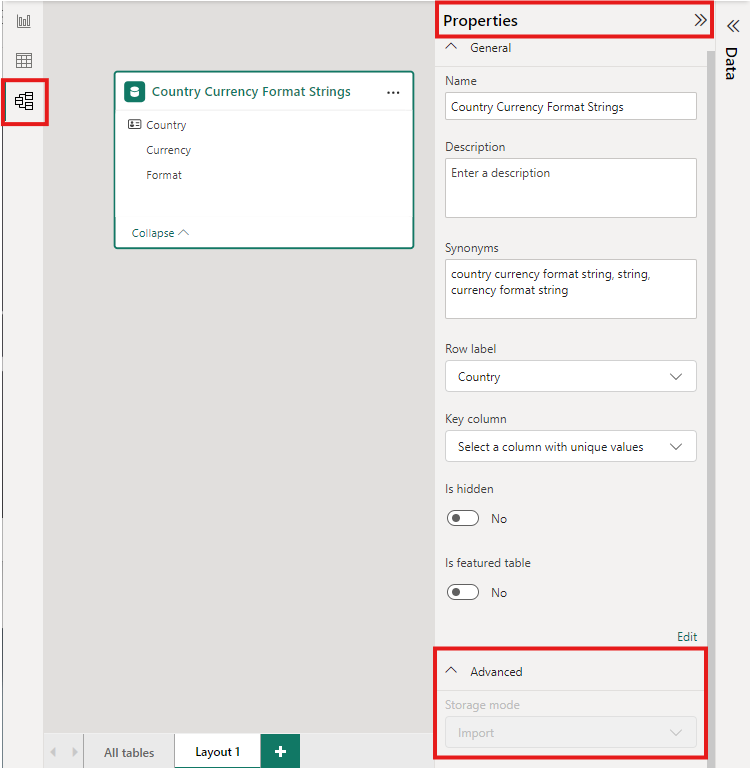
Per impostare la modalità di archiviazione di una tabella aggregata su Import per velocizzare le query, selezionare la tabella aggregata nella visualizzazione Modello di Power BI Desktop. Nel riquadro Proprietà espandere Avanzate e nell'elenco a discesa Modalità di archiviazione selezionare Import. La modifica dell'importazione è irreversibile.
Per ulteriori informazioni sulle modalità di archiviazione delle tabelle, vedere Gestire la modalità di archiviazione in Power BI Desktop.
Sicurezza a livello di riga per le aggregazioni
Per il corretto funzionamento delle aggregazioni, le espressioni di sicurezza a livello di riga devono filtrare la tabella delle aggregazioni e la tabella dei dettagli.
Nell'esempio seguente l'espressione di sicurezza a livello di riga sulla tabella Geography funziona per le aggregazioni, perché Geography è presente sul lato del filtro delle relazioni con la tabella Sales e con la tabella Sales Agg. La sicurezza a livello di riga verrà applicata correttamente alle query che raggiungono la tabella di aggregazione e alle query che non la raggiungono.
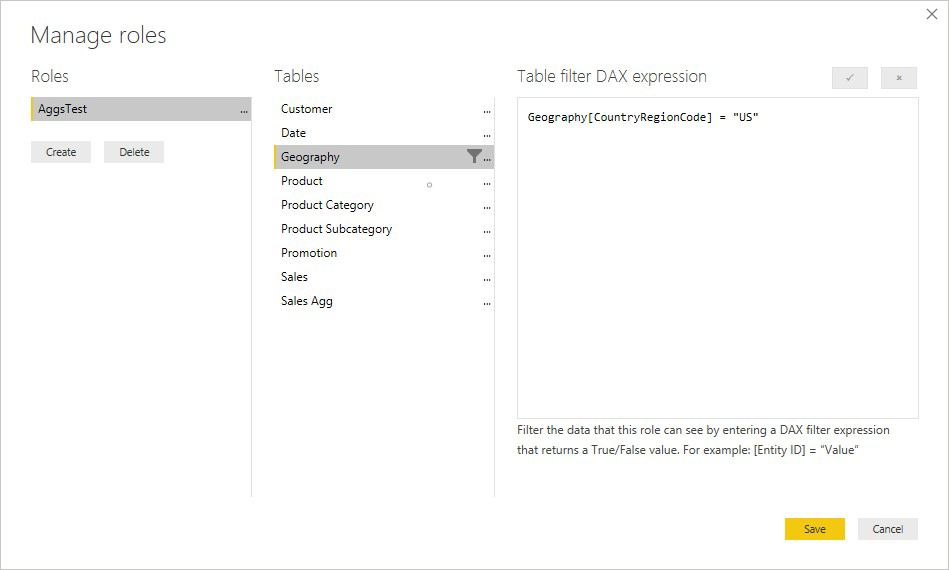
Un'espressione di sicurezza a livello di riga sulla tabella Product filtra soltanto la tabella dei dettagli Sales, non la tabella aggregata Sales Agg. Dal momento che la tabella di aggregazione è semplicemente un'altra rappresentazione dei dati presenti nella tabella dei dettagli, rispondere alle query dalla tabella delle aggregazioni non è un'operazione sicura se il filtro della sicurezza a livello di riga non può essere applicato. Non è consigliabile filtrare solo la tabella dei dettagli, perché le query degli utenti da questo ruolo non usufruiscono dei riscontri di aggregazione.
Un'espressione di sicurezza a livello di riga che filtra solo la tabella delle aggregazioni Sales Agg e non la tabella dei dettagli Sales non è consentita.
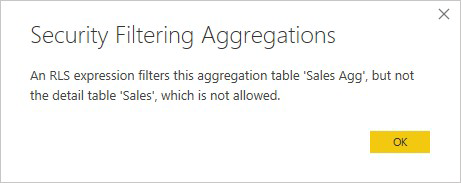
Per le aggregazioni basate sulle colonne GroupBy, un'espressione di sicurezza a livello di riga applicata alla tabella dei dettagli può essere usata per filtrare la tabella delle aggregazioni perché tutte le colonne GroupBy nella tabella delle aggregazioni sono previste dalla tabella dei dettagli. D'altra parte, un filtro di sicurezza a livello di riga sulla tabella delle aggregazioni non può essere applicato alla tabella dei dettagli, quindi non è consentito.
Aggregazione basata su relazioni
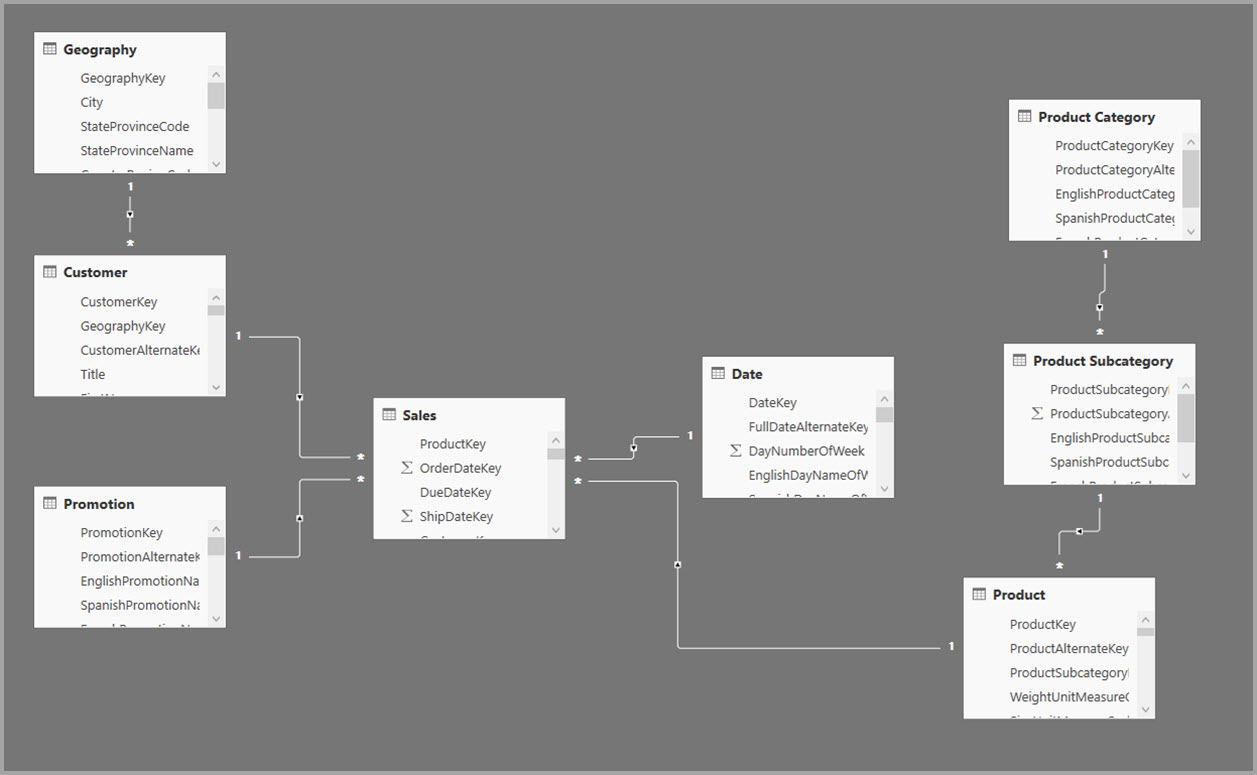
I modelli dimensionali in genere usano le aggregazioni basate su relazioni. I modelli di Power BI provenienti da data warehouse e data mart assomigliano a schemi star o snowflake e presentano relazioni tra tabelle delle dimensioni e tabelle dei fatti.
Nell'esempio seguente, il modello ottiene i dati da una singola origine dati. Le tabelle usano la modalità di archiviazione DirectQuery. La tabella dei fatti Sales contiene miliardi di righe. L'impostazione della modalità di archiviazione di Sales su Import per la memorizzazione nella cache comporterebbe un notevole sovraccarico della memoria e delle risorse.
Creare invece la tabella delle aggregazioni Sales Agg. Nella tabella Sales Agg il numero di righe è uguale alla somma di SalesAmount con i valori raggruppati per CustomerKey, DateKey e ProductSubcategoryKey. La tabella Sales Agg ha una granularità più elevata di Sales, quindi invece di miliardi di righe, può contenerne milioni, che è più facile gestire.
Se le tabelle delle dimensioni seguenti sono le più usate per le query con valore di business elevato, possono filtrare Sales Agg, usando relazioni uno-a-molti o molti-a-uno.
- Geografia
- Customer
- Data
- Product Subcategory
- Product Category
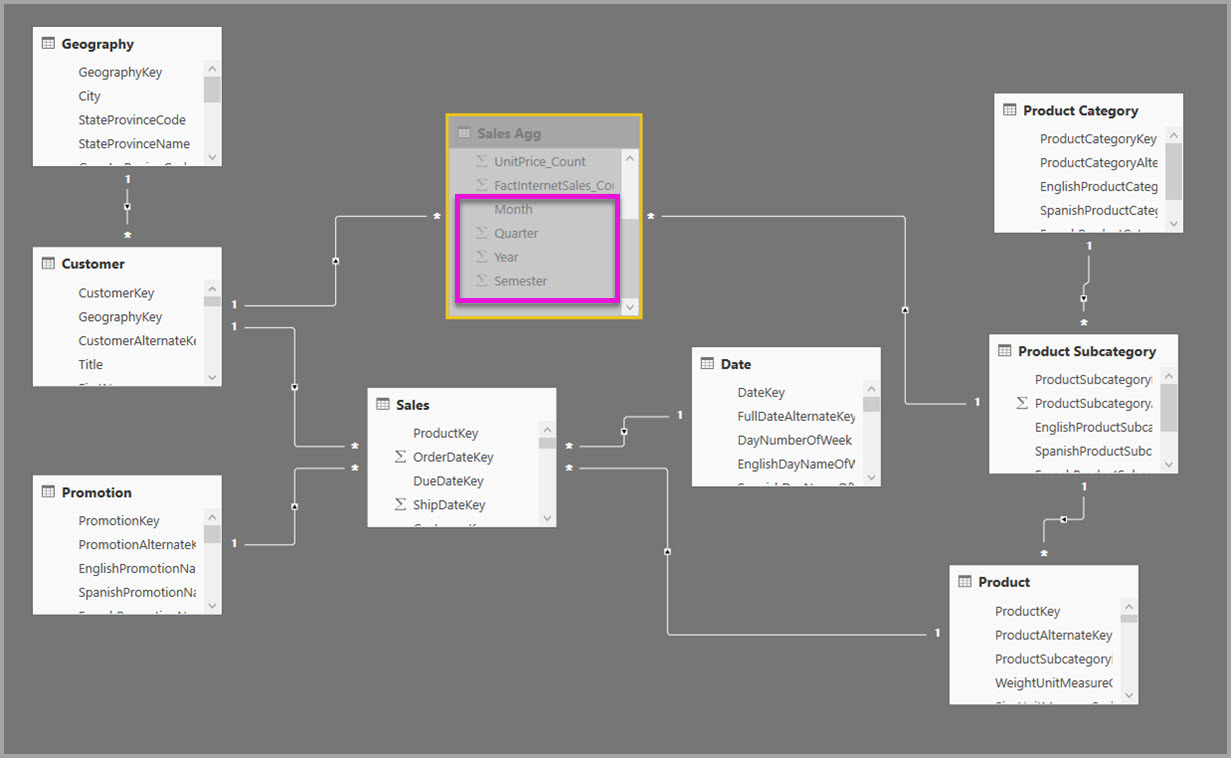
L'immagine seguente mostra questo modello.
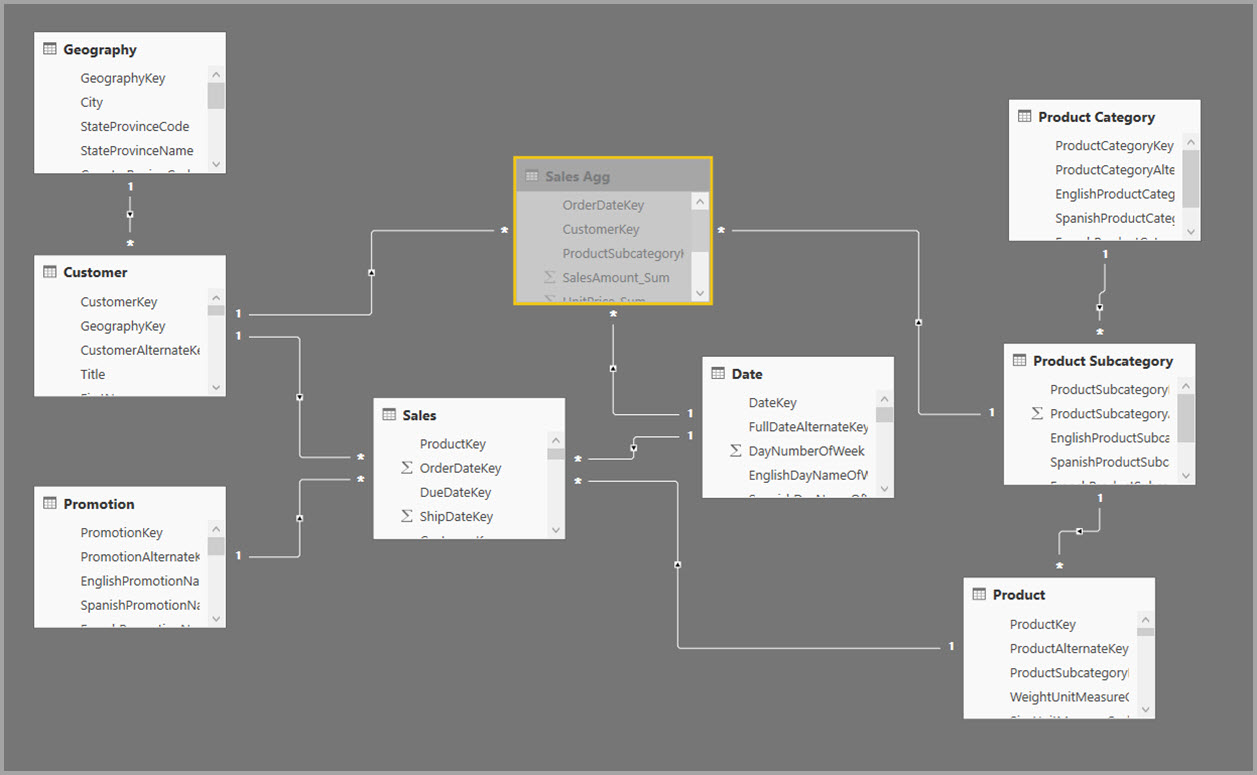
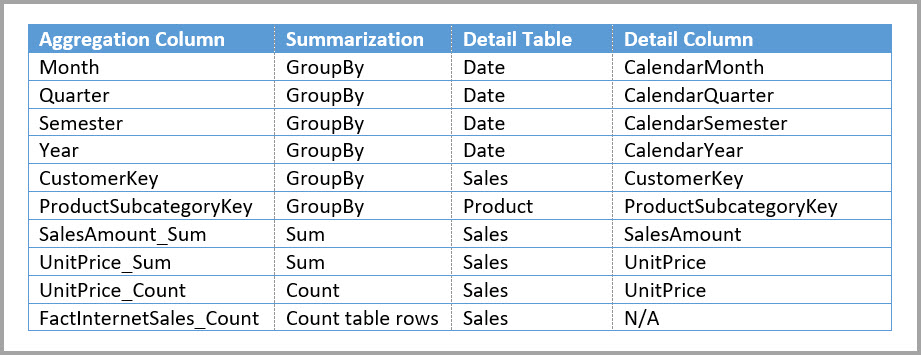
Nella tabella seguente vengono mostrate le aggregazioni per la tabella Sales Agg.
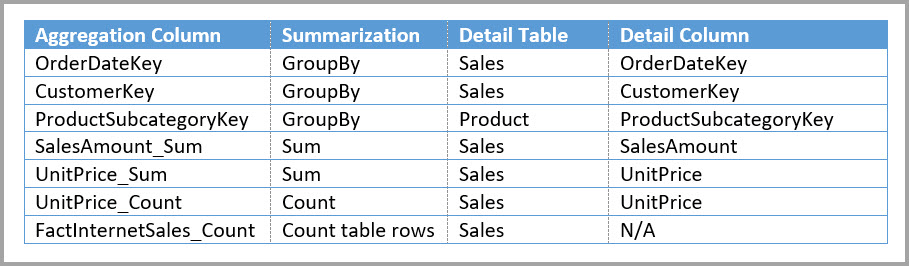
Nota
La tabella Sales Agg, come qualsiasi tabella, offre la flessibilità di essere caricata in vari modi. L'aggregazione può essere eseguita nel database di origine usando i processi ETL/ELT oppure usando l'espressione M per la tabella. La tabella aggregata può usare la modalità di archiviazione Import, con o senza aggiornamento incrementale per i modelli semantici, oppure la modalità DirectQuery ed essere ottimizzata per query veloci usando gli indici columnstore. Questa flessibilità consente di creare architetture bilanciate in cui il carico di query può essere ripartito per evitare i colli di bottiglia.
Impostando la modalità di archiviazione della tabella Sales Agg aggregata su Import, si apre una finestra di dialogo che informa che le tabelle delle dimensioni correlate possono essere impostate sulla modalità di archiviazione Dual.
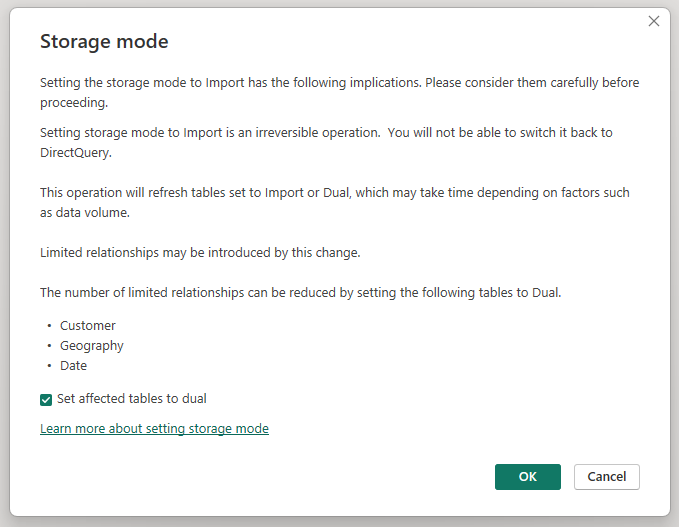
L'impostazione delle tabelle delle dimensioni correlate su Dual consente di usare la modalità Import o DirectQuery, a seconda della sottoquery. Nell'esempio:
- Le query con cui si aggregano le metriche della tabella Sales Agg in modalità Import e che raggruppano i valori in base a uno o più attributi delle tabelle Dual correlate possono essere restituite dalla cache in memoria.
- Le query con cui si aggregano le metriche dalla tabella Sales DirectQuery e che raggruppano i valori in base a uno o più attributi delle tabelle Dual correlate, possono essere restituite in modalità DirectQuery. La logica di query, che include l'operazione GroupBy, viene passata al database di origine.
Per altre informazioni sulla modalità di archiviazione Dual, vedere Gestire la modalità di archiviazione in Power BI Desktop.
Relazioni normali e limitate
I riscontri delle aggregazioni basati sulle relazioni richiedono relazioni normali.
Le relazioni normali includono le combinazioni seguenti di modalità di archiviazione, in cui entrambe le tabelle provengono da una singola origine:
| Tabella sui lati molti | Tabella sul lato uno |
|---|---|
| Doppio | Doppio |
| Import | Importa o Doppia |
| DirectQuery | DirectQuery o Doppia |
Una relazione tra origini diverse è considerata normale esclusivamente se entrambe le tabelle sono impostate su Import. Le relazioni molti-a-molti sono sempre considerate limitate.
Per i riscontri di aggregazione tra origini diverse che non dipendono da relazioni, vedere Aggregazioni basate su colonne GroupBy.
Esempi di query di aggregazione basata su relazioni
La query seguente raggiunge l'aggregazione perché le colonne nella tabella Date sono al livello di granularità corretto per raggiungere l'aggregazione. La colonna SalesAmount usa l'aggregazione Sum.

La query seguente non raggiunge l'aggregazione. Nonostante richieda la somma di SalesAmount, la query esegue un'operazione GroupBy su una colonna della tabella Product, che non è al livello di granularità corretto per raggiungere l'aggregazione. Se si osservano le relazioni nel modello, una sottocategoria di prodotti può avere più righe Product. La query non potrebbe determinare il prodotto in cui eseguire l'aggregazione. In questo caso, la query torna alla modalità DirectQuery e invia una query SQL all'origine dati.

Le aggregazioni non servono solo per eseguire semplici calcoli come banali somme. Possono servire anche per eseguire calcoli complessi. Concettualmente, un calcolo complesso viene suddiviso in sottoquery per ogni SOMMA, MIN, MAX e COUNT. Ogni sottoquery viene valutata per determinare se può raggiungere l'aggregazione. Questa logica non risulta efficace in tutti i casi a causa dell'ottimizzazione del piano di query, ma in generale è applicabile. L'esempio seguente raggiunge l'aggregazione:

La funzione COUNTROWS può trarre vantaggio dalle aggregazioni. La query seguente raggiunge l'aggregazione perché per la tabella Sales è definita un'aggregazione di righe della tabella Count.

La funzione AVERAGE può trarre vantaggio dalle aggregazioni. La query raggiunge l'aggregazione perché AVERAGE viene trattata internamente come un'operazione SUM divisa per COUNT. Poiché la colonna UnitPrice dispone di aggregazioni definite per SUM e COUNT, l'aggregazione viene raggiunta.

In alcuni casi, la funzione DISTINCTCOUNT può trarre vantaggio dalle aggregazioni. La query seguente raggiunge l'aggregazione perché è presente una voce GroupBy per CustomerKey, che mantiene le specificità di CustomerKey nella tabella di aggregazione. Questa tecnica potrebbe comunque raggiungere la soglia delle prestazioni per la quale una quantità di valori distinct superiore a due - cinque milioni può influire sulle prestazioni delle query. Può tuttavia essere utile nelle situazioni in cui sono presenti miliardi di righe nella tabella dei dettagli, ma da due a cinque milioni di valori distinct nella colonna. In questo caso, l'operazione DISTINCTCOUNT può essere svolta più velocemente rispetto all'analisi della tabella con miliardi di righe, anche se è stata memorizzata nella cache in memoria.

Le funzioni di Business Intelligence per le gerarchie temporali di Data Analysis Expressions (DAX) sono compatibili con le aggregazioni. La query seguente raggiunge l'aggregazione perché la funzione DATESYTD genera una tabella di valori CalendarDay e la tabella di aggregazione è a un livello di granularità coperto per le colonne group-by nella tabella Date. Questo è un esempio di filtro con valori di tabella per la funzione CALCULATE, che può funzionare con le aggregazioni.

Aggregazione basata su colonne GroupBy
I modelli di big data basati su Hadoop hanno caratteristiche diverse rispetto ai modelli dimensionali. Per evitare join tra tabelle di grandi dimensioni, i modelli di Big Data spesso non usano le relazioni, ma denormalizzano gli attributi delle dimensioni in tabelle dei fatti. È possibile sbloccare questi modelli di Big Data di grandi dimensioni per l'analisi interattiva usando aggregazioni basate su colonne GroupBy.
La tabella seguente contiene la colonna numerica Movement da aggregare. Tutte le altre colonne sono gli attributi per il raggruppamento. La tabella contiene dati IoT e un elevato numero di righe. La modalità di archiviazione è DirectQuery. Le query sull'origine dati che eseguono l'aggregazione nell'intero modello sono lente a causa del volume elevato.
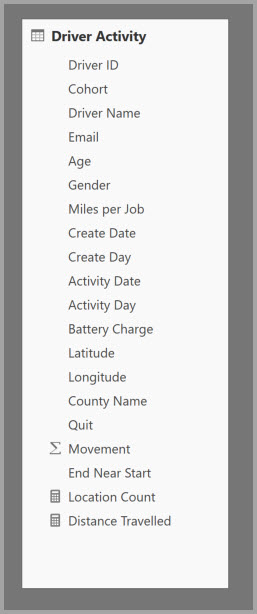
Per abilitare l'analisi interattiva in questo modello, è possibile aggiungere una tabella di aggregazione che esegue il raggruppamento in base alla maggior parte degli attributi, ma esclude gli attributi con cardinalità elevata, ad esempio longitudine e latitudine. Ciò riduce notevolmente il numero di righe ed è sufficientemente piccola da rientrare agevolmente in un'istanza di cache in memoria.
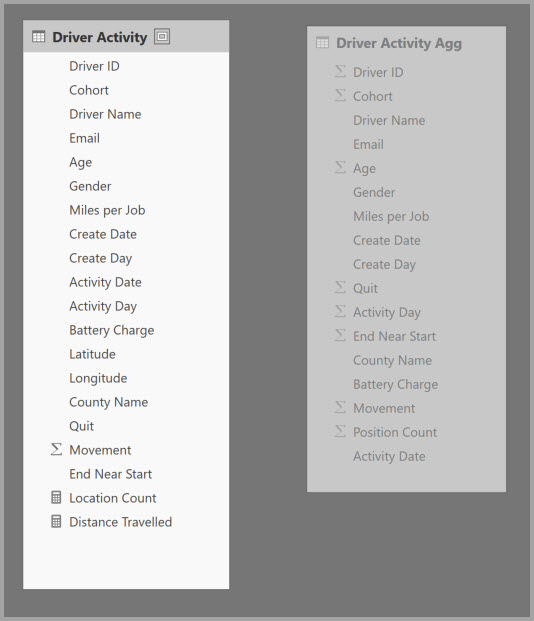
I mapping delle aggregazioni per la tabella Driver Activity Agg vengono definiti nella finestra di dialogo Gestisci aggregazioni.
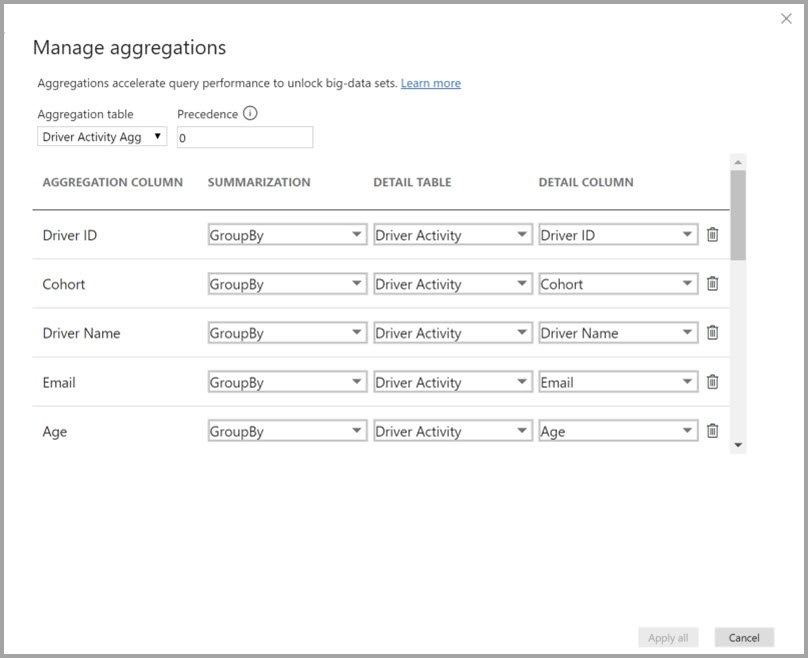
Nelle aggregazioni basate su colonne GroupBy, le voci GroupBy non sono facoltative. Senza di esse, le aggregazioni non vengono raggiunte. Non è come usare le aggregazioni basate su relazioni, dove le voci GroupBy sono facoltative.
La tabella seguente mostra le aggregazioni per la tabella Driver Activity Agg.
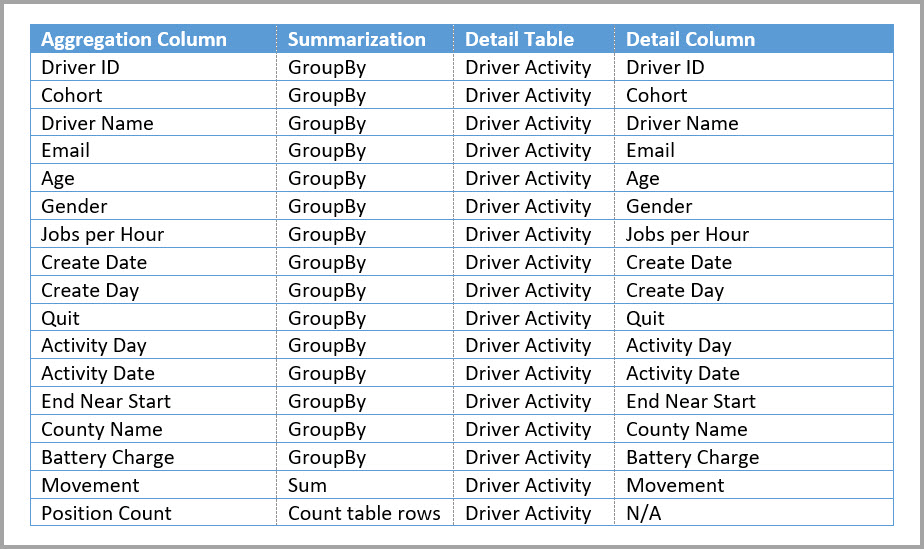
È possibile impostare la modalità di archiviazione della tabella aggregata Driver Activity Agg su Import.
Esempio di query di aggregazione GroupBy
La query seguente raggiunge l'aggregazione perché la colonna Activity Date è coperta dalla tabella delle aggregazioni. La funzione COUNTROWS usa l'aggregazione Conta righe della tabella.

In particolare per i modelli che contengono attributi di filtro nelle tabelle dei fatti, è consigliabile usare le aggregazioni Conta righe della tabella. Power BI può inviare query al modello usando COUNTROWS nei casi in cui non è esplicitamente richiesto dall'utente. Ad esempio, la finestra di dialogo Filtri mostra il numero di righe per ogni valore.
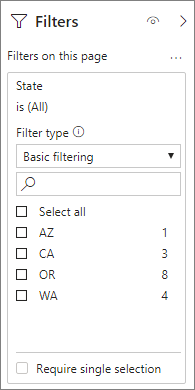
Tecniche di aggregazione combinate
È possibile combinare le tecniche delle relazioni e delle colonne GroupBy per le aggregazioni. Le aggregazioni basate su relazioni possono richiedere che le tabelle con le dimensioni denormalizzate vengano suddivise in più tabelle. Se questo risulta dispendioso o poco efficiente per alcune tabelle delle dimensioni, è possibile replicare gli attributi necessari nella tabella delle aggregazioni per tali dimensioni e usare le relazioni per le altre.
Il modello seguente, ad esempio, replica i valori Month, Quarter, Semester e Year nella tabella Sales Agg. Non esistono relazioni tra Sales Agg e la tabella Date, ma sono presenti relazioni con Customer e Product Subcategory. La modalità di archiviazione di Sales Agg è Import.
La tabella seguente mostra le voci impostate nella finestra di dialogo Gestisci aggregazioni della tabella Sales Agg. Le voci GroupBy in cui Date è la tabella dei dettagli sono obbligatorie per raggiungere le aggregazioni per le query che eseguono il raggruppamento in base agli attributi Date. Come nell'esempio precedente, le voci GroupBy per CustomerKey e ProductSubcategoryKey non influiscono sui riscontri delle aggregazioni, fatta eccezione per DISTINCTCOUNT, a causa della presenza di relazioni.
Esempi di query di aggregazione combinate
La query seguente raggiunge l'aggregazione perché la tabella delle aggregazioni copre CalendarMonth e CategoryName è accessibile tramite le relazioni uno-a-molti. SalesAmount usa l'aggregazione SUM.

La query seguente non raggiunge l'aggregazione perché la tabella delle aggregazioni non copre CalendarDay.

La seguente query di Business Intelligence per le gerarchie temporali non raggiunge l'aggregazione perché la funzione DATESYTD genera una tabella di valori CalendarDay e la tabella delle aggregazioni non copre CalendarDay.

Precedenza di aggregazione
La precedenza di aggregazione consente a più tabelle di aggregazione di essere considerate da una singola sottoquery.
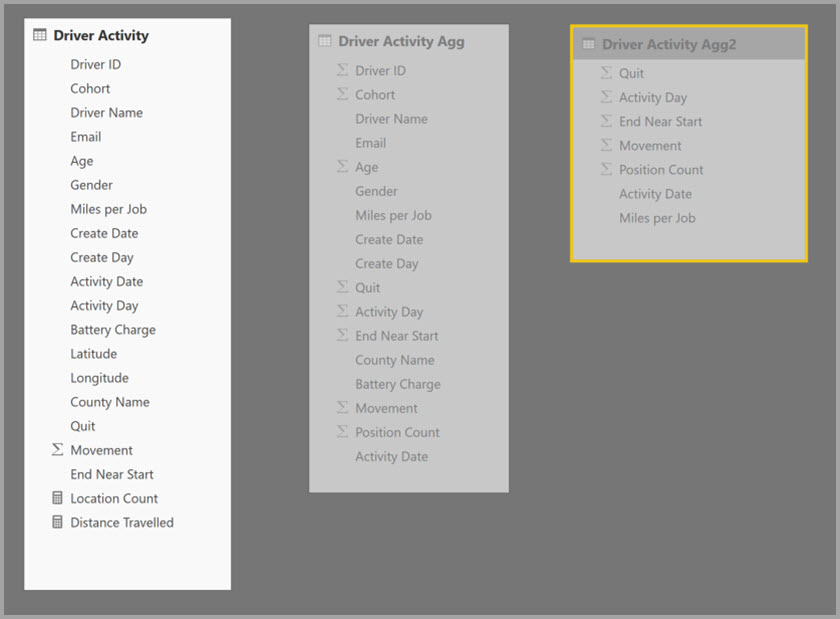
L'esempio seguente è un modello composito contenente più origini:
- La tabella in modalità DirectQuery Driver Activity contiene oltre un trilione di righe di dati IoT originati da un sistema per Big Data. Serve query drill-through per visualizzare singole letture IoT in contesti filtro controllati.
- La tabella Driver Activity Agg è una tabella di aggregazione intermedia con modalità DirectQuery. Contiene oltre un miliardo di righe in Azure Synapse Analytics (precedentemente SQL Data Warehouse) ed è ottimizzata all'origine tramite indici columnstore.
- La tabella Driver Activity Agg2 di tipo Import ha una granularità molto elevata perché gli attributi group-by sono pochi e con cardinalità bassa. Il numero di righe potrebbe essere di appena qualche migliaio, pertanto la tabella potrebbe stare facilmente in un'istanza di cache in memoria. Poiché accade che questi attributi vengano utilizzati da un pannello personale di alto profilo, le query che fanno riferimento a essi devono essere più veloci possibile.
Nota
Le tabelle delle aggregazioni DirectQuery che usano un'origine dati diversa dalla tabella dei dettagli sono supportate solo se la tabella delle aggregazioni proviene da un'origine SQL Server, Azure SQL o Azure Synapse Analytics (precedentemente SQL Data Warehouse).
Il footprint della memoria di questo modello è relativamente piccolo, ma sblocca un modello di grandi dimensioni. Rappresenta un'architettura bilanciata perché distribuisce il carico di query tra i componenti dell'architettura e li utilizza in base ai punti di forza.
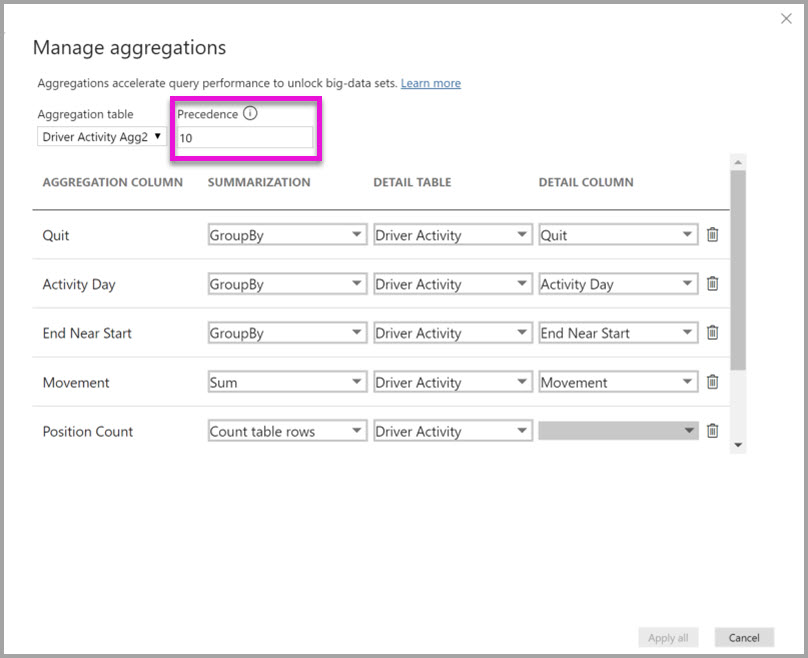
La finestra di dialogo Aggregazioni gestite per Driver Activity Agg2 imposta il campo Precedenza su 10, ovvero su un valore più elevato che per Driver Activity Agg. L'impostazione di precedenza più elevata indica che le query che usano le aggregazioni considerano prima Driver Activity Agg2. Le sottoquery il cui livello di granularità non consente di ottenere una risposta da Driver Activity Agg2 prendono in considerazione Driver Activity Agg. Le query dettagli a cui non può rispondere nessuna delle tabelle di aggregazione possono essere indirizzate a Driver Activity.
La tabella specificata nella colonna Tabella dettagli è Driver Activity, non Driver Activity Agg, perché le aggregazioni concatenate non sono consentite.
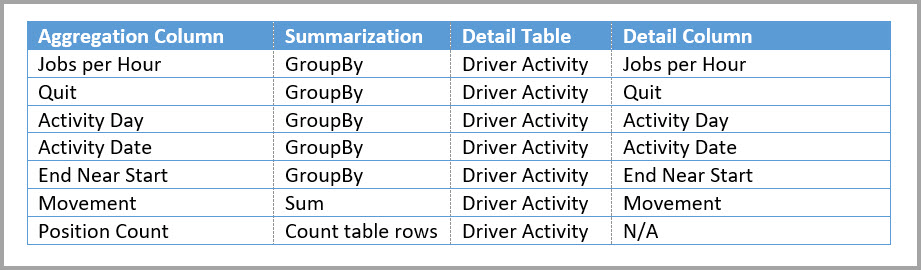
La tabella seguente mostra le aggregazioni per la tabella Driver Activity Agg2.
Rilevare se le query raggiungono o meno le aggregazioni
SQL Profiler può rilevare se le query vengono restituite dal motore di archiviazione della cache in memoria o se ne viene eseguito il push nell'origine dati da DirectQuery. È possibile usare lo stesso processo per rilevare se le aggregazioni sono raggiunte. Per altre informazioni, vedere Query con o senza riscontri nella cache.
SQL Profiler fornisce anche l'evento esteso Query Processing\Aggregate Table Rewrite Query.
Il frammento di codice JSON seguente mostra un esempio dell'output dell'evento generato quando viene utilizzata un'aggregazione.
- matchingResult indica che la sottoquery ha usato un'aggregazione.
- dataRequest mostra le colonne GroupBy e le colonne aggregate usate dalla sottoquery.
- mapping mostra le colonne nella a cui è stato eseguito il mapping tabella di aggregazione.

Mantenere sincronizzate le cache
Le aggregazioni in cui le modalità di archiviazione DirectQuery, Import e/o Dual sono combinate possono restituire dati diversi a meno che la cache in memoria venga mantenuta sincronizzata con i dati di origine. Ad esempio, l'esecuzione della query non prova a mascherare i problemi dei dati filtrando i risultati di DirectQuery in modo che corrispondano ai valori memorizzati nella cache. Esistono tecniche consolidate per gestire questi problemi nell'origine, se necessario. Le ottimizzazioni delle prestazioni devono essere usate solo in modi che non compromettano la possibilità di soddisfare i requisiti aziendali. È responsabilità dell'utente conoscere i flussi di dati e progettare il sistema di conseguenza.
Considerazioni e limitazioni
Le aggregazioni non supportano il Parametro di query M dinamico.
A partire da agosto 2022, a causa delle modifiche apportate alle funzionalità, Power BI ignora le tabelle di aggregazione in modalità di importazione con origini dati abilitate per l'accesso Single Sign-On (SSO) a causa di potenziali rischi per la sicurezza. Per garantire prestazioni ottimali delle query con le aggregazioni, è consigliabile disabilitare l'accesso SSO per queste origini dati.
Community
Power BI ha una vivace community in cui MVP, professionisti BI e colleghi condividono competenze in gruppi di discussione, video, blog e altro ancora. Quando si apprendono informazioni sulle aggregazioni, assicurarsi di controllare queste risorse aggiuntive: