Che cos'è un gruppo di disponibilità Always On?
Si applica a: ![]() SQL Server
SQL Server
In questo articolo sono introdotti i concetti dei gruppi di disponibilità Always On, fondamentali per la configurazione e la gestione di uno o più gruppi di disponibilità nell’edizione Enterprise di SQL Server. Per l'edizione Standard, vedere Gruppi di disponibilità Always On di base per un database singolo.
I gruppi di disponibilità Always On sono una soluzione di disponibilità elevata e recupero di emergenza che offre un'alternativa di livello aziendale al mirroring del database. I Gruppi di disponibilità AlwaysOn ottimizzano la disponibilità di un set di database utente per un'azienda. Un gruppo di disponibilità supporta un ambiente di failover per un set discreto di database utente, noti come database di disponibilità, su cui si verifica il failover. Un gruppo di disponibilità supporta un set di database primari di lettura e scrittura e da uno a otto set di database secondari corrispondenti. Facoltativamente, i database secondari possono essere resi disponibili per l'accesso di sola lettura e/o alcune operazioni di backup.
Con SQL Server abilitato da Azure Arc, è possibile visualizzare i gruppi di disponibilità nel portale di Azure.
Panoramica
Un gruppo di disponibilità supporta un ambiente di replica per un set discreto di database utente, noti come database di disponibilità. È possibile creare un gruppo di disponibilità per la disponibilità elevata (HA) o per la scalabilità in lettura. Un gruppo di disponibilità elevata è un set di database il cui failover viene eseguito contemporaneamente. Un gruppo di disponibilità a scalabilità in lettura è un set di database che vengono copiati in altre istanze di SQL Server per il carico di lavoro di sola lettura. Un gruppo di disponibilità supporta un set di database primari e da uno a otto set di database secondari corrispondenti. I database secondari non sono backup. Continuare a eseguire il backup dei database e dei log delle transazioni regolarmente.
Suggerimento
È possibile creare qualsiasi tipo di backup di un database primario. In alternativa, è possibile creare backup del log e backup completi di sola copia dei database secondari. Per maggiori informazioni, vedere Offload dei backup supportati nelle repliche secondarie di un gruppo di disponibilità.
Ogni set di database di disponibilità è ospitato da una replica di disponibilità. Esistono due tipi di repliche di disponibilità: una singola replica primaria, in cui sono ospitati i database primari e da una a otto repliche secondarie, ognuna ospitante un set di database secondari, che sono usate come destinazione del failover potenziale per il gruppo di disponibilità. Per un gruppo di disponibilità il failover si verifica al livello di una replica di disponibilità. Una replica di disponibilità fornisce la ridondanza solo a livello di database, ovvero per il set di database in un gruppo di disponibilità. I failover non sono dovuti a database ritenuti sospetti in seguito a una perdita di un file di dati o al danneggiamento di un log delle transazioni.
La replica primaria rende disponibili i database primari per le connessioni in lettura e scrittura dei client La replica primaria invia i record di log delle transazioni di ogni database primario a ogni database secondario. Questo processo, noto come sincronizzazione dei dati, si verifica a livello di database. Ogni replica secondaria memorizza nella cache i record del log delle transazioni (finalizza il log), quindi li applica al database secondario corrispondente. La sincronizzazione dei dati si verifica tra il database primario e ogni database secondario collegato, indipendentemente dagli altri database. Pertanto, un database secondario può essere sospeso o non riuscire senza influire su altri database secondari e un database primario può essere sospeso o non riuscire senza influire su altri database primari.
Facoltativamente, è possibile configurare una o più repliche secondarie per supportare l'accesso in sola lettura ai database secondari e una qualsiasi replica secondaria per consentire l'esecuzione di backup sui database secondari.
SQL Server 2017 ha introdotto due architetture diverse per i gruppi di disponibilità. I gruppi di disponibilità Always On offrono disponibilità elevata, ripristino di emergenza e bilanciamento della scalabilità in lettura. Questi gruppi di disponibilità richiedono una gestione del cluster. In Windows, la funzionalità di clustering di failover fornisce la gestione del cluster. In Linux è possibile utilizzare Pacemaker. L'altra architettura è data dai gruppi di disponibilità con scalabilità in lettura. Un gruppo di disponibilità con scalabilità in lettura fornisce repliche per i carichi di lavoro di sola lettura, ma non un'elevata disponibilità. In un gruppo di disponibilità con scalabilità di lettura non è disponibile alcun gestore cluster, poiché il failover non può essere automatico.
La distribuzione di Gruppi di disponibilità Always On per disponibilità elevata in Windows richiede un cluster WSFC (Windows Server Failover Cluster). Ogni replica di disponibilità di un determinato gruppo di disponibilità deve risiedere su un nodo diverso dello stesso cluster WSFC. L'unica eccezione è che quando viene eseguita la migrazione a un altro cluster WSFC, un gruppo di disponibilità può risiedere temporaneamente in due cluster.
Nota
Per informazioni sui gruppi di disponibilità in Linux, vedere Gruppo di disponibilità per SQL Server in Linux.
In una configurazione a disponibilità elevata, un ruolo cluster viene creato per ogni gruppo di disponibilità che viene creato. Con il cluster WSFC è possibile eseguire il monitoraggio del ruolo per valutare lo stato di integrità della replica primaria. Il quorum di Gruppi di disponibilità Always On si basa su tutti i nodi del cluster WSFC, indipendentemente dal fatto che un nodo del cluster ospiti una replica di disponibilità o meno. A differenza del mirroring del database, non esiste alcun ruolo del server di controllo in Gruppi di disponibilità Always On.
Nota
Per informazioni sulla relazione dei componenti di SQL Server AlwaysOn con il cluster WSFC, vedere Windows Server Failover Clustering con SQL Server.
Di seguito viene illustrato un gruppo di disponibilità contenente una replica primaria e quattro repliche secondarie. Sono supportate fino a otto repliche secondarie, incluse una replica primaria e quattro repliche secondarie con commit sincrono.
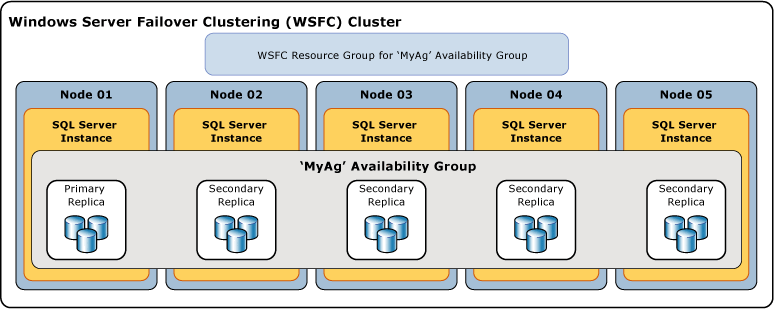
Termini e definizioni
| Termine | Descrizione |
|---|---|
| gruppo di disponibilità | Contenitore per un set di database, i database di disponibilità, su cui si verifica il failover. |
| database di disponibilità | Database che appartiene a un gruppo di disponibilità. Per ogni database di disponibilità, il gruppo di disponibilità gestisce una sola copia di lettura e scrittura (il database primario) e da una a otto copie di sola lettura (database secondari). |
| database primario | Copia di lettura e scrittura di un database di disponibilità. |
| database secondario | Copia di sola lettura di un database di disponibilità. |
| replica di disponibilità | Istanza di un gruppo di disponibilità ospitata da un'istanza specifica di SQL Server che mantiene una copia locale di ogni database di disponibilità che appartiene al gruppo di disponibilità. Sono disponibili due tipi di replica di disponibilità: una replica primaria e da una a otto repliche secondarie. |
| replica primaria | Replica di disponibilità che rende disponibili i database primari per le connessioni in lettura e scrittura dai client e invia i record del log delle transazioni per ogni database primario a ogni replica secondaria. |
| replica secondaria | Replica di disponibilità che mantiene una copia secondaria di ogni database di disponibilità e che rappresenta la destinazione potenziale del failover per il gruppo di disponibilità. Facoltativamente, una replica secondaria può supportare l'accesso in sola lettura ai database secondari creando backup sui database secondari. |
| listener del gruppo di disponibilità | Nome del server a cui i client possono connettersi per accedere a un database in una replica primaria o secondaria di un gruppo di disponibilità. I listener del gruppo di disponibilità indirizzano le connessioni in ingresso alla replica primaria o a una replica secondaria in sola lettura. |
Database di disponibilità
Per poter essere aggiunto a un gruppo di disponibilità, il database deve essere online, di lettura e scrittura ed esistere sull'istanza del server che ospita la replica primaria. Il database viene aggiunto al gruppo di disponibilità come database primario, pur rimanendo disponibile ai client. Non esiste alcun database secondario corrispondente finché i backup del nuovo database primario non sono ripristinati sull'istanza del server che ospita la replica secondaria (tramite RESTORE WITH NORECOVERY). Il nuovo database secondario rimane nello stato RESTORING finché non ne viene creato un join al gruppo di disponibilità. Per altre informazioni, vedere Avviare lo spostamento dati su un database secondario Always On (SQL Server).
Dopo la creazione di un join, il database secondario passa allo stato ONLINE e avvia la sincronizzazione dati con il database primario corrispondente. Lasincronizzazione dati è il processo tramite cui le modifiche apportate a un database primario sono riprodotte in un database secondario. La sincronizzazione dei dati comporta che il database primario invia i record del log delle transazioni al database secondario.
Importante
Un database di disponibilità viene a volte definito replica di database in Transact-SQL, PowerShell e nei nomi di oggetti SMO (SQL Server Management Objects). Il termine "database replica" (replica di database) viene usato ad esempio nei nomi delle DMV AlwaysOn che restituiscono informazioni sui database di disponibilità: sys.dm_hadr_database_replica_states e sys.dm_hadr_database_replica_cluster_states. Tuttavia, nella documentazione online di SQL Server il termine "replica" si riferisce solitamente alle repliche di disponibilità. Ad esempio, "replica primaria" e "replica secondaria" si riferiscono sempre a repliche di disponibilità.
Repliche di disponibilità
Ogni gruppo di disponibilità definisce un set di due o più partner di failover noti come repliche di disponibilità. Lerepliche di disponibilità sono componenti del gruppo di disponibilità. Ogni replica di disponibilità ospita una copia dei database di disponibilità del gruppo di disponibilità. Per un determinato gruppo di disponibilità, le repliche di disponibilità devono essere ospitate da istanze separate di SQL Server che risiedono in nodi diversi di un cluster WSFC. Ognuna di queste istanze del server deve essere abilitata per AlwaysOn.
SQL Server 2019 (15.x) aumenta il numero massimo di repliche sincrone a 5, rispetto a 3 in SQL Server 2017 (14.x). È possibile configurare questo gruppo di cinque repliche per il failover automatico all'interno del gruppo. Sono presenti una replica primaria e quattro repliche secondarie sincrone.
In una determinata istanza può essere ospitata solo una replica di disponibilità per gruppo di disponibilità. Tuttavia, ogni istanza può essere usata per numerosi gruppi di disponibilità. Un'istanza specificata può essere un'istanza autonoma o un'istanza del cluster di failover di SQL Server. Se è necessaria la ridondanza a livello di server, usare le istanze del cluster di failover.
A ogni replica di disponibilità viene assegnato un ruolo iniziale, ovvero il ruolo primario o il ruolo secondario, ereditato dai database di disponibilità della replica in questione. È il ruolo a determinare se la replica a cui è stato assegnato ospiterà database di lettura e scrittura o database di sola lettura. La replica primaria, a cui viene assegnato il ruolo primario, ospiterà i database di lettura e scrittura, noti come database primari. Ad almeno un'altra replica, nota come replica secondariaviene assegnato il ruolo secondario. Una replica secondaria ospita i database di sola lettura, noti come database secondari.
Nota
Quando il ruolo di una replica di disponibilità è indeterminato, ad esempio durante un failover, i relativi database si trovano temporaneamente nello stato NOT SYNCHRONIZING. Il loro ruolo rimane impostato su RESOLVING finché il ruolo della replica di disponibilità non viene risolto. Se una replica di disponibilità viene risolta nel ruolo primario, i relativi database diventano i database primari. Se una replica di disponibilità viene risolta nel ruolo secondario, i relativi database diventano i database secondari.
Modalità di disponibilità
La modalità di disponibilità è una proprietà di ogni replica di disponibilità. La modalità di disponibilità determina se la replica primaria eseguirà il commit delle transazioni su un database solo dopo che una determinata replica secondaria avrà scritto su disco i record del log delle transazioni (consolidamento del log). Gruppi di disponibilità Always On supporta due modalità di disponibilità: modalità con commit asincrono e modalità con commit sincrono.
Asynchronous-commit mode
Una replica di disponibilità che usa questa modalità di disponibilità viene chiamata replica con commit asincrono. Nella modalità commit asincrono, la replica primaria esegue il commit delle transazioni senza attendere l'acknowledgement da parte delle repliche con commit asincrono per la finalizzazione dei log delle transazioni. La modalità commit asincrono riduce la latenza delle transazioni sui database secondari, ma consente un certo ritardo rispetto ai database primari, rendendo possibile la perdita di dati.
Synchronous-commit mode
Una replica di disponibilità che usa questa modalità di disponibilità è nota come replica con commit sincrono. Nella modalità commit sincrono, prima di eseguire il commit delle transazioni, una replica primaria con commit sincrono attende l'acknowledgement della finalizzazione del log da parte della replica secondaria con commit sincrono. Nella modalità commit sincrono si può essere sicuri che al termine della sincronizzazione di un determinato database secondario con il database primario, le transazioni di cui è stato eseguito il commit sono completamente protette. Questa protezione comporta un aumento della latenza delle transazioni. SQL Server 2017 ha introdotto una funzionalità Repliche secondarie sincronizzate necessarie opzionale per aumentare ulteriormente la sicurezza a costo della latenza, quando desiderato. La funzionalità REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT può essere abilitata per richiedere un numero specifico di repliche sincrone per eseguire il commit di una transazione prima che una replica primaria possa eseguire il commit.
Per altre informazioni, vedere Differenze tra le modalità di disponibilità per un gruppo di disponibilità Always On.
Tipi di failover
Nel contesto di una sessione tra la replica primaria e una replica secondaria, i ruoli primari e secondari sono potenzialmente intercambiabili in un processo noto come failover. Durante un failover la replica secondaria di destinazione assume il ruolo primario, diventando la nuova replica primaria. La nuova replica primaria porta i relativi database online come database primari, consentendo alle applicazioni client di connettersi ad essi. Se la replica primaria precedente è disponibile, assume il ruolo secondario, diventando una replica secondaria. I database primari precedenti diventano database secondari e la sincronizzazione dati viene ripresa.
Per un gruppo di disponibilità il failover si verifica al livello di una replica di disponibilità. I failover non sono dovuti a database ritenuti sospetti in seguito a una perdita di un file di dati, all'eliminazione di un database o al danneggiamento di un log delle transazioni.
Sono disponibili tre tipi di failover: automatico, manuale e forzato (con possibile perdita di dati). La forma o le forme di failover supportate da una determinata replica secondaria dipendono dalla relativa modalità di disponibilità e, per la modalità commit sincrono, dalla modalità di failover sulla replica primaria e sulla replica secondaria di destinazione.
La modalità commit sincrono supporta due forme di failover, ovvero failover manuale pianificato e failover automatico, se la replica secondaria di destinazione è sincronizzata con quella primaria. Il supporto per queste forme di failover dipende dall'impostazione della proprietà della modalità di failover sui partner di failover. Se la modalità di failover è impostata su "manuale" sulla replica primaria o su quella secondaria, per la replica secondaria è supportato solo il failover manuale. Se la modalità di failover è impostata su "automatico" sia sulla replica primaria sia sulle repliche secondarie, sulla replica secondaria sono supportate entrambe le forme di failover, manuale e automatico.
Failover manuale pianificato (senza perdita di dati)
Si verifica un failover manuale quando un amministratore di database esegue un comando di failover causando il passaggio di una replica secondaria sincronizzata al ruolo primario (con protezione dei dati garantita) e della replica primaria al ruolo secondario. Un failover manuale richiede che sia la replica primaria sia la replica secondaria di destinazione siano eseguite nella modalità commit sincrono e che la replica secondaria sia già sincronizzata.
Failover automatico (senza perdita di dati)
Un failover automatico si verifica in risposta a un errore che causa il passaggio di una replica secondaria sincronizzata al ruolo primario (con protezione dei dati garantita). Quando la replica primaria precedente diventa disponibile, assume il ruolo secondario. Il failover automatico richiede che sia la replica primaria sia la replica secondaria di destinazione siano eseguite nella modalità commit sincrono con la modalità di failover impostata su Automatico. È inoltre necessario che la replica secondaria sia già sincronizzata, disponga del quorum WSFC e soddisfi le condizioni specificate dai criteri di failover flessibili del gruppo di disponibilità.
Nella modalità commit asincrono, l'unica forma di failover supportata è il failover manuale forzato (con possibile perdita di dati), in genere denominato failover forzato. Il failover forzato è considerato una forma di failover manuale, in quanto può essere avviato solo manualmente. Il failover forzato rappresenta un'opzione di ripristino di emergenza. Si tratta dell'unica forma di failover possibile quando la replica secondaria di destinazione non è sincronizzata con la replica primaria.
Per altre informazioni, vedere Failover e modalità di failover (Gruppi di disponibilità Always On).
Importante
- Le istanze del cluster di failover di SQL Server non supportano il failover automatico da gruppi di disponibilità, pertanto le replica di disponibilità ospitate da un'istanza del cluster di failover possono essere configurate solo per il failover manuale.
- Se si esegue un comando di failover forzato su una replica secondaria sincronizzata, la replica secondaria si comporta come con un failover manuale pianificato.
Vantaggi
I gruppi di disponibilità Always On offrono un ampio set di opzioni con cui è possibile migliorare la disponibilità del database e l’uso delle risorse. I componenti chiave sono i seguenti:
Supporta fino a nove repliche di disponibilità. Una replica di disponibilità è la creazione di un'istanza di un gruppo di disponibilità ospitata da un'istanza specifica di SQL Server e che mantiene una copia locale di ogni database di disponibilità che appartiene al gruppo di disponibilità. Ogni gruppo di disponibilità supporta una replica primaria e fino a otto repliche secondarie. Per altre informazioni, vedere Che cos'è un gruppo di disponibilità AlwaysOn?
Importante
Ogni replica di disponibilità deve risiedere su un nodo diverso di un singolo cluster WSFC (Windows Server Failover Clustering). Per altre informazioni su prerequisiti, restrizioni e consigli per i gruppi di disponibilità, vedere Prerequisiti, restrizioni e consigli per i gruppi di disponibilità Always On.
Supporta modalità di disponibilità alternative, come segue:
Modalità commit asincrono. La modalità di disponibilità è una soluzione di recupero di emergenza che offre risultati ottimali quando le repliche di disponibilità vengono distribuite a distanze considerevoli.
Modalità commit sincrono. La modalità di disponibilità privilegia la disponibilità elevata e la protezione dei dati rispetto alle prestazioni, aumentando tuttavia la latenza delle transazioni. Un determinato gruppo di disponibilità è in grado di supportare fino a cinque repliche di disponibilità con commit sincrono, inclusa la replica primaria corrente.
Per altre informazioni, vedere Differenze tra le modalità di disponibilità per un gruppo di disponibilità Always On.
Supporta molti formati di failover del gruppo di disponibilità: failover automatico, failover manuale pianificato (in genere definito semplicemente "failover manuale") e failover manuale forzato (in genere definito semplicemente "failover forzato"). Per altre informazioni, vedere Failover e modalità di failover (Gruppi di disponibilità Always On).
Permette di configurare una determinata replica di disponibilità per supportare una o entrambe le seguenti funzionalità delle repliche secondarie attive:
Accesso alla connessione in sola lettura che permette connessioni in sola lettura alla replica per accedere e leggere i relativi database quando viene eseguita come replica secondaria. Per altre informazioni, vedere Ripartire il carico di lavoro di sola lettura in una replica secondaria di un gruppo di disponibilità Always On.
Esecuzione di operazioni di backup sui relativi database quando viene eseguito come replica secondaria. Per maggiori informazioni, vedere Offload dei backup supportati nelle repliche secondarie di un gruppo di disponibilità.
L'uso delle funzionalità secondarie attive migliora l'efficienza IT e riduce i costi tramite un migliore uso delle risorse dell'hardware secondario. Inoltre, la ripartizione delle applicazioni con finalità di lettura e dei processi di backup alle repliche secondarie permette di migliorare le prestazioni sulla replica primaria.
Supporta un listener del gruppo di disponibilità per ogni gruppo di disponibilità. Un listener del gruppo di disponibilità è un nome del server a cui i client possono connettersi per accedere a un database in una replica primaria o secondaria di un gruppo di disponibilità Always On. I listener del gruppo di disponibilità indirizzano le connessioni in ingresso alla replica primaria o a una replica secondaria in sola lettura. Il listener permette un failover rapido dell'applicazione dopo il failover del gruppo di disponibilità. Per altre informazioni, vedere Connessione a un listener di un gruppo di disponibilità Always On.
Supporta criteri di failover flessibili per un maggiore controllo del failover del gruppo di disponibilità. Per altre informazioni, vedere Failover e modalità di failover (Gruppi di disponibilità Always On).
Supporta il ripristino automatico della pagina per la protezione da danneggiamenti di pagina. Per altre informazioni, vedere Correzione automatica della pagina (Gruppi di disponibilità/Mirroring del database).
Supporta crittografia e compressione, che forniscono il trasporto sicuro a prestazioni elevate.
Fornisce un set integrato di strumenti per semplificare la distribuzione e la gestione dei gruppi di disponibilità, tra cui:
Istruzioni DDL di Transact-SQL per la creazione e la gestione di gruppi di disponibilità. Per altre informazioni, vedere Istruzioni Transact-SQL per i gruppi di disponibilità Always On.
Strumenti di SQL Server Management Studio, come illustrato di seguito:
La Creazione guidata gruppo di disponibilità crea e configura un gruppo di disponibilità. In alcuni ambienti, questa procedura guidata prepara automaticamente i database secondari e avvia la sincronizzazione dei dati per ognuno di essi. Per altre informazioni, vedere Usare la finestra di dialogo Nuovo gruppo di disponibilità (SQL Server Management Studio).
La procedura guidata Aggiungi database a gruppo di disponibilità aggiunge uno o più database primari a un gruppo di disponibilità esistente. In alcuni ambienti, questa procedura guidata prepara automaticamente i database secondari e avvia la sincronizzazione dei dati per ognuno di essi. Per altre informazioni, vedere Aggiungere un database a un gruppo di disponibilità Always On con la "Procedura guidata Gruppo di disponibilità".
La procedura guidata Aggiungi replica a gruppo di disponibilità aggiunge una o più repliche secondarie a un gruppo di disponibilità esistente. In alcuni ambienti, questa procedura guidata prepara automaticamente i database secondari e avvia la sincronizzazione dei dati per ognuno di essi. Per altre informazioni, vedere Aggiungere una replica al gruppo di disponibilità Always On usando la Procedura guidata Gruppo di disponibilità in SQL Server Management.
La procedura guidata Failover gruppo di disponibilità avvia un failover manuale in un gruppo di disponibilità. A seconda della configurazione e dello stato della replica secondaria specificata come destinazione del failover, la procedura guidata può eseguire un failover pianificato o un failover manuale forzato. Per altre informazioni, vedere Usare la procedura guidata Failover gruppo di disponibilità (SQL Server Management Studio).
Il Dashboard AlwaysOn monitora i gruppi di disponibilità Always On, le repliche di disponibilità e i database di disponibilità e valuta i risultati per i criteri Always On. Per altre informazioni, vedere Usare il Dashboard del gruppo di disponibilità Always On (SQL Server Management Studio).
Nel riquadro Dettagli Esplora oggetti sono visualizzate informazioni di base sui gruppi di disponibilità esistenti. Per altre informazioni, vedere Usare Dettagli Esplora oggetti per monitorare i gruppi di disponibilità.
Cmdlet di PowerShell. Per altre informazioni, vedere Informazioni generali sui cmdlet di PowerShell per Gruppi di disponibilità Always On.
Connessioni client
È possibile fornire la connettività client alla replica primaria di un determinato gruppo di disponibilità creando un listener del gruppo di disponibilità. Un listener del gruppo di disponibilità fornisce un set di risorse collegate a un determinato gruppo di disponibilità per l'indirizzamento delle connessioni client alla replica di disponibilità appropriata.
Un listener del gruppo di disponibilità è associato a un nome DNS univoco che funge da nome di rete virtuale (VNN), a uno o più indirizzi IP virtuali (VIP) e a un numero di porta TCP. Per altre informazioni, vedere Connessione a un listener di un gruppo di disponibilità Always On.
Suggerimento
Se un gruppo di disponibilità dispone unicamente di due repliche di disponibilità e non è configurato per consentire l'accesso in lettura alla replica secondaria, i client possono connettersi alla replica primaria tramite una stringa di connessione per il mirroring del database. Questo approccio può essere utile temporaneamente dopo la migrazione di un database dal mirroring del database a Gruppi di disponibilità Always On. Prima di aggiungere ulteriori repliche di disponibilità, è necessario creare un listener del gruppo di disponibilità e aggiornare le applicazioni affinché usino il nome di rete del listener.
Repliche secondarie attive
Gruppi di disponibilità Always On supporta le repliche secondarie attive. Le funzionalità delle repliche secondarie attive includono il supporto per:
Esecuzione di operazioni di backup sulle repliche secondarie
Le repliche secondarie supportano l'esecuzione di backup del log e backup di sola copia di un database completo, di file o di un filegroup. È possibile configurare il gruppo di disponibilità per specificare una preferenza per la destinazione dei backup. È importante comprendere che la preferenza non viene applicata da SQL Server, di conseguenza non ha alcun impatto sui backup ad hoc. L'interpretazione di questa preferenza dipende dalla logica, se presente, di cui viene generato lo script nei processi di backup per ogni database di un determinato gruppo di disponibilità. Per una replica di disponibilità singola, è possibile specificare la priorità di esecuzione dei backup in questa replica rispetto alle altre repliche dello stesso gruppo di disponibilità. Per maggiori informazioni, vedere Offload dei backup supportati nelle repliche secondarie di un gruppo di disponibilità.
Accesso in sola lettura a una o più repliche secondarie (repliche secondarie leggibili)
Una replica di disponibilità secondaria può essere configurata in modo da consentire solo l'accesso in sola lettura ai relativi database locali, sebbene alcune operazioni non siano pienamente supportate. In questo modo si evitano i tentativi di connessione in lettura/scrittura alla replica secondaria. È anche possibile impedire carichi di lavoro di sola lettura nella replica primaria consentendo solo l'accesso in lettura/scrittura. In questo modo si evitano connessioni di sola lettura alla replica primaria. Per altre informazioni, vedere Ripartire il carico di lavoro di sola lettura in una replica secondaria di un gruppo di disponibilità Always On.
Se un listener del gruppo di disponibilità e una o più repliche secondarie leggibili vengono elaborate da un gruppo di disponibilità, tramite SQL Server è possibile instradare le richieste di connessione con finalità di lettura a una di tali repliche (routing di sola lettura). Per altre informazioni, vedere Connessione a un listener di un gruppo di disponibilità Always On.
Periodo di timeout della sessione
Il periodo di timeout della sessione è una proprietà della replica di disponibilità che determina quanto tempo la connessione con un'altra replica di disponibilità può rimanere inattiva prima che la connessione venga chiusa. Le repliche primarie e secondarie effettuano vicendevolmente il ping per segnalare che ancora sono attive. La ricezione di un ping dall'altra replica durante il periodo di timeout indica che la connessione è ancora aperta e che le istanze del server sono in comunicazione. Alla ricezione di un ping, la replica di disponibilità reimposta il contatore del timeout della sessione per quella connessione.
Il periodo di timeout della sessione impedisce alla replica di attendere indefinitamente la ricezione di un ping dall'altra replica. Se non viene ricevuto alcun ping dall'altra replica entro il periodo di timeout della sessione, si verifica il timeout della replica. La connessione viene chiusa e per la replica scaduta viene impostato lo stato DISCONNECTED. Anche se la replica disconnessa è configurata per la modalità con commit sincrono, le transazioni non attendono che quella replica venga riconnessa e risincronizzata.
Il periodo di timeout della sessione predefinito per ogni replica di disponibilità è di 10 secondi. Questo valore è configurabile dall'utente (minimo 5 secondi). È consigliabile usare generalmente un periodo di timeout di almeno 10 secondi. Con un valore inferiore a 10 secondi, può verificarsi un sovraccarico del sistema, con generazione di falsi errori.
Nota
Nel ruolo di risoluzione, il periodo di timeout della sessione non si applica perché il ping non viene eseguito.
Correzione di pagina automatica
Ogni replica di disponibilità tenta di recuperare automaticamente delle pagine danneggiate su un database locale risolvendo determinati tipi di errore che impediscono la lettura di una pagina di dati. Se una replica secondaria non legge una pagina, la replica richiede alla replica primaria una copia aggiornata della pagina. Se la replica primaria non legge una pagina, la replica trasmette una richiesta per una copia aggiornata a tutte le repliche secondarie e ottiene la pagina dalla prima replica secondaria che risponderà. Se la richiesta viene soddisfatta, la pagina illeggibile viene sostituita dalla copia e l'errore viene risolto.
Per altre informazioni, vedere Correzione automatica della pagina (Gruppi di disponibilità/Mirroring del database).
Interoperabilità e coesistenza con altre funzionalità del motore di database
È possibile usare la soluzione Gruppi di disponibilità Always On con le funzionalità o i componenti seguenti di SQL Server:
- Cos’è Change Data Capture (CDC)?
- Informazioni sul rilevamento delle modifiche (SQL Server)
- Database indipendenti
- Transparent Data Encryption (TDE)
- Snapshot del database con gruppi di disponibilità Always On (SQL Server)
- FILESTREAM (SQL Server)
- FileTable (SQL Server)
- Informazioni sul log shipping (SQL Server)
- Archivio Blob remoto (RBS) (SQL Server)
- Replica di SQL Server
- Service Broker
- SQL Server Agent
- Reporting Services con i gruppi di disponibilità Always On (SQL Server)
Attività correlate
- Prerequisiti, restrizioni e consigli per i gruppi di disponibilità Always On
- Riferimento per la creazione e la configurazione di gruppi di disponibilità Always On
- Amministrazione di un gruppo di disponibilità
- Strumenti per il monitoraggio dei Gruppi di disponibilità Always On
- Ripartire il carico di lavoro di sola lettura in una replica secondaria di un gruppo di disponibilità Always On
- Ripartire i backup supportati nelle repliche secondarie di un gruppo di disponibilità
- Connettersi a un listener del gruppo di disponibilità Always On
- Istruzioni Transact-SQL per i gruppi di disponibilità Always On
- Informazioni generali sui cmdlet di PowerShell per Gruppi di disponibilità Always On
- Blog del supporto di SQL Server: disponibilità elevata
- Blog di SQL Server: SQL Server Always On
- Archivio: blog del team di SQL Server Always On: blog ufficiale del team di SQL Server AlwaysOn
- Archivio: blog del Servizio Supporto Tecnico Clienti per gli ingegneri di SQL Server
- Microsoft SQL Server Always On Solutions Guide for High Availability and Disaster Recovery (Guida alle soluzioni AlwaysOn di Microsoft SQL Server per la disponibilità elevata e il ripristino di emergenza)