Azure Cosmos DB Java SDK v4 のパフォーマンスに関するヒント
適用対象: ![]() NoSQL
NoSQL
重要
この記事のパフォーマンスに関するヒントは、Azure Cosmos DB Java SDK v4 のみを対象としています。 詳細については、Azure Cosmos DB Java SDK v4 のリリース ノート、Maven リポジトリ、Azure Cosmos DB Java SDK v4 のトラブルシューティング ガイドを参照してください。 v4 より前のバージョンを現在使用している場合、v4 へのアップグレードについては、Azure Cosmos DB Java SDK v4 への移行ガイドを参照してください。
Azure Cosmos DB は、高速で柔軟性に優れた分散データベースです。待機時間とスループットが保証されており、シームレスにスケーリングできます。 Azure Cosmos DB でデータベースをスケーリングするために、アーキテクチャを大きく変更したり、複雑なコードを記述したりする必要はありません。 スケールアップとスケールダウンは、API 呼び出しか SDK メソッド呼び出しを 1 回行うだけで簡単に実行できます。 ただし、Azure Cosmos DB にはネットワーク呼び出しによってアクセスするため、Azure Cosmos DB Java SDK v4 を使用するときに最高のパフォーマンスを実現するために、クライアント側の最適化を行うことができます。
データベースのパフォーマンスを向上させる場合は、以下のオプションを検討してください。
ネットワーク
パフォーマンスを確保するために同じ Azure リージョン内にクライアントを併置する
可能であれば、Azure Cosmos DB を呼び出すアプリケーションを Azure Cosmos DB データベースと同じリージョンに配置します。 おおよその比較では、Azure Cosmos DB の呼び出しは、同じリージョン内であれば 1 から 2 ミリ秒以内で完了するのに対し、米国西部と米国東部の間では待ち時間が 50 ミリ秒より長くなります。 要求がクライアントから Azure データセンターの境界まで流れるときに使用されるルートに応じて、この待機時間が要求ごとに異なる可能性があります。 最短の待機時間は、プロビジョニングされた Azure Cosmos DB エンドポイントと同じ Azure リージョン内に呼び出し元アプリケーションを配置することによって実現されます。 使用可能なリージョンの一覧については、「 Azure のリージョン」を参照してください。
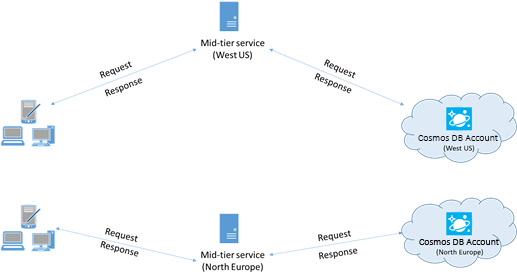
マルチリージョンの Azure Cosmos DB アカウントとやり取りするアプリでは、併置されたリージョンに要求が確実に送信されるように、優先される場所を構成する必要があります。
高速ネットワークを有効にして待機時間と CPU ジッターを削減する
待ち時間と CPU ジッターを減らしてパフォーマンスを最大限に高めるために、手順に従って Windows (選んで手順を参照) または Linux (選んで手順を参照) の Azure VM で高速ネットワークを有効にすることをお勧めします。
高速ネットワークを使用しない場合、Azure VM と他の Azure リソース間を通過する IO は、VM とそのネットワーク カードの間にあるホストと仮想スイッチを介してルーティングされる可能性があります。 データパスにインラインでホストと仮想スイッチがあると、通信チャネルで待機時間とジッターが増加するだけでなく、VM から CPU サイクルが奪われます。 高速ネットワークでは、VM は仲介者なしで NIC と直接やり取りします。 すべてのネットワーク ポリシーの詳細は、ホストと仮想スイッチをバイパスして、NIC のハードウェアで処理されます。 通常、高速ネットワークを有効にすると、待機時間の短縮とスループットの向上だけでなく、より "一貫した" 待機時間と CPU 使用率の削減が期待できます。
制限事項: 高速ネットワークは、VM の OS でサポートされている必要があり、VM が停止され、割り当てが解除されている場合にのみ有効にすることができます。 Azure Resource Manager を使って VM をデプロイすることはできません。 App Service では高速ネットワークが有効になっていません。
詳細については、Windows と Linux の手順を参照してください。
高可用性
Azure Cosmos DB での高可用性の構成に関する一般的なガイダンスについては、Azure Cosmos DB での高可用性に関する記事をご覧ください。
データベース プラットフォームでの適切な基本的設定に加えて、Java SDK 自体に実装できる特定の手法があり、停止シナリオに役立ちます。 2 つの重要な戦略は、しきい値ベースの可用性戦略とパーティション レベルのサーキット ブレーカーです。
これらの手法によって提供される、待ち時間と可用性の特定の課題に対処するための高度なメカニズムは、SDK に既定で組み込まれているリージョンをまたがる再試行機能より優れています。 これらの戦略では、要求とパーティションのレベルで潜在的な問題を事前に管理して、特に高負荷または機能低下の状況で、アプリケーションの回復性とパフォーマンスを大幅に向上させることができます。
しきい値ベースの可用性戦略
しきい値ベースの可用性戦略を使って、セカンダリ リージョンに並列読み取り要求を送信し、最も速い応答を受け入れると、完了までの待ち時間と可用性を向上させることができます。 このアプローチを使うと、アプリケーションのパフォーマンスに対するリージョンの障害や高遅延状態の影響を大幅に軽減できます。 さらに、プロアクティブ接続管理を使用して、現在の読み取りリージョンと優先リモート リージョンの両方で接続とキャッシュをウォームアップすることで、パフォーマンスをさらに向上させることができます。
構成の例:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
しくみ:
初期要求: 時刻 T1 に、プライマリ リージョン (米国東部など) に対して読み取り要求が行われます。 SDK は、最大 500 ミリ秒 (
thresholdの値) まで応答を待ちます。2 回目の要求: 500 ミリ秒以内にプライマリ リージョンから応答がない場合、次の優先リージョン (たとえば、米国東部 2) に並列要求が送信されます。
3 回目の要求: プライマリとセカンダリどちらのリージョンも 600 ミリ秒 (500 ミリ秒 + 100 ミリ秒、
thresholdStepの値) 以内に応答しない場合、SDK は別の並列要求を 3 番目の優先リージョン (米国西部など) に送信します。最速応答の採用: 最初に応答するのがどのリージョンであっても、その応答が受け入れられて、他の並列要求は無視されます。
プロアクティブ接続管理は、優先リージョン間でコンテナーの接続とキャッシュをウォームアップし、複数リージョンのセットアップでのフェールオーバー シナリオまたは書き込みのコールド スタート待機時間を短縮するため便利です。
この戦略を使うと、特定のリージョンが低速または一時的使用不可になるシナリオで待ち時間が大幅に向上しますが、リージョン間の並列要求が必要な場合は、要求ユニットに関するコストが高くなる可能性があります。
Note
1 番目の優先リージョンから一時的なものではないエラー状態コード (ドキュメントが見つからない、認可エラー、競合など) が返された場合、操作自体がフェイル ファストするので、可用性戦略にはこのシナリオでのメリットはありません。
パーティション レベルのサーキット ブレーカー
パーティション レベルのサーキット ブレーカーでは、異常な物理パーティションに対する要求が追跡されてショートサーキットされ、完了までの待ち時間と書き込みの可用性が向上します。 問題があることがわかっているパーティションが回避され、より正常なリージョンに要求がリダイレクトされるので、パフォーマンスが向上します。
構成の例:
パーティション レベルのサーキット ブレーカーを有効にするには:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
利用不可のリージョンをバックグラウンド プロセスで調べる頻度を設定するには:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
パーティションが利用不可のままでいられる期間を設定するには:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
しくみ:
エラーの追跡: SDK は、特定のリージョンの個々のパーティションでターミナル エラー (503、500、タイムアウトなど) を追跡します。
利用不可としてマーク: リージョン内のパーティションが構成されているエラーのしきい値を超えた場合は、"Unavailable" としてマークされます。このパーティションへの後続の要求はショートサーキットされ、他のより正常なリージョンにリダイレクトされます。
自動復旧: バックグラウンド スレッドは、利用不可のパーティションを定期的にチェックします。 一定の期間が経過すると、これらのパーティションは暫定的に "HealthyTentative" としてマークされ、復旧を検証するためのテスト要求が行われます。
正常性の昇格と降格: これらのテスト要求の成功または失敗に基づいて、パーティションの状態は "Healthy" に昇格して戻されるか、もう一度 "Unavailable" に降格されます。
このメカニズムは、パーティションの正常性を継続的に監視するのに役立ち、要求が問題のあるパーティションによって滞ることなく、最小の待ち時間と最大の可用性で処理されるようにします。
Note
パーティションが Unavailable とマークされると、読み取りと書き込みの両方が次の優先リージョンに移動されるため、サーキット ブレーカーは複数リージョン書き込みアカウントにのみ適用されます。 これは、異なるリージョンからの読み取りと書き込みが、同じクライアント インスタンスから提供されるのを防ぐためです。これはアンチパターンになります。
重要
パーティション レベルのサーキット ブレーカーをアクティブにするには、Java SDK バージョン 4.63.0 以降を使う必要があります。
可用性の最適化の比較
しきい値ベースの可用性戦略:
- 利点: セカンダリ リージョンに並列読み取り要求を送信して完了までの待ち時間を短縮し、ネットワーク タイムアウトになる要求を優先させて可用性を向上させます。
- トレードオフ: 並列リージョン間要求が増えるので (しきい値を超えた期間だけですが)、サーキット ブレーカーと比べて余分な RU (要求ユニット) コストが発生します。
- ユース ケース: 待ち時間の短縮が重要であり、ある程度の追加コスト (RU 料金とクライアントの CPU 負荷の両方) が許容される、読み取り量の多いワークロードに最適です。 また、非べき等書き込み再試行ポリシーにオプトインし、アカウントに複数リージョンの書き込みがある場合は、書き込み操作にもメリットがあります。
パーティション レベルのサーキット ブレーカー:
- 利点: 異常なパーティションを回避し、要求をより正常なリージョンにルーティングするので、可用性と待ち時間が向上します。
- トレードオフ: 追加の RU コストは発生しませんが、要求の初期の可用性が若干低下して、ネットワーク タイムアウトが発生する可能性があります。
- ユース ケース: 一貫したパフォーマンスが不可欠な、書き込み量の多いワークロードや混合ワークロードに最適です (特に、断続的に異常になる可能性があるパーティションを扱う場合)。
両方の戦略を併用して、読み取りと書き込みの可用性を高め、完了までの待ち時間を短縮できます。 パーティション レベルのサーキット ブレーカーを使うと、並列要求を実行する必要なしに、レプリカのパフォーマンスが低下する可能性があるシナリオなど、さまざまな一時的障害シナリオを処理できます。 さらに、RU コストが増えてもかまわない場合は、しきい値ベースの可用性戦略を追加すると、完了までの待ち時間がいっそう短くなり、可用性が失われなくなります。
これらの戦略を実装すると、開発者はアプリケーションの回復性を確保し、ハイ パフォーマンスを維持し、リージョンで停止や高遅延の状況が発生しても優れたユーザー エクスペリエンスを提供できます。
リージョン スコープのセッション整合性
概要
一般的な整合性の設定について詳しくは、「Azure Cosmos DB の整合性レベル」をご覧ください。 Java SDK では、複数リージョン書き込みアカウントのセッション整合性をリージョン スコープにして最適化できます。 これにより、クライアント側の再試行が最小限になり、リージョン間レプリケーションの待ち時間が軽減されて、パフォーマンスが向上します。 これは、セッション トークンの管理をグローバルではなくリージョン レベルで行うことによって実現されます。 リージョン スコープのセッション整合性を実装して、アプリケーションの整合性のスコープをより少ないリージョンにできる場合は、リージョン間レプリケーションの遅延と再試行が最小限になり、複数書き込みアカウントでの読み取りと書き込み操作のパフォーマンスと信頼性の向上を実現できます。
メリット
- 待ち時間の短縮: セッション トークンの検証をリージョン レベルにローカル化すると、コストのかかるリージョン間再試行の可能性が低くなります。
- パフォーマンスの向上: リージョンのフェールオーバーとレプリケーションのラグの影響を最小限に抑えて、読み取り/書き込みの一貫性を高め、CPU 使用率を低くします。
- リソース使用率の最適化: 再試行とリージョン間呼び出しの必要性が制限されて、クライアント アプリケーションでの CPU とネットワークのオーバーヘッドが減り、リソース使用率が最適化されます。
- 高可用性: リージョン スコープのセッション トークンが維持されるので、特定のリージョンで待ち時間が長くなったり一時的な障害が発生した場合でも、アプリケーションはスムーズに動作し続けることができます。
- 整合性の保証: 不要な再試行がなくなり、セッション整合性 (書き込みの読み取り、単調読み取り) の保証がより確実に満たされます。
- コスト効率: リージョン間呼び出しの数が減るので、リージョン間のデータ転送に関連するコストが下がる可能性があります。
- スケーラビリティ: グローバル セッション トークンの維持に関連する競合とオーバーヘッドが減るので、アプリケーションはより効率的にスケーリングできます(特に複数リージョンのセットアップ)。
トレードオフ
- メモリ使用量の増加: ブルーム フィルターとリージョン固有のセッション トークン ストレージのために追加のメモリが必要になり、リソースが限られたアプリケーションでは考慮事項になる可能性があります。
- 構成の複雑さ: ブルーム フィルターに関して予想される挿入数と誤検知率の微調整により、構成プロセスに複雑なレイヤーが追加されます。
- 誤検知の可能性: ブルーム フィルターによりリージョン間の再試行は最小限になりますが、それでも誤検知がセッション トークンの検証に影響を与える可能性が若干あります。ただし、その割合は制御できます。 誤検知はグローバル セッション トークンが解決されることを意味し、それにより、ローカル リージョンがこのグローバル セッションに追いついていない場合、リージョン間の再試行の可能性を高くなります。 誤検知が存在する場合でも、セッションの保証は満たされます。
- 適用性: この機能のメリットが最も大きくなるのは、論理パーティションのカーディナリティが高く、定期的に再起動されるアプリケーションの場合です。 論理パーティションが少ないアプリケーションや、再起動があまり行われないアプリケーションでは、大きなメリットがない可能性があります。
しくみ
セッション トークンを設定する
- 要求の完了: 要求が完了した後、SDK はセッション トークンをキャプチャして、リージョンとパーティション キーに関連付けます。
- リージョン レベルのストレージ: セッション トークンは、パーティション キー範囲とリージョン レベルの進行状況の間のマッピングを維持する、入れ子になった
ConcurrentHashMapに格納されます。 - ブルーム フィルター: ブルーム フィルターは、各論理パーティションによってアクセスされたリージョンを追跡し、セッション トークンの検証をローカル化するのに役立ちます。
セッション トークンを解決する
- 要求の初期化: 要求が送信される前に、SDK はセッション トークンの適切なリージョンへの解決を試みます。
- トークン チェック: トークンはリージョン固有のデータに対してチェックされて、要求は確実に最新のレプリカにルーティングされます。
- 再試行ロジック: セッション トークンが現在のリージョン内で検証されない場合、SDK は他のリージョンで再試行しますが、ローカル化されたストレージを使うと、これは頻度が低くなります。
SDK の使用
リージョン スコープのセッション整合性を使って CosmosClient を初期化する方法を次に示します。
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
リージョン スコープのセッション整合性を有効にする
アプリケーションでリージョン スコープのセッション キャプチャを有効にするには、次のシステム プロパティを設定します。
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
ブルーム フィルターを構成する
ブルーム フィルターの予想される挿入数と誤検知率を構成して、パフォーマンスを微調整します。
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
メモリへの影響
次に示すのは、ブルーム フィルターへの異なる予想挿入数での、(SDK によって管理される) 内部セッション コンテナーの保持サイズ (オブジェクトのサイズと、それに依存するもの) です。
| 予想される挿入数 | 偽陽性率 | 保持サイズ |
|---|---|---|
| 10,000 | 0.001 | 21 KB |
| 100,000 | 0.001 | 183 KB |
| 100 万 | 0.001 | 1.8 MB |
| 1,000 万 | 0.001 | 17.9 MB |
| 1 億 | 0.001 | 179 MB |
| 10 億 | 0.001 | 1.8 GB |
重要
リージョン スコープのセッション整合性をアクティブにするには、Java SDK バージョン 4.60.0 以降を使う必要があります。
直接接続とゲートウェイ接続の構成チューニング
直接モードとゲートウェイ モードの接続構成の最適化については、Java SDK v4 の接続構成を調整する方法を参照してください。
SDK の使用
- 最新の SDK をインストールする
Azure Cosmos DB SDK は、最適なパフォーマンスを提供するために頻繁に改善されています。 最新の SDK の改善点を確認するには、Azure Cosmos DB SDK を参照してください。
各 Azure Cosmos DB クライアント インスタンスはスレッドセーフであり、効率的な接続管理とアドレスのキャッシュが実行されます。 Azure Cosmos DB クライアントによる効率的な接続管理とパフォーマンスの向上を実現するために、アプリケーションの有効期間中は、Azure Cosmos DB クライアントの単一のインスタンスを使用することを強くお勧めします。
CosmosClient を作成するときに、明示的に設定されていない場合に使用される既定の整合性は "Session (セッション) " です。 アプリケーション ロジックで "Session (セッション) " 整合性が必要とされない場合は、"Consistency (整合性) " を "Eventual (最終的) " に設定します。 注: Azure Cosmos DB 変更フィード プロセッサを使用するアプリケーションでは、少なくとも "セッション" 整合性を使用することをお勧めします。
- 非同期 API を使用してプロビジョニングされたスループットを最大化する
Azure Cosmos DB Java SDK v4 には、同期と非同期の 2 つの API がバンドルされています。 大まかに言うと、非同期 API は SDK 機能を実装し、同期 API は非同期 API のブロッキング呼び出しを行うシン ラッパーです。 これは、非同期のみであった以前の Azure Cosmos DB Async Java SDK v2 や、同期のみで、別の実装を備えていた以前の Azure Cosmos DB Sync Java SDK v2 とは対照的です。
API の選択は、クライアントの初期化中に決定されます。CosmosAsyncClient では非同期 API がサポートされ、CosmosClient では同期 API がサポートされます。
非同期 API では非ブロッキング IO を実装しており、Azure Cosmos DB に要求を発行するときにスループットを最大化することが目標である場合に最適な選択肢です。
各要求への応答でブロックする API が必要な場合や、同期操作がアプリケーションの主要パラダイムである場合は、同期 API の使用が適切な選択と言えます。 たとえば、スループットが重要でないのであれば、マイクロサービス アプリケーションで Azure Cosmos DB にデータを保持する場合に、同期 API を使用できます。
同期 API では要求の応答時間の増加によってスループットが低下し、非同期 API ではハードウェアの全帯域幅の機能を飽和させる可能性があることに注意してください。
同期 API を使用する場合、地理的な併置によって、より高いより一貫したスループットが得られますが (「パフォーマンスを確保するために同じ Azure リージョン内にクライアントを併置する」を参照)、非同期 API で達成可能なスループットを超えることはやはり期待できません。
一部のユーザーは、Azure Cosmos DB Java SDK v4 の非同期 API を実装するために使用される Reactive Streams フレームワークである、Project Reactor に詳しくない場合もあります。 これが懸念される場合は、入門用の「Reactor pattern guide (Reactor パターン ガイド)」を読んでから、こちらの「Introduction to Reactive Programming (Reactive プログラミングの概要)」を読んで理解を深めてください。 非同期インターフェイスで Azure Cosmos DB を既に使用しており、使用していた SDK が Azure Cosmos DB Async Java SDK v2 の場合、ReactiveX/RxJava を使い慣れているかもしれませんが、Project Reactor での変更点がわからない可能性があります。 その場合は、「Reactor vs.RxJava guide (Reactor と RxJava の比較ガイド)」を参照して理解を深めてください。
次のコード スニペットは、それぞれ非同期 API または同期 API 操作で Azure Cosmos DB クライアントを初期化する方法を示しています。
Java SDK V4 (Maven com.azure::azure-cosmos) 非同期 API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- クライアント ワークロードをスケールアウトする
高いスループット レベルでテストを行っている場合、コンピューターが CPU 使用率またはネットワーク使用率の上限に達したことでクライアント アプリケーションがボトルネックになることがあります。 この状態に達しても、クライアント アプリケーションを複数のサーバーにスケールアウトすることで引き続き同じ Azure Cosmos DB アカウントで対応できます。
低待機時間を維持するには、経験則として、特定のサーバーで CPU 使用率が 50% を超えないようにします。
- 適切なスケジューラを使用する (イベント ループの IO Netty スレッドを盗まない)
Azure Cosmos DB Java SDK の非同期機能は、netty 非ブロッキング IO に基づいています。 SDK は、固定数の IO netty イベント ループ スレッド (コンピューターの CPU コアと同じ数) を使って IO 操作を実行します。 API によって返される Flux は、共有 IO イベント ループ netty スレッドの 1 つに結果を出力します。 したがって、共有 IO イベント ループ netty スレッドをブロックしないことが重要です。 IO イベント ループ netty スレッドで CPU を大量に使う処理を行ったり、操作をブロックしたりすると、デッドロックが発生したり、SDK のスループットが大幅に低下したりする可能性があります。
たとえば、次のコードは、イベント ループ IO netty スレッドで CPU を大量に使う処理を実行します。
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
結果を受け取った後、イベント ループ IO netty スレッドでは、結果に対する CPU 負荷の高い操作の実行を避ける必要があります。 次に示すように、代わりに独自のスケジューラを用意して、処理を実行するための独自のスレッドを提供できます (import reactor.core.scheduler.Schedulers が必要です)。
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
作業の種類に基づいて、作業に適した既存の Reactor Scheduler を使用する必要があります。 「Schedulers」をご覧ください。
Project Reactor のスレッドとスケジューリングのモデルをさらに理解するには、Project Reactor によるこのブログ記事を参照してください。
Azure Cosmos DB Java SDK v4 の詳細については、GitHub の Azure SDK for Java 単一リポジトリの Azure Cosmos DB ディレクトリに関する記事を参照してください。
- アプリケーションのログ設定を最適化する
さまざまな理由から、高い要求スループットを生成しているスレッドにログを追加する必要があります。 このスレッドによって生成される要求でコンテナーのプロビジョニングされたスループットを完全に飽和させることが目的である場合は、ログの最適化によってパフォーマンスを大幅に向上させることができます。
- 非同期ロガーを構成する
同期ロガーの待機時間は、要求を生成するスレッドの全体的な待機時間の計算に必ず含まれます。 高パフォーマンスのアプリケーション スレッドからログのオーバーヘッドを分離するために、log4j2 などの非同期ロガーが推奨されます。
- netty のログを無効にする
netty ライブラリのログは量が多いので、CPU コストが増えないようにオフにする必要があります (構成のサインインを抑制するだけでは不十分な場合があります)。 デバッグ モードではない場合は、netty のログを完全に無効にします。 したがって、Log4j を使って netty からの org.apache.log4j.Category.callAppenders() によって発生する追加の CPU コストを削除するには、コードベースに次の行を追加します。
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- OS の開かれるファイルのリソース制限
Red Hat などの一部の Linux システムには、開かれるファイルの数、したがって合計接続数に上限があります。 現在の制限を確認するには、次のコマンドを実行します。
ulimit -a
構成されている接続プール サイズおよび OS によって開かれる他のファイルのために十分なスペースがあるよう、開かれるファイル (nofile) の値は十分な大きさである必要があります。 大きい接続プール サイズに対応できるように変更できます。
limits.conf ファイルを開きます。
vim /etc/security/limits.conf
次の行を追加または変更します。
* - nofile 100000
- ポイント書き込みでパーティション キーを指定する
ポイント書き込みのパフォーマンスを向上させるには、次に示すように、ポイント書き込み API 呼び出しで項目のパーティション キーを指定します。
Java SDK V4 (Maven com.azure::azure-cosmos) 非同期 API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
項目インスタンスだけを指定した場合は次のようになります。
後者はサポートされていますが、アプリケーションに待機時間が追加されます。SDK が項目を解析し、パーティション キーを抽出する必要があります。
クエリ操作
クエリ操作については、クエリのパフォーマンスのヒントに関するページを参照してください。
インデックス作成ポリシー
- インデックス作成から未使用のパスを除外して書き込みを高速化する
Azure Cosmos DB のインデックス作成ポリシーでは、インデックス作成パス (setIncludedPaths および setExcludedPaths) を使って、インデックス作成に含めるか除外するドキュメント パスを指定できます。 インデックス作成コストはインデックス付きの一意のパスの数に直接関係するため、パスのインデックス作成を使用すると、クエリ パターンが事前にわかっているシナリオで書き込みパフォーマンスが向上し、インデックス ストレージを削減できます。 たとえば、次のコードは、ワイルドカード "*" を使用して、ドキュメントのセクション全体 (サブツリーとも呼ばれる) をインデックス作成から追加および除外する方法を示しています。
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
詳細については、Azure Cosmos DB インデックス作成ポリシーに関するページをご覧ください。
スループット
- 測定と調整によって 1 秒あたりの要求ユニットの使用量を削減する
Azure Cosmos DB には、UDF、ストアド プロシージャ、トリガーを使ったリレーショナル クエリや階層クエリなど、さまざまなデータベース操作が用意されています。これらの操作はすべて、データベース コレクション内のドキュメントに対して実行できます。 これらの操作のそれぞれに関連付けられたコストは、操作を完了するために必要な CPU、IO、およびメモリに応じて異なります。 ハードウェア リソースの管理について考える代わりに、各種のデータベース操作を実行しアプリケーション要求を処理するのに必要なリソースに関する単一の測定単位として要求単位 (RU) を考えることができます。
コンテナーごとに設定された要求ユニットの数に基づいて、スループットをプロビジョニングします。 要求単位の消費は、1 秒あたりのレートとして評価されます。 コンテナーのプロビジョニング済み要求ユニット レートを超過したアプリケーションは、レートがそのコンテナーにプロビジョニングされているレベルを下回るまで制限されます。 アプリケーションでより高いスループットが必要になった場合は、追加の要求ユニットをプロビジョニングしてスループットを増やすことができます。
クエリの複雑さは、操作で消費される要求ユニット数に影響します。 述語の数、述語の特性、UDF 数、ソース データ セットのサイズのすべてがクエリ操作のコストに影響します。
操作 (作成、更新、または削除) のオーバーヘッドを測定するには、x-ms-request-charge ヘッダーを調べて、これらの操作で使われる要求ユニット数を測定します。 ResourceResponse<T> または FeedResponse<T> で同等の RequestCharge プロパティを確認することもできます。
Java SDK V4 (Maven com.azure::azure-cosmos) 非同期 API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
このヘッダーで返される要求の使用量は、プロビジョニングしたスループットの一部です。 たとえば、2000 RU/秒がプロビジョニングされていて、上記のクエリで 1 KB のドキュメントを 1,000 個返した場合、この操作のコストは 1000 になります。 そのため、後続の要求をレート制限する前に、サーバーは 1 秒以内にこのような要求を 2 つだけ受け付けます。 詳細については、要求ユニットに関する記事および要求ユニット計算ツールのページを参照してください。
- レート制限と大きすぎる要求レートに対処する
クライアントがアカウントの予約済みスループットを超えようとしても、サーバーでパフォーマンスの低下が発生することはなく、予約済みのレベルを超えてスループット容量が使用されることもありません。 サーバーはいち早く RequestRateTooLarge (HTTP 状態コード 429) で要求を終了させ、要求を再試行するまでにユーザーが待機しなければならない時間 (ミリ秒) を示す x-ms-retry-after-ms ヘッダーを返します。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK はすべてこの応答を暗黙的にキャッチし、サーバーが指定した retry-after ヘッダーを優先して要求を再試行します。 アカウントに複数のクライアントが同時アクセスしている状況でなければ、次回の再試行は成功します。
複数のクライアントが要求レートを常に上回った状態で累積的に動作している場合、現在クライアントによって内部的に 9 に設定されている既定の再試行回数では不十分な可能性があります。この場合、クライアントは状態コード 429 を含む CosmosClientException をアプリケーションにスローします。 デフォルトの再試行カウントは、ThrottlingRetryOptions インスタンス上の setMaxRetryAttemptsOnThrottledRequests() を使って変更できます。 既定では、要求レートを超えて要求が続行されている場合に、30 秒の累積待機時間を過ぎると、状態コード 429 を含む CosmosClientException が返されます。 これは、現在の再試行回数が最大再試行回数 (既定値の 9 またはユーザー定義の値) より少ない場合でも発生します。
自動再試行動作により、ほとんどのアプリケーションの回復性とユーザービリティが向上しますが、パフォーマンス ベンチマークの実行時 (特に待機時間の測定時) に問題が生じることがあります。 実験でサーバー スロットルが発生し、クライアント SDK によって警告なしに再試行が行われると、クライアントが監視する待機時間が急増します。 パフォーマンスの実験中に待機時間が急増するのを回避するには、各操作で返される使用量を測定し、予約済みの要求レートを下回った状態で要求が行われていることを確認します。 詳細については、 要求ユニットに関する記事を参照してください。
- スループットを向上させるためにサイズの小さいドキュメントに合わせて設計する
特定の操作の要求の使用量 (要求処理コスト) は、ドキュメントのサイズに直接関係します。 サイズの大きいドキュメントの操作は、サイズの小さいドキュメントの操作よりもコストがかかります。 項目のサイズを最大 1 KB 程度にするようにアプリケーションとワークフローを設計するのが理想的です。 待ち時間の影響を受けやすいアプリケーションでは、サイズの大きい項目は避ける必要があります。数 MB のドキュメントはアプリケーションの速度を低下させます。
次のステップ
スケーリングと高パフォーマンスのためのアプリケーションの設計について詳しくは、「Azure Cosmos DB でのパーティション分割とスケーリング」をご覧ください。
Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コアまたは vCPU を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください