データ フローを使用したデータ レイクへのファイル書き込みのベスト プラクティス
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルでは、データ フローを使用して ADLS Gen2 または Azure Blob Storage にファイルを書き込むときに適用できるベスト プラクティスについて説明します。 Parquet ファイルを読み取り、その結果をフォルダーに格納するには、Azure Blob Storage アカウントまたは Azure Data Lake Store Gen2 アカウントにアクセスする必要があります。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
- Azure ストレージ アカウント。 ADLS ストレージを、ソースとシンクのデータ ストアとして使用します。 ストレージ アカウントがない場合の作成手順については、Azure のストレージ アカウントの作成に関するページを参照してください。
このチュートリアルのステップでは、次が前提となっています
Data Factory の作成
この手順では、データ ファクトリを作成し、Data Factory UX を開いて、データ ファクトリにパイプラインを作成します。
Microsoft Edge または Google Chrome を開きます。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
a. [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
b. [新規作成] を選択し、リソース グループの名前を入力します。リソース グループの詳細については、リソース グループを使用した Azure リソースの管理に関する記事を参照してください。
[バージョン] で、 [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、その旨が通知センターに表示されます。 [リソースに移動] を選択して、Data factory ページに移動します。
[Author & Monitor]\(作成と監視\) を選択して、別のタブで Data Factory (UI) を起動します。
データ フロー アクティビティが含まれるパイプラインの作成
この手順では、データ フロー アクティビティが含まれるパイプラインを作成します。
Azure Data Factory のホーム ページで、 [Orchestrate](調整) を選択します。
パイプラインの [全般] タブで、パイプラインの名前として「DeltaLake」と入力します。
ファクトリの上部のバーで、 [Data Flow のデバッグ] スライダーをオンにスライドします。 デバッグ モードを使用すると、ライブ Spark クラスターに対する変換ロジックの対話型テストが可能になります。 Data Flow クラスターのウォームアップには 5 から 7 分かかるため、ユーザーが Data Flow の開発を計画している場合は、最初にデバッグを有効にすることをお勧めします。 詳細については、デバッグ モードに関するページを参照してください。

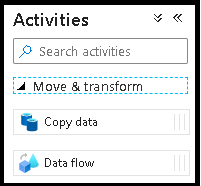
[アクティビティ] ウィンドウで、 [移動と変換] アコーディオンを展開します。 ウィンドウから Data Flow アクティビティをパイプライン キャンバスにドラッグ アンド ドロップします。
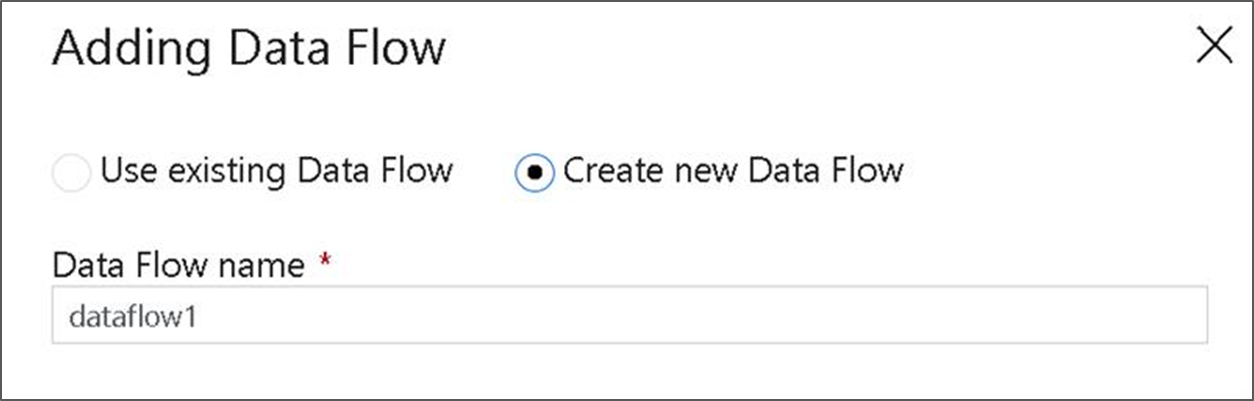
[Data Flow の追加] ポップアップで、 [新しい Data Flow の作成] を選択し、データ フローに DeltaLake という名前を付けます。 終了したら、[完了] をクリックします。
データ フロー キャンバスでの変換ロジックの作成
ソース データをすべて取得し (このチュートリアルでは、Parquet ファイル ソースを使用します)、シンク変換を使用して、データ レイク ETL に最も効果的なメカニズムで Parquet 形式のデータを配置します。

チュートリアルの目標
- 新しいデータ フローで任意のソース データセットを選択する 1. データ フローを使用してシンク データセットを効果的にパーティション分割する
- ADLS Gen2 レイク フォルダーにパーティション分割されたデータを配置する
空のデータ フロー キャンバスから開始する
まず、ADLS Gen2 のデータ配置用に、以下で説明する各メカニズムのデータ フロー環境を設定してみましょう
- [ソース変換] をクリックします。
- 下部パネルのデータセットの横にある [新規] ボタンをクリックします。
- サブネットを選択するか、新しいものを作成します。 このデモでは、User Data という Parquet データセットを使用します。
- 派生列変換を追加します。 ここでは、必要なフォルダー名を動的に設定する方法として使用します。
- シンク変換を追加します。
階層フォルダーの出力
データ内で一意の値を使用して、レイク内のデータをパーティション分割するためのフォルダー階層を作成することは非常に一般的です。 これは、レイクおよび Spark (データ フローの背後にあるコンピューティング エンジン) でデータを整理して処理するために非常に最適な方法です。 ただし、この方法で出力を整理すると、パフォーマンスがわずかに低下します。 シンクでは、このメカニズムを使用すると、パイプラインの全体的なパフォーマンスがわずかに低下することが予想されます。
- データ フロー デザイナーに戻り、先に作成したデータ フローを編集します。 [シンク変換] をクリックします。
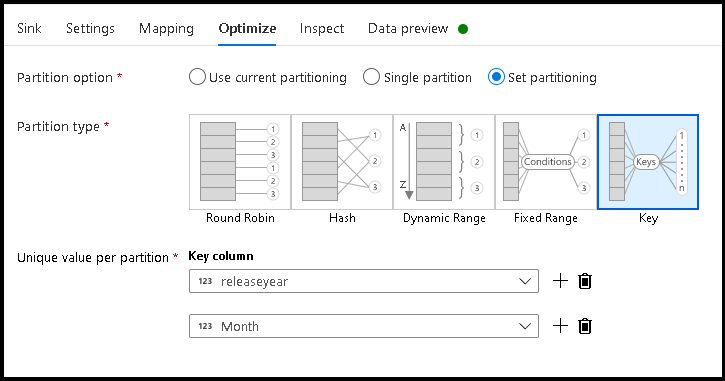
- [最適化] > [パーティション分割の設定] > [キー] の順にクリックします
- 階層フォルダー構造を設定するために使用する列を選択します。
- 下の例では、フォルダー名の列として年と月を使用しています。 結果として、フォルダーの形式は
releaseyear=1990/month=8になります。 - データ フロー ソース内のデータ パーティションにアクセスする場合は、
releaseyearの上の最上位フォルダーのみをポイントし、後続の各フォルダーにワイルドカード パターン (例:**/**/*.parquet) を使用します - データ値を操作する場合、またはフォルダー名の合成値を生成する必要がある場合でも、派生列変換を使用して、フォルダー名に使用する値を作成します。
データ値としてフォルダーに名前を付ける
キーや値のパーティション分割と同じベネフィットを得られない ADLS Gen2 を使用したレイク データに対し、わずかにパフォーマンスに優れたシンク手法が Name folder as column data です。 階層構造のキーのパーティション分割スタイルを使用すると、データ スライスを簡単に処理できますが、この手法はデータをより迅速に書き込むことができるフラット化されたフォルダー構造です。
- データ フロー デザイナーに戻り、先に作成したデータ フローを編集します。 [シンク変換] をクリックします。
- [最適化] > [パーティション分割の設定] > [Use current partitioning](現在のパーティション分割を使用) の順にクリックします。
- [設定] > [列データでフォルダーに名前を付ける] の順にクリックします。
- フォルダー名を生成するために使用する列を選択します。
- データ値を操作する場合、またはフォルダー名の合成値を生成する必要がある場合でも、派生列変換を使用して、フォルダー名に使用する値を作成します。
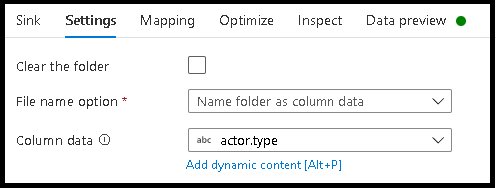
データ値としてファイル名に名前を付ける
上記のチュートリアルに記載されている手法は、データ レイクにフォルダーのカテゴリを作成するための優れたユース ケースです。 これらの手法によって採用されている既定のファイル命名スキームは、Spark 実行プログラムのジョブ ID を使用することです。 場合によっては、データ フロー テキスト シンクで出力ファイルの名前を設定する必要があります。 この手法は、小さなファイルを使用する場合にのみ推奨されます。 パーティション ファイルを 1 つの出力ファイルにマージするプロセスは、実行時間の長いプロセスです。
- データ フロー デザイナーに戻り、先に作成したデータ フローを編集します。 [シンク変換] をクリックします。
- [最適化] > [パーティション分割の設定] > [単一パーティション] の順にクリックします。 これは単一パーティションの要件であり、ファイルがマージされると実行プロセスにボトルネックが作成されます。 このオプションは、小さなファイルに対してのみ推奨されます。
- [設定] > [列データでファイルに名前を付ける] の順にクリックします。
- ファイル名を生成するために使用する列を選択します。
- データ値を操作する場合、またはファイル名の合成値を生成する必要がある場合でも、派生列変換を使用して、ファイル名に使用する値を作成します。
関連するコンテンツ
データ フロー シンクの詳細を確認する。