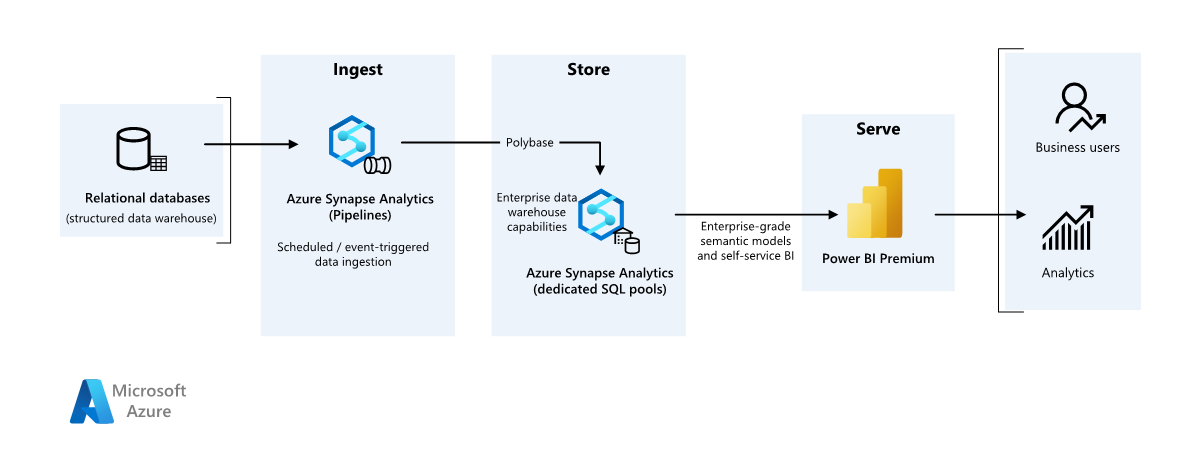
このシナリオ例は、オンプレミスのデータ ウェアハウスからクラウド環境にデータを取り込み、ビジネス インテリジェンス (BI) モデルを使って提供する方法を示しています。 このアプローチは、クラウドベースのコンポーネントを使った完全なモダン化に向けて、最終目標または最初の手順にすることができます。
次の手順は、Azure Synapse Analytics のエンドツーエンド シナリオに基づいています。 Azure Pipelines を使って SQL データベースから Azure Synapse SQL プールにデータを取り込み、分析のためにデータを変換します。
アーキテクチャ

このアーキテクチャの Visio ファイルをダウンロードします。
ワークフロー
データ ソース
- ソース データは、Azure の SQL Server データベース内にあります。 オンプレミス環境をシミュレートするために、このシナリオのデプロイ スクリプトでは Azure SQL データベースをプロビジョニングしています。 AdventureWorks サンプル データベースをソース データ スキーマとサンプル データとして使います。 オンプレミス データベースからデータをコピーする方法については、「データを SQL Server 間でコピー、および変換する」を参照してください。
インジェストとデータ ストレージ
Azure Data Lake Gen2 は、データ インジェスト時に一時的な "ステージング" 領域として使われます。 その後、PolyBase を使って Azure Synapse 専用 SQL プールにデータをコピーできます。
Azure Synapse Analytics は、大規模なデータの分析を目的として設計された分散システムです。 超並列処理 (MPP) がサポートされているので、ハイパフォーマンス分析の実行に適しています。 Azure Synapse 専用 SQL プールは、オンプレミスから継続的に取り込まれる対象です。 DirectQuery を介して Power BI にデータを提供するだけでなく、その後のプロセスに使用できます。
Azure Pipelines は、Azure Synapse ワークスペース内でデータ インジェストと変換を調整するために使われます。
分析とレポート
- このシナリオでは、エンタープライズ モデルと BI セマンティック モデルを組み合わせたデータ モデル化アプローチが提示されます。 エンタープライズ モデルは Azure Synapse 専用 SQL プールに格納され、BI セマンティック モデルは Power BI Premium 容量に格納されます。 Power BI からデータには DirectQuery 経由でアクセスします。
コンポーネント
このシナリオでは、次のコンポーネントを使用します。
簡略化されたアーキテクチャ
シナリオの詳細
ある組織が、SQL データベースに格納された大規模なオンプレミス データ ウェアハウスを持っています。 この組織では、Azure Synapse を使って分析を行い、その分析情報を Power BI を使って提供したいと考えています。
認証
Power BI ダッシュボードとアプリに接続するユーザーは Microsoft Entra の認証を受けます。 Azure Synapse プロビジョニング プールのデータソースに接続するためにシングル サインオンが使われます。 認可はソースに対して行われます。
段階的な読み込み
自動 Extract/Transform/Load (ETL) または Extract/Load/Transform (ELT) プロセスを実行する場合、前回の実行以降に変更されたデータのみを読み込むのが最も効率的です。 すべてのデータを読み込む完全読み込みとは対照的に、これは段階的な読み込みと呼ばれます。 段階的な読み込みを実行するには、変更されたデータを特定する方法が必要です。 最も一般的な方法は、"高基準値" を使用することです。これにより、ソース テーブルの特定の列の最新の値 (日時列または一意の整数列) を追跡します。
SQL Server 2016 以降はテンポラル テーブルを使用できます。これは、データ変更の完全な履歴を保持するシステムバージョン管理テーブルです。 データベース エンジンは、各変更履歴を別々の履歴テーブルに自動的に記録します。 クエリに FOR SYSTEM_TIME 句を追加することで、履歴データのクエリを実行することができます。 内部的には、データベース エンジンは履歴テーブルのクエリを実行しますが、この処理はアプリケーションにとって透過的です。
Note
以前のバージョンの SQL Server では、変更データ キャプチャ (CDC) を使用できます。 このアプローチでは、別の変更テーブルのクエリを実行する必要があり、変更がタイムスタンプではなくログ シーケンス番号で追跡されるため、テンポラル テーブルよりも不便です。
テンポラル テーブルは、時間と共に変化する可能性のあるディメンション データの場合に便利です。 通常、ファクト テーブルは、販売などの不変トランザクションを表します。この場合、システムのバージョン履歴を保持することは意味がありません。 その代わり、通常、トランザクションにはトランザクション日付を表す列があります。これをウォーターマーク値として使用できます。 たとえば、AdventureWorks Data Warehouse では、SalesLT.* テーブルに LastModified フィールドがあります。
ELT パイプラインの一般的なフローは次のとおりです。
ソース データベースの各テーブルについて、最後の ELT ジョブが実行されたときのカットオフ時間を追跡します。 この情報をデータ ウェアハウスに格納します 初期設定では、すべての時間が
1-1-1900に設定されます。データのエクスポート手順では、カットオフ時間がパラメーターとしてソース データベース内のストアド プロシージャのセットに渡されます。 これらのストアド プロシージャは、カットオフ時間後に変更または作成されたレコードのクエリを実行します。 例のすべてのテーブルには
ModifiedDate列を使用できます。データの移行が完了したら、カットオフ時間を格納するテーブルを更新します。
データ パイプライン
このシナリオでは、データソースとして AdventureWorks サンプル データベースを使います。 直近のパイプライン実行後に変更または追加されたデータのみを読み込むように、増分データ読み込みパターンが実装されています。
メタデータ駆動型のコピー ツール
Azure Pipelines に組み込まれているメタデータ駆動型コピー ツールには、リレーショナル データベースに含まれるすべてのテーブルの増分読み込み機能があります。 ウィザードベースのエクスペリエンスを使って操作して、コピー データ ツールをソース データベースに接続し、各テーブルに対して増分または完全な読み込みのいずれかを構成できます。 そうすると、コピー データ ツールによって、パイプラインと SQL スクリプトの両方が作成され、増分読み込みプロセスのデータ (たとえば各テーブルの高基準値または列) を格納するために必要なコントロール テーブルが生成されます。 これらのスクリプトを実行すると、パイプラインはソース データ ウェアハウス内の全テーブルを Synapse 専用プールに読み込む準備が整います。
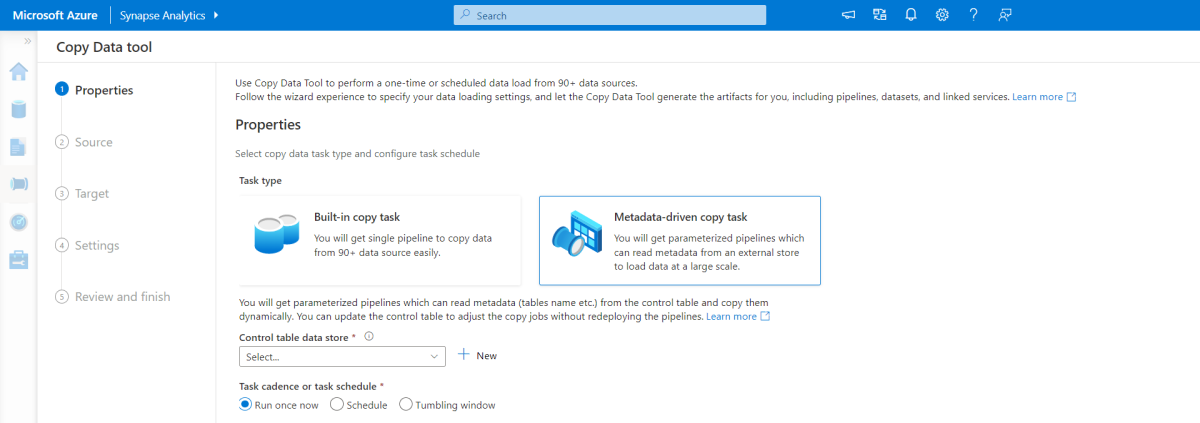
このツールを使うと、データを読み込む前に、データベース内のすべてのテーブルを反復処理する 3 つのパイプラインを作成できます。
このツールで生成されるパイプラインは次のとおりです。
- パイプラインの実行でコピーされるテーブルなどのオブジェクト数をカウントします。
- 読み込まれる、またはコピーされる各オブジェクトを反復処理してから、次のことを行います。
- 差分読み込みが必要かどうかを確認し、そうでなければ通常の完全な読み込みを完了します。
- コントロール テーブルから高基準値を取得します。
- ソース テーブルから Data Lake Storage Gen2 のステージング アカウントにデータをコピーします。
- 選んだコピー方法 (たとえば PolyBase、Copy コマンド) で、データを専用 SQL プールに読み込みます。
- コントロール テーブルの高基準値を更新します。
Azure Synapse SQL プールにデータを読み込む
コピー アクティビティにより、SQL データベースから Azure Synapse SQL プールにデータをコピーします。 この例では、SQL データベースが Azure 内にあるため、Azure 統合ランタイムを使って SQL データベースからデータを読み取り、指定したステージング環境にデータを書き込んでいます。
その後、コピー ステートメントを使って、ステージング環境から Synapse 専用プールにデータを読み込みます。
Azure Pipelines を使用する
Azure Synapse のパイプラインは、増分読み込みパターンを完了する順序が指定されたアクティビティ セットを定義するために使われます。 パイプラインを開始するにはトリガーを使います。手動または指定した時間にトリガーすることができます。
データの変換
参照アーキテクチャのサンプル データベースはそれほど大きくないため、パーティションのないレプリケート テーブルを作成しました。 運用ワークロードでは、分散テーブルを使用すると、クエリ パフォーマンスが向上する可能性があります。 詳細については、「Azure Synapse での分散テーブルの設計に関するガイダンス」をご覧ください。 このサンプル スクリプトでは、静的リソース クラスを使ってクエリを実行しています。
運用環境では、ラウンドロビン分散を使ってステージング テーブルを作成することを検討してください。 その後、データを変換して、クラスター化列ストア インデックスを設定した運用テーブルに移行します。これにより、全体として最適なクエリ パフォーマンスを実現できます。 列ストア インデックスは、多数のレコードをスキャンするクエリに最適化されています。 列ストア インデックスは、シングルトンのルックアップ (つまり、単一行の検索) には適していません。 単一ルックアップを頻繁に実行する必要がある場合は、テーブルに非クラスター化インデックスを追加できます。 非クラスター化インデックスを使用すると、単一ルックアップの実行を大幅に高速化できます。 ただし、データ ウェアハウス シナリオでは、通常、単一ルックアップは OLTP ワークロードほど一般的ではありません。 詳細については、「Azure Synapse でのテーブルのインデックス作成」をご覧ください。
Note
クラスター化列ストア テーブルでは、varchar(max)、nvarchar(max)、varbinary(max) の各データ型はサポートしていません。 その場合、ヒープ インデックスまたはクラスター化インデックスを検討してください。 それらの列を別のテーブルに配置できます。
Power BI Premium を使ったデータのアクセス、モデル化、視覚化
Power BI Premium は、Azure 上のデータ ソース、特に Azure Synapse プロビジョニング プールに接続するためのいくつかのオプションをサポートしています。
- インポート: データは Power BI モデルにインポートされます。
- DirectQuery: データはリレーショナル ストレージから直接プルされます。
- 複合モデル: 一部のテーブルには "インポート" を、他のものには DirectQuery を組み合わせて使います。
このシナリオは使うデータ量やモデルの複雑さが高くないため、DirectQuery ダッシュボードを使って実現できます。そのため、優れたユーザー エクスペリエンスを提供できます。 クエリは DirectQuery からその下にある強力なコンピューティング エンジンに委任され、ソースに対して広範なセキュリティ機能が利用されます。 また、DirectQuery を使用すると、結果を最新のソース データと常に一致させることができます。
インポート モードはクエリ応答時間が最速です。これは、モデルが Power BI のメモリ内に完全に収まり、更新間のデータ待機時間が許容範囲であり、ソース システムと最終モデルの間に複雑な変換が存在する可能性がある場合に検討することをお勧めします。 このケースでは、エンド ユーザーは、Power BI 更新時の最新データ (遅延なし) とすべての履歴データに完全にアクセスできることを希望しています。これは Power BI データセットで処理できる容量よりも大きくなります (容量のサイズに応じて 25 から 400 GB)。 専用 SQL プールのデータ モデルは既にスター スキーマであり、変換の必要がないため、DirectQuery が適切な選択です。
Power BI Premium Gen2 では、大規模モデル、ページ分割されたレポート、デプロイ パイプライン、組み込みの Analysis Services エンドポイントを処理できます。 また、独自の価値提案を備えた専用の容量を持つこともできます。
BI モデルが大きくなった場合、またはダッシュボードが複雑になった場合は、複合モデルに切り替え、ハイブリッド テーブルや何らかの事前集計データを使って、ルックアップ テーブルの一部のインポートを始めることができます。 インポートしたデータセットに対して Power BI 内でクエリ キャッシュを有効にすることや、ストレージ モードのプロパティにデュアル テーブルを利用することができます。
複合モデル内では、データセットは仮想的なパススルー レイヤーとして機能します。 ユーザーが視覚エフェクトを操作すると、Power BI により、SQL クエリが Synapse SQL プールのデュアル ストレージに生成されます。メモリ内か直接クエリかは、どちらが効率的であるかに応じて決まります。 このエンジンにより、メモリ内から直接クエリに切り替えるタイミングが決定され、ロジックが Synapse SQL プールにプッシュされます。 クエリ テーブルのコンテキストに応じて、キャッシュされた (インポートされた)、またはキャッシュされない複合モデルとして機能する場合があります。 メモリにキャッシュするテーブルを選び、1 つ以上の DirectQuery ソースからデータを結合し、DirectQuery ソースとインポート データを混合したデータを結合することができます。
推奨事項: Azure Synapse Analytics プロビジョニング プールに対して DirectQuery を使う場合:
- Azure Synapse の結果セットのキャッシュ機能を使うと、クエリ結果をユーザー データベースにキャッシュして繰り返し使い、クエリのパフォーマンスをミリ秒単位まで改善し、コンピューティング リソースの使用量を削減することができます。 キャッシュされた結果セットを使うクエリには、Azure Synapse Analytics のコンカレンシー スロットは使われないため、既存のコンカレンシー制限にカウントされることはありません。
- Azure Synapse の具体化されたビューを使うと、テーブルと同様にデータを事前に計算し、格納し、管理することができます。 具体化されたビューのデータのすべてまたはサブセットを使うクエリは、パフォーマンスが向上します。また、定義済みの具体化されたビューを直接参照する必要はありません。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
頻繁に見出しに登場するデータ侵害、マルウェア感染、悪意のあるコード インジェクションなどが、クラウドの最新化を目指す企業にとってのセキュリティ上の懸念の詳細なリストに含まれています。 企業のお客様は、失敗するわけにはいかないので、懸念を解消できるクラウド プロバイダーまたはサービス ソリューションを必要とします。
このシナリオでは、ネットワーク、ID、プライバシー、認可といった階層的なセキュリティ制御を組み合わせて、最も要求の厳しいセキュリティ上の問題に対処しています。 データの大部分は Azure Synapse プロビジョニング プールに格納し、Power BI にはシングル サインオンで DirectQuery を使っています。 認証に Microsoft Entra ID を使用できます。 また、プロビジョニング プールのデータ認可のための広範なセキュリティ機能があります。
セキュリティに関する一般的な質問には、次のようなものがあります。
- どのユーザーが何のデータを表示できるかを制御できますか?
- 組織は、データ侵害のリスクを軽減するために、国、地域、および会社のガイドラインに準拠するようにデータを保護する必要があります。 Azure Synapse には、コンプライアンスを実現するデータ保護機能が複数用意されています。
- ユーザーの ID を確認するためのオプションは何ですか?
- ネットワークとデータの整合性、機密性、およびアクセスを保護するために使用できるネットワーク セキュリティ テクノロジは何ですか?
- Azure Synapse を保護するには、使用できる一連のネットワーク セキュリティ オプションを検討する必要があります。
- 脅威を検出して通知するツールは何ですか?
- Azure Synapse には、データベースの監査、保護、監視のための SQL 監査、SQL の脅威検出、脆弱性評価など、多数の脅威検出機能が用意されています。
- ストレージ アカウント内のデータを保護するにはどうすればよいですか?
- Azure Storage アカウントは、高速の一貫した応答時間を必要とするワークロードや、1 秒あたりの入出力操作数 (IOP) が多いワークロードに最適です。 ストレージ アカウントには、すべての Azure Storage データ オブジェクトが含まれており、ストレージ アカウントのセキュリティのための多くのオプションがあります。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
このセクションでは、このソリューションに関連するさまざまなサービスの価格に関する情報を提供します。また、サンプル データセットを使うこのシナリオで下された決定について説明します。
Azure Synapse
Azure Synapse Analytics のサーバーレス アーキテクチャを使用すると、コンピューティングおよびストレージのレベルを個別にスケーリングすることができます。 コンピューティング リソースは使用量に基づいて課金されるため、オンデマンドでそれらのリソースをスケーリングまたは一時停止できます。 ストレージ リソースはテラバイト単位で課金されるため、データを取り込んだ分だけコストが増加します。
Azure Pipelines
Azure Synapse 内のパイプラインに関する価格の詳細については、Azure Synapse の価格ページの「データ統合」タブを参照してください。 パイプラインの価格に影響する主なコンポーネントは 3 つあります。
- データ パイプラインのアクティビティと統合ランタイム時間
- データフロー クラスターのサイズと実行
- 運用料金
価格は、コンポーネントまたはアクティビティ、頻度、統合ランタイムのユニット数によって変わります。
サンプル データセットでは、標準の Azure ホステッド統合ランタイムで、パイプラインのコアに対する "データのコピー アクティビティ" が、ソース データベースのすべてのエンティティ (テーブル) に対して毎日のスケジュールでトリガーされます。 このシナリオには、データ フローは含まれていません。 パイプラインを使った操作は月に 100 万件未満であるため、運用コストはかかりません。
Azure Synapse 専用プールとストレージ
Azure Synapse 専用プールの価格の詳細については、Azure Synapse の価格ページの「データ ウェアハウス」タブを参照してください。 専用従量課金モデルでは、プロビジョニングされた Data Warehouse ユニット (DWU) ユニットごとに、アップタイムの時間単位で課金されます。 もう 1 つの要因は、データ ストレージのコストです。つまり、保存データのサイズ + スナップショット + geo 冗長 (ある場合) です。
サンプル データセットでは、500DWU をプロビジョニングできます。これにより、分析負荷に対する良好なエクスペリエンスを確保できます。 レポートの営業時間中は、コンピューティングを実行し続けることができます。 運用環境に移行する場合、データ ウェアハウスの容量を予約することは、コスト管理にとって魅力的なオプションです。 コストとパフォーマンスのメトリックを最大化するには、前のセクションで取り上げたように、さまざまな手法を使う必要があります。
BLOB ストレージ
ストレージ コストを削減するには、Azure Storage の予約容量機能を使用することを検討してください。 このモデルでは、1 年間または 3 年間固定のストレージ容量の予約した場合に割引が適用されます。 詳しくは、「予約容量を使用して BLOB ストレージのコストを最適化する」を参照してください。
このシナリオには永続的なストレージはありません。
Power BI Premium
Power BI Premium の価格の詳細については、Power BI の価格のページを参照してください。
このシナリオでは、要求の厳しい分析ニーズに対応するために、さまざまなパフォーマンスの強化が組み込まれた Power BI Premium ワークスペースを使います。
オペレーショナル エクセレンス
オペレーショナル エクセレンスは、アプリケーションをデプロイし、それを運用環境で実行し続ける運用プロセスをカバーします。 詳細については、「オペレーショナル エクセレンスの重要な要素の概要」を参照してください。
DevOps の推奨事項
運用、開発、およびテスト環境それぞれに対して個別のリソース グループを作成してください。 個別のリソース グループにより、デプロイの管理、テスト デプロイの削除、およびアクセス権の割り当てが行いやすくなります。
各ワークロードを別々のデプロイ テンプレートに配置し、リソースをソース管理システムに格納します。 テンプレートは一緒にデプロイすることも、継続的インテグレーションや継続的デリバリー (CI/CD) プロセスの一環として個別にデプロイすることもできるため、自動化プロセスが簡単になります。 このアーキテクチャには、主に次の 4 つのワークロードがあります。
- データ ウェアハウス サーバーと関連リソース
- Azure Synapse パイプライン
- Power BI 資産: ダッシュボード、アプリ、データセット
- オンプレミスからクラウドへのシミュレートされたシナリオ
ワークロードごとに個別のデプロイ テンプレートを用意することを目指します。
ワークロードをステージングすることを検討します。 さまざまなステージにデプロイし、各ステージで検証チェックを実行してから、次のステージに進みます。 これにより、制御された方法で運用環境に更新プログラムをプッシュし、予期しないデプロイの問題を最小限に抑えることができます。 アクティブな運用環境を更新するために、ブルーグリーン デプロイとカナリア リリースの戦略を使用してください。
失敗したデプロイを処理するための、適切なロールバック戦略を用意します。 たとえば、デプロイ履歴から以前に成功したデプロイを自動的に再デプロイすることができます。 Azure CLI の
--rollback-on-errorフラグを参照してください。Azure Monitor は、統合された監視エクスペリエンスを実現するために、データ ウェアハウスと Azure 分析プラットフォーム全体のパフォーマンスを分析するための、推奨されるオプションです。 Azure Synapse Analytics を使うと、Azure portal 内で監視エクスペリエンスが提供され、データ ウェアハウスのワークロードに関する分析情報が表示されます。 Azure portal は、データ ウェアハウスを監視する場合に推奨されるツールです。構成可能なリテンション期間、アラート、推奨事項、およびメトリックとログのカスタマイズ可能なグラフとダッシュボードが用意されているためです。
クイック スタート
- ポータル: Azure Synapse の概念実証 (POC)
- Azure CLI: Azure CLI を使用して Azure Synapse workspace を作成する
- Terraform: Terraform と Microsoft Azure を使ったモダン データ ウェアハウス
パフォーマンス効率
パフォーマンス効率とは、ユーザーによって行われた要求に合わせて効率的な方法でワークロードをスケーリングできることです。 詳細については、「パフォーマンス効率の柱の概要」を参照してください。
このセクションでは、このデータセットに対応するサイズ設定の判断について詳しく説明します。
Azure Synapse プロビジョニング プール
さまざまなデータ ウェアハウスの構成から選択できます。
| データ ウェアハウス ユニット | コンピューティング ノードの数 | ノードあたりのディストリビューションの数 |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
スケールアウトのパフォーマンス上のメリット (特に、大規模なデータ ウェアハウス ユニットのスケールアウトのパフォーマンス上の メリット) を確認するには、少なくとも 1 TB のデータ セットを使います。 専用 SQL プールの最適なデータ ウェアハウス ユニット数を確認するには、スケールアップとスケールダウンを試します。 データを読み込んだ後、さまざまなデータ ウェアハウス ユニット数でいくつかのクエリを実行します。 スケーリングは簡単に行えるので、1 時間以内でさまざまなパフォーマンス レベルを試すことができます。
最適なデータ ウェアハウス ユニット数を見つける
開発中の専用 SQL プールの場合は、少ない数のデータ ウェアハウス ユニットを選択することから始めます。 手始めとしては、DW400c または DW200c が適しています。 アプリケーションのパフォーマンスを監視し、選択したデータ ウェアハウス ユニットの数に対するパフォーマンスの変化を観察します。 線形スケールを想定し、データ ウェアハウス ユニットをどれだけ増減する必要があるかを確認します。 ビジネス要件に応じた最適なパフォーマンス レベルに到達するまで調整を行います。
Synapse SQL プールのスケーリング
- Azure portal を使用して Synapse SQL プールのコンピューティングをスケーリングする
- Azure PowerShell を使用して専用 SQL プールのコンピューティングをスケーリングする
- Azure Synapse Analytics の専用 SQL プールに使用されるコンピューティングを T-SQL を使用してスケーリングする
- 一時停止、監視、自動化
Azure Pipelines
Azure Synapse のパイプラインと使うコピー アクティビティのスケーラビリティとパフォーマンス最適化機能については、「Copy アクティビティのパフォーマンスとスケーラビリティに関するガイド」を参照してください。
Power BI Premium
この記事では、Power BI Premium Gen 2 を使って BI の機能を実演しています。 現在、Power BI Premium の容量 SKU は P1 (8 仮想コア) から P5 (128 仮想コア) の範囲です。 必要な容量を選ぶ最善の方法は、容量負荷評価を受け、継続的な監視のために Gen 2 のメトリック アプリをインストールし、Power BI Premium での自動スケーリングの使用を検討することです。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Galina Polyakova |シニア クラウド ソリューション アーキテクト
- Noah Costar | クラウド ソリューション アーキテクト
- George Stevens | クラウド ソリューション アーキテクト
その他の共同作成者:
- Jim McLeod | クラウド ソリューション アーキテクト
- Miguel Myers | シニア プログラム マネージャー
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- Power BI Premium とは何ですか?
- Microsoft Entra ID とは
- Azure Databricks で Azure Data Lake Storage Gen2 と Blob Storage にアクセスする
- Azure Synapse Analytics とは
- Azure Data Factory と Azure Synapse Analytics のパイプラインとアクティビティ
- Azure SQL とは