Azure Kubernetes Service (AKS) を使用すると、運用上のオーバーヘッドが Azure クラウド プラットフォームにオフロードされるため、Azure でのマネージド Kubernetes クラスターのデプロイが簡素化されます。 ホストされた Kubernetes サービスとして、Azure によって正常性監視やメンテナンスなどの重要なタスクが処理されます。 AKS コントロール プレーンは Azure プラットフォームによって管理され、お使いのアプリケーションを実行する AKS ノードに対してのみ課金されます。
AKS クラスターは、さまざまなシナリオや方法で複数のテナント間で共有できます。 場合によっては、同じクラスター内で多様なアプリケーションを実行できます。 その他の場合は、同じアプリケーションの複数のインスタンスを、テナントごとに 1 つずつ、同じ共有クラスターで実行できます。 これらすべての種類の共有は、しばしば "マルチテナント" という包括的用語を使って説明されます。 Kubernetes にはエンドユーザーやテナントについての最上位の概念がありません。 それでも、さまざまなテナント要件を管理するのに役立ついくつかの機能が提供されます。
この記事では、マルチテナント システムを構築するときに役立つ AKS のいくつかの機能について説明します。 Kubernetes マルチテナントの一般的なガイダンスとベスト プラクティスについては、Kubernetes のドキュメントの「マルチテナント」を参照してください。
マルチテナント型
AKS クラスターを複数のテナント間で共有する方法を決定する最初の手順は、パターンとツールを自由に評価することです。 一般に、Kubernetes クラスターのマルチテナントは 2 つの主要なカテゴリに分類されますが、多くのバリエーションも可能です。 Kubernetes の ドキュメント では、マルチテナントの 2 つの一般的なユース ケースである複数のチームと複数の顧客について説明しています。
複数のチーム
マルチテナントの一般的な形式は、組織内の複数のチームでクラスターを共有することです。 各チームは、1 つ以上のソリューションをデプロイ、監視、運用できます。 多くの場合、これらのワークロードは相互に通信したり、同じクラスターまたは別のホスティング プラットフォーム上にある他の内部または外部のアプリケーションと通信したりする必要があります。
さらにこれらのワークロードは、同じクラスターでホストされているか、Azure 上で PaaS サービスとして実行されている、リレーショナル データベース、NoSQL リポジトリ、メッセージング システムなどのサービスと通信する必要があります。
このシナリオでは多くの場合、チームのメンバーは kubectl などのツールを使用して Kubernetes リソースに直接アクセスできます。 またはメンバーは、 Flux や Argo CD などの GitOps コントローラー、または他の種類のリリース自動化ツールを介して間接的にアクセスできます。
このシナリオの詳細については、Kubernetes のドキュメントの「複数のチーム」を参照してください。
複数の顧客
マルチテナントのもう 1 つの一般的な形式として、サービスとしてのソフトウェア (SaaS) ベンダーが含まれることがよくあります。 つまり、サービス プロバイダーは別々のテナントと見なされる顧客に対し、ワークロードの複数のインスタンスを実行します。 このシナリオでは、顧客は AKS クラスターに直接アクセスできませんが、自分のアプリケーションにのみアクセスできます。 加えて、顧客は自分のアプリケーションが Kubernetes で実行されていることも知りません。 コストの最適化がしばしば重大な懸念事項となります。 サービス プロバイダーは リソース クォータ や ネットワーク ポリシーなどの Kubernetes ポリシーを使用して、ワークロードが互いに明確に分離されるようにします。
このシナリオの詳細については、Kubernetes のドキュメントの「複数の顧客」を参照してください。
分離モデル
Kubernetes のドキュメントによると、マルチテナント Kubernetes クラスターは、一般的に "テナント" と呼ばれる複数のユーザーおよびワークロードによって共有されます。 この定義には、さまざまなチームまたは部門が組織内で共有する Kubernetes クラスターが含まれます。 また、サービスとしてのソフトウェア (SaaS) アプリケーションの顧客ごとのインスタンスによって共有されるクラスターも含まれます。
クラスター マルチテナント機能は、多数のシングルテナント専用クラスターを管理することに代わる手段です。 マルチテナントの Kubernetes クラスターのオペレーターは、テナントを相互に分離する必要があります。 この分離により、侵害されたテナントまたは悪意のあるテナントがクラスターや他のテナントに及ぼす可能性がある損害を最小限に抑えることができます。
決まった数のノードを持つ同じクラスターを複数のユーザーまたはチームで共有する場合、1 つのチームによって適正な分け前を超えるリソースが使用され得るという懸念があります。 リソース クォータ は、管理者がこの問題に対処するためのツールです。
分離によって提供されるセキュリティ レベルに基づき、ソフト マルチテナントとハード マルチテナントを区別できます。
- ソフト マルチテナントは、単一の企業内で、テナントが互いに信頼し合う異なるチームまたは部門である場合に適しています。 このシナリオでは、分離の目的は、ワークロードの整合性を保証し、クラスター リソースをさまざまな内部ユーザー グループ間で調整し、起こりうるセキュリティ攻撃から防御することです。
- ハード マルチテナントは、多くの場合にセキュリティとリソース共有の観点から、異種テナントが相互に信頼しないシナリオを記述するために使われます。
マルチテナントの Azure Kubernetes Service (AKS) クラスターの構築を計画する場合、 Kubernetesによって提供されている、次に示すリソース分離とマルチテナントのレイヤーを考慮する必要があります。
- クラスター
- 名前空間
- ノード プールまたはノード
- Pod
- コンテナー
また、複数のテナント間で異なるリソースを共有することによるセキュリティへの影響についても考慮する必要があります。 たとえば、同じノード上で異なるテナントからポッドをスケジュールすると、そのクラスターで必要なマシンの数を削減できる可能性があります。 一方、特定のワークロードが併置されないようにする必要がある場合もあります。 たとえば、ユーザーの組織外で作成された信頼できないコードは、機密情報を処理するコンテナーと同じノード上で実行しないようにすることができます。
Kubernetes では、テナント間の完全に安全な分離を保証することはできませんが、特定のユース ケースには十分と言って差し支えない機能が用意されています。 ベスト プラクティスとして、各テナントとその Kubernetes リソースを、それらの名前空間に分ける必要があります。 次いで、 Kubernetes のロールベースのアクセス制御 (RBAC) と ネットワーク ポリシー を使用して、テナントの分離を強制することができます。 たとえば、次の図では、同じクラスター上で同じアプリケーションの複数のインスタンスを、各テナントにつき 1 つホストする一般的な SaaS プロバイダー モデルを示しています。 各アプリケーションは、別々の名前空間に存在します。
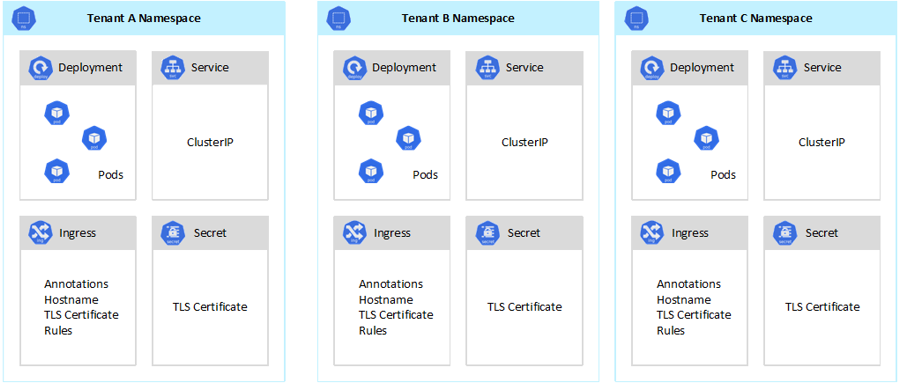
Azure Kubernetes Service (AKS) を使用してマルチテナント ソリューションを設計および構築するには、いくつかの方法があります。 これらの方法には、インフラストラクチャのデプロイ、ネットワーク トポロジ、およびセキュリティの観点から、それぞれ独自の一連のトレードオフがあります。 これらの方法は、分離レベル、実装作業、運用の複雑さ、コストに影響します。 自分の要件に基づいて、コントロール プレーンとデータ プレーンでテナントの分離を適用することができます。
コントロール プレーンの分離
コントロール プレーン レベルで分離する場合、異なるテナントが、ポッドやサービスなどの互いのリソースにアクセスしたり影響を与えたりできないことを保証できます。 また、それらは別のテナントのアプリケーションのパフォーマンスに影響を与えることはありません。 詳細については、Kubernetes のドキュメントの「コントロール プレーンの分離」を参照してください。 コントロール プレーン レベルで分離を実装する最善の方法は、各テナントのワークロードとその Kubernetes リソースを個別の名前空間に分離することです。
Kubernetes のドキュメントによると、 名前空間 は、1 つのクラスター内のリソース グループの分離をサポートするために使用される抽象化です。 名前空間を使用して、Kubernetes クラスターを共有しているテナント ワークロードを分離できます。
- 名前空間を使用すると、互いの作業に影響を与えるリスクを負わずに、個別のテナント ワークロードをそれぞれ独自の仮想ワークスペースに存在させることができます。 組織内の別々のチームは、名前空間を使用してプロジェクトを相互に分離できます。これは、名前が重複するリスクを負わずに、異なる名前空間で同じリソース名を使用できるためです。
- RBAC ロールとロール バインディング は、テナントユーザーとプロセスが、それらの名前空間内でのみリソースとサービスにアクセスできるように制限するためにチームが使用できる、名前空間スコープのリソースです。 さまざまなチームが、アクセス許可または機能のリストを 1 つの名前でグループ化するロールを定義できます。 次に、これらのロールをユーザー アカウントとサービス アカウントに割り当てて、承認された ID のみが特定の名前空間内のリソースにアクセスできるようにします。
- CPU とメモリのリソース クォータ は、名前空間指定のオブジェクトです。 チームではそれらを使用して、同じクラスターを共有しているワークロードが、システム リソースの消費から厳密に分離されるようにすることができます。 この方法により、個別の名前空間で実行されるすべてのテナント アプリケーションに、実行に必要なリソースが確保され、同じクラスターを共有する別のテナント アプリケーションに影響を与える可能性がある うるさい隣人の問題を回避できます。
- ネットワーク ポリシー は、特定のテナント アプリケーションで許可されるネットワーク トラフィックを強制するためにチームが採用できる、名前空間指定のオブジェクトです。 ネットワーク ポリシーを使用すると、同じクラスターを共有する個別のワークロードをネットワークの観点から分離できます。
- 異なる名前空間で実行されるチーム アプリケーションは、異なる サービス アカウントを使用して、同じクラスター、外部アプリケーション、またはマネージド サービス内のリソースにアクセスできます。
- 名前空間を使用して、コントロール プレーン レベルでのパフォーマンスを向上させてください。 共有クラスター内のワークロードが複数の名前空間に編成されている場合、Kubernetes API では、操作の実行時に検索する項目が少なくなります。 この編成により、API サーバーに対する呼び出しの待機時間を短縮し、コントロール プレーンのスループットを向上させることができます。
名前空間レベルでの分離の詳細については、Kubernetes のドキュメントの次のリソースを参照してください。
データ プレーンの分離
データ プレーンの分離により、異なるテナントのポッドとワークロードが互いに十分に分離されることが保証されます。 詳細については、Kubernetes のドキュメントの「データ プレーンの分離」を参照してください。
ネットワークの分離
Kubernetes で最新のマイクロサービス ベースのアプリケーションを実行するときは、どのコンポーネントが互いに通信できるかを制御したいことがよくあります。 既定では、AKS クラスター内のすべてのポッドは、同じクラスターを共有する他のアプリケーションを含め、トラフィックを制限なく送受信できます。 セキュリティを向上させるために、トラフィック フローを制御するネットワーク ルールを定義できます。 ネットワーク ポリシーは、ポッド間の通信のアクセス ポリシーを定義する Kubernetes の仕様です。 ネットワーク ポリシー を使用して、同じクラスターを共有するテナント アプリケーション間の通信を分離できます。
Azure Kubernetes Service (AKS) には、ネットワーク ポリシーを実装する 2 つの方法が用意されています。
- Azure には、Azure ネットワーク ポリシーと呼ばれるネットワーク ポリシーの実装があります。
- Calico ネットワーク ポリシー は、 Tigeraによって設立されたオープンソース ネットワークおよびネットワーク セキュリティ ソリューションです。
どちらの実装も Linux IPTables を使用して、指定されたポリシーを適用します。 ネットワーク ポリシーは、許可される IP ペアと許可されない IP ペアのセットに変換されます。 その後、これらのペアは IPTable フィルタ ルールとしてプログラミングされます。 Azure ネットワーク ポリシーは、 Azure CNI ネットワーク プラグインで構成された AKS クラスターでのみ使用できます。 ただし、Calico ネットワーク ポリシーでは、 Azure CNI と kubenetの両方がサポートされています。 詳細については、「Azure Kubernetes Service のネットワーク ポリシーを使用したポッド間のトラフィックの保護」を参照してください。
詳細については、Kubernetes のドキュメントの「ネットワークの分離」を参照してください。
記憶域の分離
Azure には、 Azure SQL Database や Azure Cosmos DBなどの管理対象の PaaS (サービスとしてのプラットフォーム) データ リポジトリの豊富なセットと、ワークロードの 永続ボリューム として使用できるその他のストレージ サービスが用意されています。 共有 AKS クラスターで実行されているテナント アプリケーションは、 データベースまたはファイル ストアを共有 することも、 専用のデータ リポジトリとストレージ リソースを使用することもできます。 マルチテナント シナリオでデータを管理するためのさまざまな戦略とアプローチの詳細については、「マルチテナント ソリューションでのストレージとデータのアーキテクチャ アプローチ」を参照してください。
Azure Kubernetes Service (AKS) で実行されているワークロードでは、永続ボリュームを使用してデータを格納することもできます。 Azure では、Azure Storage によってサポートされる Kubernetes リソースとして 永続ボリューム を作成できます。 データ ボリュームを手動で作成してポッドに直接割り当てることもできます。また、 永続ボリューム要求を使用して AKS で自動的に作成することもできます。 AKS には、 Azure ディスク、 Azure Files、 Azure NetApp Filesによってサポートされる永続ボリュームを作成するための組み込みのストレージ クラスが用意されています。 詳細については、「Azure Kubernetes Service (AKS) でのアプリケーションのストレージ オプション」を参照してください。 セキュリティと回復性の理由から、 emptyDir と hostPathを介してエージェント ノードでローカル ストレージを使用しないようにしてください。
AKS の 組み込みストレージ クラス が 1 つ以上のテナントに適していない場合は、さまざまなテナント要件に対応するカスタム ストレージ クラス を構築できます。 これらの要件には、ボリューム サイズ、ストレージ SKU、サービス レベル アグリーメント (SLA)、バックアップ ポリシー、価格レベルが含まれます。
たとえば、テナントごとにカスタム ストレージ クラスを構成できます。 その後、それを使用して、名前空間内に作成されたあらゆる永続ボリュームにタグを適用して、コストをそれらにチャージバックすることができます。 このシナリオの詳細については、「Azure Kubernetes Service (AKS) での Azure タグの使用」を参照してください。
詳細については、Kubernetes のドキュメントの「ストレージの分離」を参照してください。
ノードの分離
テナント ワークロードを個別のエージェント ノードで実行するように構成することで、 うるさい隣人の問題 を回避し、情報漏えいのリスクを軽減できます。 AKS では、分離、セキュリティ、規制コンプライアンス、パフォーマンスの厳密な要件を持つテナント用に、個別のクラスターや専用ノード プールのみを作成できます。
テイント、 容認、 ノード ラベル、 ノード セレクター、 ノード アフィニティ を使用して、テナント ポッドをノードまたはノード プールの特定のセットでのみ実行するように制限できます。
一般に、AKS はさまざまなレベルでワークロードの分離を提供します。
- カーネル レベルでは、共有エージェント ノード上の軽量仮想マシンでテナント ワークロードを実行し、 Kata コンテナーに基づく ポッド サンドボックス を使用します。
- 物理レベルでは、専用クラスターまたはノード プールでテナント アプリケーションをホストします。
- ハードウェア レベルでは、エージェント ノード VM が専用の物理マシンを実行することを保証する Azure 専用ホスト上でテナント ワークロードを実行します。 ハードウェアの分離により、他の仮想マシンが専用ホストに配置されなくなり、テナント ワークロードに対して分離レイヤーが追加されます。
これらの手法を組み合わせることができます。 たとえば、 Azure Dedicated Host グループ でテナントごとのクラスターとノード プールを実行して、ハードウェア レベルでワークロードの分離と物理的な分離を実現できます。 また、 Federal Information Process Standard (FIPS)、 Confidential Virtual Machines (CVM)、または ホストベースの暗号化をサポートする共有ノード プールまたはテナントごとのノード プールを作成することもできます。
ノード分離を使用すると、ノードまたはノード プールのセットのコストを 1 つのテナントに簡単に関連付けてチャージバックできます。 これは、ご使用のソリューションで採用されているテナント モデルに厳密に関連しています。
詳細については、Kubernetes のドキュメントの「ノードの分離」を参照してください。
テナント モデル
Azure Kubernetes Service (AKS) には、より多くの種類のノード分離モデルとテナント モデルが用意されています。
自動シングルテナント デプロイ
自動シングルテナント デプロイ モデルでは、次の例に示すように、テナントごとに専用のリソース セットをデプロイします。
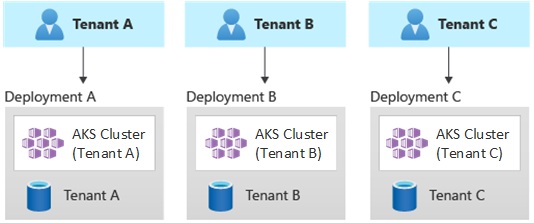
各テナント ワークロードは専用の AKS クラスターで実行され、Azure リソースの個別のセットにアクセスします。 通常、このモデルを使用して構築されたマルチテナント ソリューションでは、 コードとしてのインフラストラクチャ(IaC) が広範に使用されます。 たとえば、 Bicep、 Azure Resource Manager、 Terraform、または Azure Resource Manager REST API は、テナント専用リソースのオンデマンド デプロイの開始と調整に役立ちます。 この方法は、顧客ごとに完全に個別のインフラストラクチャをプロビジョニングする必要があるときに使用できます。 デプロイを計画するときは、 デプロイ スタンプ パターンを考慮してください。
メリット:
- この方法の主なメリットは、各テナント AKS クラスターの API サーバーが独立していることです。 この方法では、セキュリティ、ネットワーク、リソース消費のレベルから、テナント全体にわたる完全な分離が保証されます。 コンテナーの制御を取得しようとする攻撃者は、1 つのテナントに属するマウント済みのコンテナーとボリュームにのみアクセスできます。 完全分離テナンシー モデルは、規制コンプライアンスのオーバーヘッドが高い一部のお客様にとって重要です。
- テナントが互いのシステム パフォーマンスに影響することはほとんどないため、これによって うるさい隣人の問題を回避できます。 この考慮事項には、API サーバーに対するトラフィックが含まれます。 API サーバーは、任意の Kubernetes クラスター内で共有される重要なコンポーネントです。 API サーバーに対して規制されていない大量のトラフィックを生成するカスタム コントローラーは、クラスターの不安定性を引き起こす可能性があります。 この不安定性により、要求の失敗、タイムアウト、API の再試行ストームが発生します。 アップタイム SLA (サービス レベル アグリーメント) 機能を使用すると、トラフィックの需要を満たすために AKS クラスターのコントロール プレーンをスケールアウトできます。 ただし、専用クラスターをプロビジョニングすると、ワークロードの分離という点で厳しい要件を持つお客様にとっては、より優れたソリューションになる場合もあります。
- 更新と変更はテナント間で徐々にロールアウトすることができるため、システム全体の障害が発生する可能性が減ります。 どのリソースも 1 つのテナントによって使用されるため、Azure のコストをテナントに簡単にチャージバックできます。
リスク:
- すべてのテナントで専用のリソース セットが使用されるため、コスト効率は低くなります。
- 継続的なメンテナンスに時間がかかることがあります。これは、テナントごとに 1 つずつ、複数の AKS クラスターにわたってレプリケートする必要があるためです。 運用プロセスを自動化することと、環境全体で変更を段階的に適用することを検討してください。 また、資産全体でのレポートや分析など、他のデプロイ間操作を検討すると役立つ場合もあります。 同様に、複数のデプロイ間でデータを照会および操作する方法も計画するようにしてください。
完全なマルチテナント デプロイ
完全マルチテナント デプロイでは、1 つのアプリケーションですべてのテナントの要求が処理され、AKS クラスターを含むすべての Azure リソースが共有されます。 このコンテキストでは、デプロイ、監視、保守するインフラストラクチャのセットは 1 つだけです。 次の図に示すように、リソースがすべてのテナントで使用されます。
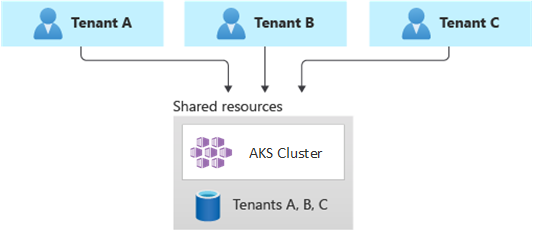
利点:
- 共有コンポーネントを使用してソリューションを運用するコストが低いため、このモデルは魅力的です。 このテナント モデルを使用する場合は、データ リポジトリなどのすべてのテナントのリソースによって生成されるトラフィックを維持するために、大きな AKS クラスターをデプロイし、すべての共有データ リポジトリに対して高い SKU を採用することが必要になる場合があります。
リスク:
- このコンテキストでは、1 つのアプリケーションですべてのテナントの要求を処理します。 テナントが呼び出しでアプリケーションを飽和状態にしないように、セキュリティ対策を設計して実装する必要があります。 これらの呼び出しにより、システム全体の速度が低下し、すべてのテナントに影響を与える可能性があります。
- トラフィック プロファイルが大きく変動する場合は、ポッドとエージェント ノードの数を変更するように AKS クラスター オートスケーラーを構成する必要があります。 構成は、CPU やメモリなどのシステム リソースの使用量に基づいて行います。 または、カスタム メトリックに基づいて、ポッドとクラスター ノードの数をスケール アウトしたりスケール インしたりすることもできます。 たとえば、保留中の要求の数や、 Kubernetes イベント ドリブン自動スケール (KEDA) を使用する外部メッセージング システムのメトリックを調べることができます。
- テナントごとにデータを分離し、異なるテナント間のデータ漏えいを回避するための保護機能を実装してください。
- 実際の使用状況に基づいて、 Azure のコストを追跡し、個々のテナントに関連付ける 必要があります。 kubecost などのサードパーティ ソリューションは、さまざまなチームやテナントのコストを計算して明細を示すのに役立つことがあります。
- Azure リソースのセットを 1 つだけ更新し、1 つのアプリケーションを維持するだけで済むため、1 つのデプロイではメンテナンスがより簡単になることがあります。 ただし、インフラストラクチャまたはアプリケーション コンポーネントに対する変更が顧客ベース全体に影響を与える可能性があるため、多くの場合はリスクが高くなります。
- スケールの制限も考慮する必要があります。 リソースのセットを共有している場合は、Azure リソースのスケールの上限に到達する可能性が高くなります。 リソース クォータ制限に達しないように、テナントを複数の Azure サブスクリプションに分散することを検討してください。
水平方向にパーティション分割されたデプロイ
別の方法として、マルチテナント Kubernetes アプリケーションを水平方向にパーティション分割することを検討できます。 このアプローチは、一部のソリューション コンポーネントをすべてのテナント間で共有する方法と、個々のテナントに専用リソースをデプロイする方法で構成されます。 たとえば、次の図に示すように、1 つのマルチテナント Kubernetes アプリケーションを構築してから、テナントごとに 1 つずつ、個別のデータベースを作成することができます。
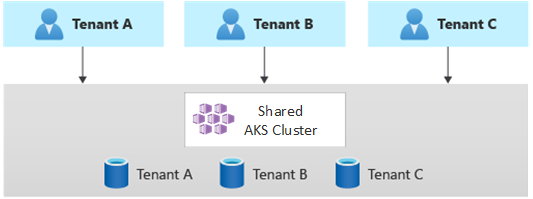
メリット:
- 水平方向にパーティション分割されたデプロイは、うるさい隣人の問題を軽減するのに役立ちます。 Kubernetes アプリケーションのトラフィック負荷の大部分が、テナントごとに個別にデプロイできる特定のコンポーネントが原因であることが判明した場合は、このアプローチを検討してください。 たとえば、クエリの負荷が高いため、システムの負荷の大部分がデータベースによって占められる場合があります。 1 つのテナントから大量の要求がソリューションに送信されると、1 つのデータベースのパフォーマンスは低下する可能性がありますが、他のテナントのデータベース (およびアプリケーション層などの共有コンポーネント) は影響を受けません。
リスク:
- 水平方向にパーティション分割されたデプロイを使用する場合でも、コンポーネント (特に、1 つのテナントで使用されるコンポーネント) のデプロイと管理を自動化することを検討する必要があります。
- このモデルでは、他のテナントとリソースを共有できない顧客にとって、内部ポリシーまたはコンプライアンス上の理由から、必要なレベルの分離が提供されない可能性があります。
垂直方向にパーティション分割されたデプロイ
テナントを複数の AKS クラスターまたはノード プール間で垂直方向にパーティション分割するハイブリッド モデルを使用することで、シングルテナント モデルと完全マルチテナント モデルの利点を活用できます。 このアプローチでは、前の 2 つのテナンシー モデルに比べて次の利点があります。
- シングルテナント デプロイとマルチテナント デプロイを組み合わせて使用できます。 たとえば、ほとんどの顧客には、マルチテナント インフラストラクチャ上の AKS クラスターとデータベースを共有させることができます。 その上で、より高いパフォーマンスと分離を必要とする顧客に対して、シングルテナント インフラストラクチャをデプロイすることもできます。
- 構成が異なる可能性がある複数のリージョン AKS クラスターにテナントをデプロイできます。 この手法は、テナントがさまざまな地域に分散している場合に最も効果的です。
このテナント モデルのさまざまなバリエーションを実装できます。 たとえば、さまざまなコストでさまざまな機能レベルを備えたマルチテナント ソリューションを提供することも選択できます。 価格モデルでは、リソース共有、パフォーマンス、ネットワーク、データ分離の観点から複数の SKU を提供し、それぞれパフォーマンスと分離のレベルが段階的に増えていくものとすることができます。 次のレベルを検討してください。
- Basic レベル: テナント要求は、他のテナントと共有される単一のマルチテナント Kubernetes アプリケーションによって処理されます。 データは、すべての Basic レベルのテナントによって共有される 1 つ以上のデータベースに格納されます。
- Standard レベル: テナント要求は、セキュリティ、ネットワーク、リソース消費の観点から分離の境界を提供する個別の名前空間で実行される専用の Kubernetes アプリケーションによって処理されます。 テナントごとに 1 つずつあるすべてのテナントのアプリケーションでは、同じ AKS クラスターとノード プールが他の Standard レベルの顧客との間で共有されます。
- Premium レベル: テナント アプリケーションは専用のノード プールまたは AKS クラスターで実行されるため、より高いサービス レベルアグリーメント、パフォーマンスの向上、より高い分離度が保証されます。 このレベルでは、テナント アプリケーションのホストに使用されるエージェント ノードの数と SKU に基づいて、柔軟なコスト モデルを提供できます。 ポッド サンドボックス は、専用クラスターまたはノード プールを使用して個別のテナント ワークロードを分離するための代替ソリューションとして使用できます。
次の図は、テナント A と B が共有 AKS クラスターで実行され、テナント C が別の AKS クラスターで実行されるシナリオを示しています。
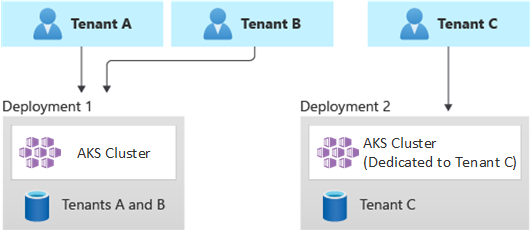
同様に、次の図は、テナント A と B が同じノード プールで実行され、テナント C が専用のノード プールで実行されるシナリオを示しています。
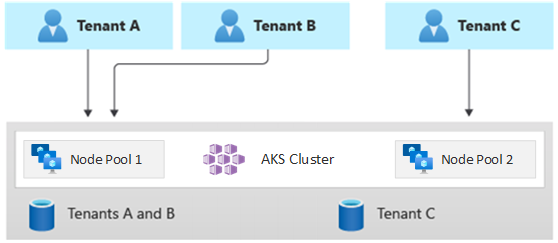
このモデルでは、レベルごとに異なるサービス レベル アグリーメントを提供することもできます。 たとえば、Basic レベルでは 99.9% のアップタイムを提供でき、Standard レベルでは 99.95% のアップタイムを提供でき、Premium レベルでは 99.99% を提供できます。 より高いサービス レベル アグリーメント (SLA) は、より高い可用性の目標を実現するサービスと機能を使用して実装できます。
メリット:
- 依然としてインフラストラクチャを共有しているため、共有マルチテナント デプロイを使用することのコスト面での利点を引き続きいくらか得られます。 エージェント ノードに対して割安な VM サイズを使用する、複数の Basic レベルおよび Standard レベルのテナント アプリケーション間で共有されるクラスターとノード プールをデプロイできます。 このアプローチにより、より高い密度とコスト削減が保証されます。 Premium レベルの顧客の場合は、VM サイズが大きく、ポッド レプリカとノードの数を最大にした AKS クラスターとノード プールを、より高い価格でデプロイできます。
- CoreDNS、 Konnectivity、 Azure Application Gateway イングレス コントローラーなどのシステム サービスを、専用のシステム モード ノード プールで実行できます。 テイント、 容認、 ノード ラベル、 ノード セレクター、 ノード アフィニティ を使用して、1 つ以上のユーザー モード ノード プールでテナント アプリケーションを実行できます。
- テイント、 容認、 ノード ラベル、 ノード セレクター、 ノード アフィニティ を使用して、共有リソースを実行できます。 たとえば、イングレス コントローラーまたはメッセージング システムを専用ノード プール上に設定し、特定の VM サイズ、自動スケーラー設定、可用性ゾーンをサポートすることができます。
リスク:
- マルチテナントとシングルテナントの両方のデプロイをサポートするように Kubernetes アプリケーションを設計する必要があります。
- インフラストラクチャ間の移行を許可することを計画している場合は、顧客をマルチテナント デプロイから独自のシングルテナント デプロイに移行する方法を検討する必要があります。
- より多くの AKS クラスターを監視および管理するには、一貫性のある戦略と 1 つのウィンドウ (1 つの視点) が必要です。
自動スケール
テナント アプリケーションによって生成されるトラフィック需要に対応するために、 クラスター オートスケーラー で Azure Kubernetes Service (AKS) のエージェント ノードをスケールアップできるようにすることが可能です。 自動スケールは、次の状況でシステムの応答性を維持するのに役立ちます。
- 特定の作業時間や 1 年のうちの特定の期間にトラフィックの負荷が増加する。
- テナントまたは共有される負荷がクラスターにデプロイされる。
- ゾーン障害により、エージェント ノードが使用できなくなる。
ノード プールの自動スケールを有効にする場合は、予想されるワークロード サイズに基づいてノードの最小数と最大数を指定します。 ノードの最大数を構成することで、それらが実行されている名前空間に関係なく、クラスター内のすべてのテナント ポッドに対して十分な領域を確保できます。
トラフィックが増加すると、クラスターの自動スケールによって新しいエージェント ノードが追加され、CPU とメモリの観点でリソースが不足することによりポッドが保留中の状態になることを防ぐことができます。
同様に、負荷が減少すると、クラスターの自動スケールによって、指定された境界に基づいてノード プール内のエージェント ノードの数が減り、運用コストの削減に役立ちます。
ポッドの自動スケールを使用すると、リソースの需要に基づいてポッドを自動的にスケーリングできます。 ポッドの水平オートスケーラー (HPA) は、CPU またはメモリの使用率またはカスタム メトリックに基づいて、ポッド レプリカの数を自動的にスケーリングします。 Kubernetes イベント ドリブン自動スケール (KEDA) を使用すると、テナント アプリケーションで使用される Azure Event Hubs や Azure Service Bus などの外部システムのイベントの数に基づいて、Kubernetes 内の任意のコンテナーのスケーリングを実行できます。
メンテナンス
クラスターまたはノード プールのアップグレード中にテナント アプリケーションに影響を与える可能性のあるダウンタイムのリスクを軽減するには、AKS 計画メンテナンスがピーク時間外に発生するようにスケジュールします。 計画メンテナンスを使用すると、テナント アプリケーションとノード プールを実行する AKS クラスターのコントロール プレーンを更新するように毎週のメンテナンス期間をスケジュールできます。これにより、ワークロードへの影響を最小限に抑えることができます。 曜日や特定の日の時間の範囲を指定して、クラスター上で 1 つまたは複数の毎週のメンテナンス期間をスケジュールすることができます。 すべてのメンテナンス操作は、スケジュールされた期間中に行われます。
セキュリティ
クラスターへのアクセス
組織内の複数のチームで AKS クラスターを共有する場合は、異なるテナントを互いに分離するために 最小特権の原則 を実装する必要があります。 特に、 kubectl、 Helm、 Flux、 Argo CDなどのツールやその他の種類のツールを使用する場合は、ユーザーが Kubernetes の名前空間とリソースにのみアクセスできるようにする必要があります。
AKS での認証と承認の詳細については、次の記事を参照してください。
- Azure Kubernetes Service (AKS) でのアクセスと ID オプション
- AKS マネージド Microsoft Entra の統合
- Azure Kubernetes Service で Kubernetes のロールベースのアクセス制御と Microsoft Entra ID を使用してクラスター リソースへのアクセスを制限する
ワークロード ID
1 つの AKS クラスターに複数のテナント アプリケーションをホストし、それぞれが別々の名前空間にある場合、各ワークロードは異なる Kubernetes サービス アカウント と資格情報を使用してダウンストリームの Azure サービスにアクセスする必要があります。 "サービス アカウント" は、Kubernetes のプライマリ ユーザー タイプの 1 つです。 Kubernetes API により、サービス アカウントが保持および管理されます。 サービス アカウントの資格情報は Kubernetes シークレットとして保管され、これによって承認されたポッドが API サーバーと通信するためにこれらを使用できます。 ほとんどの API 要求では、サービス アカウントまたは通常のユーザー アカウント用の認証トークンが提供されします。
AKS クラスターにデプロイされたテナント ワークロードでは、Microsoft Entra アプリケーションの資格情報を使って、Azure Key Vault や Microsoft Graph などの Microsoft Entra ID で保護されたリソースにアクセスすることができます。 Kubernetes の Microsoft Entra ワークロード ID は、外部の ID プロバイダーと連携するために Kubernetes ネイティブ機能と統合されます。
ポッド サンドボックス
AKS には、コンテナー アプリケーションとコンテナー ホストの共有カーネルやCPU、メモリ、ネットワークなどのコンピューティング リソースとの間に分離境界を提供する、 ポッド サンドボックス と呼ばれるメカニズムが含まれています。 ポッド サンドボックスは、テナント ワークロードが機密情報を保護し、支払いカード業界データ セキュリティ標準 (PCI DSS)、国際標準化機構 (ISO) 27001、医療保険の携行性と責任に関する法律 (HIPAA) などの規制、業界、またはガバナンスのコンプライアンス要件を満たすために役立つ、他のセキュリティ対策またはデータ保護制御を補完します。
個別のクラスターまたはノード プールにアプリケーションをデプロイすると、さまざまなチームや顧客のテナント ワークロードを強力に分離できます。 複数のクラスターとノード プールの使用は、多くの組織と SaaS ソリューションの分離要件に適している場合がありますが、信頼されていないポッドと信頼されているポッドを同じノードで実する場合や、ローカル通信の高速化と機能グループ化のためにデーモン セットと特権コンテナーを同じノードに配置する場合など、VM ノード プールを共有する単一クラスターの方が効率的なシナリオもあります。 ポッド サンドボックス は、これらのワークロードを個別のクラスターまたはノード プールで実行する必要がない場合でも、同じクラスター ノード上のテナント アプリケーションを強力に分離するのに役立ちます。 他の方法では、コードを再コンパイルする必要や、他の互換性の問題が引き起こされることがありますが、AKS のポッド サンドボックスでは、セキュリティが強化された VM 境界内で、いかなるコンテナーも変更せずに実行できます。
AKS のポッド サンドボックスは、ハードウェア強制の分離を提供するために、 AKS スタック用の Azure Linux コンテナー ホスト 上で実行される Kata コンテナー に基づいています。 AKS 上の Kata コンテナーは、セキュリティが強化された Azure ハイパーバイザー上に構築されています。 ポッドごとの分離は、親 VM ノードからのリソースを利用する入れ子になった軽量 Kata VM を介して実現されます。 このモデルでは、各 Kata ポッドは、入れ子になった Kata ゲスト VM で独自のカーネルを取得します。 このモデルを使用すると、親 VM でコンテナーを継続的に実行しながら、単一のゲスト VM に多数の Kata コンテナーを配置できます。 このモデルは、共有 AKS クラスターで強力な分離境界を提供します。
詳細については、次を参照してください。
Azure Dedicated Host
Azure Dedicated Host には、単一の Azure サブスクリプション専用の物理サーバーが用意されており、物理サーバー レベルでハードウェアを分離するサービスです。 これらの専用ホストは、リージョン、可用性ゾーン、障害ドメイン内にプロビジョニングでき、プロビジョニングされたホストに VM を直接配置できます。
AKS での Azure Dedicated Host の使用は、次のようないくつかの利点があります。
ハードウェアの分離により、他の VM が専用ホストに配置されなくなり、テナント ワークロードに対して分離レイヤーが追加されます。 専用ホストは同じデータセンターに展開され、他の分離されていないホストと同じネットワークおよび基になるストレージ インフラストラクチャを共有します。
Azure Dedicated Host では、Azure プラットフォームで開始されるメンテナンス イベントを制御できます。 メンテナンス期間を選択すると、サービスへの影響を軽減し、テナント ワークロードの可用性とプライバシーを確保できます。
Azure Dedicated Host は、SaaS プロバイダーでテナント アプリケーションが機密情報を保護するための規制、業界、ガバナンスのコンプライアンス要件を満たすのに役立ちます。 詳細については、「Azure Kubernetes Service (AKS) クラスターに Azure Dedicated Host を追加する」を参照してください。
機密仮想マシン
機密仮想マシン (CVM) を使用して、1 つ以上のノード プールを AKS クラスターに追加して、テナントの厳格な分離、プライバシー、およびセキュリティ要件に対処できます。 CVM では、ハードウェア ベースの 高信頼実行環境 (TEE)を使用します。 AMD Secure Encrypted Virtualization - Secure Nested Paging (SEV-SNP) 機密 VM は、ハイパーバイザーやその他のホスト管理コードによる VM メモリや状態へのアクセスを拒否し、オペレーター アクセスに対する多層防御層を追加します。 詳細については、「AKS クラスターで CVM を使用する」を参照してください。
連邦情報処理標準 (FIPS)
Federal Information Processing Standards (FIPS) 140-3 は、情報技術の製品やシステムに含まれる暗号化モジュールに関して最低限のセキュリティ要件を規定する米国政府の規格です。 AKS ノード プール向け FIPS コンプライアンスを有効にすることで、テナント ワークロードの分離、プライバシー、セキュリティを強化できます。 FIPS コンプライアンスにより、暗号化、ハッシュ、その他のセキュリティ関連操作に対する検証済みの暗号化モジュールの使用が保証されます。 FIPS 対応 AKS ノード プールを使用すると、堅牢な暗号化アルゴリズムとメカニズムを採用することで、規制と業界のコンプライアンス要件を満たすことができます。 Azure には、AKS ノード プールに対して FIPS を有効にする方法に関するドキュメントが用意されており、マルチテナント AKS 環境のセキュリティ体制を強化できます。 詳細については、「AKS ノード プール向け FIPS を有効にする」を参照してください。
Azure ディスクでの Bring Your Own Key (BYOK) の使用
Azure Storage は、AKS クラスターの OS やデータ ディスクなど、静止状態のストレージ アカウントですべてのデータを暗号化します。 規定では、データは Microsoft のマネージド キーで暗号化されます。 暗号化キーの制御を強化するために、AKS クラスターの OS ディスクとデータ ディスクの暗号化に使用する目的でカスタマーマネージド キーを提供できます。 詳細については、次を参照してください。
ホストベースの暗号化
AKS 上でのホストベースの暗号化 により、テナント ワークロードの分離、プライバシー、セキュリティがさらに強化されます。 ホストベースの暗号化を有効にすると、AKS は基になるホスト マシン上で保存データを暗号化し、機密性の高いテナント情報を未承認のアクセスから確実に保護します。 エンドツーエンド暗号化を有効にすると、一時ディスクとエフェメラル OS ディスクは保存時に、プラットフォーム マネージド キーを使用して暗号化されます。
AKS では、既定で OS ディスクとデータ ディスクでプラットフォーム マネージド キーによるサーバー側暗号化が使われます。 これらのディスクのキャッシュは、プラットフォーム マネージド キーを使って保存時に暗号化されます。 エンベロープ暗号化 (別名: ラップ) を使用して、独自の キー暗号化キー (KEK) を指定して データ保護キー (DEK) を暗号化できます。 OS ディスクとデータ ディスクのキャッシュも、指定した BYOK を介して暗号化されます。
ホストベースの暗号化により、マルチテナント環境のセキュリティ層が追加されます。 OS とデータ ディスクのキャッシュ内の核テナントのデータは、選択されたディスクの暗号化の種類に応じて、カスタマー マネージド キーまたはプラットフォーム マネージド キーのいずれかを使用して保存時に暗号化されます。 詳細については、次を参照してください。
ネットワーク
API サーバーへのネットワーク アクセスを制限する
Kubernetes では、API サーバーは、リソースの作成やノードの数のスケーリングなどのクラスター内のアクションを実行するための要求を受信します。 組織内の複数のチームで AKS クラスターを共有する場合は、次のいずれかのソリューションを使用してコントロール プレーンへのアクセスを保護します。
プライベート AKS クラスター
プライベート AKS クラスターを使用すると、API サーバーとノード プールの間のネットワーク トラフィックが仮想ネットワーク内に存在するようにすることができます。 プライベート AKS クラスターでは、コントロール プレーンまたは API サーバーに、AKS クラスターの同じ仮想ネットワーク内にある Azure プライベート エンドポイント経由でのみアクセスできる内部 IP アドレスがあります。 同様に、同じ仮想ネットワーク内のすべての仮想マシンは、プライベート エンドポイントを介してコントロール プレーンとプライベートに通信できます。 詳細については、「プライベート Azure Kubernetes Service クラスターを作成する」を参照してください。
承認された IP
クラスターのセキュリティを向上させ、攻撃を最小限に抑えるための 2 つ目のオプションは、承認された IP を使用することです。 このアプローチでは、パブリック AKS クラスターのコントロール プレーンへのアクセスを、インターネット プロトコル (IP) アドレスとクラスレス ドメイン間ルーティング (CIDR) の既知の一覧に制限します。 承認された IP を使用すると、それらは引き続きパブリックに公開されますが、アクセスは一連の IP 範囲に制限されます。 詳細については「Azure Kubernetes Service (AKS) で許可された IP アドレス範囲を使用して API サーバーへのアクセスをセキュリティで保護する」を参照してください。
Private Link 統合
Azure Private Link サービス (PLS) は、仮想ネットワークで定義され、 Azure Load Balancer (ALB) インスタンスのフロントエンド IP 構成に接続されている Azure プライベート エンドポイント (PE) を介して、アプリケーションがサービスにプライベートに接続できるようにするインフラストラクチャ コンポーネントです。 Azure Private Link を使用すると、サービス プロバイダーはデータ流出のリスクを負うことなく Azure 内またはオンプレミスから接続できるテナントにサービスを安全に提供できます。
Azure Private Link サービス統合を使用すると、AKS でホストされるワークロードへのプライベート接続を安全な方法でテナントに提供でき、パブリック インターネット上でパブリック エンドポイントを公開する必要はありません。
Azure でホストされたマルチテナント ソリューション用に Private Link を構成する方法に関する一般的なガイダンスについては、「マルチテナント機能と Azure Private Link」を参照してください。
リバース プロキシ
リバース プロキシ は、受信要求のセキュリティ保護、フィルター処理、ディスパッチを行うためにテナント アプリケーションのフロント側で通常使用されるロード バランサーと API ゲートウェイ です。 一般的なリバース プロキシでは、負荷分散、SSL ターミネーション、第 7 層のルーティングなどの機能がサポートされています。 リバース プロキシは通常、セキュリティ、パフォーマンス、信頼性を向上させるために実装されます。 Kubernetes の一般的なリバース プロキシには、次の実装が含まれます。
- NGINX イングレス コントローラー は、負荷分散、SSL ターミネーション、第 7 層のルーティングなどの高度な機能をサポートする一般的なリバース プロキシ サーバーです。
- Traefik Kubernetes イングレス プロバイダー は、イングレス仕様をサポートすることでクラスター サービスへのアクセスを管理するために使用できる Kubernetes イングレス コントローラーです。
- HAProxy Kubernetes イングレス コントローラー は、TLS ターミネーション、URL パス ベースのルーティングなどの標準機能をサポートする Kubernetes のもう 1 つのリバース プロキシです。
- Azure Application Gateway イングレス コントローラー (AGIC) は、テナント アプリケーションをパブリック インターネットに公開するか、仮想ネットワークで実行される他のシステムに内部的に公開するために、Azure Kubernetes Service (AKS) のお客様が Azure のネイティブ Application Gateway L7 ロード バランサーを利用できるようにする Kubernetes アプリケーションです。
AKS でホストされるリバース プロキシを使用して、複数のテナント アプリケーションへの受信要求をセキュリティで保護して処理する場合は、次の推奨事項を考慮してください。
- リバース プロキシは、高ネットワーク帯域幅と 高速ネットワーク が可能な VM サイズを使用するように構成された専用ノード プールでホストします。
- 自動スケール用にリバース プロキシをホストするノード プールを構成します。
- テナント アプリケーションの待機時間の増加とタイムアウトを回避するには、自動スケール ポリシーを定義して、イングレス コントローラー ポッドの数がトラフィックの変動に一致するようにすぐに拡張および縮小できるようにします。
- スケーラビリティと分離レベルを高めるために、イングレス コントローラーの複数のインスタンス間でテナント アプリケーションへの受信トラフィックをシャーディングすることを検討してください。
Azure Application Gateway イングレス コントローラー (AGIC) を使用する場合は、次のベスト プラクティスを実装することを検討してください。
- 自動スケール のためにイングレス コントローラーによって使用される Application Gatewayを構成します。 自動スケーリングを有効にすると、Application Gateway と WAF v2 SKU は、アプリケーションのトラフィック要件に基づいて、スケールアウトまたはスケールインします。 このモードでは、アプリケーションに対して優れた柔軟性が提供され、アプリケーション ゲートウェイのサイズまたはインスタンスの数を推測する必要がなくなります。 また、このモードでは、予想される最大トラフィック負荷に対するピーク時のプロビジョニング容量でゲートウェイを実行する必要がないので、コストを節約することもできます。 最小の (および必要に応じて最大の) インスタンス数を指定する必要があります。
- テナント アプリケーションの数が サイトの最大数を超える場合は、それぞれ個別の Application Gateway に関連付けられた、 Application Gateway イングレス コントローラー (AGIC)の複数のインスタンスをデプロイすることを検討してください。 各テナント アプリケーションが専用の名前空間で実行されていることを前提とすると、 複数の名前空間サポート を使用して、 Application Gateway イングレス コントローラー (AGIC) のより多くのインスタンスにわたってテナント アプリケーションを分散させます。
Azure Front Door との統合
Azure Front Door は、グローバルな第 7 層のロード バランサーおよび Microsoft の最新のクラウド コンテンツ配信ネットワーク (CDN) であり、世界中のユーザーと Web アプリケーションの間で、高速で信頼性が高く、セキュリティで保護されたアクセスを提供します。 Azure Front Door では、AKS でホストされるマルチテナント アプリケーションをパブリック インターネットに公開するときに利用できる、要求高速化、SSL ターミネーション、応答キャッシュ、エッジでの WAF、URL ベースのルーティング、書き換え、リダイレクトなどの機能がサポートされています。
たとえば、AKS でホストされるマルチテナント アプリケーションを使用して、すべての顧客の要求に対応する必要がある場合があります。 この状況では、Azure Front Door を使用して、テナントごとに 1 つずつ、複数のカスタム ドメインを管理できます。 エッジで SSL 接続を終了し、1 つのホスト名で構成された AKS でホストされるマルチテナント アプリケーションに、すべてのトラフィックをルーティングできます。
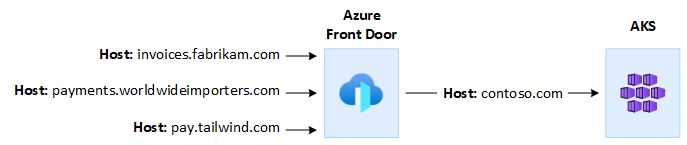
要求元ホスト ヘッダー を変更して、バックエンド アプリケーションのドメイン名と一致するようにするように Azure Front Door を構成できます。 クライアントから送信された元の Host ヘッダーは、 X-Forwarded-Host ヘッダーによって伝達されます。マルチテナント アプリケーション コードでは、この情報を使用することで 適切なテナントに着信要求をマップできるようになります。
Azure Front Door の Azure Web Application Firewall (WAF) は、Web アプリケーションに対する一元的な保護を提供します。 Azure WAF を使用して、インターネット上のパブリック エンドポイントを公開する AKS でホストされるテナント アプリケーションを悪意のある攻撃から保護できます。
Azure Front Door Premium を構成して、 Azure Private Link サービスを使用することによって、内部ロード バランサーの配信元を介して、AKS クラスターで実行される 1 つ以上のテナント アプリケーションにプライベートに接続できます。 詳細については、「Private Link を使用して Azure Front Door Premium を配信元に接続する」を参照してください。
送信接続
AKS でホストされたアプリケーションが多数のデータベースや外部サービスに接続する場合、そのクラスターは SNAT ポート不足の危険にさらされることがあります。 SNAT ポートでは、同じコンピューティング リソースのセットで実行されるアプリケーションによって開始された個別のフローを維持するために使用される一意の識別子が生成されます。 共有された Azure Kubernetes Service (AKS) クラスターで複数のテナント アプリケーションを実行すると、多数の送信呼び出しが行われる可能性があり、SNAT ポートが枯渇する可能性があります。 AKS クラスターは、次の 3 つの方法で送信接続を処理できます。
- Azure Public Load Balance: 既定では、AKS は、エグレス接続用に設定および使用される Standard SKU Load Balancerをプロビジョニングします。 ただし、パブリック IP が許可されていない場合、またはエグレスに追加のホップが必要な場合、既定の設定ではすべてのシナリオの要件を満たせない可能性があります。 既定では、パブリック ロード バランサーは、 アウトバウンド規則で使用される既定のパブリック IP アドレスで作成されます。 アウトバウンド規則を使用すると、パブリック標準ロード バランサーの送信元ネットワーク アドレス変換 (SNAT) を明示的に定義できます。 この構成では、ロード バランサーのパブリック IP を使用して、バックエンド インスタンスに対して送信インターネット接続を提供できます。 必要に応じて、 SNAT ポートの枯渇を回避するために、追加のパブリック IP アドレスを使用するようにパブリック ロード バランサーのアウトバウンド規則を構成できます。 「送信規則による送信には、ロード バランサーのフロントエンド IP アドレスが使用される」を参照してください。
- Azure NAT Gateway: Azure NAT ゲートウェイを使用してテナント アプリケーションからのエグレス トラフィックをルーティングするように AKS クラスターを構成できます。 NAT Gateway ではパブリック IP アドレスあたり最大で 64,512 個の送信 UDP および TCP トラフィック フローが許容され、最大で 16 個の IP アドレスを使用できます。 NAT Gateway を使用して AKS クラスターからの送信接続を処理するときに SNAT ポートが枯渇するリスクを回避するには、より多くのパブリック IP アドレスまたは パブリック IP アドレス プレフィックス をゲートウェイに関連付けることができます。 詳細については、「マルチテナント機能に関する Azure NAT Gateway の考慮事項」を参照してください。
- ユーザー定義ルート (UDR): AKS クラスターのエグレス ルートをカスタマイズして、パブリック IP を禁止し、クラスターをネットワーク仮想アプライアンス (NVA) の背後に配置することを必須にするなどのカスタム ネットワーク シナリオをサポートすることができます。 ユーザー定義ルーティング用にクラスターを構成する場合、AKS ではエグレス パスが自動的に構成されません。 エグレス セットアップは、ユーザーが行う必要があります。 たとえば、エグレス トラフィックを Azure Firewall 経由でルーティングします。 AKS クラスターは、以前構成済みのサブネットがある既存の仮想ネットワークにデプロイする必要があります。 Standard ロード バランサー (SLB) アーキテクチャを使用しない場合は、明示的なエグレスを確立する必要があります。 そのため、このアーキテクチャでは、ファイアウォール、ゲートウェイ、プロキシなどのアプライアンスにエグレス トラフィックを明示的に送信する必要があります。 または、このアーキテクチャを使用すると、ネットワーク アドレス変換 (NAT) を、標準のロード バランサーまたはアプライアンスに割り当てられているパブリック IP によって実行できます。
監視
Azure Monitor と Container Insights を使用して、共有 AKS クラスターで実行されるテナント アプリケーションを監視し、個々の名前空間のコスト内訳を計算できます。 Azure Monitor を使用すると、Azure Kubernetes Service (AKS) の正常性とパフォーマンスを監視できます。 これには、傾向を識別して重大な問題を予防的に通知するアラートを構成するために、 ログとメトリック、テレメトリ分析、収集されたデータの視覚化のコレクションが含まれます。 コンテナーの分析情報 を有効にして、この監視を広げることができます。
また、Kubernetes 監視のためにコミュニティによって広く使用されている Prometheus や Grafana などのオープンソース ツールを採用することもできます。 または、監視のための他のサードパーティ製ツールを採用することもできます。
コスト
コスト ガバナンスは、コストを管理するためのポリシーを実装する継続的なプロセスです。 Kubernetes のコンテキストでは、組織がコストを管理および最適化できるいくつかの方法が存在します。 これには、リソースの使用状況や消費を管理および制御し、基になるインフラストラクチャを予防的に監視および最適化するためのネイティブな Kubernetes ツールが含まれます。 テナントごとのコストを計算するときは、テナント アプリケーションによって使用されるすべてのリソースに関連するコストを考慮する必要があります。 テナントに料金を請求するために従う方法は、ソリューションで採用されているテナント モデルによって異なります。 詳細について、次のテナント モデルを使用して説明します。
- 完全マルチテナント: 1 つのマルチテナント アプリケーションですべてのテナント要求を処理する場合は、リソースの消費量と、各テナントによって生成された要求番号を追跡する必要があります。 その後、それに応じて顧客に請求します。
- 専用クラスター: クラスターが 1 つのテナント専用の場合、Azure リソースのコストを顧客に請求することは簡単です。 総保有コストは多くの要因によって左右され、これには仮想マシンの数とサイズ、ネットワーク トラフィックに起因するネットワーク コスト、パブリック IP アドレス、ロード バランサー、テナント ソリューションで使用されるマネージド ディスクや Azure ファイルなどのストレージ サービスなどが含まれます。 コスト課金操作を容易にするために、ノード リソース グループ内の AKS クラスターとそのリソースにタグを付けることができます。 詳細については、「クラスターにタグを追加する」を参照してください。
- 専用ノード プール: 1 つのテナント専用の新規または既存のノード プールに Azure タグを適用できます。 ノード プールに適用されるタグは、ノード プール内の各ノードに適用され、アップグレードによって保持されます。 また、スケールアウト操作中にノード プールに追加される新しいノードにもタグが適用されます。 タグを追加すると、ポリシーの追跡やコスト見積もりなどのタスクに役立ちます。 詳細については、「ノード プールにタグを追加する」を参照してください。
- その他のリソース: タグを使用して、特定のテナントに専用リソースのコストを関連付けることができます。 特に、Kubernetes マニフェストを使用して、パブリック IP、ファイル、ディスクにタグを付けることができます。 この方法でタグを設定すると、後で別の方法を使用してこれらを更新した場合でも、Kubernetes 値は維持されます。 パブリック IP、ファイル、またはディスクが Kubernetes を介して削除されると、Kubernetes によって設定されたタグはすべて削除されます。 Kubernetes によって追跡されていないそれらのリソース上のタグは影響を受けません。 詳細については、「Kubernetes を使用してタグを追加する」を参照してください。
KubeCost などのオープンソース ツールを使用して、AKS クラスターのコストを監視および管理できます。 コストの割り当ては、デプロイ、サービス、ラベル、ポッド、および名前空間にスコープを設定できるため、クラスターのユーザーに柔軟にチャージバックまたはショーバックすることができます。 詳細については、「Kubecost を使用したコスト ガバナンス」を参照してください。
マルチテナント アプリケーションのコストの測定、割り当て、最適化の詳細については、「マルチテナント ソリューションでのコスト管理と割り当てのアーキテクチャ アプローチ」を参照してください。 コストの最適化に関する一般的なガイダンスについては、Azure Well-Architected フレームワークの記事「コストの最適化の柱の概要」を参照してください
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Paolo Salvator | FastTrack for Azure のプリンシパル カスタマー エンジニア
その他の共同作成者:
- John Downs | プリンシパル ソフトウェア エンジニア
- Ed Price | シニア コンテンツ プログラム マネージャー
- Arsen Vladimirskiy | FastTrack for Azure のプリンシパル カスタマー エンジニア
- Bohdan Cherchyk | FastTrack for Azure のシニア カスタマー エンジニア
次のステップ
「マルチテナント ソリューションの設計者と開発者向けのリソース」を確認します。