マッピング データ フローでのピボット変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
ピボット変換を使用して、1 つの列の一意の行値から複数の列を作成します。 ピボットは、グループ化列を選択し、集計関数を使用してピボット列を生成する集計変換です。
構成
ピボット変換には、グループ化列、ピボット キー、およびピボットされた列の生成方法という 3 つの異なる入力が必要です
グループ化
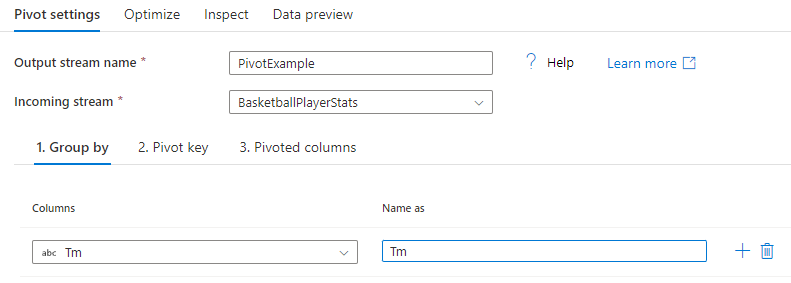
ピボットされた列を集計する列を選択します。 出力データは、同じグループ化の値を持つすべての行を 1 つの行にグループ化します。 ピボットされた列で行われる集計は、各グループに対して行われます。
このセクションは省略可能です。 グループ化列が選択されていない場合は、データ ストリーム全体が集計され、1 つの行だけが出力されます。
ピボット キー
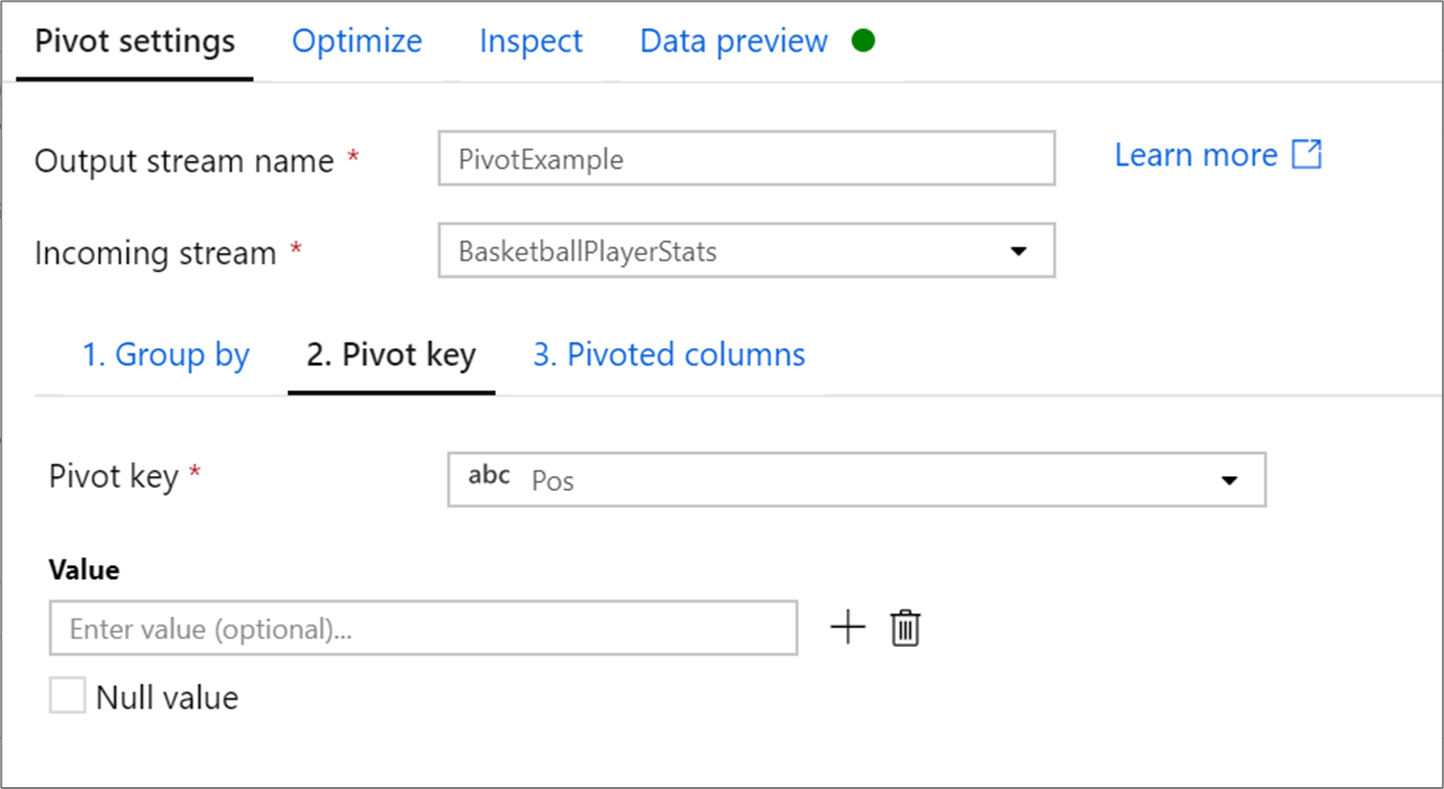
ピボット キーは、行の値が新しい列にピボットされる列です。 既定では、ピボット変換によって、一意の行値ごとに新しい列が作成されます。
[Value](値) というラベルが付いたセクションには、ピボットする特定の行値を入力できます。 このセクションに入力された行値だけがピボットされます。 [Null value](Null 値) を有効にすると、列の null 値に対するピボットされた列が作成されます。
ピボットされた列
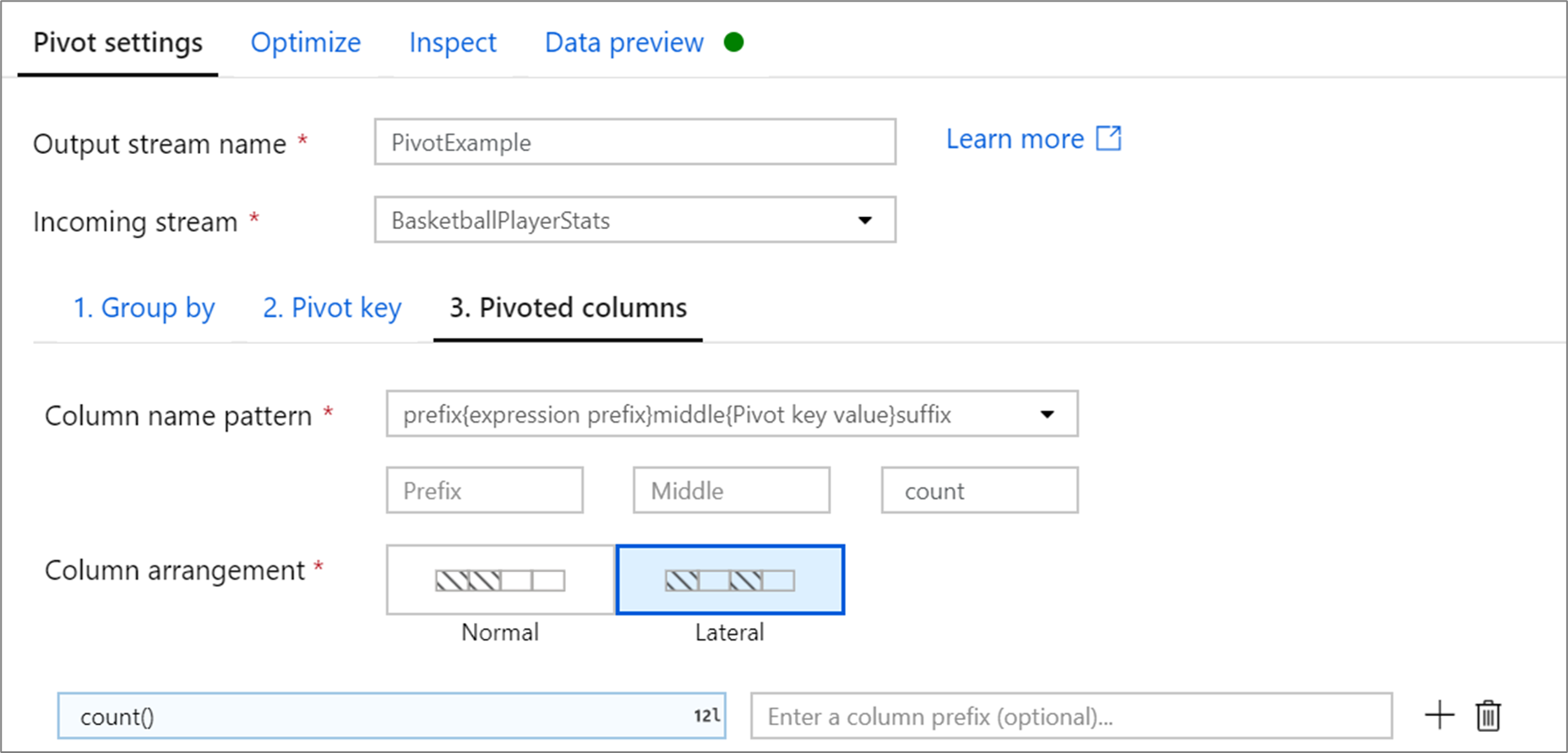
列になる一意のピボット キー値ごとに、各グループの集計された行値を生成します。 ピボット キーごとに複数の列を作成できます。 各ピボット列には、少なくとも 1 つの集計関数が含まれている必要があります。
[Column name pattern](列名のパターン): 各ピボット列の列名の書式を設定する方法を選択します。 出力された列名は、ピボット キー値、列プレフィックス、および省略可能なプレフィックス、サフィックス、中間文字を組み合わせたものになります。
[Column arrangement](列の配置): ピボット キーごとに複数のピボット列を生成する場合は、列の順序付け方法を選択します。
[Column prefix](列プレフィックス): ピボット キーごとに複数のピボット列を生成する場合は、各列の列プレフィックスを入力します。 ピボットされた列が 1 つしかない場合、この設定は省略可能です。
ヘルプ グラフィック
次のヘルプ グラフィックは、さまざまなピボット コンポーネントがどのように相互に作用しているかを示しています。

ピボットのメタデータ
ピボット キー構成に値が指定されていない場合、ピボットされた列は実行時に動的に生成されます。 ピボットされた列の数は、一意のピボット キー値の数にピボット列の数を乗算した値と等しくなります。 この数は変わる可能性があるため、UX は [Inspect](検査) タブに列のメタデータを表示せず、列の反映は行われません。 これらの列を変換するには、マッピング データ フローの列パターン機能を使用します。
特定のピボット キー値が設定されている場合、ピボットされた列はメタデータに表示されます。 列名は、検査とシンク マッピングで利用可能になります。
誤差のある列からメタデータを生成する
ピボットでは、行の値に基づいて動的に新しい列名が生成されます。 これらの新しい列は、後でデータ フローで参照できるメタデータに追加できます。 これを行うには、データ プレビューで [Map Drifted](誤差のマップ) クイック アクションを使用します。

ピボットされた列のシンク
ピボットされた列は動的ですが、宛先のデータ ストアに書き込むことができます。 シンク設定で、 [Allow Schema Drift](スキーマの誤差を許可) を有効にします。 これにより、メタデータに含まれていない列を書き込むことができます。 列のメタデータ内の新しい動的な名前は表示されませんが、スキーマの誤差のオプションによってデータを取得することができます。
元のフィールドを再結合する
ピボット変換では、グループ化列とピボットされた列だけが射影されます。 出力データに他の入力列を含めたい場合は、自己結合パターンを使用します。
データ フローのスクリプト
構文
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
例
構成セクションに表示される画面には、次のデータ フロー スクリプトがあります。
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
関連するコンテンツ
列の値を行の値に変換するピボット解除変換を試します。