Document Intelligence サンプル ラベル付けツールの使用を開始する
このコンテンツの適用対象: ![]() v2.1。
v2.1。
ヒント
- 強化されたエクスペリエンスと高度なモデル品質のためには、Document Intelligence v3.0 Studio をお試しください。
- v3.0 Studio では、v2.1 ラベル付きデータでトレーニングされたすべてのモデルがサポートされます。
- v2.1 から v3.0 への移行の詳細については、API 移行ガイドを参照してください。
- v3.0 バージョンで作業開始するには、REST API または、C#、Java、JavaScript、Python の SDK クイックスタートを "参照" してください。
Azure AI Document Intelligence サンプル ラベル付けツールは Document Intelligence および光学式文字認識 (OCR) サービスの次に示す最新の機能をテストできるようにするオープンソース ツールです。
レイアウト API を使用してドキュメントを分析します。 レイアウト API を試して、ドキュメントからテキスト、テーブル、選択マーク、および構造を抽出します。
事前構築済みモデルモデルを使用してドキュメントを分析します。 事前構築済みモデルから開始して、請求書、領収書、ID ドキュメント、または名刺からデータを抽出します。
カスタム フォームのトレーニングと解析。 カスタム モデルを使用して、個別のビジネス データおよびユース ケースに固有のドキュメントからデータを抽出します。
前提条件
作業を開始するには、次のものが必要です。
Azure サブスクリプション — 無料で作成することができます
Azure AI サービスまたは Document Intelligence リソース。 Azure サブスクリプションを用意できたら、Azure portal で単一サービスまたはマルチサービスの Document Intelligence リソースを作成し、キーとエンドポイントを取得します。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。ヒント
1 つのエンドポイント/キーで複数の Azure AI サービスにアクセスする予定の場合は、Azure AI サービス リソースを作成します。 Document Intelligence へのアクセスのみの場合は、Document Intelligence リソースを作成します。 Microsoft Entra 認証を使用する場合は、単一サービス リソースが必要になることに注意してください。
Document Intelligence リソースを作成する
Azure portal に移動し新しい Document Intelligence リソースを作成します。 [作成] ウィンドウには以下の情報が表示されます。
| プロジェクトの詳細 | 説明 |
|---|---|
| サブスクリプション | アクセスが許可されている Azure サブスクリプションを選択します。 |
| リソース グループ | ご利用のリソースを含んだ Azure リソース グループ。 新しいグループを作成することも、既存のグループに追加することもできます。 |
| リージョン | Azure AI サービス リソースの場所。 別の場所を選択すると待機時間が生じる可能性がありますが、リソースのランタイムの可用性には影響しません。 |
| 名前 | リソースのわかりやすい名前。 わかりやすい名前 (MyNameFaceAPIAccount など) を使用することをお勧めします。 |
| 価格レベル | リソースのコストは、選択した価格レベルと使用量に依存します。 詳細については、「API の価格の詳細」をご覧ください。 |
| [確認および作成] | [確認および作成] ボタンを選択して、Azure portal にリソースをデプロイします。 |
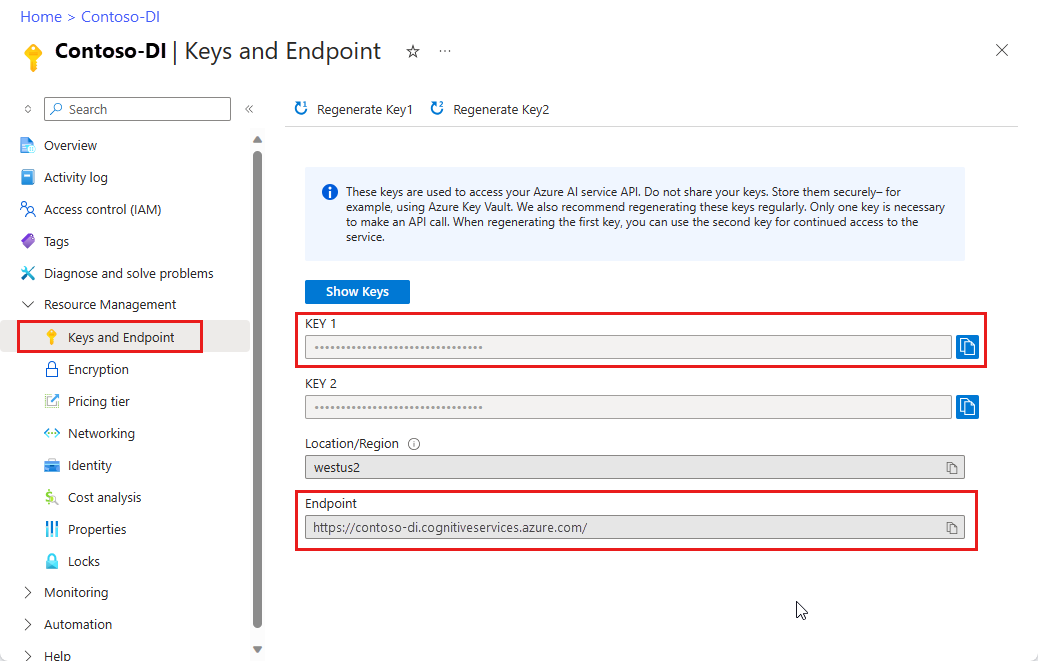
キーとエンドポイントを取得する
Document Intelligence リソースのデプロイが完了したら、ポータルの [すべてのリソース] リストからそれを見つけて選択します。 キーとエンドポイントは、リソースの [キーとエンドポイント] ページの [リソース管理] に配置されます。 これらの両方を一時的な場所に保存してから、先に進んでください。
事前構築済みモデルを使用して分析する
Document Intelligence では、いくつかの事前構築済みモデルから選択を行えます。 各モデルには、サポートされているフィールドの独自のセットがあります。 Analyze 操作に使用するモデルは、分析するドキュメントの種類によって異なります。 Document Intelligence サービスで現在サポートされている事前構築済みモデルを次に示します。
- 請求書: 請求書からテキスト、選択マーク、テーブル、キーと値のペア、キー情報を抽出します。
- レシート: レシートからテキストとキー情報を抽出します。
- 身分証明書: 運転免許証と国際パスポートからテキストとキー情報を抽出します。
- 名刺: 名刺からテキストとキー情報を抽出します。
サンプル ツールのホーム ページで、[事前構築済みモデルを使用してデータを取得する] タイルを選択します。
ドロップダウン メニューから、分析する [フォームの種類] を選択します。
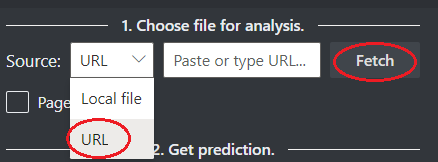
次のオプションを使用して、分析するファイルの URL を選択します。
[ソース] フィールドで、ドロップダウン メニューから [URL] を選択し、選択した URL を貼り付けて、[フェッチ] ボタンを選択します。
[Document Intelligence サービス エンドポイント] フィールドに、Document Intelligence サブスクリプションで取得したエンドポイントを貼り付けます。
[キー] フィールドに、Document Intelligence リソースから取得したキーを貼り付けます。
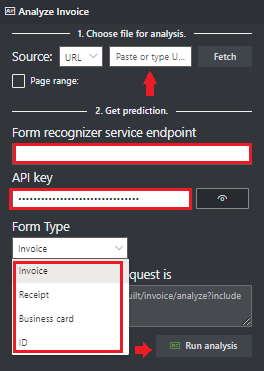
[Run analysis](解析の実行) を選択します。 Document Intelligence サンプル ラベル付けツールは、Analyze Prebuilt API を呼び出してドキュメントを分析します。
結果を表示する - 抽出されたキーと値のペア、行項目、抽出された強調表示テキスト、および検出されたテーブルを確認します。
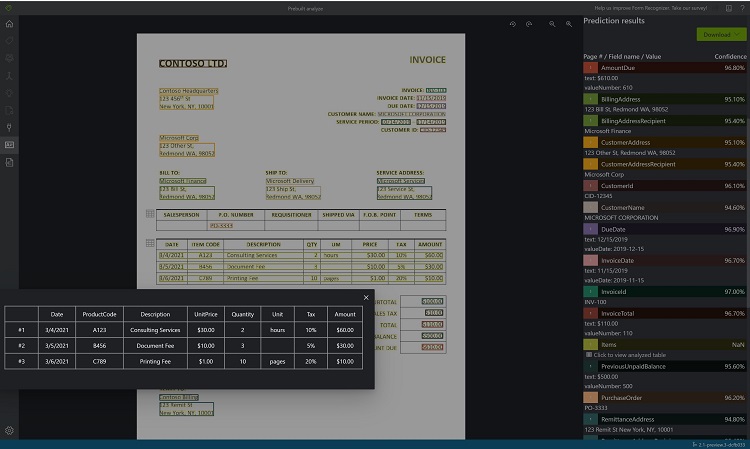
JSON 出力ファイルをダウンロードして、詳細なレイアウト結果を表示します。
- "readResults" ノードには、あらゆるテキスト行が、ページ上の対応する境界ボックスの配置と共に表示されます。
- "selectionMarks" ノードには、すべての選択マーク (チェック ボックス、ラジオ マーク) と、その状態が
selectedとunselectedのどちらであるかが示されます。 - 抽出された表は、"pageResults" セクションに含まれています。 それぞれの表について、テキスト、行インデックス、列インデックス、行スパン、列スパン、境界ボックスなどが抽出されます。
- "documentResults" フィールドには、キーと値のペアの情報と、ドキュメントの最も関連性の高い部分の行項目の情報が含まれます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
レイアウトを分析する
Azure Document Intelligence Layout API はドキュメント (PDF、TIFF) と画像 (JPG、PNG、BMP) から、テキスト、テーブル、選択マーク、構造情報を抽出します。
サンプル ツールのホーム ページで、[Use Layout to get text, tables and selection marks](レイアウトを使用してテキスト、テーブル、選択マークを取得する) を選択します。
[Document Intelligence サービス エンドポイント] フィールドに、Document Intelligence サブスクリプションで取得したエンドポイントを貼り付けます。
[キー] フィールドに、Document Intelligence リソースから取得したキーを貼り付けます。
[ソース] フィールドで、ドロップダウン メニューから [URL] を選択し、URL
https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/layout-page-001.jpgを貼り付けて、[フェッチ] ボタンを選択します。[Run Layout](レイアウトの実行) を選択します。 Document Intelligence サンプル ラベル付けツールを使用すると、
Analyze Layout APIの呼び出しとドキュメントの分析が行われます。
結果を表示する - 抽出された強調表示テキスト、検出された選択マーク、検出されたテーブルを確認します。
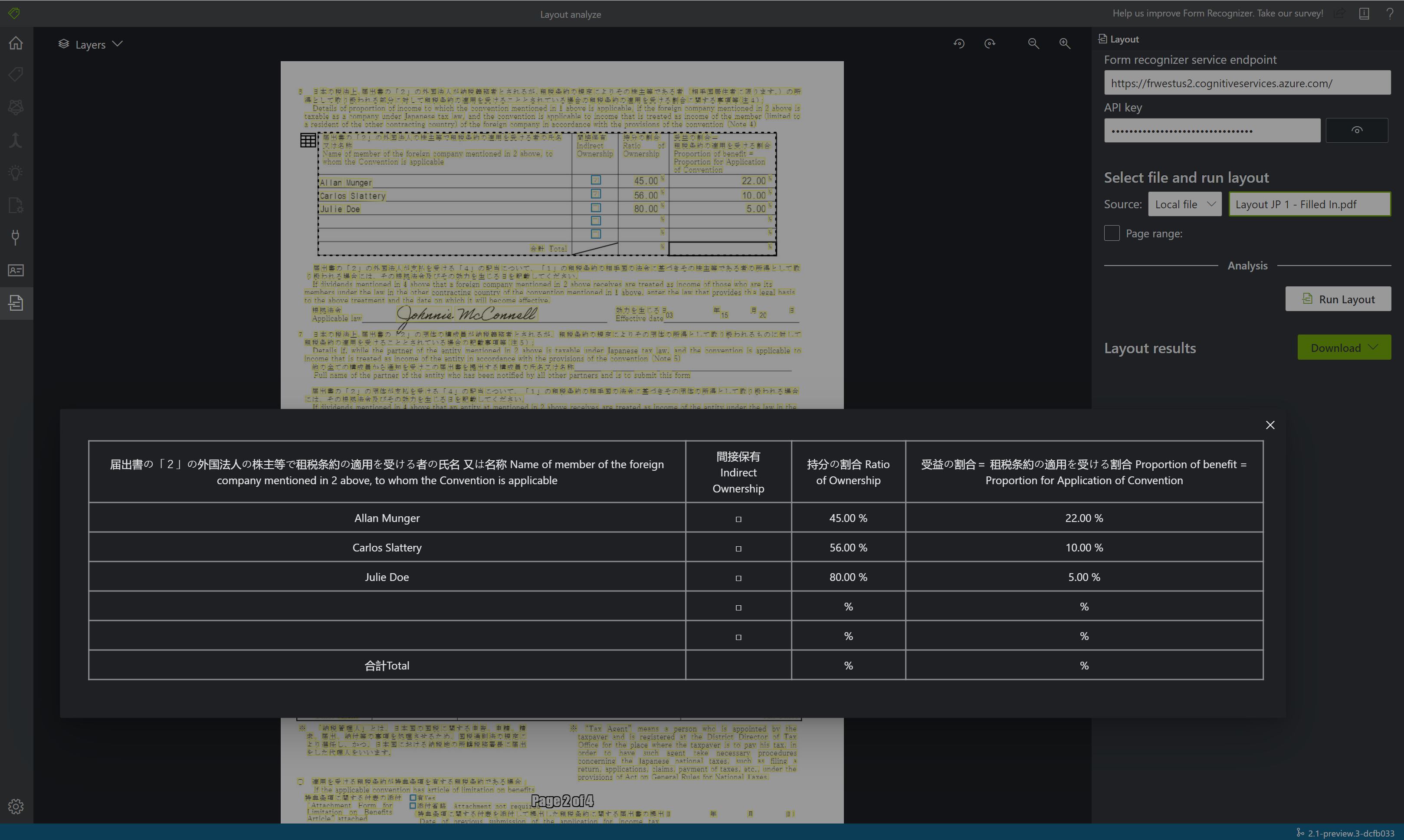
JSON 出力ファイルをダウンロードして、詳細なレイアウト結果を表示します。
readResultsノードには、あらゆるテキスト行が、ページ上の対応する境界ボックスの配置と共に表示されます。selectionMarksノードには、すべての選択マーク (チェック ボックス、ラジオ マーク) と、その状態がselectedとunselectedのどちらであるかが示されます。- 抽出された表は、
pageResultsセクションに含まれています。 それぞれの表について、テキスト、行インデックス、列インデックス、行スパン、列スパン、境界ボックスなどが抽出されます。
カスタム フォーム モデルをトレーニングする
カスタム モデルをトレーニングし、ビジネスに固有のフォームやドキュメントからデータが分析されて抽出されるようにします。 この API は、特定のコンテンツ内のフォーム フィールドを認識し、キーと値のペアおよびテーブル データを抽出するようにトレーニングされた、機械学習プログラムです。 始めるには、同じフォームの少なくとも 5 種類の例が必要であり、それにより、カスタム モデルをラベル付けされたデータセットあり、またはなしでトレーニングできます。
カスタム フォーム モデルをトレーニングするための前提条件
トレーニング データのセットを含む Azure Storage Blob コンテナー。 すべてのトレーニング ドキュメントが同じ形式であることを確認します。 複数の形式のフォームがある場合は、共通する形式に基づいてサブフォルダーに分類します。 このプロジェクトでは、サンプル データ セットを使用できます。
コンテナーを含む Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートに従ってください。
CORS を構成する
CORS (クロス オリジン リソース共有) は Document Intelligence Studio からアクセスできるように Azure ストレージ アカウント上で構成する必要があります。 Azure portal で CORS を構成するには、ストレージ アカウントの [CORS] タブへのアクセスが必要になります。
ストレージ アカウントの [CORS] タブを選択します。
まず、Blob service に新しい CORS エントリを作成します。
[許可されたオリジン] は、
https://fott-2-1.azurewebsites.netに設定します。
ヒント
ドメインを指定するのではなくワイルドカード文字 (*) を使用すると、すべての元のドメインからの CORS を使用した要求を許可できます。
[許可されたメソッド] で使用可能な 8 つすべてのオプションを選択します。
各フィールドに * を入力して、 [許可されたヘッダー] と [公開されるヘッダー] をすべて承認します。
[Max Age](最長有効期間) 120 秒、または任意の許容値に設定します。
ページの先頭にある [保存] ボタンを選択して、変更を保存します。
サンプル ラベル付けツールの使用
サンプル ツールのホーム ページで、[Use custom form to train a model with labels and get key value pairs](カスタム フォームを使用してラベルを持つモデルをトレーニングし、キーと値のペアを取得する) を選択します。
[新しいプロジェクト] を選択する
新しいプロジェクトを作成する
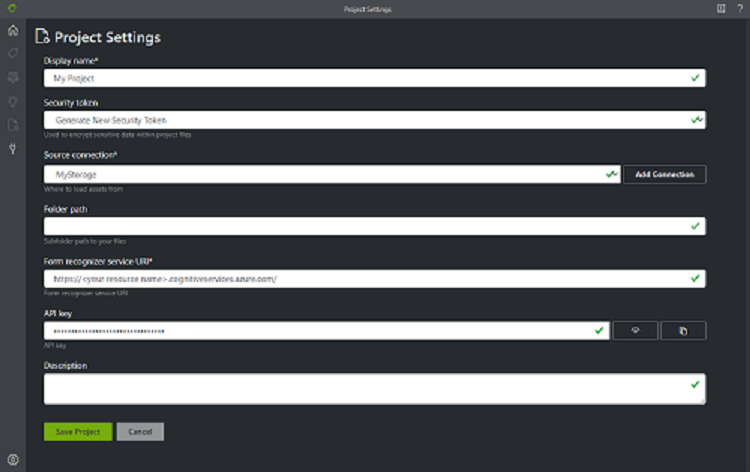
[プロジェクト設定] フィールドを次の値を使用して構成します。
表示名。 プロジェクトに名前を付けます。
セキュリティ トークン。 各プロジェクトでは、機密性の高いプロジェクト設定の暗号化または暗号化解除に使用できるセキュリティ トークンが自動生成されます。 セキュリティ トークンは、左側のナビゲーション バーの下部にある歯車アイコンを選択すると、[アプリケーション設定] に表示されます。
ソースの接続。 サンプル ラベル付けツールは、ソース (元のアップロードされたフォーム) とターゲット (作成されたラベルと出力データ) に接続されます。 接続は、複数のプロジェクトにまたがって設定および共有できます。 拡張可能なプロバイダー モデルが使用されるため、新しいソースまたはターゲット プロバイダーを簡単に追加できます。
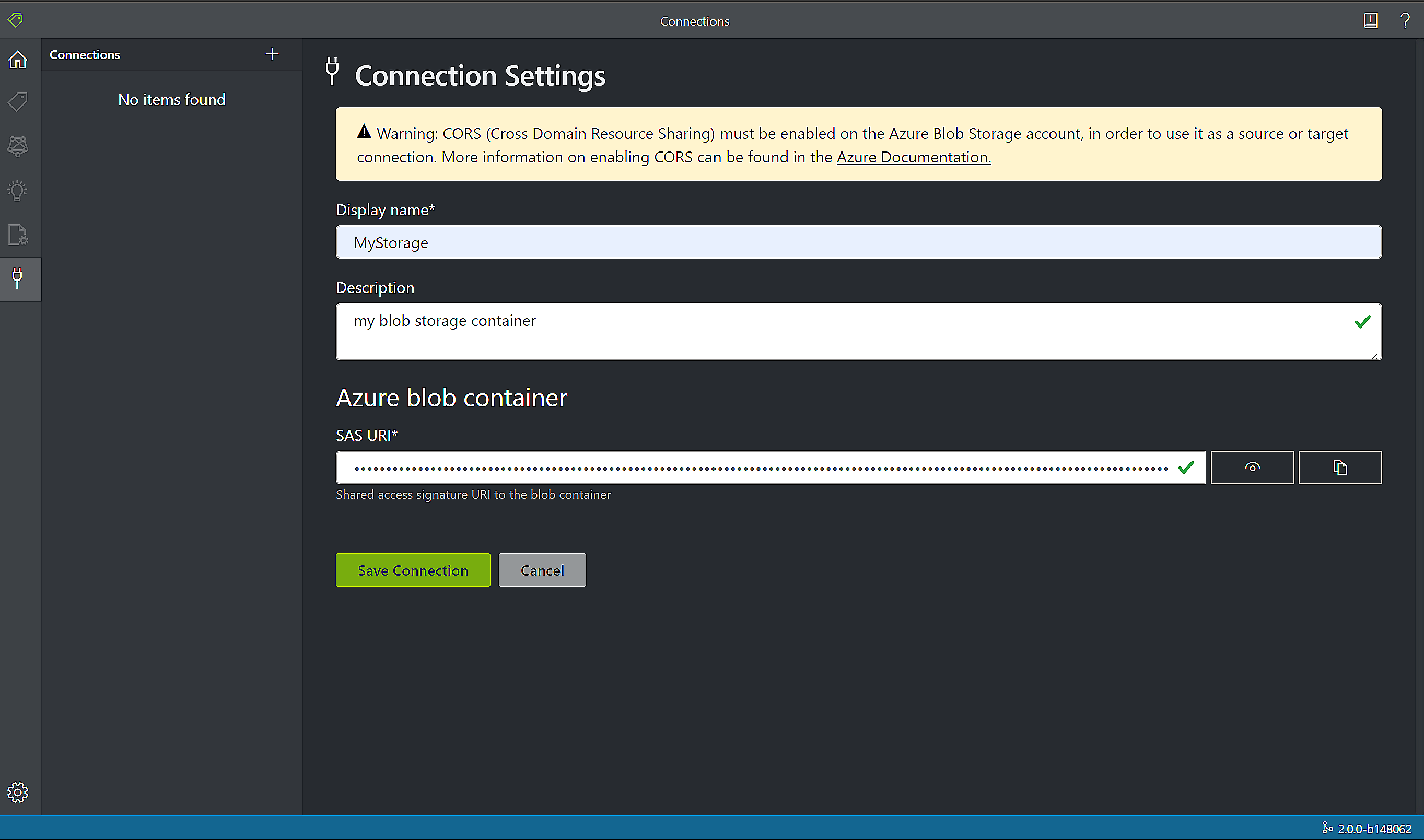
- 新しい接続を作成します。 [接続の追加] ボタンを選択します。 次の値を使用してフィールドに入力します。
- 表示名。 接続に名前を指定します。
- 説明。 簡単な説明を追加します。
- SAS URL。 Azure Blob Storage コンテナーの Shared Access Signature (SAS) URL を貼り付けます。
カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、 [Storage Explorer] タブを選択します。コンテナーに移動して右クリックし、 [Get shared access signature](Shared Access Signature の取得) を選択します。 ストレージ アカウント自体ではなく、コンテナー用の SAS を取得することが重要です。 [読み取り] 、 [書き込み] 、 [削除] 、および [表示] 権限がオンになっていることを確認し、 [作成] を選択します。 次に、URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。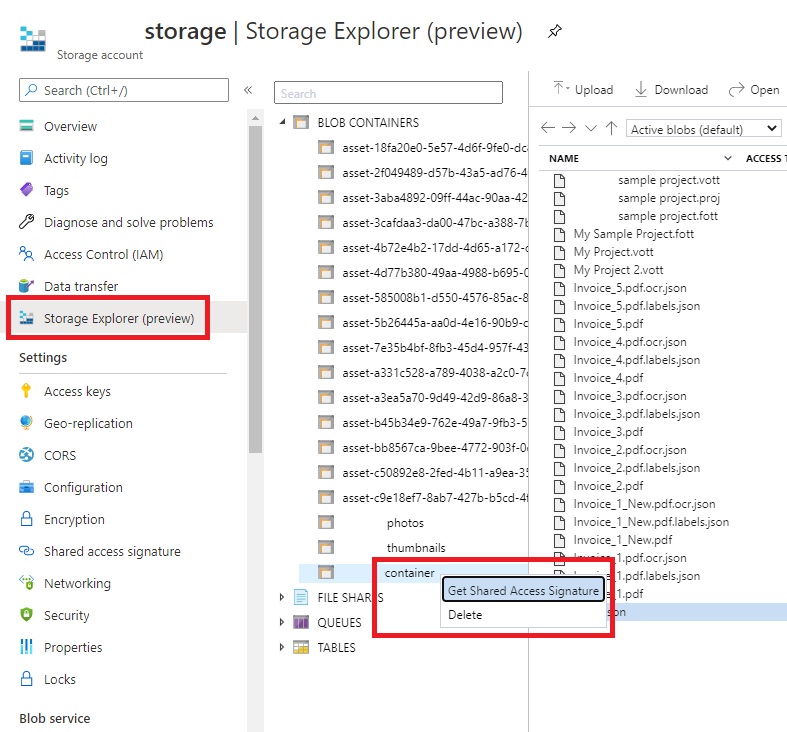
フォルダー パス (オプション)。 ソース フォームが BLOB コンテナー内のフォルダー内にある場合は、フォルダー名を指定します。
Document Intelligence サービス URI - Document Intelligence エンドポイントの URL。
[キー] Document Intelligence キー。
API バージョン。 v2.1 (既定値) のままにします。
[説明] (省略可能): プロジェクトの説明を入力します。
フォームにラベルを付ける
プロジェクトを作成するか開くと、メインのタグ エディター ウィンドウが開きます。 このタグ エディターは、次の 3 つの部分で構成されます。
- サイズ変更可能なプレビュー ペイン。基になる接続にあるフォームのスクロール可能な一覧が表示されます。
- メインのエディター ペイン。ここで、タグを適用できます。
- タグ エディター ペイン。ここで、タグの変更、ロック、並べ替え、削除を行うことができます。
テキストとテーブルを特定する
左側のペインにある [Run Layout on unvisited documents] (未処理ドキュメントでレイアウトを実行) を選択して、各ドキュメントのテキストとテーブルのレイアウト情報を取得します。 ラベル付けツールによって、各テキスト要素の周囲に境界ボックスが描画されます。
ラベル付けツールでは、どのテーブルが自動的に抽出されたかも示されます。 ドキュメントの左側にあるテーブル (グリッド) アイコンを選択すると、抽出されたテーブルが表示されます。 テーブルの内容は自動的に抽出されるため、テーブルの内容に対するラベル付けは行わず、自動化された抽出を信頼することにします。
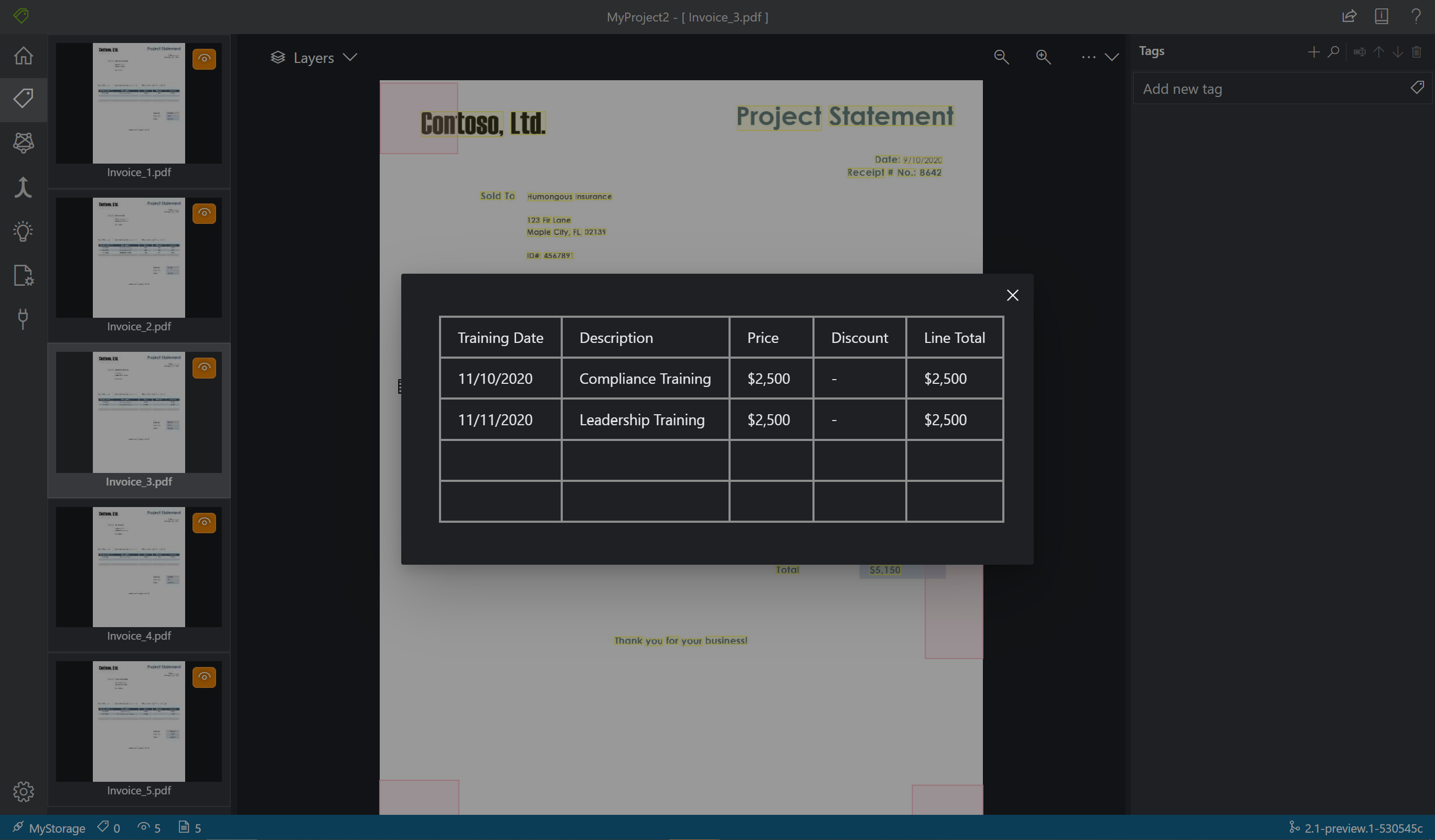
ラベルをテキストに適用する
次に、タグ (ラベル) を作成し、モデルに分析させるテキスト要素に適用します。 サンプル ラベル データ セットには、既にラベルが付けられているフィールドが含まれており、別のフィールドは追加されます。
タグ エディター ウィンドウを使用して、識別する新しいタグを作成します。
プラス記号 (+) を選択して、新しいタグを作成します。
"Total" というタグを入力します。
Enter キーを押して、タグを保存します。
メインのエディターで、強調表示されたテキスト要素から合計の値を選択します。
値に適用する合計タグを選択するか、対応するキーボード キーを押します。 数字キーは、最初の 10 個のタグのホットキーとして割り当てられます。 タグの順序は、タグ エディター ペインの上矢印と下矢印のアイコンを使用して変更できます。 次の手順に従って、サンプル データセット内の 5 つのフォームすべてにラベルを付けます。
ヒント
フォームにラベルを付けるときは、次のヒントに留意してください。
適用できるタグは、選択したテキスト要素ごとに 1 つのみです。
各タグは、1 ページにつき 1 回のみ適用できます。 同じフォームに同じ値が複数回出現する場合は、インスタンスごとに異なるタグを作成します。 たとえば、"invoice # 1"、"invoice # 2" などとします。
タグは複数のページにまたがることはできません。
フォームに表示されるラベル値は、2 つの異なるタグを使用して 2 つの部分に分割しないでください。 たとえば、アドレス フィールドが複数の行にまたがる場合でも、1 つのタグを使用してラベルを付ける必要があります。
タグが付けられたフィールドには値のみを含めます。キーは含めないでください。
テーブル データは自動的に検出され、'pageResults' セクションの最終的な出力 JSON ファイルに表示されます。 ただし、モデルですべてのテーブル データの検出に失敗した場合は、モデルにラベルを付けテーブルを検出するトレーニングを行うことができます。「カスタム モデルをトレーニングする | フォームにラベルを付ける」を参照してください。
+ の右にあるボタンを使用して、タグの検索、名前の変更、順序変更、削除を行います。
タグそのものは削除せずに、適用されているタグを解除するには、タグ付けされた四角形をドキュメント ビューで選択し、Delete キーを押します。
カスタム モデルをトレーニングする
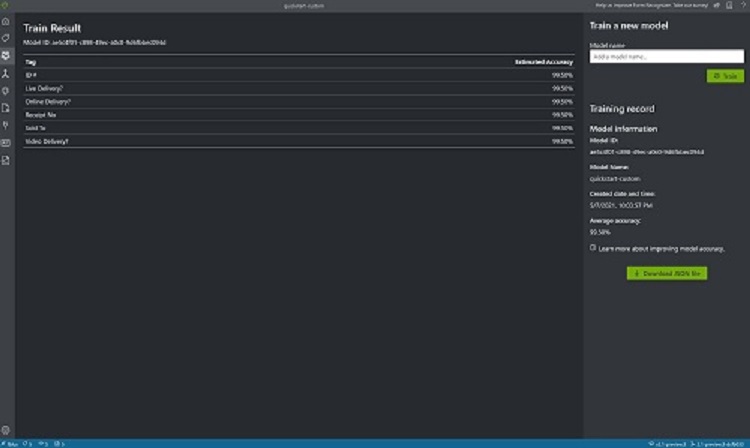
左側のペインでトレーニング アイコンを選択して、[トレーニング] ページを開きます。 次に、 [Train](トレーニング) ボタンを選択して、モデルのトレーニングを開始します。 トレーニング プロセスが完了すると、次の情報が表示されます。
[Model ID] - 作成およびトレーニングされたモデルの ID。 トレーニングの呼び出しごとに、独自の ID を持つ新しいモデルが作成されます。 この文字列を安全な場所にコピーしてください。REST API またはクライアント ライブラリを使用して予測呼び出しを行う場合に必要になります。
[Average Accuracy](平均精度) - モデルの平均精度。 追加のフォームにラベルを付け、再度トレーニングを行って新しいモデルを作成することにより、モデルの精度を向上させることができます。 最初に、結果を解析してテストする 5 つのフォームにラベルを付け、必要に応じてフォームを追加することをお勧めします。
タグの一覧と、タグごとの予測精度。 詳細については、正確性スコアと信頼度スコアの解釈と改善に関するページを参照してください。
カスタムフォームを解析する
ナビゲーション バーから
Analyzeアイコンを選択して、モデルをテストします。ソース [ローカル ファイル] を選択し、テスト フォルダーに展開したサンプル データセットから選択するファイルを参照します。
[分析を実行する] ボタンを選択して、フォームのキーと値のペア、テキスト、テーブルの予測を取得します。 このツールでは、境界ボックスにタグが適用され、各タグの信頼度がレポートされます。
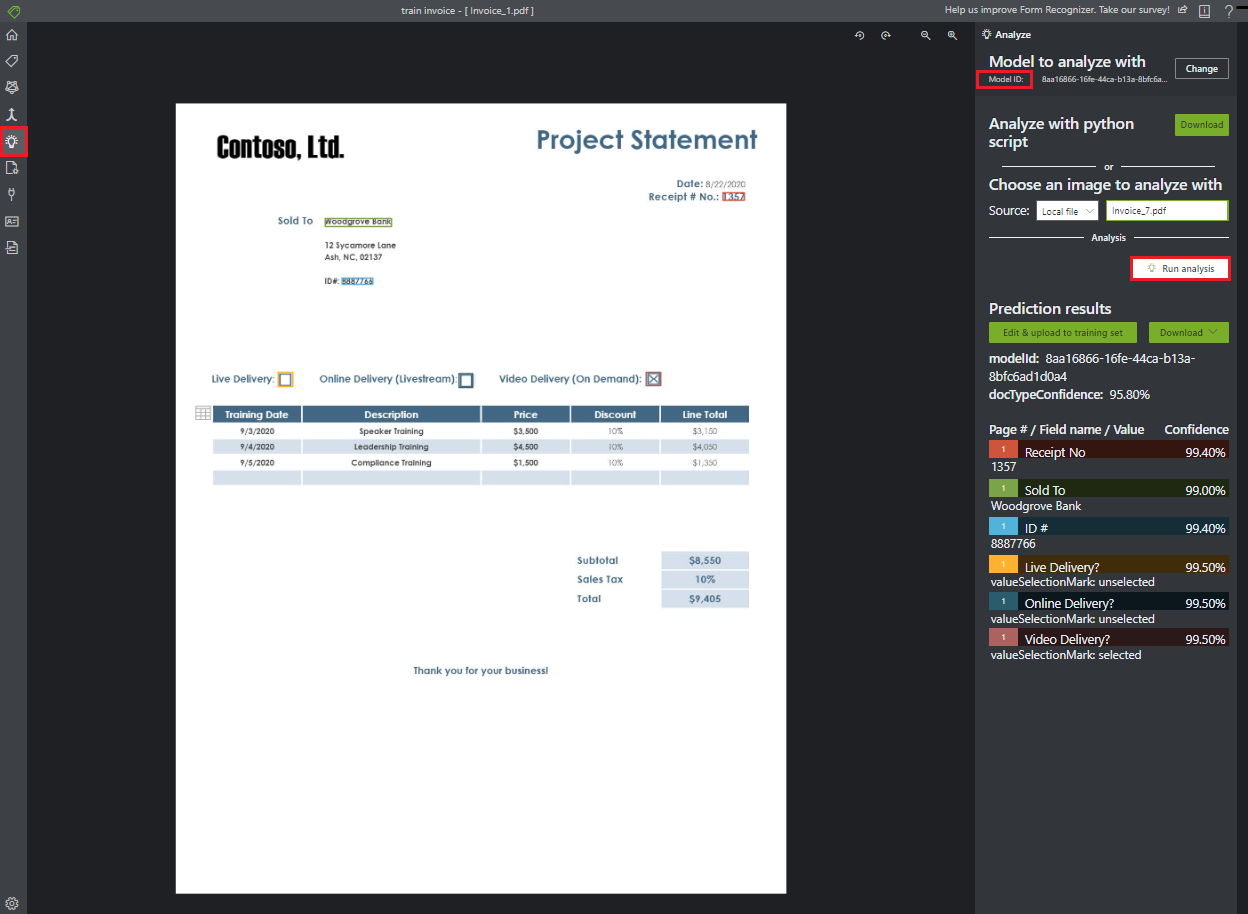
これで完了です。 Document Intelligence のサンプル ツールを Document Intelligence の事前構築済みのレイアウト モデルおよびカスタム モデルに対してどのように使用するかについて確認しました。 また、手動でラベル付けされたデータを使用してカスタム フォームを分析する方法についても学習しました。