ダッシュボードを使用して Azure Databricks のメトリックを視覚化する
注意
この記事は、GitHub でホストされているオープン ソース ライブラリ https://github.com/mspnp/spark-monitoring に依存しています。
元のライブラリでは、Azure Databricks Runtime 10.x (Spark 3.2.x) 以前がサポートされています。
Databricks は、Azure Databricks Runtime 11.0 (Spark 3.3.x) 以降をサポートするように更新されたバージョンを l4jv2 ブランチで提供しました (https://github.com/mspnp/spark-monitoring/tree/l4jv2)。
Databricks Runtime で使用されるログ システムが異なるため、11.0 リリースには下位互換性がないことに注意してください。 Databricks Runtime に正しいビルドを使用するようにしてください。 ライブラリと GitHub リポジトリはメンテナンス モードです。 今後のリリースの計画はなく、問題のサポートはベスト エフォートでのみ行われます。 ライブラリまたは Azure Databricks 環境の監視とログのロードマップに関するその他の質問については、azure-spark-monitoring-help@databricks.com までお問い合わせください。
この記事では、パフォーマンスの問題について Azure Databricks ジョブを監視するように Grafana ダッシュ ボードを設定する方法について説明します。
Azure Databricks は、ビッグ データ分析ソリューションと人工知能 (AI) ソリューションの高速な開発とデプロイを容易にする、高速、強力、かつ協調的な Apache Spark ベースの分析サービスです。 監視は、実稼働環境で Azure Databricks ワークロードを運用するうえで重要な構成要素です。 最初の手順は、分析のためにメトリックをワークスペースに収集することです。 Azure では、ログ データを管理するための最良のソリューションは Azure Monitor です。 Azure Databricks は、Azure Monitor へのログ データの送信をネイティブにサポートしていませんが、この機能のためのライブラリを GitHub から入手できます。
このライブラリにより、Azure Databricks サービスのメトリックおよび Apache Spark 構造化ストリーミング クエリ イベントのメトリックのログ記録が可能になります。 このライブラリを Azure Databricks クラスターに正常にデプロイしたら、さらに、実稼働環境の一部としてデプロイできる Grafana ダッシュボードのセットをデプロイすることができます。
前提条件
GitHub の readme の説明に従って、監視ライブラリを使うように Azure Databricks クラスターを構成します。
Azure Log Analytics ワークスペースをデプロイする
Azure Log Analytics ワークスペースをデプロイするには、以下の手順に従ってください。
/perftools/deployment/loganalyticsディレクトリに移動します。logAnalyticsDeploy.json Azure Resource Manager テンプレートをデプロイします。 Resource Manager テンプレートのデプロイの詳細については、「Azure Resource Manager テンプレートと Azure CLI を使用したリソースのデプロイ」をご覧ください。 このテンプレートには、次のパラメーターがあります。
- location:Log Analytics ワークスペースとダッシュボードがデプロイされるリージョン。
- serviceTier:ワークスペースの価格レベル。 有効値の一覧については、こちらを参照してください。
- dataRetention (省略可能):Log Analytics ワークスペースにログ データが保持される日数。 既定値は 30 日間です。 価格レベルが
Freeの場合、データ保持は 7 日間でなければなりません。 - workspaceName (省略可能):ワークスペースの名前。 指定しない場合、テンプレートが名前を生成します。
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
このテンプレートではワークスペースを作成し、さらに、ダッシュボードで使用される定義済みクエリのセットも作成します。
Grafana を仮想マシンにデプロイする
Grafana はオープン ソース プロジェクトです。これをデプロイすると、Azure Monitor 用の Grafana プラグインを使用して、Azure Log Analytics ワークスペースに格納されている時間系列メトリックを視覚化することができます。 Grafana は仮想マシン (VM) 上で実行され、ストレージ アカウント、仮想ネットワーク、およびその他のリソースを必要とします。 Bitnami で認定された Grafana イメージと関連リソースを使用して仮想マシンをデプロイするには、以下の手順に従ってください。
Azure CLI を使用して、Grafana の Azure Marketplace イメージの使用条件に同意します。
az vm image terms accept --publisher bitnami --offer grafana --plan defaultGitHub リポジトリのローカル コピーの
/spark-monitoring/perftools/deployment/grafanaディレクトリに移動します。grafanaDeploy.json Resource Manager テンプレートを以下のようにデプロイします。
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
デプロイが完了すると、Grafana の Bitnami イメージが仮想マシンにインストールされます。
Grafana のパスワードを更新する
セットアップ プロセスの一環として、Grafana のインストール スクリプトは、admin ユーザー用の一時パスワードを出力します。 サインインするためには、この一時パスワードが必要です。 一時パスワードを取得するには、次の手順に従ってください。
- Azure portal にサインインします。
- リソースがデプロイされたリソース グループを選択します。
- Grafana がインストールされた VM を選択します。 デプロイ テンプレートで既定のパラメーター名を使用した場合、VM 名は sparkmonitoring-vm-grafana で始まります。
- [サポート + トラブルシューティング] セクションで [ブート診断] をクリックして、[ブート診断] ページを開きます。
- [ブート診断] ページで [シリアル ログ] をクリックします。
- 次の文字列を検索します。"Setting Bitnami application password to" (Bitnami アプリケーションのパスワードを次のように設定する)。
- パスワードを安全な場所にコピーします。
次に、次の手順に従って Grafana の管理者パスワードを変更します。
- Azure portal で、VM を選択して [概要] をクリックします。
- パブリック IP アドレスをコピーします。
- Web ブラウザーを開き、次の URL に移動します:
http://<IP address>:3000。 - Grafana ログイン画面で、ユーザー名として admin と入力し、前の手順で取得した Grafana のパスワードを使用します。
- ログインしたら、 [Configuration] (歯車のアイコン) を選択します。
- [Server Admin] を選択します。
- [User] タブで、 [admin] ログインを選択します。
- パスワードを変更します。
Azure Monitor データ ソースを作成する
Grafana で Log Analytics ワークスペースへのアクセスを管理できるようにするサービス プリンシパルを作成します。 詳細については、「Azure CLI で Azure サービス プリンシパルを作成する」をご覧ください。
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionID次のコマンドの出力にある appId、password、および tenant の値をメモします。
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }前述の説明に従って Grafana にサインインします。 [Configuration] (歯車のアイコン) を選択し、次に [Data Sources] を選択します。
[Data Sources] タブで、 [Add data source] をクリックします。
データ ソースの種類として [Azure Monitor] を選択します。
[Settings] セクションで、 [Name] テキストボックスにデータ ソースの名前を入力します。
[Azure Monitor API Details] セクションで、次の情報を入力します。
- サブスクリプション ID:お使いの Azure サブスクリプション ID。
- テナント ID:前のテナント ID。
- クライアント ID:前の "appId" の値。
- クライアント シークレット: 前の "password" の値。
[Azure Log Analytics API Details] セクションで、[Same Details as Azure Monitor API] チェックボックスをオンにします。
[Save & Test] をクリックします。 Log Analytics のデータ ソースが正しく構成されている場合は、成功メッセージが表示されます。
ダッシュボードを作成する
次の手順に従って、Grafana にダッシュボードを作成します。
GitHub リポジトリのローカル コピーの
/perftools/dashboards/grafanaディレクトリに移動します。次のスクリプトを実行します。
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shこのスクリプトの出力は、SparkMonitoringDash.json という名前のファイルです。
Grafana ダッシュボードに戻り、 [Create] (プラス記号のアイコン) を選択します。
[インポート] を選択します。
[Upload .json File] をクリックします。
手順 2 で作成した SparkMonitoringDash.json ファイルを選択します。
[Options] セクションの [ALA] で、先ほど作成した Azure Monitor データ ソースを選択します。
[インポート] をクリックします。
ダッシュ ボードでの視覚化
Azure Log Analytics ダッシュボード と Grafana ダッシュ ボードの両方に、時系列の視覚化のセットが含まれています。 各グラフは、Apache Spark のジョブ、ジョブのステージ、および各ステージを形成するタスクに関連したメトリック データの時系列プロットです。
次の視覚化があります。
ジョブの待機時間
この視覚化は、ジョブの実行の待機時間を示すもので、ジョブの全体的なパフォーマンスの粗いビューです。 開始から完了までのジョブの実行時間が表示されます。 ジョブの開始時刻はジョブの送信時刻と同じではないことに注意してください。 待機時間は、クラスター ID とアプリケーション ID によってインデックスが付けられたジョブの実行のパーセンタイル (10%、30%、50%、90%) として表されます。
ステージの待機時間
この視覚化は、クラスターごと、アプリケーションごと、および個々のステージごとの各ステージの待機時間を示します。 この視覚化は、実行速度が遅い特定のステージを識別するのに役立ちます。
タスクの待機時間
この視覚化は、タスクの実行の待機時間を示します。 待機時間は、クラスター、ステージ名、およびアプリケーションごとのタスクの実行のパーセンタイルとして表されます。
ホストごとのタスクの実行の合計
この視覚化は、クラスターで実行されているホストごとのタスクの実行の合計待機時間を示しています。 ホストごとのタスクの実行の待機時間を表示すると、他のホストよりも全体的なタスクの待機時間がずっと長いホストを識別できます。 これは、タスクが非効率的または不均等にホストに分散されていたことを意味する場合があります。
タスクのメトリック
この視覚化は、特定のタスクの実行の実行メトリックのセットを示します。 これらのメトリックには、データ シャッフルのサイズと時間、シリアライズ操作と逆シリアライズ操作の時間などが含まれます。 メトリックの完全なセットについては、パネルの Log Analytics クエリをご覧ください。 この視覚化は、タスクを形成する操作を理解したり、各操作のリソース使用量を特定したりするのに役立ちます。 グラフの急上昇は、調査が必要なコストのかかる操作を表しています。
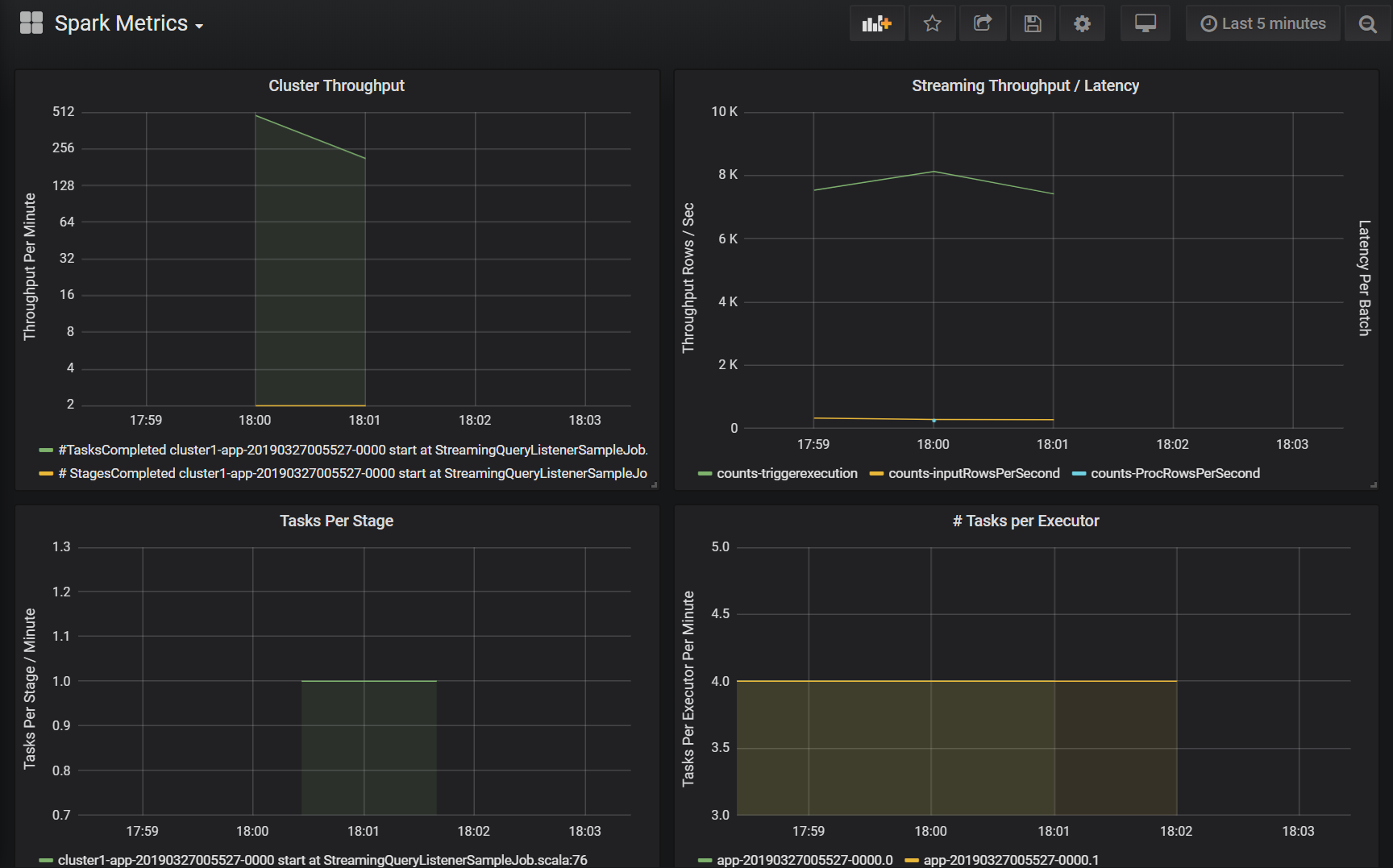
クラスターのスループット
この視覚化は、クラスターおよびアプリケーションごとに実行される作業量を表すためにクラスターとアプリケーションによってインデックスが付けられた作業項目の概要です。 これは、1 分間の増分で、クラスター、アプリケーション、およびステージごとに完了したジョブ、タスク、およびステージの数を示します。
ストリーミングのスループットと待機時間
この視覚化は、構造化ストリーミング クエリに関連付けられたメトリックに関連しています。 このグラフは、1 秒あたりの入力行数と 1 秒あたりの処理行数を示しています。 ストリーミング メトリックは、アプリケーションごとでも表されます。 これらのメトリックは、構造化ストリーミング クエリが処理される際に OnQueryProgress イベントが生成されるときに送信されます。そして、この視覚化ではストリーミング待機時間は、クエリ バッチを実行するために要した時間 (ミリ秒) で表わされます。
Executor ごとのリソース使用率
次は、特定の種類のリソースと、それが各クラスターで Executor ごとにどのように消費されているかを示すダッシュボードの視覚化のセットです。 これらの視覚化は、Executor ごとのリソース使用量の外れ値を識別するのに役立ちます。 たとえば、特定の Executor の作業割り振りにスキューがある場合、クラスターで実行されている他の Executor との関連でリソース使用量が上昇します。 これは、Executor のリソース使用量の急上昇によって識別できます。
Executor のコンピューティング時間のメトリック
次は、Executor のコンピューティング時間全体に対する Executor のシリアライズ時間、逆シリアライズ時間、CPU 時間、および Java 仮想マシン時間の割合を示すダッシュボードの視覚化のセットです。 これは、これらの 4 つの各メトリックが Executor の処理全体に占める割合を視覚的に示します。
シャッフルのメトリック
最後の視覚化のセットは、Executor 全体の構造化ストリーミング クエリに関連付けられたデータ シャッフル メトリックを示します。 これには、ファイル システムが使用されているクエリでの読み取りシャッフル バイト数、書き込みシャッフル バイト数、シャッフル メモリ、およびディスク使用量が含まれます。