Azure Functions の Python 開発者向けガイド
このガイドでは、Python を使用した Azure Functions の開発について紹介します。 この記事では、「Azure Functions の開発者向けガイド」を既に読んでいることを前提としています。
重要
この記事では、Azure Functions での Python プログラミング モデルの v1 と v2 の両方をサポートします。 Python v1 モデルでは functions.json ファイルを使用して関数を定義しますが、新しい v2 モデルでは代わりにデコレーターベースのアプローチを使用できます。 この新しいアプローチにより、ファイル構造がシンプルになり、コード中心になります。 この新しいプログラミング モデルについて学習するには、記事の上部にある v2 セレクターを選択します。
Python 開発者は、以下のトピックにも興味があるかもしれません。
- Visual Studio Code: Visual Studio Code を使用して初めての Python アプリを作成します。
- ターミナルまたはコマンド プロンプト: Azure Functions Core Tools を使用して、コマンド プロンプトから初めての Python アプリを作成します。
- サンプル: Learn サンプル ブラウザーで既存の Python アプリをいくつか確認します。
- Visual Studio Code: Visual Studio Code を使用して初めての Python アプリを作成します。
- ターミナルまたはコマンド プロンプト: Azure Functions Core Tools を使用して、コマンド プロンプトから初めての Python アプリを作成します。
- サンプル: Learn サンプル ブラウザーで既存の Python アプリをいくつか確認します。
開発オプション
どちらの Python Functions プログラミング モデルでも、次の環境のいずれかでローカル開発がサポートされます。
Python v2 プログラミング モデル:
Python v1 プログラミング モデル:
Azure portal で Python v1 関数を作成することもできます。
ヒント
Python ベースの Azure 関数を Windows 上のローカルで開発できますが、Python は、Azure で実行されている場合、Linux ベースのホスティング プランでのみサポートされます。 詳細については、サポートされているオペレーティング システムとランタイムの組み合わせの一覧を参照してください。
プログラミング モデル
Azure Functions では、関数は入力を処理して出力を生成する Python スクリプト内のステートレスなメソッドであることが求められます。 既定で、ランタイムでは、このメソッドは main() と呼ばれるグローバル メソッドとして _init_.py ファイル内に実装されると想定されます。 また、代替エントリ ポイントを指定することもできます。
トリガーとバインディングからのデータをメソッド属性を介して関数にバインドするには、function.json ファイル内で定義されている name プロパティを使用します。 たとえば、次の function.json ファイルには、req という名前の HTTP 要求によってトリガーされるシンプルな関数が記述されています。
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
この定義に基づき、関数コードを含む _init_.py ファイルは次の例のようになります。
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Python の型の注釈を使用することで、関数内に属性の種類および戻り値の型を明示的に宣言することもできます。 こうすることで、多くの Python コード エディターによって提供される IntelliSense とオートコンプリート機能を使うのに役立ちます。
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
azure.functions.* パッケージに含まれる Python の注釈を使用すると、入力と出力がご利用のメソッドにバインドされます。
Azure Functions では、関数は入力を処理して出力を生成する Python スクリプト内のステートレスなメソッドであることが求められます。 既定で、ランタイムでは、このメソッドはグローバル メソッドとして function_app.py ファイル内に実装されると想定されます。
デコレーター ベースのアプローチでは、トリガーとバインドは関数で宣言および使用できます。 これらは、関数と同じファイル function_app.py で定義されています。 例として、次の function_app.py ファイルは、HTTP 要求によってトリガーされる関数を表します。
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Python の型の注釈を使用することで、関数内に属性の種類および戻り値の型を明示的に宣言することもできます。 こうすることで、多くの Python コード エディターによって提供される IntelliSense とオートコンプリート機能を使うのに役立ちます。
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
v2 モデルに関する既知の制限事項とその回避策については、「Azure Functions での Python エラーのトラブルシューティング」を参照してください。
代替エントリ ポイント
scriptFile ファイル内で scriptFile プロパティと entryPoint プロパティをオプションで指定することによって、関数の既定の動作を変更できます。 たとえば、以下の function.json では、ご利用の Azure 関数のエントリ ポイントとして、main.py ファイル内の customentry() メソッドを使用するようにランタイムに指示が出されます。
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
エントリ ポイントは function_app.py ファイル内のみにあります。 ただし、プロジェクト内の関数は、ブループリントを使用するかインポートして、function_app.py で参照できます。
フォルダー構造
Python 関数プロジェクトの推奨フォルダー構造は、次の例のようになります。
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
メイン プロジェクト フォルダー <
- local.settings.json:ローカルで実行するときに、アプリの設定と接続文字列を格納するために使用されます。 このファイルは Azure に公開されません。 詳細については、「local.settings.file」に関するページを参照してください。
- requirements.txt:Azure に公開するときにシステムによってインストールされる Python パッケージの一覧が含まれます。
- host.json: 関数アプリ インスタンス内にあるすべての関数に影響する構成オプションが含まれます。 このファイルは Azure に公開されます。 ローカルで実行する場合は、すべてのオプションがサポートされるわけではありません。 詳細については、「host.json」に関するページを参照してください。
- .vscode/: (省略可能) 格納されている Visual Studio Code 構成が含まれます。 詳細については、Visual Studio Code の設定に関するページを参照してください。
- .venv/ :(省略可能) ローカル開発で使用される Python 仮想環境が含まれます。
- Dockerfile:(省略可能) カスタム コンテナーでプロジェクトを発行するときに使用されます。
- tests/ :(省略可能) 関数アプリのテスト ケースが含まれます。
- .funcignore:(省略可能) Azure に発行しないファイルを宣言します。 通常、このファイルには、エディター設定を無視する場合は .vscode/、ローカルの Python 仮想環境を無視する場合は .venv/、テスト ケースを無視する場合は tests/、ローカル アプリの設定を発行しない場合は local.settings.json が含まれます。
各関数には、独自のコード ファイルとバインディング構成ファイル function.json があります。
Python 関数プロジェクトの推奨フォルダー構造は、次の例のようになります。
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
メイン プロジェクト フォルダー <
- .venv/: (省略可能) ローカル開発に使用される Python 仮想環境が含まれます。
- .vscode/: (省略可能) 格納されている Visual Studio Code 構成が含まれます。 詳細については、Visual Studio Code の設定に関するページを参照してください。
- function_app.py: すべての関数とそれに関連するトリガーとバインドの既定の場所です。
- additional_functions.py: (省略可能) ブループリントを介して function_app.py で参照される関数 (通常は論理グループ化用) を含む他の Python ファイル。
- tests/ :(省略可能) 関数アプリのテスト ケースが含まれます。
- .funcignore:(省略可能) Azure に発行しないファイルを宣言します。 通常、このファイルには、エディター設定を無視する場合は .vscode/、ローカルの Python 仮想環境を無視する場合は .venv/、テスト ケースを無視する場合は tests/、ローカル アプリの設定を発行しない場合は local.settings.json が含まれます。
- host.json: 関数アプリ インスタンス内にあるすべての関数に影響する構成オプションが含まれます。 このファイルは Azure に公開されます。 ローカルで実行する場合は、すべてのオプションがサポートされるわけではありません。 詳細については、「host.json」に関するページを参照してください。
- local.settings.json: ローカルで実行するとき、アプリ設定と接続文字列を格納するために使用されます。 このファイルは Azure に公開されません。 詳細については、「local.settings.file」に関するページを参照してください。
- requirements.txt: Azure に公開するときにシステムによってインストールされる Python パッケージの一覧が含まれます。
- Dockerfile:(省略可能) カスタム コンテナーでプロジェクトを発行するときに使用されます。
Azure の関数アプリにプロジェクトをデプロイするときは、メイン プロジェクト フォルダー <project_root> の内容全体をパッケージに含める必要がありますが、フォルダー自体は含めないでください。つまり、host.json はパッケージ ルートに存在する必要があります。 テストは、他の関数と一緒に 1 つのフォルダーに保存することをお勧めします (この例では tests/)。 詳細については、「単体テスト」を参照してください。
データベースへの接続
Azure Functions は、IoT、e コマース、ゲームなど、多くのユース ケースで Azure Cosmos DB と密接に統合されています。
たとえば、イベント ソーシングの場合、2 つのサービスは、Azure Cosmos DB の変更フィード機能を使用してイベント ドリブン アーキテクチャを提供するために統合されます。 変更フィードでは、段階的かつ確実に挿入と更新を読み取る (注文イベントなど) 機能をダウンストリームのマイクロサービスに提供します。 この機能を利用すれば、状態の変化するイベントのメッセージ ブローカーとして永続的なイベント ストアを提供し、多数のマイクロサービス間で注文処理ワークフローを稼働することができます (サーバーレス Azure Functions として実装可能)。
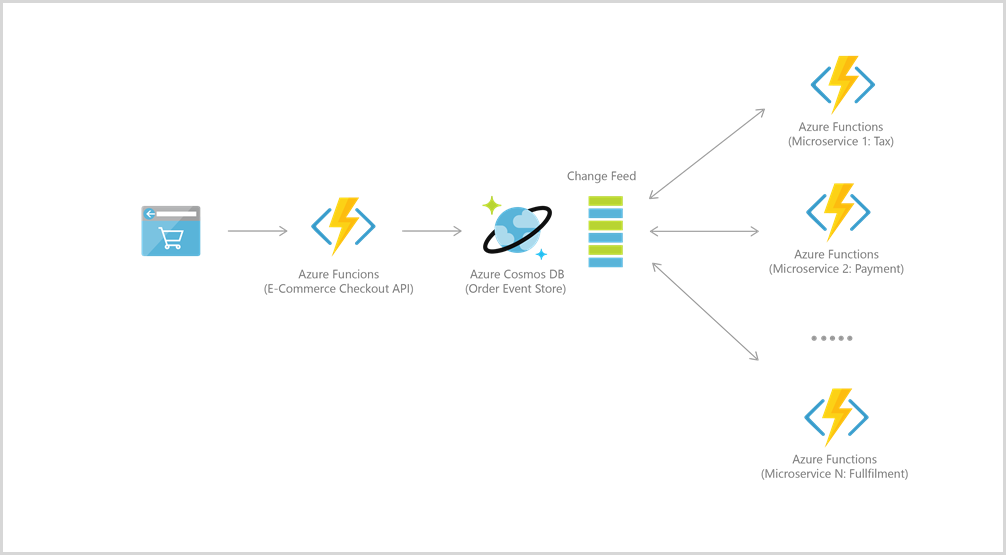
Azure Cosmos DB に接続するには、まずアカウント、データベース、コンテナーを作成します。 その後、次の例のように、トリガーとバインドを使用して、関数コードを Azure Cosmos DB に接続できます。
より複雑なアプリ ロジックを実装するには、Cosmos DB 用の Python ライブラリを使用することもできます。 非同期 I/O 実装は次のようになります。
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Blueprints
Python v2 プログラミング モデルでは、ブループリント の概念が導入されています。 ブループリントは、コア関数アプリケーションの外部で関数を登録するためにインスタンス化された新しいクラスです。 ブループリント インスタンスに登録されている関数は、関数ランタイムによって直接インデックス付けされません。 これらのブループリント関数のインデックスを作成するには、関数アプリはブループリント インスタンスから関数を登録する必要があります。
ブループリントの使用には次のような利点があります。
- 関数アプリをモジュール型コンポーネントに分割して、複数の Python ファイルで関数を定義し、ファイルごとに異なるコンポーネントに分割できます。
- 独自の API をビルドして再利用するための、拡張可能なパブリック関数アプリ インターフェイスを提供します。
次の例は、ブループリントの使用方法を示しています。
まず、http_blueprint.py ファイルで HTTP によってトリガーされる関数が最初に定義され、ブループリント オブジェクトに追加されます。
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
次に、function_app.py ファイルでブループリント オブジェクトがインポートされ、その関数が関数アプリに登録されます。
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
注意
Durable Functions では、ブループリントもサポートされています。 Durable Functions アプリのブループリントを作成するには、こちらに示すように、azure-functions-durable Blueprint クラスを使用してオーケストレーション、アクティビティ、およびエンティティ トリガーとクライアント バインドを登録します。 その後、結果のブループリントを通常どおりに登録できます。 例については、サンプルをご覧ください。
インポートの動作
絶対と相対の各参照の両方を使用して、関数コードにモジュールをインポートすることができます。 次のインポートは、前述のフォルダー構造に基づいて、関数ファイル <project_root>\my_first_function\__init__.py 内から機能します:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
注意
shared_code/ フォルダーには、絶対インポート構文を使用するときに Python パッケージとしてマークするための __init__.py ファイルが含まれている必要があります。
次の __app__ インポートおよび最上位を超える相対インポートは、静的な型チェッカーでサポートされておらず、Python テスト フレームワークでサポートされていないため非推奨です。
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
トリガーと入力
Azure Functions では、入力はトリガー入力とその他の入力の 2 つのカテゴリに分けられます。 function.json ファイルではこれらは同じではありませんが、Python コードでは同じように使用されます。 トリガーの接続文字列またはシークレットと入力ソースは、ローカル実行時には local.settings.json ファイル内の値にマップし、Azure での実行時にはアプリケーションの設定にマップします。
たとえば、次のコードでは 2 つの入力の違いが示されています。
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
この関数が呼び出されると、HTTP 要求は req として関数に渡されます。 エントリは、ルート URL 内の ID に基づいて Azure Blob Storage アカウントから取得され、関数の本体で obj として使用できるようになります。 ここで、指定されるストレージ アカウントは、CONNECTION_STRING アプリ設定で見つかる接続文字列です。
Azure Functions では、入力はトリガー入力とその他の入力の 2 つのカテゴリに分けられます。 これらは異なるデコレーターを使用して定義されていますが、Python コードでは使用方法は似ています。 トリガーの接続文字列またはシークレットと入力ソースは、ローカル実行時には local.settings.json ファイル内の値にマップし、Azure での実行時にはアプリケーションの設定にマップします。
例として、次のコードは、BLOB ストレージの入力バインドを定義する方法を示しています。
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
この関数が呼び出されると、HTTP 要求は req として関数に渡されます。 エントリは、ルート URL 内の ID に基づいて Azure Blob Storage アカウントから取得され、関数の本体で obj として使用できるようになります。 ここで、指定されるストレージ アカウントは、STORAGE_CONNECTION_STRING アプリ設定で見つかる接続文字列です。
データ集中型バインド操作の場合は、別のストレージ アカウントを使用できます。 詳しくは、「ストレージ アカウントに関するガイダンス」をご覧ください。
SDK 型バインド (プレビュー)
選択トリガーとバインドでは、基になる Azure SDK とフレームワークによって実装されたデータ型を操作できます。 これらの "SDK 型バインド" を使用すると、基になるサービス SDK を使用しているようにバインディング データとやりとりできます。
重要
SDK 型バインドのサポートには、Python v2 プログラミング モデルが必要です。
Functions では、Azure Blob Storage の Python SDK 型バインドがサポートされています。これにより、基になる BlobClient 型を使用して BLOB データを操作できます。
重要
Python に対する SDK 型バインドのサポートは現在プレビュー段階です。
- Python v2 プログラミング モデルを使用する必要があります。
- 現時点では、同期 SDK 型のみがサポートされています。
前提条件
- Azure Functions ランタイム バージョン 4.34 以降のバージョン。
- Python バージョン 3.9 以降のサポートされているバージョン。
Blob Storage 拡張機能の SDK 型バインドを有効にする
azurefunctions-extensions-bindings-blob拡張機能パッケージをプロジェクト内のrequirements.txtファイルに追加します。これには、少なくとも次のパッケージが含まれている必要があります。azure-functions azurefunctions-extensions-bindings-blob次のコードをプロジェクト内の
function_app.pyファイルに追加します。これにより、SDK 型バインドがインポートされます。import azurefunctions.extensions.bindings.blob as blob
SDK 型バインドの例
この例では、BLOB Storage トリガー (blob_trigger) と HTTP トリガーの入力バインド (blob_input) の両方から BlobClient を取得する方法を示します。
import logging
import azure.functions as func
import azurefunctions.extensions.bindings.blob as blob
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.blob_trigger(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_trigger(client: blob.BlobClient):
logging.info(
f"Python blob trigger function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
@app.route(route="file")
@app.blob_input(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_input(req: func.HttpRequest, client: blob.BlobClient):
logging.info(
f"Python blob input function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
return "ok"
Blob Storage の他の SDK 型バインドのサンプルは、Python 拡張機能リポジトリで確認できます。
HTTP ストリーム (プレビュー)
HTTP ストリームを使用すると、関数で有効になっている FastAPI 要求および応答 API を使用して、HTTP エンドポイントからのデータを受け入れて返すことができます。 これらの API を使用すると、ホストはメッセージ全体をメモリに読み込むのではなく、HTTP メッセージ内の大きなデータをチャンクとして処理できます。
この機能により、大規模なデータ ストリーム、OpenAI の統合、動的コンテンツの配信、HTTP 経由でのリアルタイムのやりとりを必要とする他のコア HTTP シナリオのサポートが可能になります。 HTTP ストリームで FastAPI 応答の種類を使用することもできます。 HTTP ストリームがない場合、HTTP 要求と応答のサイズは、メッセージ ペイロード全体をすべてメモリ内で処理するときに発生する可能性のあるメモリ制限で制限されます。
重要
HTTP ストリームのサポートには、Python v2 プログラミング モデルが必要です。
重要
Python の HTTP ストリームのサポートは現在プレビュー段階であり、Python v2 プログラミング モデルを使用する必要があります。
前提条件
- Azure Functions ランタイム バージョン 4.34.1 以降。
- Python バージョン 3.8 以降のサポートされているバージョン。
HTTP ストリームを有効にする
HTTP ストリームは既定で無効になっています。 アプリケーション設定でこの機能を有効にし、FastAPI パッケージを使用するようにコードを更新する必要があります。 HTTP ストリームを有効にすると、関数アプリでは既定で HTTP ストリーミングが使用されるため、元の HTTP 機能は機能しないことに注意してください。
azurefunctions-extensions-http-fastapi拡張機能パッケージをプロジェクト内のrequirements.txtファイルに追加します。これには、少なくとも次のパッケージが含まれている必要があります。azure-functions azurefunctions-extensions-http-fastapi次のコードをプロジェクト内の
function_app.pyファイルに追加します。これにより、FastAPI 拡張機能がインポートされます。from azurefunctions.extensions.http.fastapi import Request, StreamingResponseAzure にデプロイするときに、関数アプリに次のアプリケーション設定を追加します。
"PYTHON_ENABLE_INIT_INDEXING": "1"Linux 従量課金プランにデプロイする場合は、以下も追加します
"PYTHON_ISOLATE_WORKER_DEPENDENCIES": "1"ローカルで実行する場合は、これらの同じ設定を
local.settings.jsonプロジェクト ファイルに追加する必要もあります。
HTTP ストリームの例
HTTP ストリーミング機能を有効にすると、HTTP 経由でデータをストリーミングする関数を作成できます。
この例は、HTTP 応答データをストリーミングする HTTP でトリガーされる関数です。 これらの機能を使用して、リアルタイムの視覚化のためにパイプラインを介してイベント データを送信したり、大規模なデータ セットの異常を検出したり、インスタント通知を提供したりするなどのシナリオをサポートできます。
import time
import azure.functions as func
from azurefunctions.extensions.http.fastapi import Request, StreamingResponse
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
def generate_sensor_data():
"""Generate real-time sensor data."""
for i in range(10):
# Simulate temperature and humidity readings
temperature = 20 + i
humidity = 50 + i
yield f"data: {{'temperature': {temperature}, 'humidity': {humidity}}}\n\n"
time.sleep(1)
@app.route(route="stream", methods=[func.HttpMethod.GET])
async def stream_sensor_data(req: Request) -> StreamingResponse:
"""Endpoint to stream real-time sensor data."""
return StreamingResponse(generate_sensor_data(), media_type="text/event-stream")
この例は、クライアントからのストリーミング データをリアルタイムで受信して処理する、HTTP によってトリガーされる関数です。 これは、継続的なデータ ストリームの処理や IoT デバイスからのイベント データの処理などのシナリオに役立つストリーミング アップロード機能を示します。
import azure.functions as func
from azurefunctions.extensions.http.fastapi import JSONResponse, Request
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="streaming_upload", methods=[func.HttpMethod.POST])
async def streaming_upload(req: Request) -> JSONResponse:
"""Handle streaming upload requests."""
# Process each chunk of data as it arrives
async for chunk in req.stream():
process_data_chunk(chunk)
# Once all data is received, return a JSON response indicating successful processing
return JSONResponse({"status": "Data uploaded and processed successfully"})
def process_data_chunk(chunk: bytes):
"""Process each data chunk."""
# Add custom processing logic here
pass
HTTP ストリームの呼び出し
関数の FastAPI エンドポイントにストリーミング呼び出しを行うには、HTTP クライアント ライブラリを使用する必要があります。 お使いのクライアント ツールまたはブラウザーが、ストリーミングをネイティブにサポートしていないか、データの最初のチャンクのみを返す場合があります。
次のようなクライアント スクリプトを使用して、ストリーミング データを HTTP エンドポイントに送信できます。
import httpx # Be sure to add 'httpx' to 'requirements.txt'
import asyncio
async def stream_generator(file_path):
chunk_size = 2 * 1024 # Define your own chunk size
with open(file_path, 'rb') as file:
while chunk := file.read(chunk_size):
yield chunk
print(f"Sent chunk: {len(chunk)} bytes")
async def stream_to_server(url, file_path):
timeout = httpx.Timeout(60.0, connect=60.0)
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.post(url, content=stream_generator(file_path))
return response
async def stream_response(response):
if response.status_code == 200:
async for chunk in response.aiter_raw():
print(f"Received chunk: {len(chunk)} bytes")
else:
print(f"Error: {response}")
async def main():
print('helloworld')
# Customize your streaming endpoint served from core tool in variable 'url' if different.
url = 'http://localhost:7071/api/streaming_upload'
file_path = r'<file path>'
response = await stream_to_server(url, file_path)
print(response)
if __name__ == "__main__":
asyncio.run(main())
出力
出力は、戻り値および出力パラメーターの両方で表現できます。 出力が 1 つのみの場合は、戻り値の使用をお勧めします。 複数の出力の場合は、出力パラメーターを使用する必要があります。
出力バインディングの値として関数の戻り値を使用するには、バインディングの name プロパティを function.json ファイル内の $return に設定する必要があります。
複数の出力を生成するには、azure.functions.Out インターフェイスによって提供される set() メソッドを使用して、バインディングに値を割り当てます。 たとえば、次の関数を使用すると、キューにメッセージをプッシュすることに加え、HTTP 応答を返すこともできます。
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
出力は、戻り値および出力パラメーターの両方で表現できます。 出力が 1 つのみの場合は、戻り値の使用をお勧めします。 出力が複数の場合は、出力パラメーターを使用する必要があります。
複数の出力を生成するには、azure.functions.Out インターフェイスによって提供される set() メソッドを使用して、バインディングに値を割り当てます。 たとえば、次の関数を使用すると、キューにメッセージをプッシュすることに加え、HTTP 応答を返すこともできます。
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
ログ記録
Azure Functions ランタイム ロガーへのアクセスは、ご利用の関数アプリ内のルート logging ハンドラーを介して利用できます。 このロガーは Application Insights に関連付けられているため、関数の実行中に発生する警告とエラーにフラグを設定することができます。
次の例では、HTTP トリガーを介して関数が呼び出されるときに、情報メッセージが記録されます。
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
他にも次のようなログ記録メソッドが用意されています。これにより、さまざまなトレース レベルでコンソールへの書き込みが可能になります。
| 方法 | 説明 |
|---|---|
critical(_message_) |
ルート ロガー上に CRITICAL レベルのメッセージを書き込みます。 |
error(_message_) |
ルート ロガー上に ERROR レベルのメッセージを書き込みます。 |
warning(_message_) |
ルート ロガー上に WARNING レベルのメッセージを書き込みます。 |
info(_message_) |
ルート ロガー上に INFO レベルのメッセージを書き込みます。 |
debug(_message_) |
ルート ロガー上に DEBUG レベルのメッセージを書き込みます。 |
ログ記録の詳細については、「Azure Functions を監視する」を参照してください。
作成されたスレッドからのログ
作成されたスレッドからのログを表示するには、関数のシグネチャに context 引数を含めます。 この引数には、ローカルの invocation_id を保存する属性 thread_local_storage が含まれています。 これは、コンテキストが確実に変更されるように、関数の現在の invocation_id に設定できます。
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
カスタム テレメトリをログに記録する
既定では、Functions ランタイムには、関数によって生成されたログとその他のテレメトリ データが収集されます。 このテレメトリは、Application インサイト のトレースとして終了します。 特定の Azure サービスの要求と依存関係のテレメトリは、既定でトリガーおよびバインディングでも収集されます。
バインディングの外部でカスタム要求やカスタム依存関係テレメトリを収集するには、OpenCensus Python Extensions を使用できます。 この拡張機能は、カスタム テレメトリ データを Application Insights インスタンスに送信します。 サポートされている拡張機能の一覧は、OpenCensus リポジトリで確認できます。
Note
OpenCensus Python 拡張機能を使用するには、PYTHON_ENABLE_WORKER_EXTENSIONS を 1 に設定して、関数アプリの Python 拡張機能を有効にする必要があります。 また、アプリケーション設定がまだ存在しない場合は、そのAPPLICATIONINSIGHTS_CONNECTION_STRING への APPLICATIONINSIGHTS_CONNECTION_STRING 設定を追加して、Application Insights 接続文字列を使用するように切り替える必要があります。
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
HTTP トリガー
HTTP トリガーは function.json ファイルで定義されています。 バインディングの name は、関数の名前付きパラメーターと一致している必要があります。
前の例では、バインド名 req が使用されています。 このパラメーターは HttpRequest オブジェクトであり、HttpResponse オブジェクトが返されます。
HttpRequest オブジェクトからは、要求ヘッダー、クエリ パラメーター、ルート パラメーター、およびメッセージ本文を取得できます。
次の例は、Python 用の HTTP トリガー テンプレートからのものです。
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
この関数では、name クエリ パラメーターの値は HttpRequest オブジェクトの params パラメーターから取得されます。 JSON でエンコードされたメッセージ本文は get_json メソッドを使用して読み取ります。
同様に、返される status_code オブジェクトに応答メッセージの status_code および headers を設定できます。
HTTP トリガーは、HttpRequest オブジェクトである名前付きバインディング パラメーターを受け取り、HttpResponse オブジェクトを返すメソッドであると定義されます。 function_name デコレーターをメソッドに適用して関数名を定義しますが、HTTP エンドポイントは route デコレーターを適用することで設定します。
この例は、Python v2 プログラミング モデルの HTTP トリガー テンプレートのものであり、バインディング パラメーター名は req です。 これは、Azure Functions Core Tools または Visual Studio Code を使用して関数を作成するときに提供されるサンプル コードです。
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
HttpRequest オブジェクトからは、要求ヘッダー、クエリ パラメーター、ルート パラメーター、およびメッセージ本文を取得できます。 この関数では、name クエリ パラメーターの値は HttpRequest オブジェクトの params パラメーターから取得されます。 JSON でエンコードされたメッセージ本文は get_json メソッドを使用して読み取ります。
同様に、返される status_code オブジェクトに応答メッセージの status_code および headers を設定できます。
この例で名前を渡すには、関数の実行時に指定された URL を貼り付けてから、それに "?name={name}" を付加します。
Web フレームワーク
Flask や FastAPI などの Web Server Gateway Interface (WSGI) 互換および Asynchronous Server Gateway Interface (ASGI) 互換フレームワークを、HTTP によってトリガーされる Python 関数と共に使用できます。 このセクションでは、これらのフレームワークをサポートするために関数を変更する方法を示します。
まず、次の例に示すように、function.json ファイルを更新して、HTTP トリガーに route を含める必要があります。
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
次の例に示すように、host.json ファイルを更新して、HTTP routePrefix を含める必要があります。
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
フレームワークで使用されるインターフェイスに応じて、Python コード ファイル init.py を更新します。 次の例では、ASGI ハンドラー アプローチまたは Flask の WSGI ラッパー アプローチのいずれかを示します。
Flask や FastAPI などの Asynchronous Server Gateway Interface (ASGI) 互換フレームワークおよび Web Server Gateway Interface (WSGI) 互換フレームワーク (Flask や FastAPI など) を、HTTP によってトリガーされる Python 関数と共に使用できます。 次の例に示すように、最初に host.json ファイルを更新して、HTTP routePrefix を含める必要があります。
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
フレームワーク コードは次の例のようになります。
AsgiFunctionApp は、ASGI HTTP 関数を構築するための最上位の関数アプリ クラスです。
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
スケーリングとパフォーマンス
Python 関数アプリのスケーリングとパフォーマンスのベスト プラクティスについては、Python のスケーリングとパフォーマンスに関する記事を参照してください。
Context
実行時に関数の呼び出しコンテキストを取得するには、そのシグニチャに context 引数を含めます。
例:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Context クラスには次の文字列属性が含まれています。
| 属性 | 説明 |
|---|---|
function_directory |
関数が実行されるディレクトリです。 |
function_name |
関数の名前です。 |
invocation_id |
現在の関数呼び出しの ID です。 |
thread_local_storage |
関数のスレッド ローカル ストレージ。 作成されたスレッドからのログ用のローカルの invocation_id が含まれています。 |
trace_context |
分散トレース用のコンテキスト。 詳細については、「Trace Context」を参照してください。 |
retry_context |
関数への再試行のコンテキスト。 詳細については、「retry-policies」を参照してください。 |
グローバル変数
将来の実行に対してアプリの状態が保持されることは保証されません。 ただし、Azure Functions ランタイムでは、多くの場合、同じアプリの複数の実行に対して同じプロセスが再利用されます。 高コストの計算の結果をキャッシュするには、グローバル変数として宣言します。
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
環境変数
Azure Functions では、サービス接続文字列などのアプリケーション設定は、実行時に環境変数として公開されます。 コードでこれらの設定にアクセスするには、主に 2 つの方法があります。
| Method | 説明 |
|---|---|
os.environ["myAppSetting"] |
アプリケーション設定をキー名で取得しようとして失敗した場合はエラーを発生させます。 |
os.getenv("myAppSetting") |
アプリケーション設定をキー名で取得しようとして成功した場合は None を返します。 |
どちらの方法も、import os を宣言する必要があります。
次の設定では、os.environ["myAppSetting"] を使用して myAppSetting という名前のキーのos.environ["myAppSetting"]が取得されます。
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
ローカル開発の場合、アプリケーション設定は local.settings.json ファイルに保持されます。
Azure Functions では、サービス接続文字列などのアプリケーション設定は、実行時に環境変数として公開されます。 コードでこれらの設定にアクセスするには、主に 2 つの方法があります。
| Method | 説明 |
|---|---|
os.environ["myAppSetting"] |
アプリケーション設定をキー名で取得しようとして失敗した場合はエラーを発生させます。 |
os.getenv("myAppSetting") |
アプリケーション設定をキー名で取得しようとして成功した場合は None を返します。 |
どちらの方法も、import os を宣言する必要があります。
次の設定では、os.environ["myAppSetting"] を使用して myAppSetting という名前のキーのos.environ["myAppSetting"]が取得されます。
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
ローカル開発の場合、アプリケーション設定は local.settings.json ファイルに保持されます。
Python バージョン
Azure Functions では次の Python バージョンがサポートされています。
| Functions バージョン | Python* バージョン |
|---|---|
| 4.x | 3.11 3.10 3.9 3.8 3.7 |
| 3.x | 3.9 3.8 3.7 |
* 公式の Python ディストリビューション
Azure で関数アプリを作成するときに特定の Python バージョンを要求するには、az functionapp create コマンドの --runtime-version オプションを使用します。 Functions ランタイム バージョンは --functions-version オプションによって設定されます。 Python バージョンは、関数アプリの作成時に設定され、従量課金プランで実行されているアプリでは変更できません。
ローカル環境で実行するときは、ランタイムは使用可能な Python のバージョンを使用します。
Python バージョンの変更
Python 関数アプリを特定の言語バージョンに設定するには、サイトの構成の LinuxFxVersion フィールドで言語と言語のバージョンを指定する必要があります。 たとえば、Python 3.8 を使用するように Python アプリを変更するには、linuxFxVersion を python|3.8 に設定します。
linuxFxVersion サイト設定を表示および変更する方法については、「Azure Functions のランタイム バージョンを対象とする方法」を参照してください。
一般的な情報については、Azure Functions のランタイム サポート ポリシーに関するページおよび「Azure Functions でサポートされている言語」を参照してください。
パッケージの管理
Core Tools または Visual Studio Code を使用してローカルで開発を行う場合は、必要なパッケージの名前とバージョンを requirements.txt ファイルに追加し、pip を使用してそれらをインストールしてください。
たとえば、次の requirements.txt ファイルと pip コマンドを使用すれば、PyPI から requests パッケージをインストールすることができます。
requests==2.19.1
pip install -r requirements.txt
App Service プランで関数を実行する場合、requirements.txt で定義した依存関係は、logging などの組み込みの Python モジュールよりも優先されます。 組み込みモジュールがコード内のディレクトリと同じ名前である場合、この優先順位によって競合が生じる可能性があります。 従量課金プランまたは Elastic Premium プランで実行している場合、既定では依存関係に優先順位が設定されていないため、競合が生じる可能性は低くなります。
App Service プランで実行される問題を防ぐには、ディレクトリに Python ネイティブ モジュールと同じ名前を付けたり、プロジェクトの requirements.txt ファイルに Python ネイティブ ライブラリを含めたりしないでください。
Azure への発行
発行する準備ができたら、一般公開されているすべての依存関係が、requirements.txt ファイルに列記されていることを確認します。 このファイルは、プロジェクト ディレクトリのルートにあります。
発行から除外されたプロジェクト ファイルとフォルダー (仮想環境フォルダーなど) は、プロジェクトのルート ディレクトリにあります。
Python プロジェクトを Azure に発行するために、リモート ビルド、ローカル ビルド、およびカスタム依存関係を使用したビルドの 3 つのビルド アクションがサポートされています。
Azure Pipelines を使用して依存関係をビルドし、継続的デリバリー (CD) を使用して発行することもできます。 詳細については、「Azure Pipelines を使用した継続的デリバリー」を参照してください。
リモート ビルド
リモート ビルドを使用する場合、サーバー上に復元された依存関係とネイティブの依存関係は運用環境と一致します。 これにより、アップロードするデプロイ パッケージが小さくなります。 Windows 上で Python アプリを開発する場合は、リモート ビルドを使用します。 プロジェクトにカスタム依存関係がある場合は、追加のインデックスの URL を使用するリモート ビルドを使用することができます。
依存関係は、requirements.txt ファイルの内容に基づいてリモートで取得されます。 リモート ビルド は推奨されるビルド方法です。 次の func azure functionapp publish コマンドを使用して Python プロジェクトを Azure に発行すると、既定では Core Tools によってリモート ビルドが要求されます。
func azure functionapp publish <APP_NAME>
<APP_NAME> を、Azure 内のご自分の関数アプリの名前に置き換えることを忘れないでください。
Visual Studio Code の Azure Functions 拡張機能も、既定ではリモート ビルドを要求します。
ローカル ビルド
依存関係は、requirements.txt ファイルの内容に基づいてローカルで取得されます。 次の func azure functionapp publish コマンドを使用してローカル ビルドとして発行することで、リモート ビルドを実行しないようにすることができます。
func azure functionapp publish <APP_NAME> --build local
<APP_NAME> を、Azure 内のご自分の関数アプリの名前に置き換えることを忘れないでください。
--build local オプションを使うと、プロジェクトの依存関係が requirements.txt ファイルから読み取られ、これらの依存パッケージがローカルにダウンロードされ、インストールされます。 プロジェクト ファイルと依存関係は、ローカル コンピューターから Azure にデプロイされます。 これにより、大きいサイズのデプロイ パッケージが Azure にアップロードされます。 何らかの理由で、コア ツールを使って requirements.txt ファイルを取得できない場合は、発行でカスタム依存関係オプションを使う必要があります。
Windows でローカルに開発する場合は、ローカル ビルドの使用をお勧めしません。
カスタムの依存関係
Python パッケージ インデックスにない依存関係がプロジェクトにある場合、2 つの方法でプロジェクトをビルドすることができます。 最初のビルド方法は、プロジェクトのビルド方法によって異なります。
追加のインデックスの URL を使用するリモート ビルド
アクセス可能なカスタム パッケージ インデックスからパッケージを取得できる場合は、リモート ビルドを使用します。 発行する前に、必ず、PIP_EXTRA_INDEX_URL という名前のアプリ設定を作成してください。 この設定の値は、カスタム パッケージ インデックスの URL です。 この設定は、リモート ビルドで --extra-index-url オプションを使用して pip install を実行することを指示するために使用します。 詳細については、Pythonpip install に関するドキュメントを参照してください。
また、基本認証の資格情報を追加のパッケージ インデックスの URL と共に使用することもできます。 詳細については、Python ドキュメントの「基本認証の資格情報」を参照してください。
ローカル パッケージをインストールする
当社のツール向けに公開されていないパッケージをプロジェクトに使用している場合は、それを __app__/.python_packages ディレクトリに配置することで、アプリで使用可能にすることができます。 発行する前に次のコマンドを実行して、依存関係をローカルでインストールします。
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
カスタムの依存関係を使用する場合は、既に依存関係がプロジェクト フォルダーにインストールされているため、--no-build 発行オプションを使用する必要があります。
func azure functionapp publish <APP_NAME> --no-build
<APP_NAME> を、Azure 内のご自分の関数アプリの名前に置き換えることを忘れないでください。
単体テスト
Python で記述された関数は、標準的なテスト フレームワークを使用して、他の Python コードのようにテストできます。 ほとんどのバインドでは、azure.functions パッケージから適切なクラスのインスタンスを作成することにより、モック入力オブジェクトを作成できます。 azure.functions パッケージはすぐには利用できないため、前の「パッケージの管理」セクションで説明されているように、requirements.txt ファイルを使用してインストールしてください。
my_second_function を例にとると、次に示すのは、HTTP によってトリガーされる関数のモック テストです。
最初に、<project_root>/my_second_function/function.json ファイルを作成し、この関数を HTTP トリガーとして定義します。
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
次に、my_second_function と shared_code.my_second_helper_function を実装できます。
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
HTTP トリガーのテスト ケースの記述を開始できます。
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
.venv の Python 仮想環境フォルダー内で、任意の Python テスト フレームワーク (pip install pytest など) をインストールします。 続いて pytest tests を実行して、テスト結果を確認します。
まず、<project_root>/function_app.py ファイルを作成し、my_second_function 関数 HTTP トリガーおよび shared_code.my_second_helper_function として実装します。
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
HTTP トリガーのテスト ケースの記述を開始できます。
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
.venv の Python 仮想環境フォルダー内で、任意の Python テスト フレームワーク (pip install pytest など) をインストールします。 続いて pytest tests を実行して、テスト結果を確認します。
一時ファイル
tempfile.gettempdir() メソッドは一時フォルダーを返します。Linux では /tmp です。 関数が実行されているときに生成および使用する一時ファイルを格納するために、アプリケーションでこのディレクトリを使用できます。
重要
一時ディレクトリに書き込まれるファイルは、呼び出しをまたいで保持されることは保証されません。 スケールアウトの間、一時ファイルはインスタンス間で共有されません。
次の例では、名前付きの一時ファイルを一時ディレクトリ (/tmp) に作成します。
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
テストは、プロジェクト フォルダーとは別のフォルダーに保存することをお勧めします。 このアクションにより、アプリでテスト コードをデプロイすることを防ぐことができます。
プレインストール済みライブラリ
Python Functions ランタイムには、いくつかのライブラリが付属しています。
Python 標準ライブラリ
Python 標準ライブラリには、各 Python ディストリビューションに同梱されている組み込み Python モジュールの一覧が含まれています。 これらのライブラリのほとんどは、ファイル入出力 (I/O) などのシステム機能へのアクセスに役立ちます。 Windows システムでは、これらのライブラリは Python と共にインストールされます。 Unix ベースのシステムでは、これらはパッケージ コレクションによって提供されます。
Python バージョンのライブラリを表示するには、次の手順を実行します。
Azure Functions Python worker の依存関係
Azure Functions Python worker は、特定のライブラリ セットを必要とします。 これらのライブラリは、関数内で使用することもできますが、Python 標準の一部ではありません。 対象の関数がこれらのライブラリのいずれかに依存している場合、Azure Functions の外部で実行したときにコードでそれらのライブラリを使用できない場合があります。
Note
関数アプリの requirements.txt に azure-functions-worker エントリが含まれている場合は、それを削除します。 Functions worker は Azure Functions プラットフォームによって自動的に管理され、新しい機能とバグの修正のための更新が定期的に行われます。 古いバージョンの worker を requirements.txt に手動で組み込むと、予期しない問題が発生する可能性があります。
Note
worker の依存関係と競合する可能性がある特定のライブラリ (protobuf、tensorflow、grpcio など) がパッケージに含まれている場合は、アプリの設定で PYTHON_ISOLATE_WORKER_DEPENDENCIES を 1 に設定して、アプリケーションで worker の依存関係を参照しないようにしてください。
Azure Functions Python ライブラリ
すべての Python worker の更新プログラムには、新しいバージョンの Azure Functions Python ライブラリ (azure.functions) が含まれています。 各更新プログラムには下位互換性があるため、これで簡単に Python 関数アプリを継続的に更新できるようになります。 このライブラリのリリースの一覧は、azure-functions PyPi で確認できます。
ランタイム ライブラリのバージョンは Azure によって修正され、requirements.txt で上書きすることはできません。 requirements.txt の azure-functions エントリは、リンティングと顧客意識のためだけに用意されています。
対象のランタイムの Python Functions ライブラリの実際のバージョンを追跡するには、次のコードを使用します。
getattr(azure.functions, '__version__', '< 1.2.1')
ランタイム システム ライブラリ
Python worker の Docker イメージにプレインストールされているシステム ライブラリの一覧については、以下を参照してください。
| Functions ランタイム | Debian のバージョン | Python のバージョン |
|---|---|---|
| バージョン 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Python worker 拡張機能
Azure Functions で実行される Python worker プロセスを使用すると、サードパーティ製ライブラリを関数アプリに統合できます。 これらの拡張ライブラリは、関数の実行のライフサイクル中に特定の操作を挿入できるミドルウェアとして機能します。
これらの拡張機能は、標準の Python ライブラリ モジュールと同様に関数コードにインポートされます。 拡張機能は、次のスコープに基づいて実行されます。
| Scope | 説明 |
|---|---|
| アプリケーション レベル | 関数トリガーにインポートされると、拡張機能はアプリ内のすべての関数実行に適用されます。 |
| 関数レベル | インポート先の特定の関数トリガーにのみ実行が制限されます。 |
各拡張機能に関する情報を参照して、拡張機能が実行されるスコープの詳細を確認してください。
拡張機能で、Python worker 拡張機能インターフェイスが実装されます。 このアクションにより、Python worker プロセスは関数実行ライフサイクルの間に拡張機能のコードを呼び出すことができます。 詳細については、「拡張機能の作成」を参照してください。
拡張機能の使用
お使いの Python 関数で Python worker 拡張機能ライブラリを使用するには、次の手順を実行します。
- 拡張機能パッケージをプロジェクトの requirements.txt ファイルに追加します。
- ライブラリをアプリにインストールします。
- 次のアプリケーション設定を追加します。
- ローカル: local.settings.json ファイルの
Valuesセクションに"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"を追加します - Azure: アプリの設定に「
PYTHON_ENABLE_WORKER_EXTENSIONS=1」と入力します。
- ローカル: local.settings.json ファイルの
- 関数トリガーに拡張機能モジュールをインポートします。
- 必要に応じて、拡張機能インスタンスを構成します。 構成要件は、拡張機能のドキュメントに明記されているはずです。
重要
サード パーティ製の Python worker 拡張機能ライブラリについては、Microsoft はサポートも保証もしていません。 関数アプリで使用する拡張機能が信頼できることを確認する必要があります。悪意のある、または適切に作成されていない拡張機能を使用するリスクはすべてお客様が負うこととなります。
サードパーティは、関数アプリに拡張機能をインストールして使用する方法に関する具体的なドキュメントを提供する必要があります。 拡張機能の使用方法の基本的な例については、拡張機能の使用に関するページを参照してください。
以下に、関数アプリで拡張機能を使用する例をスコープ別に示します。
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
拡張機能の作成
拡張機能は、Azure Functions に統合可能な機能を作成したサードパーティ製ライブラリの開発者によって作成されます。 拡張機能の開発者は、関数実行のコンテキストで実行されるように特別に設計されたカスタム ロジックを含む Python パッケージを設計、実装、リリースします。 これらの拡張機能は、PyPI レジストリまたは GitHub リポジトリに発行できます。
Python worker 拡張機能パッケージを作成、パッケージ化、発行、使用する方法については、「Azure Functions 用の Python worker 拡張機能の開発」を参照してください。
アプリケーション レベルの拡張機能
AppExtensionBase から継承された拡張機能は、アプリケーション スコープで実行されます。
AppExtensionBase は、実装のための次の抽象クラス メソッドを公開します。
| 方法 | 説明 |
|---|---|
init |
拡張機能がインポートされた後に呼び出されます。 |
configure |
拡張機能を構成する必要がある場合に、関数コードから呼び出されます。 |
post_function_load_app_level |
関数が読み込まれた直後に呼び出されます。 関数名と関数ディレクトリが拡張機能に渡されます。 関数ディレクトリは読み取り専用であり、このディレクトリ内のローカル ファイルに書き込もうとしても失敗することに注意してください。 |
pre_invocation_app_level |
関数がトリガーされる直前に呼び出されます。 関数コンテキストと関数呼び出しの引数が、拡張機能に渡されます。 通常、他の属性をコンテキスト オブジェクトで渡して、関数コードで使用することができます。 |
post_invocation_app_level |
関数の実行が完了した直後に呼び出されます。 関数コンテキスト、関数呼び出しの引数、呼び出しの戻りオブジェクトが拡張機能に渡されます。 これは、ライフサイクル フックの実行が成功したかどうかを検証するのに適した実装です。 |
関数レベルの拡張機能
FuncExtensionBase から継承された拡張機能は、特定の関数トリガーで実行されます。
FuncExtensionBase は、実装のための次の抽象クラス メソッドを公開します。
| 方法 | 説明 |
|---|---|
__init__ |
拡張機能のコンストラクター。 これは、拡張機能インスタンスが特定の関数で初期化されると呼び出されます。 この抽象メソッドを実装する際、適切な拡張機能登録のために、filename パラメーターを受け入れて、親のメソッド super().__init__(filename) に渡すことが必要になる場合があります。 |
post_function_load |
関数が読み込まれた直後に呼び出されます。 関数名と関数ディレクトリが拡張機能に渡されます。 関数ディレクトリは読み取り専用であり、このディレクトリ内のローカル ファイルに書き込もうとしても失敗することに注意してください。 |
pre_invocation |
関数がトリガーされる直前に呼び出されます。 関数コンテキストと関数呼び出しの引数が、拡張機能に渡されます。 通常、他の属性をコンテキスト オブジェクトで渡して、関数コードで使用することができます。 |
post_invocation |
関数の実行が完了した直後に呼び出されます。 関数コンテキスト、関数呼び出しの引数、呼び出しの戻りオブジェクトが拡張機能に渡されます。 これは、ライフサイクル フックの実行が成功したかどうかを検証するのに適した実装です。 |
クロス オリジン リソース共有
Azure Functions では、クロス オリジン リソース共有 (CORS) がサポートされています。 CORS はポータル内で、Azure CLI によって構成されます。 CORS の許可配信元一覧は、関数アプリ レベルで適用されます。 CORS を有効にすると、応答に Access-Control-Allow-Origin ヘッダーが含まれます。 詳細については、「 クロス オリジン リソース共有」を参照してください。
クロスオリジン リソース共有 (CORS) は、Python 関数アプリで完全にサポートされています。
Async
既定では、Python のホスト インスタンスは、一度に 1 つの関数呼び出しのみを処理できます。 これは、Python がシングル スレッド ランタイムのためです。 多数の I/O イベントを処理する、または I/O バインドされている関数アプリの場合、関数を非同期的に実行することでパフォーマンスを大幅に向上させることができます。 詳細については、「Azure Functions での Python アプリのパフォーマンス向上」を参照してください。
共有メモリ プロトコル (プレビュー)
スループットを向上させるために、Azure Functions では、プロセス外の Python 言語ワーカーが Functions ホスト プロセスとメモリを共有できます。 関数アプリがボトルネックになっている場合は、 \FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLEDという名前のアプリケーション設定を1値に追加して、共有メモリを有効にすることができます。 共有メモリを有効にすると、DOCKER_SHM_SIZE 設定を使用して、共有メモリを 268435456 のような ものに設定できます。これは 256 MB に相当します。
たとえば、Blob ストレージ バインドを使用して 1 MB を超えるペイロードを転送する際、共有メモリを有効にするとボトルネックを減らすことができます。
この機能は、プレミアムおよび専用 (Azure App Service) プランで実行されている関数アプリに対してのみ使用できます。 詳細については、「共有メモリ」を参照してください。
既知の問題とよくあるご質問
以下に一般的な問題に対する 2 つのトラブルシューティング ガイドを示します。
以下に、v2 プログラミング モデルに関する既知の問題に対する 2 つのトラブルシューティング ガイドを示します。
既知の問題と機能に関する要望はすべて、GitHub issues リストで追跡されます。 問題が発生してその問題が GitHub で見つからない場合は、新しい Issue を開き、その問題の詳細な説明を記載してお知らせください。
次のステップ
詳細については、次のリソースを参照してください。