マッピング データ フローのスキーマの誤差
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
スキーマの誤差は、ソースのメタデータが頻繁に変更されるケースです。 フィールド、列、および型は、その場で追加、削除、または変更できます。 スキーマの誤差に対処しないと、アップストリームのデータ ソースの変更に対して、データ フローが脆弱になります。 通常、受信列およびフィールドが変更された場合、ETL パターンは、それらのソース名に関連している傾向があるため、失敗します。
スキーマの誤差の影響を受けないようにするには、データ エンジニアが、データ フロー ツールの機能で次のことができることが重要です。
- フィールド名、データ型、値、およびサイズを変更できるソースを定義する。
- フィールドおよび値をハードコーディングするのではなく、データのパターンを操作できる変換パラメーターを定義する。
- 名前付きフィールドを使用するのではなく、受信フィールドに一致するパターンを認識する式を定義する。
Azure Data Factory は、実行ごとに変わる柔軟なスキーマをネイティブでサポートしているため、データ フローを再コンパイルしなくても、汎用的なデータ変換ロジックを構築できます。
フロー全体を通じてスキーマの誤差を受け入れるには、データ フロー内でアーキテクチャの決定を行う必要があります。 これを行うと、ソースのスキーマの変更の影響を防ぐことができます。 ただし、データ フロー全体を通じて、列および型の早いバインディングは失われます。 Azure Data Factory では、スキーマの誤差のフローは、遅いバインディング フローとして扱われます。そのため、変換を作成する場合、フロー全体を通じて、スキーマ ビュー内で誤差のある列名は使用できません。
この動画では、データ フローのスキーマ ドリフト機能を使用して Azure Data Factory または Azure Synapse Analytics パイプラインで簡単に構築できる複雑なソリューションの概要について説明します。 この例では、柔軟なデータベース スキーマに基づいて再利用可能なパターンを構築します。
ソースのスキーマの誤差
ソース定義からデータフローに進む列が、ソース プロジェクション内に存在しない場合は、"誤差" として定義されます。 ソース変換にある [プロジェクション] タブから、ご自身のソース プロジェクションを表示できます。 ご自身のソースに対するデータセットを選択すると、このサービスによって自動的にデータセットからスキーマが取得され、そのデータセット スキーマ定義からプロジェクションが作成されます。
ソース変換では、スキーマの誤差は、データセット スキーマで定義されていない列の読み取りと定義されます。 スキーマの誤差を有効にするには、ソース変換で [Allow schema drift](スキーマの誤差を許可する) をオンにします。
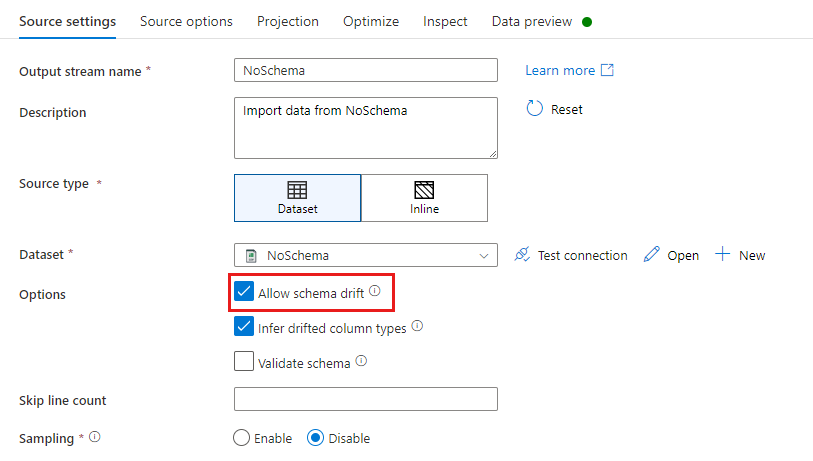
スキーマの誤差が有効な場合、すべての受信フィールドは実行中にソースから読み取られ、フロー全体を通じてシンクに渡されます。 既定では、"誤差の列" と呼ばれる新しく検出されたすべての列は文字列データ型として受信されます。 データ フローで誤差の列のデータ型を自動的に推定する場合は、ソース設定で [Infer drifted column types](誤差の列の種類を推定する) をオンにします。
シンクのスキーマの誤差
シンク変換では、シンク データ スキーマで定義されている内容の上に追加の列を記述するときにスキーマの誤差があります。 スキーマの誤差を有効にするには、シンク変換で [Allow schema drift](スキーマの誤差を許可する) をオンにします。
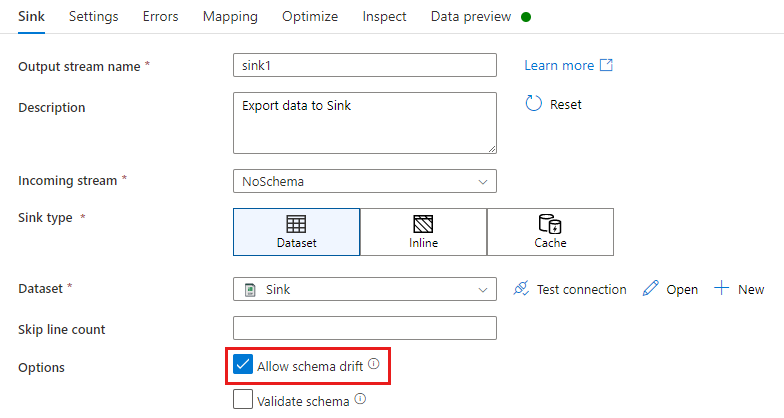
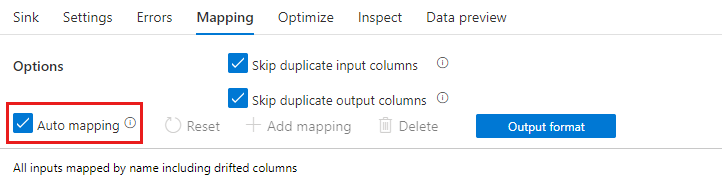
スキーマの誤差が有効な場合は、[マッピング] タブの [Auto-mapping](自動マッピング) スライダーがオンであることを確認します。 このスライダーがオンの場合、すべての受信列が宛先に書き込まれます。 それ以外の場合、誤差の列を書き込むには、ルールベースのマッピングを使用する必要があります。
誤差の列の変換
データ フローに誤差の列がある場合は、次の方法を使用して変換でそれらにアクセスできます。
- 名前または位置番号で列を明示的に参照するには、
byPosition式とbyName式を使用します。 - 名前、ストリーム、位置、原点、または型の任意の組み合わせで一致するように、派生列または集計変換に列パターンを追加します
- パターンを使用して誤差の列と列の別名と一致するように、選択またはシンク変換にルールベースのマッピングを追加します
列パターンを実装する方法の詳細については、「マッピング データ フローの列パターン」を参照してください。
誤差の列のクイック アクションをマップする
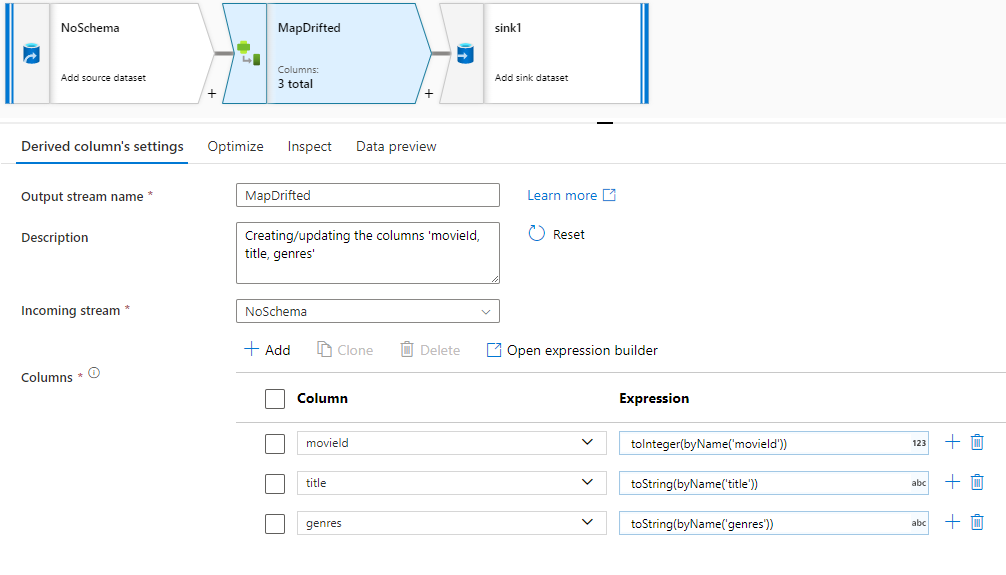
誤差の列を明示的に参照するには、データ プレビューのクイック アクションを使用して、これらの列のマッピングをすばやく生成できます。 デバッグ モードがオンになったら、[データ プレビュー] タブに移動し、 [更新] をクリックしてデータ プレビューをフェッチします。 データ ファクトリによって誤差の列が存在することが検出された場合は、 [Map Drifted](誤差のマップ) をクリックし、スキーマ ビューのダウンストリームにあるすべての誤差の列を参照できる派生列を生成できます。
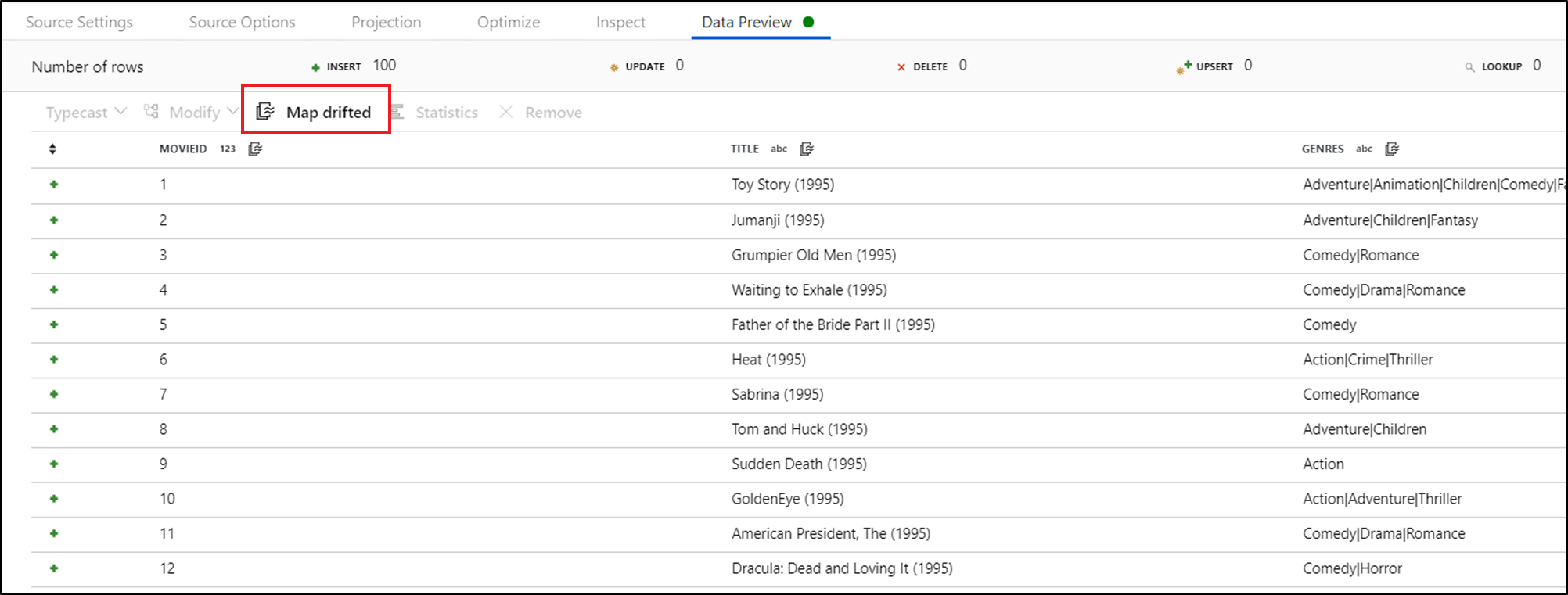
生成された派生列変換では、各誤差の列は検出された名前とデータ型にマップされます。 上のデータ プレビューでは、列 'movieId' が整数として検出されています。 [Map Drifted](誤差のマップ) をクリックすると、movieId は派生列で toInteger(byName('movieId')) と定義され、ダウンストリームの変換のスキーマ ビューに含まれます。
関連するコンテンツ
データ フロー式言語には、"byName" や "byPosition" など、列パターンとスキーマ誤差用の追加機能があります。