ソリューションのアイデア
この記事ではソリューションのアイデアについて説明します。 クラウド アーキテクトはこのガイダンスを使用すると、このアーキテクチャの一般的な実装の主要コンポーネントを視覚化しやすくなります。 ワークロードの特定の要件に適合する、適切に設計されたソリューションを設計するための出発点として、この記事を使用してください。
この例では、抽出、読み込み、変換 (ELT) パイプラインで増分読み込みを実行する方法を示しています。 Azure Data Factory を使用して ELT パイプラインを自動化します。 パイプラインは、オンプレミスの SQL Server データベースから Azure Synapse に最新の OLTP データを段階的に移動します。 トランザクション データは、分析のために表形式モデルに変換されます。
アーキテクチャ

このアーキテクチャの Visio ファイルをダウンロードします。
このアーキテクチャは、Azure Synapse を使用するエンタープライズ BI に示されているアーキテクチャに基づいて構築されていますが、エンタープライズ データ ウェアハウス シナリオに重要な機能がいくつか追加されています。
- Data Factory を使用したパイプラインの自動化
- 段階的な読み込み。
- 複数のデータ ソースの統合。
- 地理空間データや画像などのバイナリ データの読み込み。
ワークフロー
このアーキテクチャは、次のサービスとコンポーネントで構成されています。
データ ソース
オンプレミスの SQL Server。 ソース データは、オンプレミスの SQL Server データベースにあります。 オンプレミス環境をシミュレートします。 Wide World Importers OLTP サンプル データベースは、ソース データベースとして使用されます。
外部データ。 データ ウェアハウスの一般的なシナリオとして、複数のデータ ソースの統合があります。 この参照アーキテクチャは、年別の市区町村の人口を含む外部データ セットを読み込み、それを OLTP データベースのデータと統合します。 このデータは、"各地域の売上高の増加率は人口の増加率と一致するか、上回っているか" のような分析に使用できます。
インジェストとデータ ストレージ
Blob Storage。 Azure Synapse に読み込む前のソース データのステージング領域として、Blob Storage が使用されます。
Azure Synapse。 Azure Synapse は、大規模なデータの分析を目的として設計された分散システムです。 超並列処理 (MPP) がサポートされているので、ハイパフォーマンス分析の実行に適しています。
Azure Data Factory。 Data Factory は、データ移動とデータ変換を調整し、自動化するマネージド サービスです。 このアーキテクチャでは、ELT プロセスのさまざまな段階が調整されます。
分析とレポート
Azure Analysis Services。 Analysis Services は、データ モデリング機能を提供するフル マネージド サービスです。 セマンティック モデルは Analysis Services に読み込まれます。
Power BI。 Power BI は、データを分析してビジネスの分析情報を得る一連のビジネス分析ツールです。 このアーキテクチャでは、Analysis Services に格納されたセマンティック モデルに対してクエリが実行されます。
認証
Microsoft Entra ID では、Power BI から Analysis Services サーバーに接続するユーザーの認証が行われます。
Data Factory では、Microsoft Entra ID を使い、サービス プリンシパルまたは管理サービス ID (MSI) を使って Azure Synapse に対する認証を行うこともできます。
コンポーネント
- Azure Blob Storage
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
シナリオの詳細
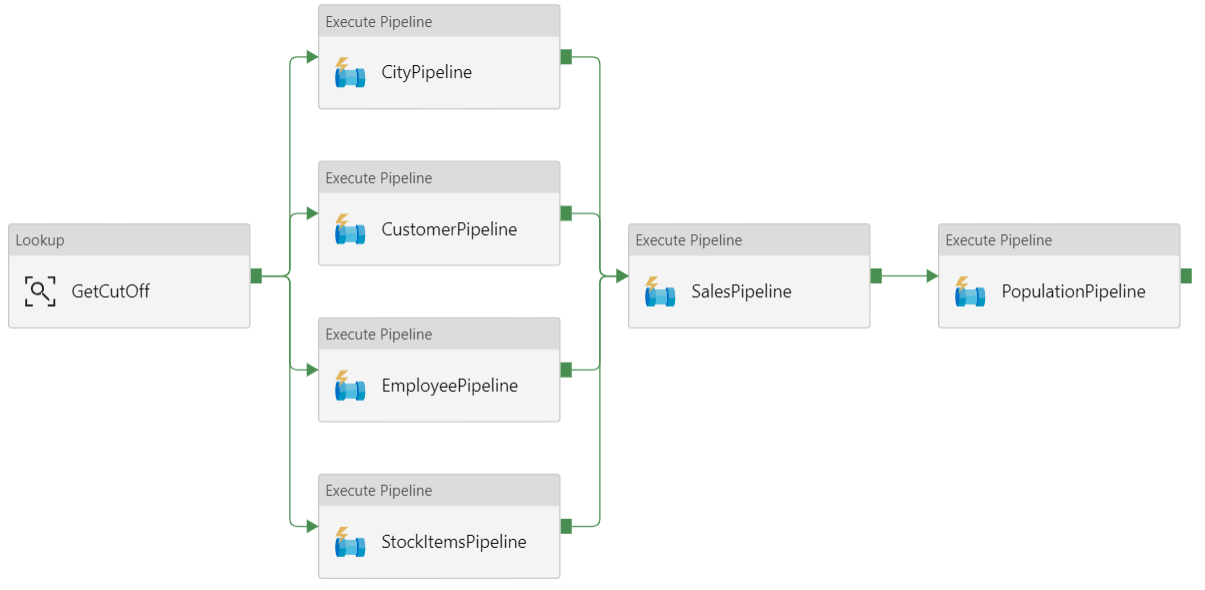
データ パイプライン
Azure Data Factory では、パイプラインはタスク (この例では、データを Azure Synapse に読み込んで変換するタスク) の調整に使用されるアクティビティの論理グループです。
この参照アーキテクチャでは、一連の子パイプラインを実行する親パイプラインを定義します。 各子パイプラインは、1 つまたは複数のデータ ウェアハウス テーブルにデータを読み込みます。
Recommendations
段階的な読み込み
自動化された ETL または ELT プロセスを実行する場合、以前の実行以降に変更されたデータのみを読み込むのが最も効率的です。 すべてのデータを読み込む完全読み込みとは対照的に、これは段階的な読み込みと呼ばれます。 段階的な読み込みを実行するには、変更されたデータを特定する方法が必要です。 最も一般的な方法は、高基準値を使用することです。つまり、ソース テーブルの特定の列の最新の値 (日時列または一意の整数列) を追跡することです。
SQL Server 2016 以降はテンポラル テーブルを使用できます。 テンポラル テーブルは、データの完全な変更履歴が保持されている、システムでバージョン管理されたテーブルです。 データベース エンジンは、各変更履歴を別々の履歴テーブルに自動的に記録します。 クエリに FOR SYSTEM_TIME 句を追加することで、履歴データのクエリを実行することができます。 内部的には、データベース エンジンは履歴テーブルのクエリを実行しますが、この処理はアプリケーションにとって透過的です。
注意
以前のバージョンの SQL Server では、変更データ キャプチャ (CDC) を使用できます。 このアプローチでは、別の変更テーブルのクエリを実行する必要があり、変更がタイムスタンプではなくログ シーケンス番号で追跡されるため、テンポラル テーブルよりも不便です。
テンポラル テーブルは、時間と共に変化する可能性のあるディメンション データの場合に便利です。 通常、ファクト テーブルは、販売などの不変トランザクションを表します。この場合、システムのバージョン履歴を保持することは意味がありません。 その代わり、通常、トランザクションにはトランザクション日付を表す列があります。これをウォーターマーク値として使用できます。 たとえば、Wide World Importers OLTP データベースでは、Sales.Invoices テーブルと Sales.InvoiceLines テーブルに既定が LastEditedWhen の sysdatetime() フィールドがあります。
ELT パイプラインの一般的なフローは次のとおりです。
ソース データベースの各テーブルについて、最後の ELT ジョブが実行されたときのカットオフ時間を追跡します。 この情報をデータ ウェアハウスに格納します (初期設定では、すべての時間が '1-1-1900'に設定されます)。
データのエクスポート手順では、カットオフ時間がパラメーターとしてソース データベース内のストアド プロシージャのセットに渡されます。 これらのストアド プロシージャは、カットオフ時間後に変更または作成されたレコードのクエリを実行します。 Sales ファクト テーブルの場合は、
LastEditedWhen列が使用されます。 ディメンション データの場合は、システムでバージョン管理されたテンポラル テーブルが使用されます。データの移行が完了したら、カットオフ時間を格納するテーブルを更新します。
ELT の実行ごとに系列を記録することも便利です。 特定のレコードについて、系列はそのレコードをそのデータを生成した ELT 実行と関連付けます。 ETL 実行ごとに、読み込みの開始時刻と終了時刻が表示された新しい系列レコードがテーブルごとに作成されます。 各レコードの系列キーは、ディメンション テーブルとファクト テーブルに格納されます。
新しいデータのバッチがウェアハウスに読み込まれたら、Analysis Services 表形式モデルを更新します。 「REST API を使用した非同期更新」を参照してください。
データ クレンジング
データ クレンジングは、ELT プロセスに含めるようにします。 この参照アーキテクチャでは、不適切なデータ ソースの 1 つが市区町村の人口テーブルです。このテーブルには、データを入手できなかったなどの理由で、人口が 0 の市区町村がいくつかあります。 処理中、ELT パイプラインは、市区町村の人口テーブルからそれらの市区町村を削除します。 外部テーブルではなくステージング テーブルにタイしてデータ クレンジングを実行します。
外部データ ソース
データ ウェアハウスは、多くの場合、複数のソースのデータを統合します。 この例は、人口統計データを含む外部データ ソースです。 このデータセットは、WorldWideImportersDW サンプルの一部として AzureBlob Storage で利用できます。
Azure Data Factory は、BLOB ストレージ コネクタを使用して、BLOB ストレージから直接コピーできます。 ただし、コネクタには接続文字列または共有アクセス署名が必要なため、パブリック読み取りアクセス権がある BLOB のコピーに使用することはできません。 回避策として、PolyBase を使用して BLOB ストレージ上に外部テーブルを作成し、外部テーブルを Azure Synapse にコピーすることができます。
大きなバイナリ データの処理
たとえば、ソース データベースでは、City テーブルに geography 空間データ型を保持する Location 列があります。 Azure Synapse では geography 型はネイティブでサポートされていないため、このフィールドは読み込み中に varbinary 型に変換されます。 (「サポートされていないデータ型の対処法」を参照してください)。
ただし、PolyBase でサポートされる最大列サイズは varbinary(8000) です。そのため、一部のデータが切り捨てられる可能性があります。 この問題の回避策は、次のようにエクスポート時にデータをチャンクに分割し、チャンクを再構成することです。
Location 列の一時ステージング テーブルを作成します。
市区町村ごとに場所データを 8,000 バイトのチャンクに分割します。その結果、市区町村ごとに 1 - N 行になります。
チャンクを再構成するには、T-SQL PIVOT 演算子を使用して行を列に変換し、各市区町村の列の値を連結します。
課題は、地理データのサイズに応じて、各市区町村を異なる数の行に分割することです。 PIVOT 演算子が機能するには、各市区町村を同じ行数にする必要があります。 これを機能させるには、PIVOT の後にすべての市区町村が同じ列数になるように、T-SQL クエリで行を空白値で埋める処理を実行します。 結果のクエリは、一度に 1 行ずつループするよりもはるかに高速になっていることがわかります。
同じアプローチが画像データに使用されます。
緩やかに変化するディメンション
ディメンション データは比較的静的ですが、変化する可能性があります。 たとえば、製品が別の製品カテゴリに再割り当てされることがあります。 緩やかに変化するディメンションを処理するにはいくつかのアプローチがあります。 タイプ 2 と呼ばれる一般的な手法では、ディメンションが変化するたびに新しいレコードを追加します。
タイプ 2 アプローチを実装するには、特定のレコードの有効な日付範囲を指定する列をディメンション テーブルに追加する必要があります。 また、ソース データベースの主キーが複製されるので、ディメンション テーブルには人工主キーが必要です。
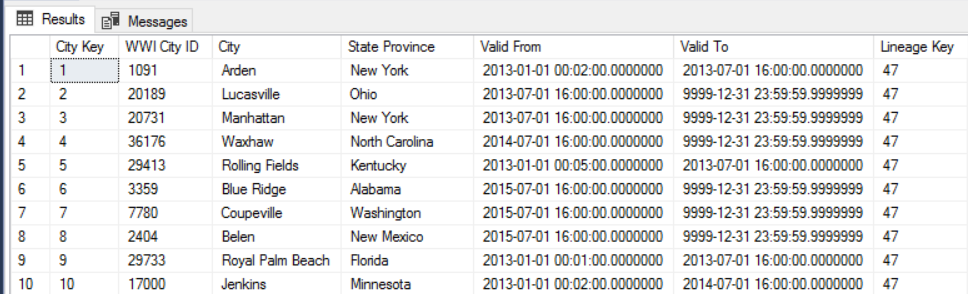
たとえば、次の画像は Dimension.City テーブルを示しています。
WWI City ID 列は、ソース データベースの主キーです。
City Key 列は、ETL パイプラインで生成された人工キーです。 また、テーブルには Valid From 列と Valid To 列があり、各行が有効なときの範囲が定義されています。 現在の値には Valid To = '9999-12-31' があります。
このアプローチの利点は、過去のデータが保存されることです。このデータは分析に役立つ可能性があります。 ただし、これは同じエンティティに対して複数の行が存在することも意味します。 たとえば、WWI City ID = 28561 に一致するレコードを次に示します。
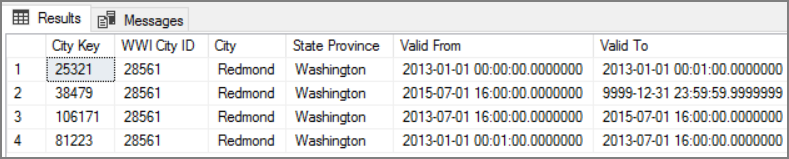
各 Sales ファクトについて、そのファクトを請求書の日付に対応する City ディメンション テーブルの単一の行に関連付ける必要があります。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティ
さらにセキュリティを強化するには、仮想ネットワーク サービス エンドポイントを使用して、仮想ネットワークに対してのみ Azure サービス リソースをセキュリティで保護することができます。 これにより、これらのリソースに対するパブリック インターネット アクセスが完全に削除され、自分の仮想ネットワークからのトラフィックのみが許可されます。
このアプローチでは、Azure 内に VNet を作成し、Azure サービス用のプライベート サービス エンドポイントを作成します。 これらのサービスは、その仮想ネットワークからのトラフィックに制限されるようになります。 オンプレミス ネットワークからゲートウェイ経由でアクセスすることもできます。
次の制限事項に注意してください。
Azure Storage でサービス エンドポイントが有効な場合、PolyBase は Storage から Azure Synapse にデータをコピーできません。 この問題には軽減策があります。 詳細については、「Azure Storage で VNet サービス エンドポイントを使用した場合の影響」を参照してください。
オンプレミスから Azure Storage にデータを移動するには、オンプレミスまたは ExpressRoute からのパブリック IP アドレスを許可する必要があります。 詳細については、「Azure サービスへのアクセスを仮想ネットワークに限定する」を参照してください。
Analysis Services で Azure Synapse からデータを読み取ることができるようにするには、Azure Synapse サービス エンドポイントを含む仮想ネットワークに Windows VM を展開します。 この VM に Azure オンプレミス データゲートウェイをインストールします。 次に Azure Analysis サービスをデータ ゲートウェイに接続します。
コストの最適化
コストの最適化は、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳細については、「コストの最適化
コストの見積もりには、Azure 料金計算ツール をご利用ください。 ここでは、この参照アーキテクチャで使用されるサービスに関するいくつかの考慮事項を示します。
Azure Data Factory
Azure Data Factory によって ELT パイプラインが自動化されます。 パイプラインでは、オンプレミスの SQL Server データベースから Azure Synapse にデータが移動されます。 次に、データは分析のために表形式モデルに変換されます。 このシナリオの場合、価格設定はアクティビティ、トリガー、およびデバッグの実行を含む月額 $0.001 のアクティビティの実行から始まります。 その価格は、オーケストレーションに対してのみの基本料金です。 また、データのコピー、参照、外部アクティビティなど、実行アクティビティに対しても課金されます。 各アクティビティの価格は、個別に設定されます。 また、その月内に関連付けられているトリガーや実行がないパイプラインに対しても、課金されます。 すべてのアクティビティが分単位で比例配分されて、切り上げられます。
コスト分析の例
異なる 2 つのソースからの 2 つの参照アクティビティがあるユース ケースについて考えてみます。 1 つのアクティビティには 1 分 2 秒 (2 分に切り上げ) かかり、もう 1 つには 1 分かかるため、合計時間は 3 分になります。 1 つのデータ コピー アクティビティには 10 分かかります。 1 つのストアド プロシージャ アクティビティには 2 分かかります。 アクテビティの実行には、合計で 4 分かかります。 コストは、次のように算出されます。
アクティビティの実行:4 * $0.001 = $0.004
参照:3 * ($0.005 / 60) = $0.00025
ストアド プロシージャ:2 * ($0.00025 / 60) = $0.000008
データのコピー:10 * ($0.25 / 60) * 4 データ統合ユニット (DIU) = $0.167
- パイプラインの実行あたりの総コスト: $0.17。
- 1 日 1 回 30 日間の実行: 月額 $5.1。
- 100 テーブルごとに 1 日 1 回 30 日間の実行: $510
どのアクティビティにも、関連するコストが生じます。 価格モデルを把握し、ADF 料金計算ツールを使用して、パフォーマンスだけでなくコストにおいても最適化されたソリューションを実現します。 サービスの開始、停止、一時停止、およびスケーリングによってコストを管理します。
Azure Synapse
Azure Synapse は、高いクエリ パフォーマンスとコンピューティングにおけるスケーラビリティを必要とする集中型のワークロードに最適です。 従量課金制モデルを選択することも、1 年間 (37% の節約) または 3 年間 (65% の節約) の予約済みプランを使用することもできます。
データ ストレージは、別途請求されます。 ディザスター リカバリーや脅威検出などの他のサービスについても、別途請求されます。
詳細については、Azure Synapse の価格に関するページを参照してください。
Analysis Services
Azure Analysis Services の価格は、レベルによって異なります。 このアーキテクチャのリファレンス実装では、Developer レベルを使用します。これは、評価、開発、テストのシナリオで推奨されます。 その他のレベルとしては、小規模な運用環境に推奨される Basic レベル、ミッション クリティカルな実稼働アプリケーション用の Standard レベルがあります。 詳細については、「必要に応じたレベルを選ぶ」を参照してください。
インスタンスを一時停止した場合、料金は適用されません。
詳しくは、「Azure Analysis Services の価格」をご覧ください。
Blob Storage
ストレージのコストを削減するには、Azure Storage の予約容量機能を使用することを検討してください。 このモデルでは、1 または 3 年間固定のストレージ容量の予約を確約できる場合に割引が適用されます。 詳しくは、「予約容量を使用して BLOB ストレージのコストを最適化する」を参照してください。
詳細については、「Microsoft Azure Well-Architected Framework」のコストのセクションを参照してください。
オペレーショナル エクセレンス
オペレーショナル エクセレンスは、アプリケーションをデプロイし、運用環境で実行し続ける運用プロセスを対象としています。 詳細については、「オペレーショナル エクセレンス
運用、開発、およびテスト環境それぞれに対して個別のリソース グループを作成してください。 個別のリソース グループにより、デプロイの管理、テスト デプロイの削除、およびアクセス権の割り当てが行いやすくなります。
各ワークロードを別々のデプロイ テンプレートに配置し、リソースをソース管理システムに格納します。 テンプレートは一緒にデプロイすることも、CI/CD プロセスの一環として個別にデプロイすることもできるため、自動化プロセスが簡単になります。
このアーキテクチャには、主に次の 3 つのワークロードがあります。
- データ ウェアハウス サーバー、Analysis Services、および関連リソース。
- Azure Data Factory。
- オンプレミスからクラウドへのシミュレートされたシナリオ。
各ワークロードには、独自のデプロイ テンプレートがあります。
データ ウェアハウス サーバーは、IaC プラクティスの命令型の手法に従う Azure CLI コマンドを使用して、設定および構成されます。 デプロイ スクリプトを使用し、それらをオートメーション プロセスに統合することを検討してください。
ワークロードをステージングすることを検討してください。 さまざまなステージにデプロイし、各ステージで検証チェックを実行してから、次のステージに進みます。 これにより、高度に制御された方法で運用環境に更新プログラムをプッシュし、予期しないデプロイの問題を最小限に抑えることができます。 アクティブな運用環境を更新するために、ブルーグリーン デプロイとカナリア リリースの戦略を使用してください。
失敗したデプロイを処理するための、適切なロールバック戦略を用意します。 たとえば、デプロイ履歴から以前に成功したデプロイを自動的に再デプロイすることができます。 Azure CLI の --rollback-on-error フラグ パラメーターを参照してください。
Azure Monitor は、統合された監視エクスペリエンスを実現するために、データ ウェアハウスと Azure 分析プラットフォーム全体のパフォーマンスを分析するための、推奨されるオプションです。 Azure Synapse Analytics を使うと、Azure portal 内で監視エクスペリエンスが提供され、データ ウェアハウスのワークロードに関する分析情報が表示されます。 Azure portal は、データ ウェアハウスを監視する場合に推奨されるツールです。構成可能なリテンション期間、アラート、推奨事項、およびメトリックとログのカスタマイズ可能なグラフとダッシュボードが用意されているためです。
次のステップ
- Azure Synapse Analytics の概要
- Azure Synapse Analytics の使用を開始する
- Azure Data Factory の概要
- Azure Data Factory とは
- Azure Data Factory のチュートリアル
関連リソース
同じテクノロジの一部を使用する具体的なソリューションを示す次の Azure のサンプル シナリオをレビューできます。