Azure SQL Database の Hyperscale Elastic Pool の概要
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
この記事では、Azure SQL Database の Hyperscale Elastic Pool の概要について説明します。
Azure SQL Database の Elastic Pool を使用すると、サービスとしてのソフトウェア (SaaS) の開発者は、各データベースのパフォーマンスに弾力性を持たせながら、データベースのグループの価格対パフォーマンス比を所定の予算内で最適化できます。 Azure SQL Database Hyperscale Elastic Pool では、Hyperscale データベース用の共有リソース モデルが導入されています。
Azure CLI または PowerShell を使用してデータベースを Hyperscale Elastic Pool に作成、スケーリング、または移動する例については、「コマンド ライン ツールを使った Hyperscale Elastic Pool の操作」を参照してください。
注意
Hyperscale のElastic Pool は現在プレビュー段階です。
概要
Hyperscale データベースを Elastic Pool に配置し、プール内のデータベース間でリソースを共有し、使用パターンが異なる複数のデータベースを保持するコストを最適化します。
Hyperscale データベースで Elastic Pool を使用するシナリオ:
- Elastic Pool に割り当てられたコンピューティング リソースを、割り当てられたストレージの量に関係なく、予測可能な時間でスケールアップまたはスケールダウンする必要があるとき。
- Elastic Pool に割り当てられたコンピューティング リソースを、1 つ以上の読み取りスケール レプリカを追加してスケールアウトしたいとき。
- コンピューティング リソースが少なくても、書き込み集中型ワークロードに対して高トランザクション ログ スループットを使用したい場合。
Hyperscale 以外のデータベースを Hyperscale Elastic Pool に追加すると、データベースが Hyperscale サービス レベルに変換されます。
Architecture
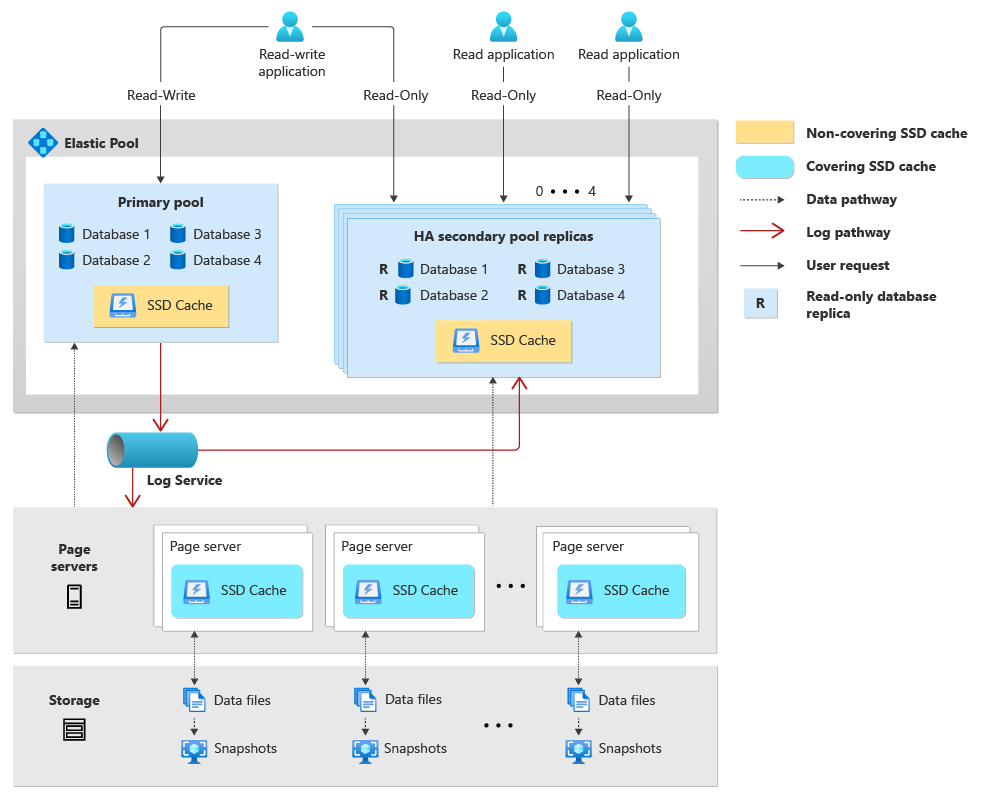
従来、スタンドアロン Hyperscale データベースのアーキテクチャは、コンピューティング、ストレージ ("ページ サーバー")、ログ ("ログ サービス") という 3 つの独立した主要コンポーネントで構成されます。 Hyperscale データベースのElastic Poolを作成すると、プール内のデータベースがコンピューティング リソースとログ リソースを共有します。 さらに、高可用性の構成を選択した場合、各高可用性プールは、同等の独立したコンピューティング リソースとログ リソースのセットで作成されます。
以下で、Hyperscale データベースのElastic Poolのアーキテクチャについて説明します。
- Hyperscale Elastic Poolは、プライマリ Hyperscale データベースをホストするプライマリ プールと、最大 4 つの追加高可用性プール (構成されている場合) で構成されます。
- プライマリ Elastic Poolでホストされているプライマリ Hyperscale データベースは、SQL Server データベース エンジン (sqlservr.exe) コンピューティング プロセス、仮想コア、メモリ、SSD キャッシュを共有します。
- プライマリ プールの高可用性を構成すると、プライマリ プール内のデータベースの読み取り専用データベース レプリカを含む追加の高可用性プールが作成されます。 各プライマリ プールは、最大 4 つの高可用性レプリカ プールを保持できます。 各高可用性プールは、プール内のすべてのセカンダリ読み取り専用データベースのコンピューティング、SSD キャッシュ、メモリ リソースを共有します。
- プライマリ Elastic Pool内の Hyperscale データベースはすべて、同じログ サービスを共有します。 高可用性プール内のデータベースには書き込みワークロードがないため、ログ サービスは利用されません。
- 各 Hyperscale データベースには独自のページ サーバー のセットがあり、これらのページ サーバーはプライマリ プール内のプライマリ データベースと高可用性プール内のすべてのセカンダリ レプリカ データベースの間で共有されます。
- geo レプリケートされたセカンダリ Hyperscale データベースは、別のElastic Pool内に配置できます。
- データベース接続文字列に
ApplicationIntent=ReadOnlyを指定すると、いずれかの高可用性プール内の読み取り専用レプリカ データベースにルーティングされます。
以下の図に、Hyperscale データベースのElastic Poolのアーキテクチャを示します。
Hyperscale Elastic Pool データベースを管理する
他のサービス レベルのプールされたデータベースと同じコマンドを使用して、プールされた Hyperscale データベースを管理できます。 Hyperscale Elastic Poolを作成するときは、エディションに必ず Hyperscale を指定してください。
唯一の違いは、既存の Hyperscale Elastic Poolについて高可用性 (H/A) レプリカの数を変更できることです。 そのためには次を行います。
- Azure PowerShell Set-AzSqlElasticPool コマンドの
HighAvailabilityReplicaCountパラメーターを使用します。 - Azure CLI az sql elastic-pool update コマンドの
--ha-replicasパラメーターを使用します。
次のクライアント ツールを使用して、Elastic Pool内の Hyperscale データベースを管理できます。
- Azure PowerShell: Az.Sql.3.11.0 以降。 PowerShell AzureRM.Sql はサポートされていません。
- Azure CLI: Az version 2.40.0 以降。
- Transact-SQL (T-SQL): SQL Server Management Studio (SSMS) v18.12.1 以降または Azure Data Studio v1.39.1 以降。
非 Hyperscale のデータベースを Hyperscale Elastic Pool に変換する
データベースを Hyperscale に変換するには、データベースを既存の Hyperscale Elastic Pool に追加します。 この場合の変換では、Hyperscale Elastic Pool がソース データベースと同じ論理サーバー上に存在する必要があります。
データベースを Hyperscale Elastic Pool に変換する場合は、Hyperscale Elastic Pool あたりのデータベースの最大数に注意してください。
T-SQL を使用して、非 Hyperscale のデータベースを Hyperscale Elastic Pool に変換する
T-SQL コマンドを使用して複数の General Purpose データベースを変換し、hsep1 という名前の既存の Hyperscale Elastic Pool に追加することができます。
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
この例ではターゲット SERVICE_OBJECTIVE を Hyperscale Elastic Pool として指定して、General Purpose から Hyperscale への変換を暗黙的に要求しています。 上記の各コマンドが各 General Purpose データベースの Hyperscale への変換を開始することができます。 これらの ALTER DATABASE コマンドは、すぐに戻ることができ、変換が完了するまで待機することはありません。 この例ではこのような 4 つの変換を General Purpose から Hyperscale へ並列に実行しています。
ユーザーは、動的管理ビュー sys.dm_operation_status クエリを実行し、これらの背景効果の変換操作の状態を監視することができます。
PowerShell を使用して、Hyperscale 以外のデータベースを Hyperscale Elastic Pool に変換する
PowerShell コマンドを使用すると、既存の hsep1 という名前の Hyperscale Elastic Pool に複数の General Purpose データベースを変換して追加できます。 例えば、サンプル スクリプトは、下記の手順を実行します。
- Get-AzSqlElasticPoolDatabase コマンドレットを使用して、General Purpose Elastic Pool内のすべてのデータベースを表示します
gpep1。 Where-Objectコマンドレットはgpepdbで始まる名前のデータベースのリストのみをフィルター処理します。- Set-AzSqlDatabase コマンドレットは、データベースごとに変換を開始します。 この場合、ターゲットとする
hsep1という名前の Hyperscale Elastic Pool を指定して Hyperscale サービス レベルへの変換を暗黙的に要求したことになります。-AsJobパラメーターを使用すると、Set-AzSqlDatabase要求を並列で実行できます。 ユーザーが変換を 1 つずつ実行したい場合は、この-AsJobパラメーターを削除することができます。
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
sys.dm_operation_status 動的管理ビューに加えて、PowerShell コマンドレット Get-AzSqlDatabaseActivity を使用し、これら背景効果の変換操作の状態を監視することができます。
リソース制限
次に、Elastic Pool内の Hyperscale データベースの使用についてサポートされている制限の一覧を示します。
- サポートされているハードウェア生成: Standard シリーズ (Gen5)、Premium シリーズ、Premium シリーズのメモリ最適化。
- プールあたりの仮想コアの最大数: サービス レベルの目標に応じて、80 または 128 の仮想コア。
- データベースあたりでサポートされる最大データ サイズ: 100 TB。
- プール内のデータベース全体でサポートされる最大合計データ サイズ: 100 TB。
- データベースあたりでサポートされる最大トランザクション ログ スループット: 100 MB。
- プール内のデータベース全体でサポートされる最大合計トランザクション ログ スループット: 131.25 MB/秒。
- 各 Hyperscale Elastic Poolは、最大 25 個のデータベースを保持できます。
詳細については、Standard シリーズ、Premium シリーズ、Premium シリーズのメモリ最適化のための Hyperscale Elastic Poolのリソース制限を参照してください。
Note
パフォーマンス プロファイル、サポートされている機能、公開されている制限は、機能がプレビュー段階にある間は変更される可能性があります。 そのため、ワークロードについて機能、パフォーマンス、スケーリングのテストを定期的に行って、ユース ケースを検証することをお勧めします。
制限事項
次の制限が適用されます。
- Hyperscale 以外の既存のElastic Poolの Hyperscale エディションへの変更はサポートされていません。 変換セクションでは使用可能ないくつかのオルタナティヴが提示されます。
- Hyperscale Elastic Poolのエディションの非 Hyperscale エディションへの変更はサポートされていません。
- Hyperscale Elastic Pool 内にある適格なデータベースを「逆移行」するには、まず Hyperscale Elastic Pool から取り出す必要があります。 その後、スタンドアロン Hyperscale データベースを General Purpose スタンドアロン データベースに「逆移行」できます。
- Hyperscale サービス レベルの場合、ゾーン冗長のサポートはデータベースまたはElastic Poolの作成時にのみ指定でき、リソースがプロビジョニングされた後は変更できません。 詳細については、「Azure SQL Database を可用性ゾーンのサポートに移行」を参照してください。
- Hyperscale Elastic Poolに名前付きレプリカを追加することはサポートされていません。 Hyperscale データベースの名前付きレプリカを Hyperscale Elastic Poolに追加しようとすると、
UnsupportedReplicationOperationエラーが発生します。 代わりに、名前付きレプリカを単一の Hyperscale データベースとして作成します。
ゾーン冗長Elastic Poolの考慮事項
ゾーン冗長 Hyperscale Elastic Pool の考慮事項を次に示します。
Note
ゾーン冗長を持つ Hyperscale Elastic Poolは、現在プレビュー段階です。 詳細については、「ブログ投稿: ゾーン冗長を持つ Hyperscale Elastic Pool」を参照してください。
- ゾーン冗長ストレージ冗長(ZRS または GZRS)を持つデータベースのみを、ゾーン冗長を持つ Hyperscale Elastic Poolに追加できます。
- スタンドアロンの Hyperscale データベースをゾーン冗長 Hyperscale Elastic Poolに追加するには、ゾーン冗長およびゾーン冗長バックアップ ストレージ(ZRS または GZRS)を持った状態で作成する必要があります。 ゾーン冗長を持たない Hyperscale データベースの場合、ゾーン冗長オプションが有効になっている新しい Hyperscale データベースへのデータ転送を実行します。 複製は、データベース コピー、ポイントインタイム リストア、geo レプリカを使用して作成する必要があります。 詳細については、「再デプロイ(Hyperscale)」を参照してください。
- Hyperscale データベースをElastic Pool間で移動するには、ゾーン冗長およびゾーン冗長バックアップ ストレージの設定が一致している必要があります。
- データベースを Hyperscale 以外の別のサービス レベルからゾーン冗長を持つ Hyperscale Elastic Pool に変換する方法は以下の通りです。
- Azure Portal を介して、まずゾーン冗長およびゾーン冗長バックアップ ストレージ(ZRS)の両方を有効にします。 その後、データベースをゾーン冗長 Hyperscale Elastic Poolに追加できます。
- PowerShell を介して、まずゾーン冗長を有効にします。 次に、「Set-AzSqlDatabase」を使用して、ゾーン冗長バックアップ ストレージ(ZRS または GZRS)を指定するために
-BackupStorageRedundancyパラメーターが使用されていることを確認します。
既知の問題
| 問題 | 推奨事項 |
|---|---|
Hyperscale 以外の多数のデータベースを Hyperscale Elastic Pool に追加すると、エラー Could not perform the operation because server would exceed the allowed Database Throughput Unit quota of 54000. (Code: ServerDtuQuotaExceeded) を受信する可能性があります。 メッセージはデータベース スループット ユニット (DTU) を参照しますが、各論理サーバーで適用される共有 DTU/仮想コア クォータに関連しています。 この問題は、個々のデータベース レベルで仮想コアが正しく計算されない欠陥が原因です。 |
ここで、問題を回避するいくつかのオプションを次に示します。 • Hyperscale Elastic Pool にデータベースを一度に 1 つずつ追加します。 • 最初にデータベースをスタンドアロン Hyperscale DB に変換してから、Hyperscale Elastic Pool に追加します。 • こちらに記載されているように、サーバー レベルのクォータの引き上げを要求します。 |
ゾーン冗長 Hyperscale Elastic Pool から別のリージョンの非ゾーン冗長 Hyperscale Elastic Pool へのデータベースの geo レプリケーションの設定は、エラー Provisioning of zone redundant Hyperscale database with local backup redundancy is not supported. Zone redundant Hyperscale databases must use either zone or geo zone backup redundancyで失敗します。 2 番目の Hyperscale Elastic Pool がゾーン冗長であるか、同じリージョンにある場合、このエラーは発生しません。 |
この問題を回避するには、Azure PowerShell を使用し、コマンド ライン New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false でゾーン冗長以外を明示的に指定します。 |
| ゾーン冗長 Hyperscale Elastic Pool からフェールオーバー グループにデータベースを追加すると、ゾーン冗長以外の Hyperscale Elastic Pool が別のリージョンに存在する場合は内部的に失敗しますが、操作が進行せずに実行されているように見える場合があります。 SSMS などのツールを使用すると、geo セカンダリ データベースが表示されることがありますが、geo セカンダリ データベースに接続して使用することはできません。 フェールオーバー グループには、geo セカンダリ データベースの状態が「シード 0%」と表示される場合があります。 2 つ目の Hyperscale Elastic Pool がゾーン冗長の場合、この問題は発生しません。 | この問題を回避するには、Azure PowerShell を使用してフェールオーバー グループの外部に geo レプリケーションを設定し、コマンド ライン New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false でゾーン冗長以外を明示的に指定します。 その後、そのフェールオーバー グループにデータベースを追加できます。 |
稀なケースですが、Hyperscale データベースをElastic Poolに移動 / 復元 / コピーしようとした場合に、エラー 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support を取得することがあります。 |
この制限は、実装固有の詳細によるものです。 このエラーによって操作が続けられない場合は、サポート インシデントを生成して、支援を要求してください。 |
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示