Azure SQL Database でアプリケーションとデータベースのパフォーマンスを調整します
適用対象:![]() Azure SQL Database
Azure SQL Database![]() Microsoft Fabric SQL Database
Microsoft Fabric SQL Database
Azure SQL Database または Fabric SQL Database でパフォーマンス問題が発生していることが確認されたら、この記事を読むと次のことに役立ちます。
- アプリケーションを調整し、パフォーマンスを向上させるベスト プラクティスを適用します。
- データをより効率的に処理するようにインデックスとクエリを変更して、データベースをチューニングします。
この記事では、該当する場合は、データベース アドバイザーの推奨事項および自動チューニングの推奨事項 (該当する場合) に従った作業が既に完了していることを前提とします。 また、監視とチューニングの概要に関する記事、「クエリ ストアを使用してパフォーマンスを監視する」、およびパフォーマンスの問題のトラブルシューティングに関連する関連記事を確認済みであることを前提としています。 さらに、この記事では、コンピューティング サイズまたはサービス レベルを上げてデータベースに対するリソースを増やすことで解決できる CPU リソース使用率関連のパフォーマンスの問題がないことを前提としています。
Note
Azure SQL Managed Instance の同様のガイダンスについては、「Azure SQL Managed Instance でアプリケーションとデータベースのパフォーマンスを調整します」を参照してください。
アプリケーションの調整
従来のオンプレミス SQL Server では多くの場合、初回の容量計画のプロセスは、運用環境でアプリケーションを実行するプロセスから分離されます。 最初にハードウェアと製品ライセンスが購入され、パフォーマンス調整は後で行われます。 Azure SQL を使用する場合、アプリケーションの実行と調整のプロセスを組み合わせることをお勧めします。 オンデマンド容量の支払いモデルでは、現在必要とされる最小のリソースを使用するようにアプリケーションを調整できます。(不正確なことが多い) アプリケーションの将来的な成長計画の推測に基づいて、ハードウェアに過剰プロビジョニングを行うことはしません。
アプリケーションを調整しないでハードウェア リソースを過剰にプロビジョニングすることを選ぶユーザーもいます。 この方法は、利用が集中する期間に重要なアプリケーションの変更を望まない場合に適していることがあります。 しかし、アプリケーションを調整することで、リソース要件を最小限に抑え、毎月の請求額を抑えることができます。
Azure SQL Database のアプリケーション設計におけるベスト プラクティスとアンチパターン
Azure SQL Database のサービス レベルは、アプリケーションのパフォーマンスの安定性と予測可能性を高めるように設計されています。一方で、いくつかのベスト プラクティスを実践することで、コンピューティング サイズ内でリソースを最大限に活用するようアプリケーションを調整できます。 多くのアプリケーションは、上位のコンピューティング サイズまたはサービス レベルに切り替えることでパフォーマンスが大幅に向上します。とはいえ、アプリケーションによっては、上位のサービス レベルの利点を活かすためにさらに調整が必要になります。 次のような特性を備えたアプリケーションでは、パフォーマンスを向上させるためにアプリケーションに調整を加えることを検討してください。
"煩雑な" 動作が原因でパフォーマンスの低いアプリケーション
煩雑なアプリケーションでは、ネットワークの待機時間が重要なデータ アクセス操作が過度に発生します。 この種のアプリケーションでは、データベースに対するデータ アクセス操作の数を減らすよう変更を施す必要があります。 たとえば、アドホック クエリを一括処理したり、ストアド プロシージャにクエリを移動したりするなどの手法を使って、アプリケーションのパフォーマンスを向上させることができます。 詳細については、「 バッチ クエリ」を参照してください。
単一のマシンではサポートし切れないほどワークロードが集中するデータベース
最高の Premium コンピューティング サイズのリソースを超えるデータベースでは、ワークロードのスケールアウトを活用できる場合があります。 詳細については、「データベース間のシャーディング」と「機能的パーティション分割」を参照してください。
最適でないクエリを含むアプリケーション
クエリが十分に調整されていないアプリケーションの場合、上位のコンピューティング サイズの利点を活かせないことがあります。 たとえば、WHERE 句がない、インデックスが足りない、統計が古いクエリです。 これらのアプリケーションの場合、クエリ パフォーマンスの標準的な調整方法で効果が得られます。 詳細については、「インデックスの不足」と「クエリの調整とヒント」を参照してください。
データ アクセス設計が最適ではないアプリケーション
デッドロックなど、データ アクセスの同時性問題が内在するアプリケーションの場合、上位のコンピューティング サイズの利点を活かせないことがあります。 Azure キャッシュ サービスや他のキャッシング技術を利用し、クライアント側でデータをキャッシュすることで、データベースに対するラウンド トリップを減らすことを検討してください。 詳しくは、「 アプリケーション層のキャッシュ」を参照してください。
Azure SQL Database でデッドロックが繰り返されるのを防ぐには、「Azure SQL Database と Fabric SQL Databaseでのデッドロックの分析と防止
に関するページを参照してください。
データベースの調整
このセクションでは、データベースを調整するいくつかの手法について説明します。これらの手法を使用すると、アプリケーションから最良のパフォーマンスを引き出し、可能な限り下位のコンピューティング サイズでアプリケーションを実行することができます。 これらの手法の一部は従来の SQL Server 調整のベスト プラクティスと同じですが、その他のものは Azure SQL Database に固有です。 場合によっては、データベースで使用されるリソースを調べ、さらに調整すべき領域を見つけることができるほか、従来の SQL Server 手法を拡大し、Azure SQL Database に応用することができます。
欠落したインデックスを特定して追加する
OLTP データベースのパフォーマンスの一般的問題は物理的なデータベース設計に関連します。 多くの場合、データベース スキーマは (負荷またはデータ量の) 規模の面で試験することなく設計され、出荷されます。 残念ながら、クエリ プランのパフォーマンスは、規模が小さい場合には許容されることがあるものの、実稼働レベルのデータ量では大幅に低下する可能性があります。 この問題の最も一般的な原因は、適切なインデックスがなく、クエリのフィルターまたはその他の制約を満たせないことにあります。 多くの場合、インデックスがないと、インデックス シークで足りるときにテーブル スキャンが行われます。
次の例では、シークで足りるときに、選択したクエリ プランでスキャンが使用されます。
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
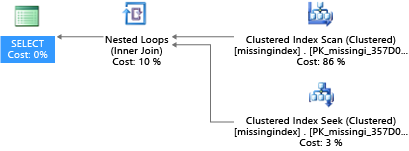
Azure SQL Database は、インデックス不足の一般的な状態を発見して修正するのに役立ちます。 Azure SQL Database に組み込まれている DMV には、クエリ コンパイルが表示されます。クエリを実行するために見積もられたコストをインデックスで大幅に削減できる場合があります。 クエリの実行中、データベース エンジンによって、各クエリ プランが実行される頻度と、実行クエリ プランとそのインデックスが存在した想定クエリ プランの間で見積もられるギャップが追跡されます。 これらの DMV を使用し、データベースとその実際のワークロードに関してワークロード コストを全体的に改善できる物理データベース設計の変更をすばやく推測できます。
次のクエリは、潜在的なインデックス不足の評価に使用できます。
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
この例では、クエリの結果として次が推奨されました。
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
作成後、同じ SELECT ステートメントを実行すると、異なるプランが選択されます。スキャンではなくシークが使用され、プランがより効率的に実行されます。
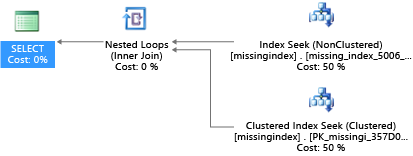
重要なことは、共有される汎用システムの IO 容量は専用サーバー コンピューターの IO 容量より限られているということです。 不必要な IO を最小限に抑え、サービス レベルの各コンピューティング サイズのリソース内でシステムを最大限に活用することが重要です。 適切な物理データベース設計を選択すると、個々のクエリの待機時間のほか、スケール ユニットごとに処理される同時要求のスループットを大幅に改善し、クエリを満たすために必要なコストを最小限に抑えることができます。
欠落インデックス要求を使用したインデックスのチューニングの詳細については、「欠落したインデックス提案を使用した非クラスター化インデックスのチューニング」を参照してください。
クエリの調整とヒント
Azure SQL Database のクエリ オプティマイザーは、従来の SQL Server クエリ オプティマイザーと似ています。 クエリを調整し、クエリ オプティマイザーの推論モデル制約を理解するためのベスト プラクティスのほとんどは、Azure SQL Database にも活かすことができます。 Azure SQL Database のクエリを調整すると、総リソース要求を減らせる場合があります。 下位のコンピューティング サイズで実行できるため、クエリが調整されていない場合に比べて少ないコストでアプリケーションを実行できます。
SQL Server でよく見られ Azure SQL Database にも適用される例は、クエリ オプティマイザーによるパラメーターの "スニッフィング" です。 コンパイル中、クエリ オプティマイザーによってパラメーターの現在の値が評価され、より最適なクエリ プランを生成できるかどうかが判断されます。 この戦略を使用すると多くの場合、既知のパラメーター値を使用せずにコンパイルされたプランよりもはるかに高速なクエリ プランが生成されます。ただし現時点では、Azure SQL Database の両方で動作が不完全です。 (SQL Server 2022 で導入された新しいインテリジェントなクエリ パフォーマンス機能であるパラメーターに依存するプランの最適化は、パラメーター化されたクエリに対してキャッシュされた単一のプランが、受け取った可能性のあるすべてのパラメーター値に対して最適ではないというシナリオに対処します。現時点では、パラメーターに依存するプランの最適化は Azure SQL Database では使用できません)
意図をより慎重に指定し、パラメーター スニッフィングの既定の動作をオーバーライドできるように、データベース エンジンはクエリ ヒント (ディレクティブ) をサポートしています。 既定の動作が特定のワークロードに対して不完全である場合は、ヒントの使用を選択できます。
次の例は、パフォーマンスとリソースの両方の要件について最適でないプランがクエリ プロセッサによって生成されるようすを示しています。 この例から、クエリ ヒントを使用すると、データベースのクエリの実行時間とリソース要件を抑えることができることもわかります。
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
セットアップ コードにより、偏った (または不規則に分散された) データが t1 テーブル内に作成されます。 最適なクエリ プランは、選択されたパラメーターによって異なります。 残念ながらプラン キャッシング動作では、常に最も一般的なパラメーター値に基づいてクエリが再コンパイルされるとは限りません。 そのため、平均すると別のプランの方がプランとしてより良い選択になる場合でも、最適でないプランがキャッシュされ、多くの値に使用される可能性があります。 次に、(一方に特殊なクエリ ヒントが含まれていることを除いて) 同一の 2 つのストアド プロシージャがクエリ プランによって作成されます。
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
例のパート 2 を開始する前に少なくとも 10 分待つことをお勧めします。これにより、生成されるテレメトリ データの結果の差異がはっきりします。
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
この例の各パートでは、(テスト データ セットとして使用するのに十分な負荷を生成するために) パラメーター化された挿入ステートメントが 1,000 回試行されます。 ストアド プロシージャを実行するとき、クエリ プロセッサは、その最初のコンパイル中にプロシージャに渡されるパラメーター値を調べます (パラメーターの "スニッフィング")。 結果として生成されたプランがプロセッサによってキャッシュされ、パラメーター値が異なる場合でも、後の呼び出しで使用されます。 最適なプランが使用されないことがあります。 クエリが最初にコンパイルされたときのケースではなく、平均的なケースに対して最適なプランを選択するように、オプティマイザーを調整する必要がある場合があります。 この例では、最初のプランは、パラメーターに一致する各値を見つけるためにすべての行を読み取る "スキャン" プランを生成します。

値 1 を使用してプロシージャを実行したため、結果として生成されたプランは値 1 に対して最適ですが、テーブルにある他のすべての値に対しては最適ではありません。 各プランを無作為に選択した場合、結果は望んだものと異なることが予想されます。これは、プランの実行が遅く、より多くのリソースが使用されるためです。
SET STATISTICS IO を ON に設定してテストを実行すると、この例の論理スキャン作業がバックグラウンドで行われます。 このプランによって 1,148 件の読み取りが行われたことがわかります (平均的なケースで返される行がたった 1 つの場合、非効率的です)。

例の 2 つ目の部分では、クエリ ヒントを利用し、コンパイル プロセス中に特定の値を使用するようにオプティマイザーに伝えます。 この場合、パラメーターとして渡される値を無視し、UNKNOWN を想定するようにクエリ プロセッサに強制します。 これはテーブル内での頻度が平均的な値を示します (傾斜を無視)。 結果として生成されるプランはシークベースのプランです。このプランはこの例のパート 1 のプランより全体的に高速であり、このプランで使用されるリソースもパート 1 のプランより全体的に少なくなっています。
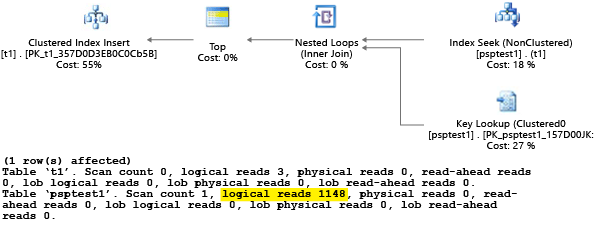
影響は、Azure SQL Database に固有の sys.resource_stats システム ビューで確認できます。 テストを実行してから、データがテーブルに入力されるまでに遅延が発生します。 この例では、パート 1 は 22:25:00 の時間枠で実行され、パート 2 は 22:35:00 の時間枠で実行されています。 遅い方の時間枠と比べ、早い方の時間枠でその時間枠のリソースがより多く使用されます (プランの効率性改善が理由)。
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

Note
この例では規模を意図的に小さくしてありますが、最適でないパラメーターの影響は特に大規模なデータベースで顕著になります。 極端なケースでは、速い場合は数秒単位、遅い場合は数時間単位の差異になります。
sys.resource_stats を調べると、あるテストで使用されるリソースが別のテストより多いか少ないか判断できます。 データを比較するとき、sys.resource_stats ビューで同じ 5 分の枠に入らないようにテストのタイミングを離します。 この演習の目標は、使用されるリソースの総量を最小限に抑えることであり、ピーク リソースを最小限に抑えることではありません。 一般的に、待ち時間のコードの一部を最適化すると、リソースの消費量も減ります。 アプリケーションに施す変更が必要なものであることと、アプリケーションでクエリ ヒントを使用している他のユーザーのカスタマー エクスペリエンスに対し変更による悪影響がないことを確認してください。
ワークロードに一連の反復的なクエリが含まれる場合は、データベースをホストするために必要な最小リソース サイズ単位を把握できるため、たいてい、プラン選択肢の最適性を理解して検証することは合理的です。 検証した後、プランのパフォーマンスが低くなっていないことを確認するために、ときどきプランを調べ直してください。 詳細については、「 クエリ ヒント (Transact-SQL)」をご覧ください。
接続と接続プールを最適化する
Azure SQL Database で頻繁にアプリケーション接続を作成するオーバーヘッドを減らすために、接続プールはデータ プロバイダーで使用できます。 たとえば、接続プールは既定で ADO.NET で有効になっています。 接続プールを使用すると、アプリケーションは接続を再利用し、新しい接続を確立するオーバーヘッドを最小限に抑えることができます。
接続プールを使用すると、スループットを向上させ、待機時間を短縮し、データベース ワークロードの全体的なパフォーマンスを向上させることができます。 組み込みの認証メカニズムを使用する場合、ドライバーはトークンとトークンの更新を内部的に管理します。 次のベスト プラクティスに留意してください。
ワークロードのコンカレンシーと待機時間の要件に基づいて、最大接続、接続タイムアウト、接続の有効期間などの接続プール設定を構成します。 詳細については、データ プロバイダーのドキュメントを参照してください。
クラウド アプリケーションでは、一時的な接続エラー 適切に処理するために、再試行ロジック を実装する必要があります。 一時的なエラーの
再試行ロジックを設計する方法について説明します。 Microsoft Entra ID 認証などのトークン ベースの認証メカニズムでは、有効期限が切れた時点で新しいトークンを生成する必要があります。 期限切れのトークンを持つプール内の物理接続を閉じ、新しい物理接続を作成する必要があります。 トークンベースの認証を使用する物理接続の作成にかかる時間を最適化するには:
- プロアクティブで非同期のトークン更新を実装する: 新しいトークンを取得するための最初の接続
Open()では、新しい Entra ID トークンを取得するために短い遅延が必要になる場合があります。 多くのアプリケーションでは、この遅延はごくわずかであり、再構成は必要ありません。 アプリケーションでトークンを管理することを選択した場合は、有効期限が切れる前に 新しいアクセス トークン 取得し、それらがキャッシュされていることを確認します。 これにより、物理接続の作成時のトークン取得の遅延を最小限に抑えることができます。 トークンの更新を実行すると、短い遅延がユーザー以外のプロセスに事前に移動されます。 - トークンの有効期間を調整する:Microsoft Entra ID のトークン有効期限切れポリシーを、アプリケーション内の論理接続の予想される有効期間以上になるように構成します。 トークンの有効期限を調整する必要はありませんが、セキュリティと物理接続を再作成するパフォーマンス オーバーヘッドのバランスを取るのに役立ちます。
- プロアクティブで非同期のトークン更新を実装する: 新しいトークンを取得するための最初の接続
Azure SQL Database 接続のパフォーマンスとリソースの使用状況を監視して、過剰なアイドル接続やプールの制限不足などのボトルネックを特定し、それに応じて構成を調整します。 Microsoft Entra ID ログ を使用して、トークンの有効期限エラーを追跡し、トークンの有効期間が適切に構成されていることを確認します。 補足的に Database Watcher や、該当する場合は Azure Monitor を使用することを検討してください。
Azure SQL Database における非常に大規模なデータベース アーキテクチャのベスト プラクティス
Azure SQL Database の単一データベースに対して
次の 2 つのセクションでは、Hyperscale サービス レベルを使用できない場合に、Azure SQL Database で非常に大規模なデータベースに発生する問題を解決するための 2 つのオプションについて説明します。
Note
エラスティック プールは、Azure SQL Managed Instance、オンプレミスの SQL Server インスタンス、Azure VM 上の SQL Server、Azure Synapse Analytics では使用できません。
データベース間のシャーディング
Azure SQL Database は汎用ハードウェアで実行されるため、従来のオンプレミス SQL Server インストールと比べ、1 つのデータベースに対する容量制限が低くなります。 データベース操作が Azure SQL Database の 1 つのデータベースの制限内に収まらないときにシャーディング手法を使用して、複数のデータベースに操作を分散しているユーザーもいます。 Azure SQL Database でシャーディング手法を利用するほとんどのユーザーは、1 つのディメンションのデータを複数のデータベースで分割します。 この手法では、OLTP アプリケーションは多くの場合、スキーマ内の 1 行のみ、またはほんの数行から成るグループに適用されるトランザクションを実行することを理解しておく必要があります。
Note
Azure SQL Database にシャーディングを支援するライブラリが追加されました。 詳細については、「 エラスティック データベース クライアント ライブラリの概要」をご覧ください。
たとえば、(AdventureWorks データベースのように) あるデータベースに顧客名、注文、および注文詳細が含まれている場合、関連する注文と注文詳細の情報を使って顧客をグループ化することで、このデータを複数のデータベースに分割できます。 顧客のデータは 1 つのデータベース内にとどめておくことができます。 アプリケーションはデータベース間で顧客を分割し、効果的に負荷を分散します。 シャーディングを使用すると、顧客はデータベース サイズの最大制限を回避できるだけでなく、個々のデータベースがそのサービス レベルの制限内に収まる限り、各コンピューティング サイズの制限を大幅に超えるワークロードを Azure SQL Database で処理できます。
データベース シャーディングではソリューションの総リソース容量を減らすことはできませんが、複数のデータベースにまたがる非常に大規模なソリューションに対応する際に非常に効果的です。 各データベースを異なるコンピューティング サイズで実行し、リソース要件の高い、非常に大規模で "効果的な" データベースに対応できます。
機能的パーティション分割
ユーザーは多くの場合、1 つのデータベースのさまざまな機能を組み合わせます。 たとえば、店舗の在庫を管理するロジックがアプリケーションに含まれている場合、そのデータベースには、在庫に関連付けられているロジック、購買発注の追跡、ストアド プロシージャ、月末報告を管理するインデックス付きビュー/マテリアライズドビューが含まれていることがあります。 この手法では、バックアップなどの操作に関するデータベースの管理が容易になりますが、アプリケーションの機能全体でピーク負荷を処理できるようにハードウェアのサイズを調整する必要もあります。
Azure SQL Database 内でスケールアウト アーキテクチャを使用する場合、アプリケーションの異なる機能を異なるデータベースに分割することをお勧めします。 この手法を使用すると、各アプリケーションは独立してスケーリングされます。 管理者は、アプリケーションがビジー状態になった (データベースの負荷が増えた) ときに、アプリケーションの機能ごとにコンピューティング サイズを個別に選択できます。 制限はありますが、このアーキテクチャを使用して、1 台の汎用コンピューターで処理できる範囲を超えてアプリケーションの規模を大きくできます。これは、複数のコンピューター間で負荷が分散されるためです。
バッチ クエリ
大量のアドホック クエリを頻繁に実行してデータにアクセスするアプリケーションの場合、アプリケーション層とデータベース層の間で行われるネットワーク通信の応答に、相当な時間が費やされます。 アプリケーションとデータベースが両方同じデータ センターに存在する場合でも、データ アクセス操作の数が多ければ、この 2 つの間のネットワーク待機時間は長くなる可能性があります。 データ アクセス操作のネットワーク ラウンド トリップを減らすために、アドホック クエリを一括処理すること、またはストアド プロシージャとしてそれらをコンパイルすることを検討してください。 アドホック クエリを一括処理すると、複数のクエリを 1 つの大きなバッチとして 1 回のトリップでデータベースに送信できます。 アドホック クエリをストアド プロシージャにコンパイルすると、それらを一括処理した場合と同じ結果が得られます。 ストアド プロシージャを使用すると、クエリ プランがデータベースにキャッシュされる機会が増えるという利点もあるため、ストアド プロシージャを再度使用できます。
一部のアプリケーションでは、書き込みが集中します。 場合によっては、書き込みを一括処理する方法を検討することで、データベースの IO 総負荷を減らすことができます。 これは多くの場合、ストアド プロシージャとアドホック バッチ内で自動コミット トランザクションではなく明示的なトランザクションを使用するのと同じくらい単純です。 使用できるさまざまな手法の評価については、 Azure でのデータベース アプリケーションのバッチ処理手法に関するページをご覧ください。 独自のワークロードで実験を行って、一括処理に適したモデルを見つけてください。 モデルによってはトランザクションの整合性の保証がわずかに異なる場合があることを理解しておいてください。 リソース使用を最小限に抑える適切なワークロードを見つけるには、整合性とパフォーマンスの適度なバランスを見つける必要があります。
アプリケーション層のキャッシュ
一部のデータベース アプリケーションでは、ワークロードの大半が読み取りになります。 キャッシュ層を利用すれば、データベースの負荷を減らすことができます。また、Azure SQL Database を使用してデータベースをサポートするために必要なコンピューティング サイズを下げられる可能性があります。 Azure Cache for Redis を利用すると、読み取りが多いワークロードがある場合に、データを 1 回 (または、構成方法に応じてアプリケーション層コンピューターごとに 1 回) 読み込んでから、データベースの外部にそのデータを格納することができます。 この方法は、データベースの負荷 (CPU と読み取り IO) を減らすことができるものの、トランザクションの整合性に影響があります。データがキャッシュから読み込まれると、データベースのデータとの同期が失われることがあるためです。 多くのアプリケーションではある程度の不整合が許容されますが、すべてのワークロードで許容されるとは限りません。 アプリケーション層のキャッシュ手法を実装する前に、あらゆるアプリケーション要件を完全に理解しておく必要があります。
構成とデザインのヒントを取得する
Azure SQL Database を使用する場合は、Azure SQL Database でデータベースの構成と設計を改善するためのオープンソースの T-SQL スクリプトを実行できます。 このスクリプトを使用すると、オンデマンドでデータベースが分析され、データベースのパフォーマンスと正常性を向上させるためのヒントが提供されます。 ベスト プラクティスに基づいて構成と運用上の変更を提案するヒントもありますが、データベース エンジンの高度な機能を有効にするなど、ワークロードに適したデザインの変更を推奨するヒントもあります。
スクリプトの詳細について、および作業を開始するには、Azure SQL ヒントの Wiki ページを参照してください。
Azure SQL データベースの最新の機能と更新プログラムを最新の状態に保つには、「AAzure SQL データベースの最新情報」を参照してください。
関連するコンテンツ
- Azure SQL Database を監視する
- Azure SQL Database のクエリ パフォーマンス インサイト
- 動的管理ビューを使用したパフォーマンスの監視
- データベース監視ツール
- Azure SQL Database での高 CPU 使用率の診断とトラブルシューティング
- インデックスの候補が見つからない、クラスター化されていないインデックスを調整する
- ビデオ: Azure SQL Database でのデータ読み込みのベスト プラクティス