会話言語理解のモデルをトレーニングする
- [アーティクル]
-
-
発話のラベル付けが完了したら、モデルのトレーニングを開始できます。 トレーニングは、モデルがラベル付きの発話から学習するプロセスです。
モデルをトレーニングするには、トレーニング ジョブを開始します。 正常に完了したジョブでのみモデルが作成されます。 トレーニング ジョブは、7 日後に期限切れになります。この期間を過ぎると、ジョブの詳細を取得できなくなります。 トレーニング ジョブが正常に完了し、モデルが作成されていれば、ジョブの期限切れによってモデルが影響を受けることはありません。 一度に実行できるトレーニング ジョブは 1 つのみで、同じプロジェクトで他のジョブを開始することはできません。
トレーニング時間は、単純なプロジェクトの処理のときは数秒で済みますが、発話数の上限に達したときは数時間かかります。
モデルの評価は、トレーニングが正常に完了した後に自動的にトリガーされます。 評価プロセスは、最初にトレーニング済みモデルを使用してテスト セット内の発話に対して予測を実行し、予測した結果と指定されているラベル (真実のベースラインを確立するもの) を比較します。
前提条件
トレーニング データのバランスを取る
トレーニング データに関しては、スキーマのバランスを保つようにします。 ある意図を大量に含め、別の意図をほとんど含めない場合、特定の意図に偏ったモデルになります。
このシナリオに対処するために、トレーニング セットをダウンサンプリングするか、 または追加することが必要になる場合があります。 ダウンサンプリングは、次のいずれかの方法で行うことができます。
- 一定の割合のトレーニング データをランダムに取り除きます。
- データセットを分析し、過剰な重複エントリを削除します。この方法の方がより体系的です。
トレーニング セットを追加するには、Language Studio の [データのラベル付け] タブで、[発話の提案] を選択します。 会話言語理解から Azure OpenAI に呼び出しが送信され、同様の発話が生成されます。
![Language Studio の [発話の提案] を示すスクリーンショット。](../media/suggest-utterances.png)
また、トレーニング セットで意図しない "パターン" を探す必要もあります。 たとえば、特定の意図のトレーニング セットがすべて小文字であるかどうか、または特定の語句で始まるかどうかを確認します。 このような場合、トレーニングするモデルは、一般化することができず、トレーニング セットでこのような意図しない偏りを学習する可能性があります。
トレーニング セットには、大文字と小文字の区別と、句読点の多様性を導入することをお勧めします。 バリエーションの処理を想定しているモデルの場合は、必ずその多様性も反映するトレーニング セットを用意してください。 たとえば、大文字と小文字が正しい発話だけでなく、すべて小文字のものも含めます。
データの分割
トレーニング プロセスを開始する前に、プロジェクト内のラベル付き発話はトレーニング用セットとテスト用セットに分割されます。 これらはそれぞれ異なる機能を提供します。
トレーニング用セットは、モデルのトレーニングに使用されます。このセットから、モデルはラベル付き発話を学習します。
テスト用セットは、トレーニング時には導入されず、評価時にのみモデルに導入されるブラインド セットです。
モデルが正常にトレーニングされた後、そのモデルを使用して、テスト用セット内の発話から予測を行うことができます。 これらの予測は、評価メトリックの計算に使用されます。
トレーニング用とテスト用の両方のセットで、すべての意図とエンティティが適切に表現されているか確認することをお勧めします。
会話言語理解は、データ分割のための 2 つの方法をサポートしています。
- トレーニング用データからテスト用セットを自動分割: システムにより、選択した割合に従って、タグ付けされたデータがトレーニング用セットとテスト用セットに分割されます。 推奨される分割の割合は、トレーニング用 80%、テスト用 20% です。
注意
[トレーニング用データからテスト用セットを自動分割] オプションを選択した場合、トレーニング用セットに割り当てられたデータのみが、指定された割合に従って分割されます。
- トレーニング用データとテスト用データの手動分割を使用: この方法を使用すると、ユーザーは、どの発話をどのセットに所属させるか定義できます。 この手順は、ラベル付け中にテスト用セットに発話を追加した場合にのみ有効になります。
トレーニング モード
CLU では、モデルをトレーニングするための 2 つのモードをサポートしています
標準トレーニングでは、高速機械学習アルゴリズムを使用して、モデルを比較的迅速にトレーニングします。 現在、これは英語でのみ使用でき、主言語として英語 (米国)、または英語 (英国) を使用しないプロジェクトでは無効になっています。 このトレーニング オプションは無料です。 標準トレーニングを使用すると、発話を追加し、それを無料ですばやくテストできます。 表示される評価スコアから、プロジェクトで変更を加えたり、発話を追加したりする場所がわかります。 数回反復し、段階的に改善を加えたら、高度なトレーニングを使用してモデルの別のバージョンをトレーニングすることを検討します。
高度なトレーニングでは、最新の機械学習テクノロジを使用して、データを使用してモデルをカスタマイズします。 これにより、モデルのパフォーマンス スコアが向上することが期待され、CLU の多言語機能も使用できるようになります。 高度なトレーニングの価格は異なります。 詳細については、価格情報を参照してください。
評価スコアを使用して決定を導き出します。 標準トレーニング モードを使用した場合とは対照的に、高度なトレーニングで特定の例が正しく予測されない場合があります。 ただし、全体的な評価結果が "高度" を使用する方が優れている場合は、最終的なモデルを使用することをお勧めします。 そうではなく、多言語機能を使用する必要がない場合は、標準モードでトレーニングされたモデルを引き続きお使いいただけます。
注意
各アルゴリズムでスコアが異なる方法で調整されるため、トレーニング モード間で意図の信頼度スコアの動作が異なることが予想されます。
モデルのトレーニング
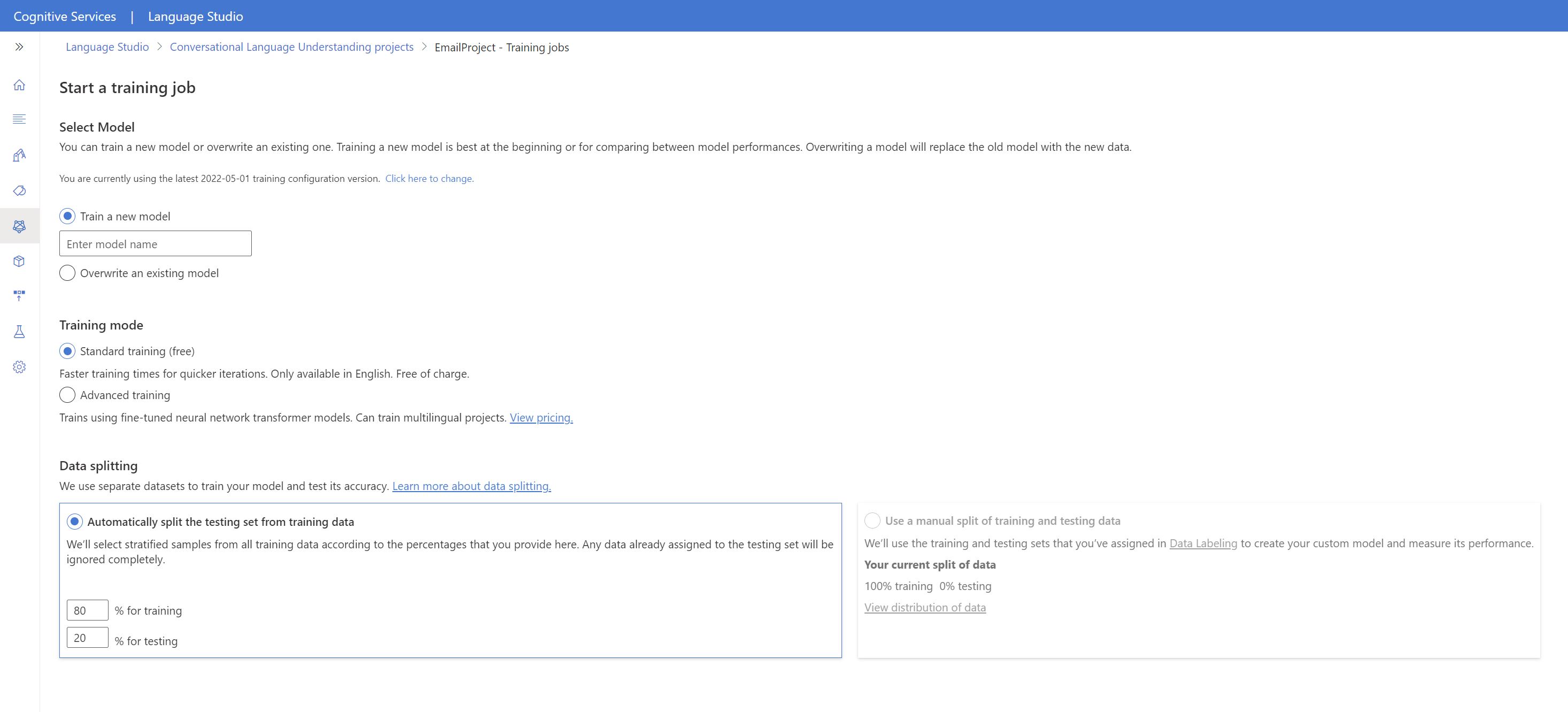
Language Studio 内からモデルのトレーニングを開始するには、次の手順を行います。
左側のメニューから [モデルのトレーニング] を選択します。
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスに新しいモデル名を入力します。 それ以外の場合、既存のモデルを新しいデータでトレーニングされたモデルに置き換えるには、[既存のモデルを上書きする](Overwrite an existing model) を選択し、既存のモデルを選択します。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
トレーニング モードを選択します。 [標準トレーニング] を選択すると、高速でトレーニングできますが、これを使用できるのは英語に限られます。 または、[高度なトレーニング] を選択できます。これは、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなります。 トレーニング モードの詳細を参照してください。
[データ分割] 方法を選択します。 [トレーニング用データからテスト用セットを自動分割] を選択できます。その場合、システムにより、指定した割合に従って、発話がトレーニング用セットとテスト用セットに分割されます。 または、[トレーニング用データとテスト用データの手動分割を使用] を選択することもできます。このオプションは、発話にラベルを付ける際に発話をテスト用セットに追加した場合にのみ有効になります。
[トレーニング] ボタンを選択します。
リストからトレーニング ジョブ ID を選択します。 ウィンドウが表示され、そのジョブのトレーニングの進行状況、ジョブの状態、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、発話数に応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了しない限り、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。
- モデルのトレーニングに使用される機械学習は定期的に更新されます。 以前の構成バージョンでトレーニングするには、[トレーニング ジョブの開始] ページから [変更するには、ここを選択してください] を選択し、以前のバージョンを選択します。
トレーニング ジョブを開始する
次の URL、ヘッダー、JSON 本文を使用して POST 要求を作成し、トレーニング ジョブを送信します。
要求 URL
API 要求を作るときは、次の URL を使います。 プレースホルダーの値は、実際の値に置き換えます。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| プレースホルダー |
値 |
例 |
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 |
EmailApp |
{API-VERSION} |
呼び出す API のバージョン。 |
2023-04-01 |
要求を認証するには、次のヘッダーを使います。
| Key |
値 |
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
要求では次のオブジェクトを使います。 トレーニングが完了すると、modelLabel パラメーターに使用する値の後にモデルの名前が付けられます。
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| キー |
プレースホルダー |
値 |
例 |
modelLabel |
{MODEL-NAME} |
モデルの名前。 |
Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
トレーニング構成モデルのバージョン。 既定では、最新のモデル バージョンが使用されます。 |
2022-05-01 |
trainingMode |
{TRAINING-MODE} |
トレーニングに使用するトレーニング モード。 サポートされているモードは、高速のトレーニングですが、英語でのみ使用可能な [標準トレーニング]と、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなる [高度なトレーニング] です。 トレーニング モードの詳細を参照してください。 |
standard |
kind |
percentage |
分割方法。 設定可能な値は、percentage または manual です。 詳細については、モデルのトレーニング方法に関するセクションを参照してください。 |
percentage |
trainingSplitPercentage |
80 |
トレーニング セットに含まれるタグ付きデータの割合。 推奨値は 80 です。 |
80 |
testingSplitPercentage |
20 |
テスト用セットに含めるタグ付けされたデータの割合。 推奨値は 20 です。 |
20 |
注意
trainingSplitPercentage と testingSplitPercentage は、Kind が percentage に設定されている場合にのみ必要であり、両方の割合の合計は 100 に等しくなる必要があります。
API 要求を送信すると、成功を示す 202 応答が返されます。 応答ヘッダーで、operation-location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
この URL を使用してトレーニング ジョブの状態を取得できます。
トレーニング ジョブの状態を取得する
トレーニング データのサイズとスキーマの複雑さによっては、トレーニングに時間がかかる場合があります。 次の要求を用いることにより、トレーニング ジョブが正常に完了するまで、その状態をポーリングし続けることができます。
トレーニング要求の送信に成功すると、インポート ジョブの状態を確認するための完全な要求 URL (エンドポイント、プロジェクト名、ジョブ ID を含む) が応答の operation-location ヘッダーに組み込まれます。
モデルのトレーニングの進行状況を表す状態を取得するには、次の GET 要求を使用します。 次のプレースホルダーの値を実際の値に置き換えてください。
要求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー |
値 |
例 |
{YOUR-ENDPOINT} |
API 要求を認証するためのエンドポイント。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 |
EmailApp |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出す API のバージョン。 |
2023-04-01 |
要求を認証するには、次のヘッダーを使います。
| Key |
値 |
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
応答本文
要求を送信すると、次の応答を受け取ります。 [status](状態) パラメーターが [succeeded](成功) に変更されるまで、このエンドポイントのポーリングを続けます。
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| キー |
値 |
例 |
modelLabel |
モデル名 |
Model1 |
trainingConfigVersion |
トレーニング構成バージョン。 既定では、最新バージョンが使用されます。 |
2022-05-01 |
trainingMode |
選択したトレーニング モード。 |
standard |
startDateTime |
トレーニングが開始された時間 |
2022-04-14T10:23:04.2598544Z |
status |
トレーニング ジョブの状態 |
running |
estimatedEndDateTime |
トレーニング ジョブが完了するまでの推定時間 |
2022-04-14T10:29:38.2598544Z |
jobId |
トレーニング ジョブ ID |
xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
トレーニング ジョブの作成日時 |
2022-04-14T10:22:42Z |
lastUpdatedDateTime |
トレーニング ジョブの最終更新日時 |
2022-04-14T10:23:45Z |
expirationDateTime |
トレーニング ジョブの有効期限の日時 |
2022-04-14T10:22:42Z |
トレーニング ジョブのキャンセル
Language Studio 内でトレーニング ジョブをキャンセルするには
- [Train model] (モデルのトレーニング) ページで、キャンセルするトレーニング ジョブを選択し、上部のメニューから [キャンセル] を選択します。
トレーニングをキャンセルするには、次の URL、ヘッダー、JSON 本文を使用して POST 要求を作成します。
要求 URL
API 要求を作るときは、次の URL を使います。 次のプレースホルダーの値を実際の値に置き換えてください。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}/:cancel?api-version={API-VERSION}
| プレースホルダー |
値 |
例 |
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 |
EmailApp |
{JOB-ID} |
これは、トレーニング ジョブ ID です |
XXXXX-XXXXX-XXXX-XX |
{API-VERSION} |
呼び出す API のバージョン。 |
2023-04-01 |
要求を認証するには、次のヘッダーを使います。
| Key |
値 |
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
API 要求を送信すると、成功を示す 202 応答を受け取ります。これは、トレーニング ジョブがキャンセルされたことを意味します。 呼び出しが成功すると、ジョブの状態を確認するために使用する Operation-Location ヘッダーが返されます。
次のステップ
![Language Studio の [発話の提案] を示すスクリーンショット。](../media/suggest-utterances.png#lightbox)
