Azure Cosmos DB の分析ストアでの変更データ キャプチャの概要
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Azure Cosmos DB 分析ストアの変更データ キャプチャ (CDC) を Azure Data Factory または Azure Synapse Analytics に対するソースとして使用して、データに対する特定の変更をキャプチャします。
注意
Azure Cosmos DB for MongoDB API のリンク サービス インターフェイスは、データフローではまだ使用できません。 ただし、Mongo のリンク サービスが直接サポートされるまで、"Azure Cosmos DB for NoSQL" のリンク サービス インターフェイスを使用して、アカウントのドキュメント エンドポイントを使用できます。 NoSQL リンク サービスで [手動で入力] を選択して Cosmos DB アカウント情報を指定し、MongoDB エンドポイント (例: mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/) ではなく、アカウントのドキュメント エンドポイント (例: https://[your-database-account-uri].documents.azure.com:443/) を使用します
前提条件
- 既存の Azure Cosmos DB アカウント。
- Azure サブスクリプションをお持ちの場合は、新しいアカウントを作成します。
- Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
- または、コミットする前に Azure Cosmos DB を無料で試すこともできます。
分析ストアを有効にする
まず、アカウント レベルで Azure Synapse Link を有効にしてから、ワークロードに適したコンテナーの分析ストアを有効にします。
Azure Synapse Link を有効にします: Azure Cosmos DB アカウントの Azure Synapse Link を有効にする
コンテナーの分析ストアを有効にする:
オプション ガイド 特定の新しいコンテナーに対して有効にする 新しいコンテナーで Azure Synapse Link を有効にする 特定の既存のコンテナーで有効にする 既存のコンテナーで Azure Synapse Link を有効にする
データ フローを使用してターゲット Azure リソースを作成する
分析ストアの変更データ キャプチャ機能は、Azure Data Factory または Azure Synapse Analytics のデータ フロー機能を通じて使用できます。 このガイドでは、Azure Data Factory を使用します。
重要
Azure Synapse Analytics を使用することもできます。 まず、Azure Synapse ワークスペースを作成します (まだない場合)。 新しく作成したワークスペース内で、[開発] タブを選択し、[新しいリソースの追加] を選択して、[データ フロー] を選択します。
Azure Data Factory を作成します (まだない場合)。
ヒント
可能であれば、Azure Cosmos DB アカウントが存在するのと同じリージョンにデータ ファクトリを作成します。
新しく作成したデータ ファクトリを起動します。
そのデータ ファクトリで、[データ フロー] タブを選択し、[新しいデータ フロー] を選択します。
新しく作成したデータ フローに一意の名前を付けます。 この例では、データ フローの名前は
cosmoscdcです。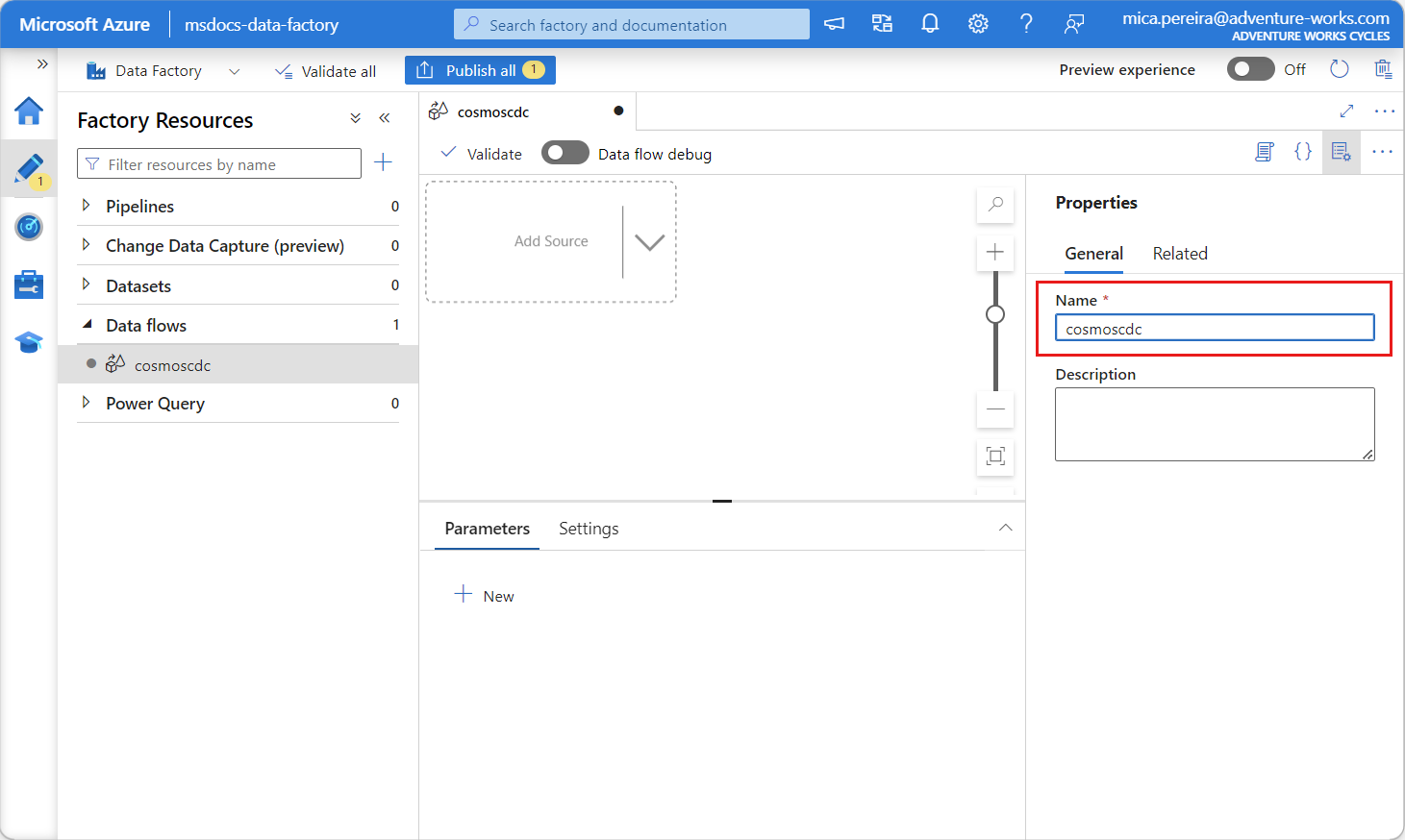

分析ストア コンテナーのソース設定を構成する
次に、Azure Cosmos DB アカウントの分析ストアからデータを送信するソースを作成して構成します。
[ソースの追加] を選択します。
![[ソースの追加] メニュー オプションのスクリーンショット。](media/get-started-change-data-capture/add-source.png)
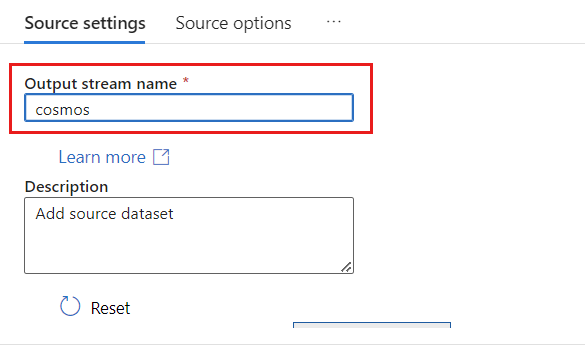
[出力ストリーム名] フィールドに cosmos と入力します。
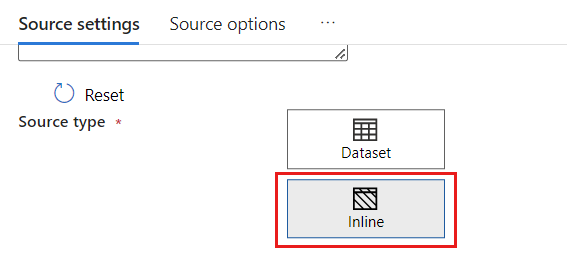
[ソースの種類] セクションで、[インライン] を選択します。
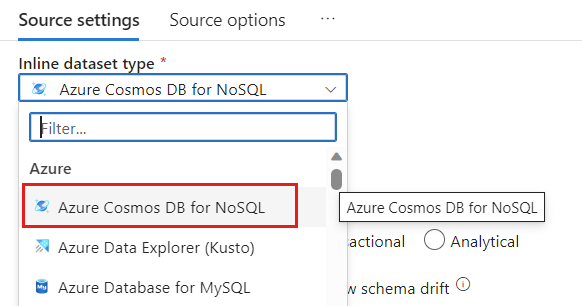
[データセット] フィールドで、Azure - Azure Cosmos DB for NoSQL を選択します。
cosmoslinkedservice という名前のアカウントの新しいリンク サービスを作成します。 [新しいリンク サービス] ポップアップ ダイアログで既存の Azure Cosmos DB for NoSQL アカウントを選択し、[OK] を選択します。 この例では、
msdocs-cosmos-sourceという名前の既存の Azure Cosmos DB for NoSQL アカウントと、cosmicworksという名前のデータベースを選択します。![Azure Cosmos DB アカウントが選択された [新しいリンク サービス] ダイアログのスクリーンショット。](media/get-started-change-data-capture/new-linked-service.png)
ストアの種類として [分析] を選択します。
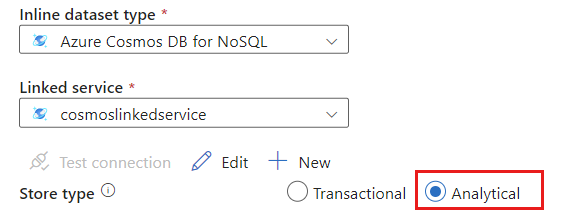
[ソース オプション] タブを選択します。
[ソース オプション] で、ターゲット コンテナーを選択し、[データ フローのデバッグ] を有効にします。 この例では、コンテナーの名前は
productsです。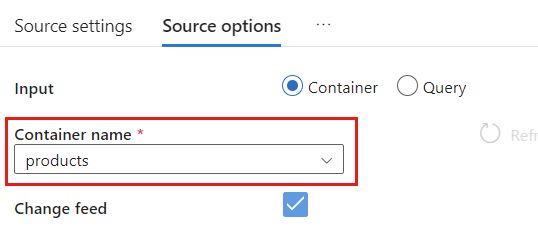
[データ フローのデバッグ] を選択します。 [Turn on data flow debug](データ フローデバッグを有効にする) ポップアップ ダイアログで、既定のオプションを維持し、[OK] を選択します。
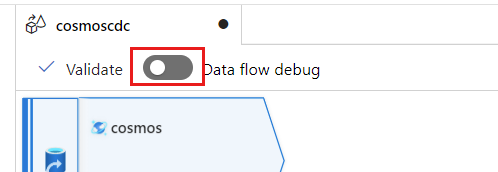
[ソース オプション] タブには、有効にできる他のオプションも含まれています。 次の表では、これらのオプションについて説明します。
| オプション | 説明 |
|---|---|
| [Capture intermediate updates](中間更新のキャプチャ) | 変更データ キャプチャの読み取りの間の中間変更を含む、項目の変更履歴をキャプチャする場合は、このオプションを有効にします。 |
| [Capture Deletes](削除のキャプチャ) | ユーザーが削除したレコードをキャプチャし、それらをシンクに適用する場合は、このオプションを有効にします。 削除は、Azure Data Explorer および Azure Cosmos DB シンクには適用できません。 |
| [Capture Transactional store TTLs](トランザクション ストアの TTL のキャプチャ) | Azure Cosmos DB トランザクション ストア (Time-to-Live) TTL で削除されたレコードをキャプチャし、シンクに適用する場合、このオプションを有効にします。 TTL での削除は、Azure Data Explorer および Azure Cosmos DB シンクには適用できません。 |
| [Batchsize in bytes](バッチサイズ (バイト単位)) | この設定は実際にはギガバイトです。 変更データ キャプチャ フィードをバッチ処理する場合は、サイズをギガバイト単位で指定します |
| [Extra Configs](追加の構成) | 追加の Azure Cosmos DB 分析ストアの構成とその値。 (例: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
ソース オプションの操作
Capture intermediate updates、Capture Deltes、Capture Transactional store TTLs のいずれかのオプションをチェックすると、CDC プロセスによってシンク内の__usr_opType フィールドが作成され、次の値が設定されます。
| 値 | 説明 | オプション |
|---|---|---|
| 1 | UPDATE | 中間更新をキャプチャする |
| 2 | INSERT | 挿入のオプションはありません。既定ではオンになっています |
| 3 | USER_DELETE | [Capture Deletes](削除のキャプチャ) |
| 4 | TTL_DELETE | [Capture Transactional store TTLs](トランザクション ストアの TTL のキャプチャ) |
TTL で削除されたレコードと、ユーザーまたはアプリケーションによって削除されたドキュメントを区別する必要がある場合は、Capture intermediate updates と Capture Transactional store TTLs の両方のオプションをチェックします。 その後、ビジネス ニーズに応じて、__usr_opType を使用するように CDC プロセスまたはアプリケーションまたはクエリを調整する必要があります。
ヒント
ダウンストリーム コンシューマーが [中間更新プログラムのキャプチャ] オプションをオンにして更新の順序を復元する必要がある場合は、システム タイムスタンプの _ts フィールドを順序付けフィールドとして使用できます。
更新および削除の操作のシンク設定を作成して構成する
まず、シンプルな Azure Blob Storage シンクを作成してから、特定の操作のみにデータをフィルター処理するように、そのシンクを構成します。
Azure Blob Storage アカウントとコンテナーを作成します (まだない場合)。 次の例では、
msdocsblobstorageという名前のアカウントとoutputという名前のコンテナーを使用します。ヒント
可能であれば、Azure Cosmos DB アカウントが存在するのと同じリージョンにストレージ アカウントを作成します。
Azure Data Factory に戻り、
cosmosソースからキャプチャされた変更データの新しいシンクを作成します。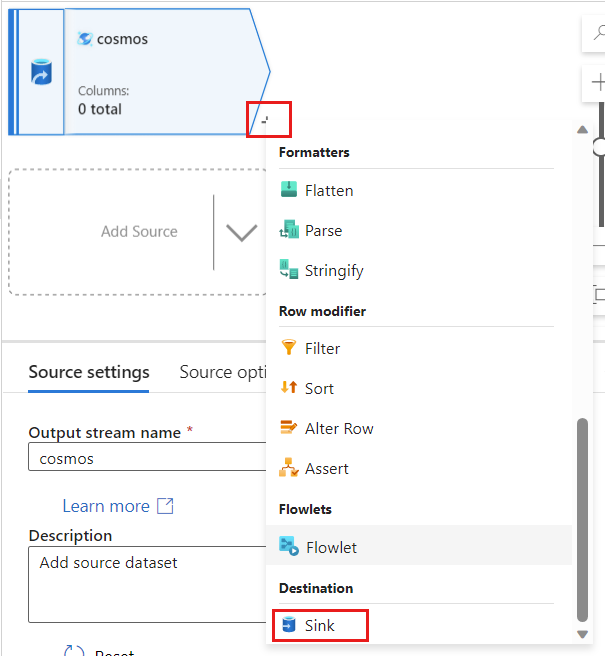
シンクに一意の名前を付けます。 この例では、シンクの名前は
storageです。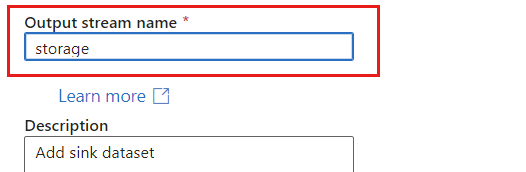
[シンクの種類] セクションで、[インライン] を選択します。 [データセット] フィールド で、[デルタ] を選択します。
![シンクにインラインの [デルタ] のデータセットの種類を選択しているスクリーンショット。](media/get-started-change-data-capture/sink-dataset-type.png)
Azure Blob Storage を使用して、storagelinkedservice という名前の、アカウントの新しいリンク サービスを作成します。 [新しいリンク サービス] ポップアップ ダイアログで既存の Azure Blob Storage アカウントを選択してから、[OK] を選択します。 この例では、
msdocsblobstorageという名前の既存の Azure Blob Storage アカウントを選択します。![新しい [デルタ] リンク サービスでのサービスの種類オプションのスクリーンショット。](media/get-started-change-data-capture/new-linked-service-sink-type.png)
![Azure Blob Storage アカウントが選択された [新しいリンク サービス] ダイアログのスクリーンショット。](media/get-started-change-data-capture/new-linked-service-sink-config.png)
[Settings](設定) タブを選択します。
[設定] で、[フォルダー パス] を BLOB コンテナーの名前に設定します。 この例では、コンテナーの名前は です
output。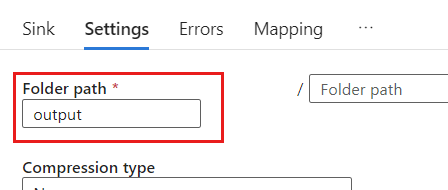
[更新方法] セクションを見つけて、削除および更新操作のみを許可するように選択内容を変更します。 また、フィールド
{_rid}を一意識別子として使用して、[キー列] を [列の一覧] として指定します。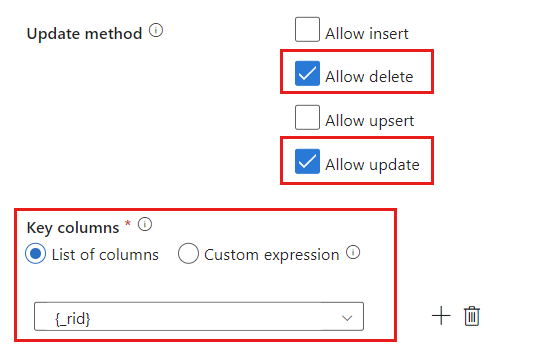
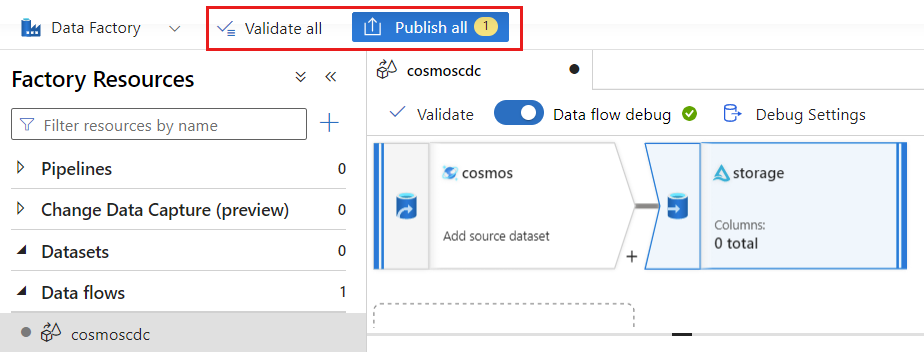
[検証] を選択して、エラーや省略を行っていないことを確認します。 次に、[発行] を選択してデータ フローを発行します。
変更データ キャプチャの実行をスケジュールする
データ フローが発行されたら、新しいパイプラインを追加してデータを移動および変換できます。
新しいパイプラインを作成する。 パイプラインに一意の名前を付けます。 この例では、パイプラインの名前
cosmoscdcpipelineはです。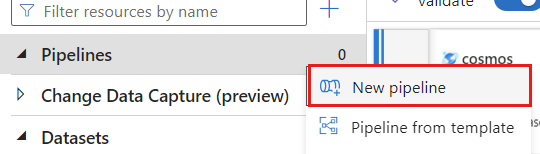
[アクティビティ] セクションで、[変換と移動] オプションを展開し、[データ フロー] を選択します。
![[アクティビティ] セクション内のデータ フロー アクティビティ オプションのスクリーンショット。](media/get-started-change-data-capture/data-flow-activity.png)
データ フロー アクティビティに一意の名前を付けます。 この例では、アクティビティの名前は
cosmoscdcactivityです。[設定] タブで、このガイドの前の部分で作成した
cosmoscdcという名前のデータ フローを選択します。 次に、データ ボリュームに基づいたコンピューティング サイズとワークロードで必要な待機時間を選択します。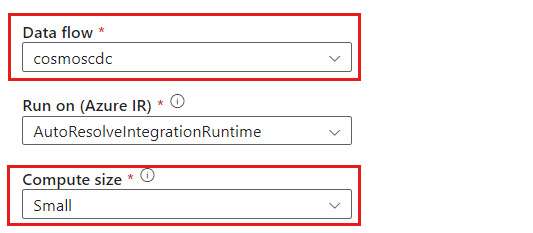
ヒント
100 GB を超える増分データ サイズの場合は、コア数が 32 (+16 ドライバー コア) のカスタム サイズをお勧めします。
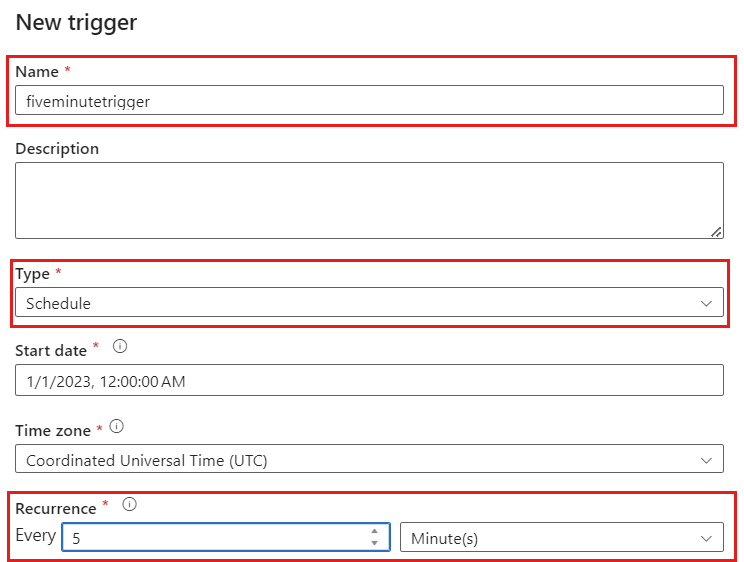
[トリガーの追加] を選択します。 このパイプラインを、ワークロードに適した頻度で実行するようにスケジュールします。 この例では、パイプラインは 5 分ごとに実行するように構成されています。
![新しいパイプラインでの [トリガーの追加] ボタンのスクリーンショット。](media/get-started-change-data-capture/add-trigger.png)
注意
変更データ キャプチャの実行の最小繰り返し期間は 1 分です。
[検証] を選択して、エラーや省略を行っていないことを確認します。 次に、[発行] を選択してパイプラインを発行します。
Azure Cosmos DB 分析ストアの変更データ キャプチャを使用したデータ フローの出力として Azure Blob Storage コンテナーに配置されたデータを確認します。
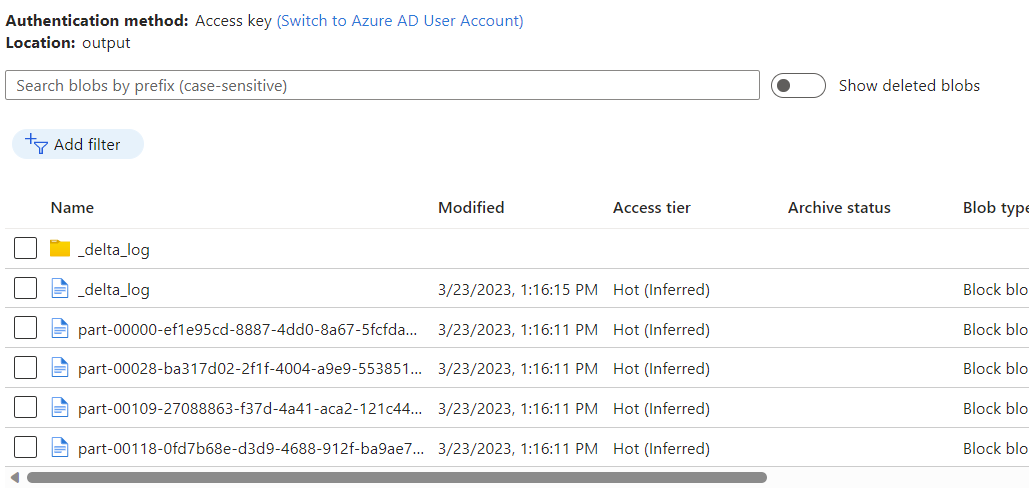
注意
最初のクラスター起動時間は、最大 3 分かかる場合があります。 後続の変更データ キャプチャの実行でクラスターの起動時間を回避するには、データフロー クラスターの Time to Live の値を構成します。 統合ランタイムと TTL の詳細については、「Azure Data Factory の統合ランタイム」を参照してください。
同時実行ジョブ
ソース オプションのバッチ サイズ、またはシンクが変更ストリームの取り込みに時間がかかる状況が、複数のジョブの同時実行の原因になる可能性があります。 この状況を回避するには、パイプライン設定で [コンカレンシー] オプションを 1 に設定して、現在の実行が完了するまで新しい実行がトリガーされないようにします。