Azure Databricks でのパフォーマンスのボトルネックのトラブルシューティング
Note
この記事は、GitHub でホストされているオープン ソース ライブラリ https://github.com/mspnp/spark-monitoring に依存しています。
元のライブラリでは、Azure Databricks Runtime 10.x (Spark 3.2.x) 以前がサポートされています。
Databricks は、Azure Databricks Runtime 11.0 (Spark 3.3.x) 以降をサポートするように更新されたバージョンを l4jv2 ブランチで提供しました (https://github.com/mspnp/spark-monitoring/tree/l4jv2)。
Databricks Runtime で使用されるログ システムが異なるため、11.0 リリースには下位互換性がないことに注意してください。 Databricks Runtime に正しいビルドを使用するようにしてください。 ライブラリと GitHub リポジトリはメンテナンス モードです。 今後のリリースの計画はなく、問題のサポートはベスト エフォートでのみ行われます。 ライブラリまたは Azure Databricks 環境の監視とログのロードマップに関するその他の質問については、azure-spark-monitoring-help@databricks.com までお問い合わせください。
この記事では、監視ダッシュ ボードを使用して Azure Databricks で Spark ジョブのパフォーマンスのボトルネックを見つける方法について説明します。
Azure Databricks は、ビッグ データ分析の迅速な開発とデプロイを容易にする、Apache Spark ベースの分析サービスです。 パフォーマンスの問題を監視してトラブルシューティングすることは、Azure Databricks の本番ワークロードを運用するときに重要です。 一般的なパフォーマンスの問題を識別するには、テレメトリ データに基づく監視の視覚化を使用することが有用です。
前提条件
この記事で示されている Grafana ダッシュ ボードを設定するには、次のようにします。
Azure Databricks 監視ライブラリを使用して、Log Analytics ワークスペースにテレメトリを送信するように Databricks クラスターを構成します。 詳細については、GitHub の Readme を参照してください。
Grafana を仮想マシンに デプロイします。 詳細については、「ダッシュボードを使用してAzure Databricks メトリックを視覚化する」を参照してください。
デプロイされている Grafana ダッシュ ボードには、時系列の視覚化のセットが含まれています。 各グラフは、Apache Spark ジョブ、ジョブのステージ、および各ステージを形成するタスクに関連したメトリックの時系列プロットです。
Azure Databricks のパフォーマンスの概要
Azure Databricks は、汎用分散コンピューティング システムである Apache Spark に基づいています。 ジョブと呼ばれるアプリケーション コードが、クラスター マネージャーに調整されて、Apache Spark クラスターで実行されます。 一般に、ジョブは、コンピューターで行う処理の最高位の単位です。 ジョブは、Spark アプリケーションによって実行される完全な操作を表します。 標準的な操作には、ソースからのデータの読み取り、データ変換の適用、およびストレージまたは別の宛先への結果の書き込みが含まれます。
ジョブは、複数のステージに分割されます。 ジョブはそれらのステージを順次通過して進んでいきます。つまり、後のステージは、前のステージが完了するのを待機しなければなりません。 ステージには、Spark クラスターの複数のノードで同時に実行できる同一タスクのグループが含まれています。 タスクは、データのサブセットで実行される、最も粒度の細かい実行単位です。
次のセクションでは、パフォーマンスのトラブルシューティングに役立ついくつかのダッシュ ボードの視覚化について説明します。
ジョブとステージの待機時間
ジョブの待機時間は、開始されてから完了するまでのジョブの実行時間です。 これは、外れ値の視覚化を可能にするために、クラスターおよびアプリケーション ID ごとのジョブの実行のパーセンタイルとして示されます。 次のグラフは、50 パーセンタイルが一貫して 10 秒前後だったのにもかかわらず、90 パーセンタイルが 50 秒に達したジョブの履歴を示しています。
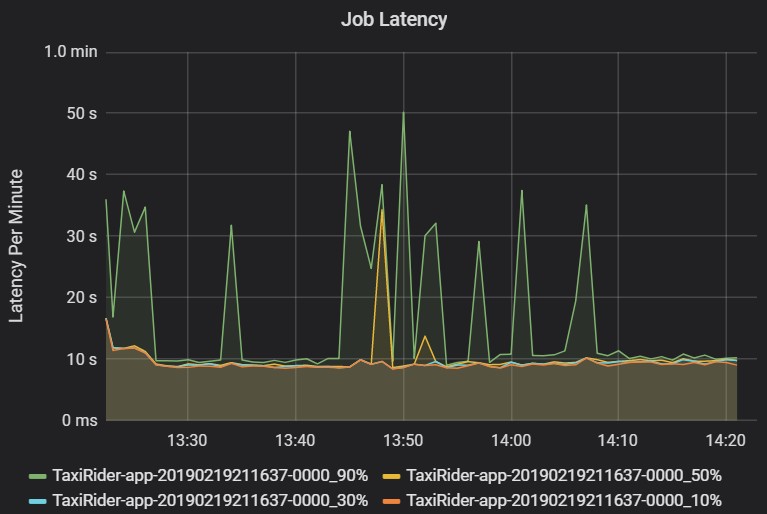
待機時間の急上昇を探して、クラスターおよびアプリケーション別にジョブの実行を調査します。 待機時間が長いクラスターとアプリケーションが特定されたら、ステージの待機時間の調査へと進みます。
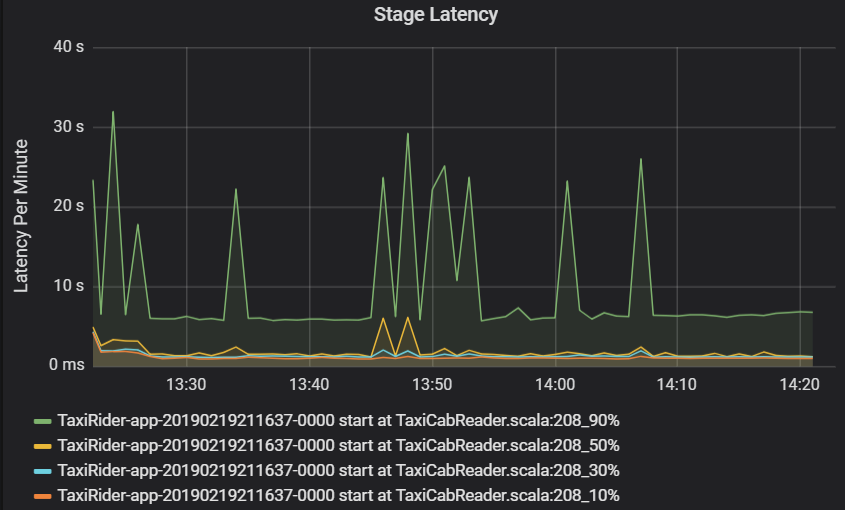
ステージの待機時間も、外れ値の視覚化を可能にするために、パーセンタイルとして示されます。 ステージの待機時間は、クラスター、アプリケーション、およびステージ名で分けられます。 グラフ内のタスク待機時間の急上昇を特定して、どのタスクがステージの完了を阻止しているのかを判別します。
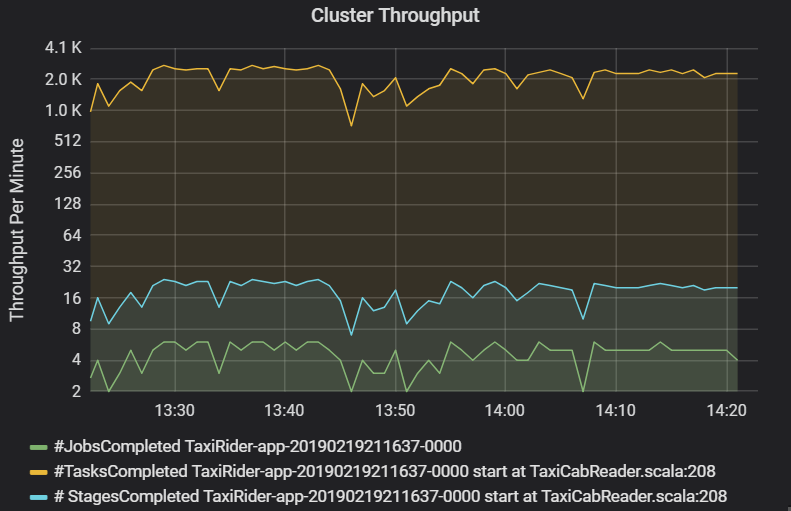
クラスターのスループットのグラフには、1 分あたりの完了したジョブ、ステージ、およびタスクの数が示されます。 これは、ジョブごとのステージとタスクの相対的な数の観点からワークロードを解釈するのに役立ちます。 ここで、1 分あたりのジョブの数が 2 個から 6 個の範囲で、ステージの数が 1 分あたり約 12 個から 24 個であることが分かります。
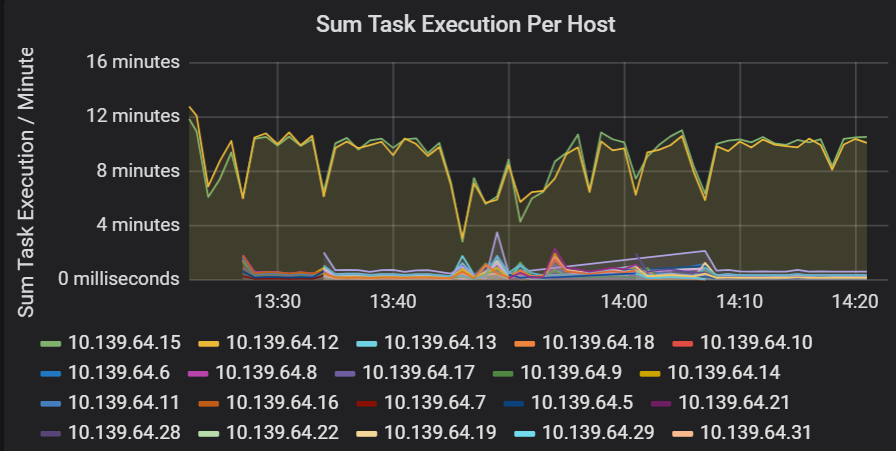
タスクの実行での待機時間の合計
この視覚化は、クラスターで実行されているホストごとのタスクの実行の合計待機時間を示しています。 このグラフを使用して、クラスターで速度が低下しているホストが原因で実行速度が低下しているタスクや、Executor ごとのタスクの不適切な割り当てを検出します。 次のグラフでは、ほとんどのホストでの合計時間は約 30 秒です。 しかし、これらのホストのうち 2 つのホストでは、合計時間は約 10 分間前後です。 ホストが低速で実行されているか、Executor ごとのタスクの数が適切に割り当てられていません。
Executor ごとのタスクの数は、2 つの Executor に不均衡な数のタスクが割り当てられているためにボトルネックが発生していることを示しています。
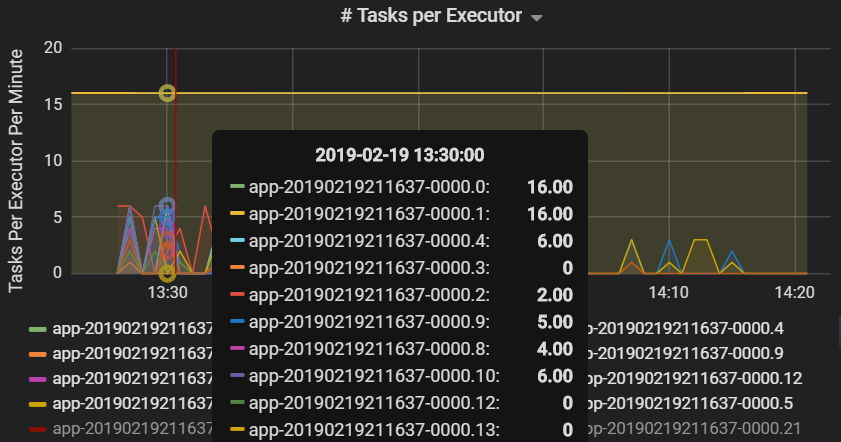
ステージごとのタスク メトリック
タスク メトリックの視覚化は、タスクの実行のコストの内訳を示します。 これを使用して、シリアル化や逆シリアル化などのタスクに費やされた相対時間を確認することができます。 このデータは、たとえば、ブロードキャスト変数を使用してデータの出荷を回避することにより、最適化する機会を示す場合があります。 タスク メトリックはまた、タスクのシャッフル データ サイズ、およびシャッフル読み取りとシャッフル書き込みの時間も示しています。 これらの値が大きい場合は、ネットワークで多くのデータが移動していることを意味します。
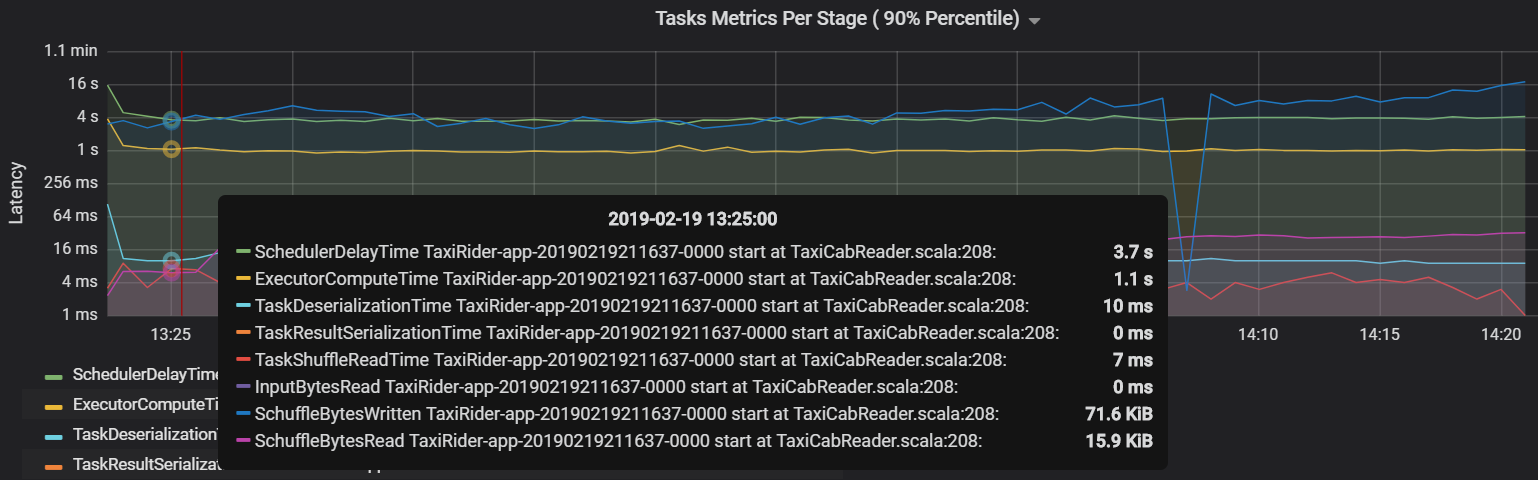
もう 1 つのタスク メトリックは、タスクをスケジュールするのにかかる時間を測定するスケジューラの遅延です。 理想的には、この値は、Executor のコンピューティング時間 (実際にタスクの実行に費やされる時間) と比べて低くなるべきです。
次のグラフは、Executor のコンピューティング時間 (1.1 秒) を超えているスケジューラの遅延時間 (3.7 秒) を示しています。 つまり、実際の作業に費やされている時間よりも、タスクがスケジュールされるのを待機している時間に費やされている時間の方が長いことになります。
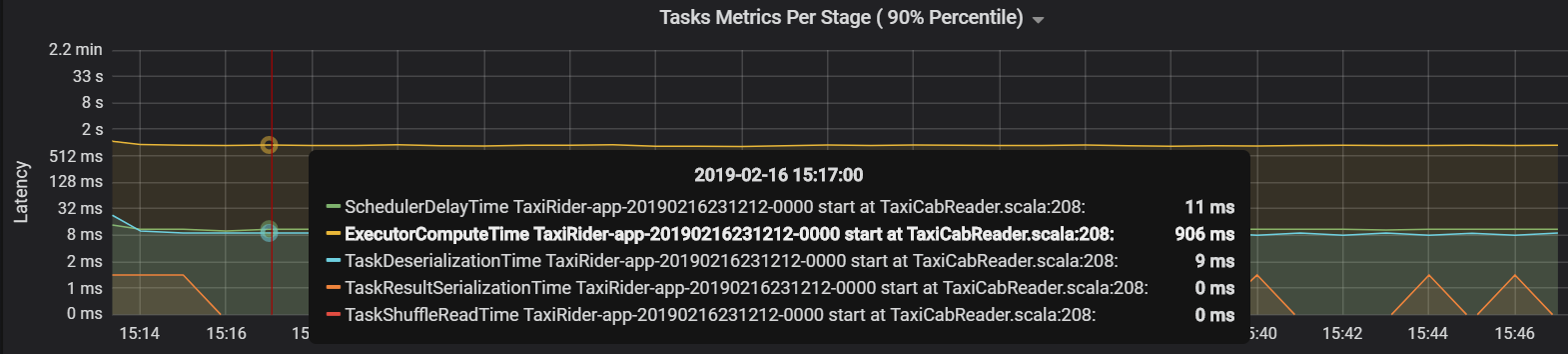
この場合の問題の原因は、パーティションの数が多すぎるために多くのオーバーヘッドが発生したことによるものです。 パーティションの数を減らすことで、スケジューラの遅延時間が削減されました。 次のグラフは、時間のほとんどがタスクの実行に費やされていることを示しています。
ストリーミングのスループットと待機時間
ストリーミングのスループットは、構造化ストリーミングに直接関連しています。 ストリーミングのスループットに関連付けられている 2 つの重要なメトリックがあります。1 秒あたりの入力行数と 1 秒あたりの処理行数です。 1 秒あたりの入力行数が 1 秒あたりの処理行数を上回る場合は、ストリーム処理システムが追いついていないことを意味します。 また、入力データが Event Hubs や Kafka から来ている場合は、1 秒あたりの入力行数が、フロント エンドのデータ インジェスト速度に遅れることなく対応している必要があります。
2 つのジョブは、同様のクラスター スループットを持ちながら、非常に異なるストリーミング メトリックを持つことができます。 次のスクリーンショットは、2 つの異なるワークロードを示しています。 これらは、クラスターのスループット (1 分あたりのジョブ、ステージ、およびタスク) の点では似ています。 しかし、2 番目の実行では、4000 行/秒に対して 12,000 行/秒が処理されています。
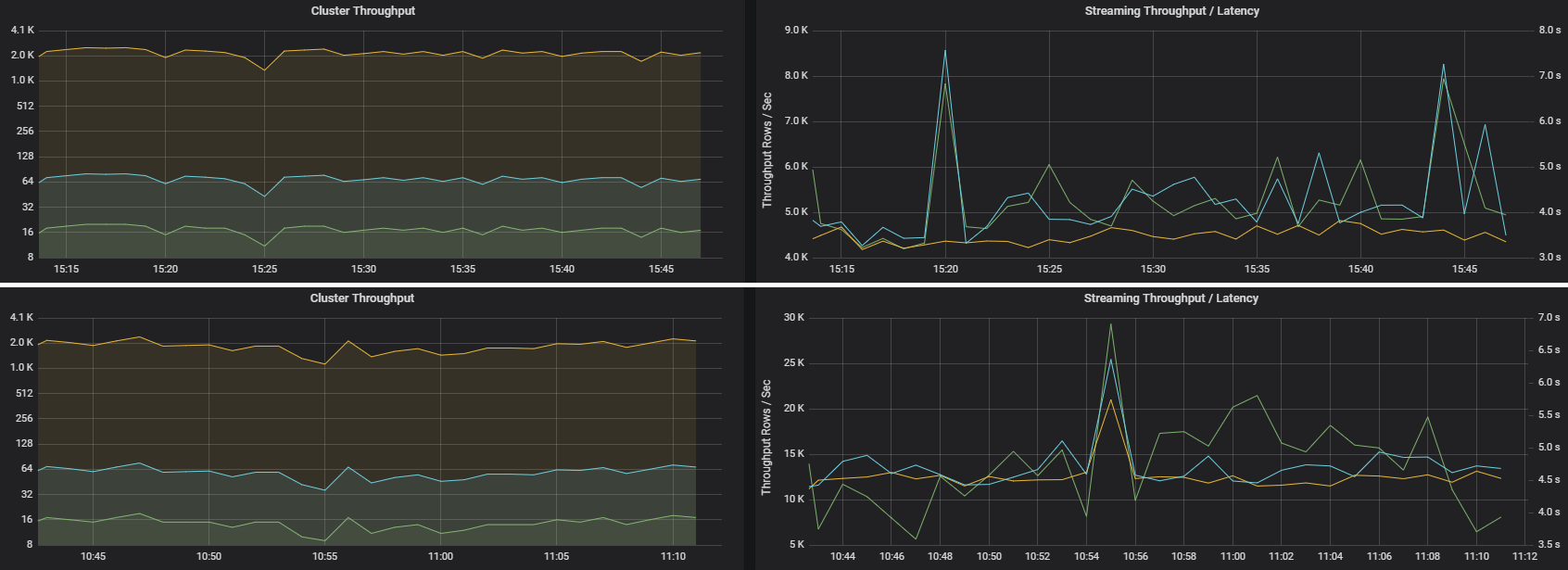
ストリーミングのスループットは、クラスターのスループットよりも優れたビジネス メトリックであることがよくあります。なぜならストリーミングのスループットでは、処理されているデータ レコードの数が測定されるからです。
Executor ごとのリソース使用率
これらのメトリックは、各 Executor で実行される作業を理解するのに役立ちます。
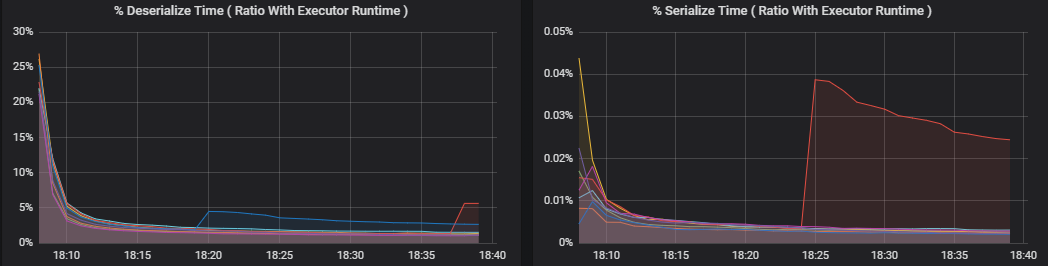
パーセンテージ メトリックは、Executor がさまざまな項目に費やしている時間を測定し、費やされた時間と Executor のコンピューティング時間全体との割合で表したものです。 メトリックは次のとおりです。
- シリアル化の時間 (%)
- 逆シリアル化の時間 (%)
- CPU Executor の時間 (%)
- JVM の時間 (%)
これらの視覚化は、これらのメトリックのそれぞれが Executor の処理全体に占める割合を示します。
シャッフル メトリックは、複数の Executor にわたるデータのシャッフルに関連するメトリックです。
- シャッフル I/O
- シャッフル メモリ
- ファイル システムの使用量
- ディスク使用量
一般的なパフォーマンスのボトルネック
Spark での 2 つの一般的なパフォーマンスのボトルネックは、タスク落伍者と最適化されていないシャッフル パーティション数です。
タスク落伍者
ジョブに含まれるステージは、前のステージが後のステージをブロックして、順次実行されます。 あるタスクが他のタスクより低速でシャッフル パーティションを実行すると、クラスター内のすべてのタスクは、ステージを終了する前に、その低速タスクが追いつくのを待たなければなりません。 これが発生する理由としては次のようなことが考えられます。
ホストまたはホスト グループの実行速度が遅い。 症状:タスク、ステージ、またはジョブの待機時間が長く、クラスターのスループットが低い。 ホストごとのタスクの待機時間の合計は、均等に分散されません。 ただし、リソース使用量は Executor 間で均等に分散されます。
実行するための負荷が大きい集約がタスクにある (データ スキュー)。 症状:タスク、ステージ、ジョブの待機時間が長いか、またはクラスターのスループットが低いが、ホストごとの待機時間の合計は均等に分散されている。 リソース使用量は Executor 間で均等に分散されます。
パーティションのサイズが等しくない場合は、より大きなパーティションが原因で不均衡なタスク実行が行われている可能性があります (パーティション スキュー)。 症状:Executor のリソース使用量が、クラスターで実行されている他の Executor と比較して多い。 その Executor で実行されているすべてのタスクの実行速度が遅くなり、パイプラインのステージの実行を阻害します。 これらのステージは、ステージのバリアと呼ばれます。
最適化されていないシャッフル パーティション数
構造化ストリーミングのクエリの間、Executor へのタスクの割り当ては、クラスターにとって多くのリソースを消費する操作です。 シャッフル データが最適なサイズでないと、タスクの遅延の量により、スループットと待ち時間に悪影響があります。 パーティションの数が少なすぎると、クラスター内のコアが十分に活用されず、処理効率が悪くなる可能性があります。 逆に、パーティションの数が多すぎる場合は、少数のタスクに対して多くの管理オーバーヘッドが生じます。
パーティション スキューとクラスター上の Executor の不適切な割り当てをトラブルシューティングするには、リソース使用量メトリックを使用します。 パーティションにスキューがある場合は、Executor リソースが、クラスターで実行されている他の Executor と比較して昇格されます。
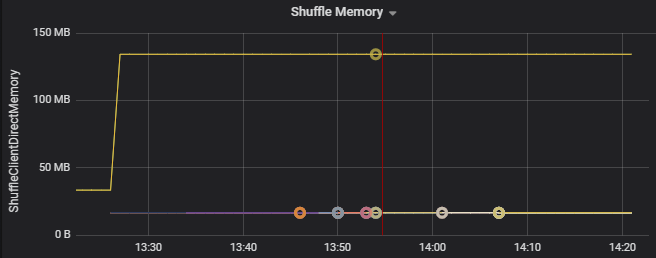
たとえば、次のグラフは、最初の 2 つの Executor でシャッフリングに使用されているメモリーが、他の Executor よりも 90X 大きいことを示しています。
次のステップ
- Azure Log Analytics ワークスペースでの Azure Databricks の監視
- ラーニング パス: Azure Databricks を使用した機械学習ソリューションの構築と運用
- Azure Databricks のドキュメント
- Azure Monitor の概要