Come funziona la corrispondenza fuzzy in Power Query
Le funzionalità di Power Query, ad esempio l'unione fuzzy, i valori del cluster e il raggruppamento fuzzy usano gli stessi meccanismi per funzionare con la corrispondenza fuzzy.
Questo articolo illustra molti scenari che illustrano come sfruttare le opzioni di corrispondenza fuzzy, con l'obiettivo di rendere chiaro "fuzzy".
Regolare la soglia di somiglianza
Lo scenario migliore per applicare l'algoritmo di corrispondenza fuzzy è quando tutte le stringhe di testo in una colonna contengono solo le stringhe che devono essere confrontate e nessun componente aggiuntivo. Ad esempio, il confronto con restituisce punteggi di somiglianza più elevati rispetto al confronto Apples Apples con My favorite fruit, by far, is Apples. I simply love them!.4ppl3s
Poiché la parola Apples nella seconda stringa è solo una piccola parte dell'intera stringa di testo, tale confronto restituisce un punteggio di somiglianza inferiore.
Ad esempio, il set di dati seguente è costituito da risposte da un sondaggio che aveva una sola domanda: "Qual è il frutto preferito?"
| Frutta |
|---|
| Mirtilli |
| Le bacche blu sono semplicemente il migliore |
| Strawberries |
| Fragole = <3 |
| Mele |
| 'sples |
| 4ppl3s |
| Banane |
| frutta fav è banane |
| Bonaparte |
| Il mio frutto preferito, di gran lunga, è Apples. Li amo semplicemente! |
Il sondaggio ha fornito una singola casella di testo per immettere il valore e non ha avuto alcuna convalida.
A questo momento è necessario eseguire il clustering dei valori. A tale scopo, caricare la tabella di frutta precedente in Power Query, selezionare la colonna e quindi selezionare l'opzione Valori cluster nella scheda Aggiungi colonna della barra multifunzione.
![]()
Viene visualizzata la finestra di dialogo Valori cluster, in cui è possibile specificare il nome della nuova colonna. Assegnare alla nuova colonna il nome Cluster e selezionare OK.
Per impostazione predefinita, Power Query usa una soglia di somiglianza pari a 0,8 (o 80%). Il valore minimo 0,00 fa sì che tutti i valori con qualsiasi livello di somiglianza corrispondano tra loro e il valore massimo di 1,00 consenta solo corrispondenze esatte. Una "corrispondenza esatta" fuzzy potrebbe ignorare le differenze, ad esempio maiuscole e minuscole, ordine delle parole e punteggiatura. Il risultato dell'operazione precedente restituisce la tabella seguente con una nuova colonna Cluster .
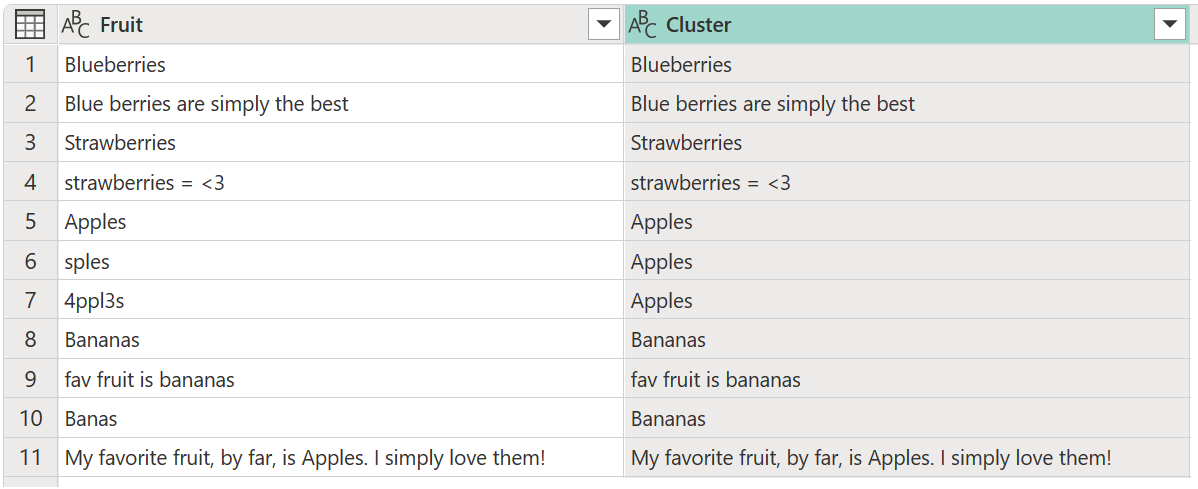
Mentre il clustering viene eseguito, non fornisce i risultati previsti per tutte le righe. La riga numero 2 (2) ha ancora il valore Blue berries are simply the best, ma deve essere raggruppata in Blueberriese si verifica un aspetto simile alle stringhe Strawberries = <3di testo , fav fruit is bananase My favorite fruit, by far, is Apples. I simply love them!.
Per determinare la causa di questo clustering, fare doppio clic su Valori cluster nel pannello Passaggi applicati per ripristinare la finestra di dialogo Valori cluster. All'interno di questa finestra di dialogo espandere Opzioni cluster fuzzy. Abilitare l'opzione Mostra punteggi di somiglianza e quindi selezionare OK.
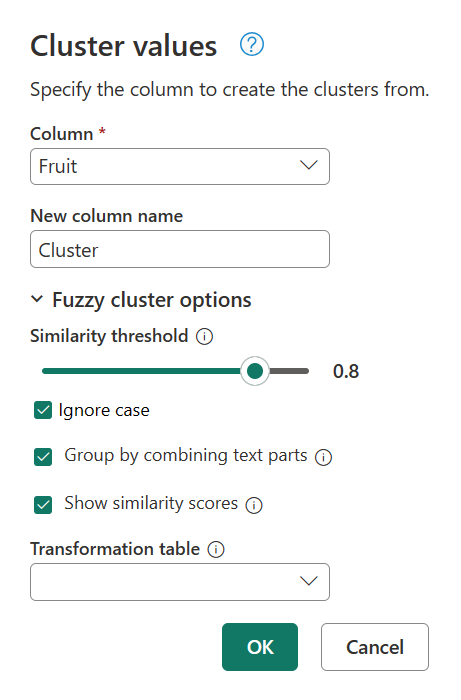
Se si abilita l'opzione Mostra punteggi di somiglianza, viene creata una nuova colonna nella tabella. Questa colonna mostra il punteggio di somiglianza esatto tra il cluster definito e il valore originale.

Dopo un'analisi più approfondita, Power Query non è riuscito a trovare altri valori nella soglia di somiglianza per le Blue berries are simply the beststringhe di testo ,Strawberries = <3fav fruit is bananas , e My favorite fruit, by far, is Apples. I simply love them!.
Tornare alla finestra di dialogo Valori cluster ancora una volta facendo doppio clic su Valori cluster nel pannello Passaggi applicati. Modificare la soglia di somiglianza da 0,8 a 0,6 e quindi selezionare OK.
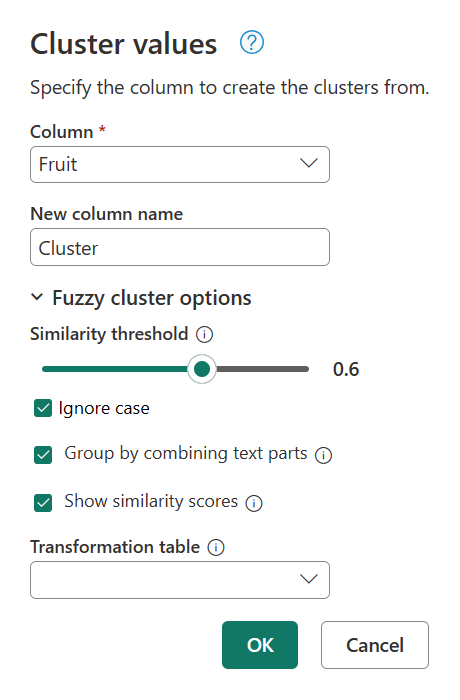
Questa modifica si avvicina al risultato che si sta cercando, ad eccezione della stringa My favorite fruit, by far, is Apples. I simply love them!di testo . Quando è stato modificato il valore soglia di somiglianza da 0,8 a 0,6, Power Query è stato ora in grado di usare i valori con un punteggio di somiglianza che inizia da 0,6 fino a 1.

Nota
Power Query usa sempre il valore più vicino alla soglia per definire i cluster. La soglia definisce il limite inferiore del punteggio di somiglianza accettabile per assegnare il valore a un cluster.
È possibile riprovare modificando il punteggio di somiglianza da 0,6 a un numero inferiore fino a ottenere i risultati che si sta cercando. In questo caso, modificare il punteggio di somiglianza impostando 0,5. Questa modifica restituisce il risultato esatto previsto con la stringa My favorite fruit, by far, is Apples. I simply love them! di testo ora assegnata al cluster Apples.

Nota
Attualmente, solo la funzionalità Valori cluster in Power Query Online fornisce una nuova colonna con il punteggio di somiglianza.
Considerazioni speciali per la tabella di trasformazione
La tabella di trasformazione consente di eseguire il mapping dei valori dalla colonna ai nuovi valori prima di eseguire l'algoritmo di corrispondenza fuzzy.
Alcuni esempi di come usare la tabella di trasformazione:
- Tabella di trasformazione nei valori del cluster
- Tabella di trasformazione nelle query di merge fuzzy
- Tabella di trasformazione in base al gruppo
Importante
Quando si usa la tabella di trasformazione, il punteggio di somiglianza massimo per i valori della tabella di trasformazione è 0,95. Questa penalità intenzionale di 0,05 è stata segnata per distinguere che il valore originale da tale colonna non è uguale ai valori rispetto al momento in cui si è verificata una trasformazione.
Per gli scenari in cui si vuole prima eseguire il mapping dei valori e quindi eseguire la corrispondenza fuzzy senza la penalità 0,05, è consigliabile sostituire i valori della colonna e quindi eseguire la corrispondenza fuzzy.