Azure Databricks ジョブでの dbt 変換を使用する
dbt Core プロジェクトは Azure Databricks ジョブのタスクとして実行できます。 dbt Core プロジェクトをジョブ タスクとして実行すると、次の Azure Databricks ジョブ機能を利用できます。
- dbt タスクを自動化し、dbt タスクを含むワークフローをスケジュールする。
- dbt 変換を監視し、変換の状態に関する通知を送信する。
- ワークフローに他のタスクと共に dbt プロジェクトを含める。 たとえば、ワークフローが自動ローダーを使用してデータを取り込み、dbt を使用してデータを変換し、ノートブック タスクを使用してデータを分析できます。
- ログ、結果、マニフェスト、構成など、ジョブ実行からの成果物の自動アーカイブ。
dbt Core の詳細については、dbt のドキュメントを参照してください。
開発と実稼働のワークフロー
Databricks では、Databricks SQL ウェアハウスに対して dbt プロジェクトを開発することをお勧めします。 Databricks SQL ウェアハウスを使用すると、dbt が生成した SQL をテストし、SQL ウェアハウスのクエリ履歴を使用して、dbt が生成したクエリをデバッグできます。
実稼働で dbt 変換を実行するには、Databricks ジョブで dbt タスクを使用することをお勧めします。 既定では、dbt タスクは Azure Databricks コンピューティングを使用して dbt Python プロセスを実行し、選択した SQL ウェアハウスに対して dbt が生成した SQL を実行します。
dbt 変換は、サーバーレス SQL ウェアハウスまたはプロ SQL ウェアハウス、Azure Databricks コンピューティング、またはその他の dbt がサポートされているウェアハウスで実行できます。 この記事では、最初の 2 つのオプションと例について説明します。
ワークスペースが Unity カタログ対応で、サーバーレス ジョブが有効になっている場合、既定では、ジョブはサーバーレス コンピューティングで実行されます。
Note
SQL ウェアハウスに対して dbt モデルを開発し、実稼働環境の Azure Databricks コンピューティングでそれらを実行すると、パフォーマンスと SQL 言語のサポートで微妙な差が発生することがあります。 Databricks では、コンピューティングと SQL ウェアハウスで同じバージョンの Databricks Runtime を使用することをお勧めします。
要件
dbt Core と
dbt-databricksパッケージを使用して開発環境で dbt プロジェクトを作成して実行する方法については、「dbt Core への接続」を参照してください。Databricks では、dbt-spark パッケージではなく dbt-databricks パッケージをお勧めします。 dbt-databricks パッケージは、Databricks 用に最適化された dbt-spark のフォークです。
Azure Databricks ジョブで dbt プロジェクトを使用するには、Databricks Git フォルダーとの Git 統合を設定する必要があります。 DBFS から dbt プロジェクトを実行することはできません。
サーバーレスまたはプロの SQL ウェアハウスを有効にする必要があります。
Databricks SQL のエンタイトルメントが必要です。
最初の dbt ジョブを作成して実行する
次の例では jaffle_shop プロジェクトを使用します。これは、dbt のコア コンセプトを示すサンプル プロジェクトです。 jaffle shop プロジェクトを実行するジョブを作成するには、以下のステップに従います。
Azure Databricks のランディング ページに移動し、次のいずれかの操作を行います。
- サイド バーの
![[ワークフロー] アイコン](../../_static/images/icons/workflows-icon.png) [ワークフロー] をクリックし、[
[ワークフロー] をクリックし、[![[ジョブの作成] ボタン](../../_static/images/jobs/create-job.png) ] をクリックします。
] をクリックします。 - サイド バーで、
 [新規] をクリックし、[ジョブ] を選択します。
[新規] をクリックし、[ジョブ] を選択します。
- サイド バーの
[タスク] タブにあるタスク テキスト ボックスで、[ジョブの名前を追加...] を自分のジョブ名に置き換えます。
[タスク名] にタスクの名前を入力します。
[種類] でタスクの種類として dbt を選択します。
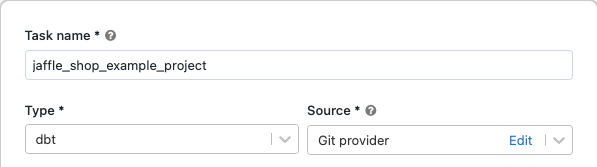
[ソース] ドロップダウン メニューで、[ワークスペース] を選んで Azure Databricks ワークスペース フォルダーにある dbt プロジェクトを使用できます。リモート Git リポジトリにあるプロジェクトの場合は、[Git プロバイダー] を選択できます。 この例では Git リポジトリにある jaffle shop プロジェクトを使用するため、[Git プロバイダー] を選択し、[編集] をクリックして、jaffle shop GitHub リポジトリの詳細を入力します。
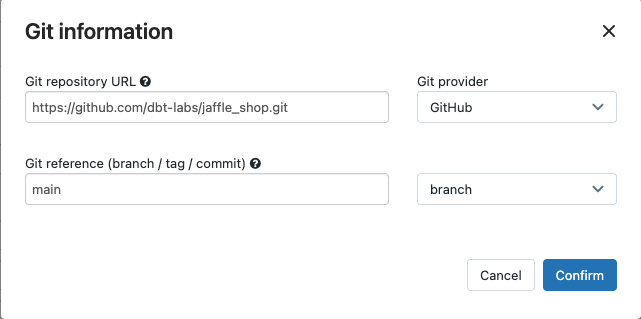
- [Git リポジトリの URL] に jaffle shop プロジェクトの URL を入力します。
- [Git 参照 (ブランチ/タグ/コミット)] に「
main」と入力します。 タグまたは SHA を使用することもできます。
[Confirm](確認) をクリックします。
dbt コマンドのテキスト ボックスで、実行する dbt コマンド (deps、seed、および run) を指定します。 すべてのコマンドの先頭に
dbtを追加する必要があります。 コマンドは指定した順序で実行されます。
[SQL ウェアハウス] で、dbt で生成された SQL を実行する SQL ウェアハウスを選択します。 [SQL ウェアハウス] のドロップダウン メニューには、サーバーレスおよびプロの SQL ウェアハウスのみが表示されます。
(省略可能) タスク出力のスキーマを指定できます。 既定では、
defaultスキーマが使用されます。(省略可能) dbt Core を実行するコンピューティング構成を変更する場合は、[dbt CLI コンピューティング] をクリックします。
(省略可能) タスクの dbt-databricks バージョンを指定できます。 たとえば、開発と実稼働のために dbt タスクを特定のバージョンにピン留めするには、次のようにします。
- [依存ライブラリ] で、現在の dbt-databricks バージョンの横の
 をクリックします。
をクリックします。 - 追加をクリックします。
- [依存ライブラリの追加] ダイアログで、[PyPI] を選択し、[パッケージ] テキスト ボックスに dbt パッケージのバージョンを入力します (例:
dbt-databricks==1.6.0)。 - 追加をクリックします。

注意
Databricks では、開発と実稼働の実行に同じバージョンが使用されるように、dbt タスクを特定バージョンの dbt-databricks パッケージにピン留めすることをお勧めします。 Databricks では、dbt-databricks パッケージのバージョン 1.6.0 以降をお勧めします。
- [依存ライブラリ] で、現在の dbt-databricks バージョンの横の
Create をクリックしてください。
ジョブをすぐに実行するには、
![[今すぐ実行] ボタン](../../_static/images/jobs/run-now-button.png) をクリックします。
をクリックします。
dbt ジョブ タスクの結果を表示する
ジョブが完了したら、ノートブックから SQL クエリを実行するか、Databricks ウェアハウスでクエリを実行することで、結果をテストできます。 たとえば、以下のサンプル クエリを参照してください。
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
<schema> をタスク構成で構成されているスキーマ名に置き換えます。
API の例
Jobs API 2.1 を使用して、dbt タスクを含むジョブを作成および管理することもできます。 次の例では、1 つの dbt タスクを使用してジョブを作成します。
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(詳細設定) カスタム プロファイルを使用して dbt を実行する
SQL ウェアハウス (推奨) または汎用コンピューティングで dbt タスクを実行するには、接続先のウェアハウスまたは Azure Databricks コンピューティングを定義するカスタム profiles.yml を使用します。 ウェアハウスまたは汎用コンピューティングで jaffle shop プロジェクトを実行するジョブを作成するには、以下の手順に従います。
Note
dbt タスクのターゲットとして使用できるのは、SQL ウェアハウスまたは汎用コンピューティングだけです。 dbt のターゲットとしてジョブ コンピューティングを使用することはできません。
jaffle_shop リポジトリのフォークを作成します。
フォークされたリポジトリをデスクトップに複製します。 たとえば、次のようなコマンドを実行できます。
git clone https://github.com/<username>/jaffle_shop.git<username>を自分の GitHub のハンドルに置き換えます。次の内容を含む
jaffle_shopディレクトリでprofiles.ymlという名前の新しいファイルを作成します。jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"<schema>をプロジェクト テーブルのスキーマ名に置き換えます。- SQL ウェアハウスで dbt タスクを実行するには、
<http-host>を SQL ウェアハウスの [接続の詳細] タブの [サーバー ホスト名] の値に置き換えます。 汎用コンピューティングで dbt タスクを実行するには、<http-host>を Azure Databricks コンピューティングの [詳細オプション]、[JDBC/ODBC] タブの [サーバー ホスト名] の値に置き換えます。 - SQL ウェアハウスで dbt タスクを実行するには、
<http-path>を SQL ウェアハウスの [接続の詳細] タブの [HTTP パス] の値に置き換えます。 汎用コンピューティングで dbt タスクを実行するには、<http-path>を Azure Databricks コンピューティングの [詳細オプション]、[JDBC/ODBC] タブの [HTTP パス] の値に置き換えます。
このファイルをソース管理にチェックインするため、このファイルにはアクセス トークンなどのシークレットは指定しません。 代わりに、このファイルは dbt テンプレート機能を使用して、実行時に資格情報を動的に挿入します。
注意
生成された資格情報は、実行期間中 (最大 30 日間) 有効であり、完了後に自動的に取り消されます。
このファイルを Git にチェックインし、フォークされたリポジトリにプッシュします。 たとえば、以下のようなコマンドを実行できます。
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushDatabricks UI のサイド バーで
[ワークフロー] をクリックします。dbt ジョブを選択し、[タスク] タブをクリックします。
[ソース] で [編集] をクリックし、フォークされた jaffle shop GitHub リポジトリの詳細を入力します。
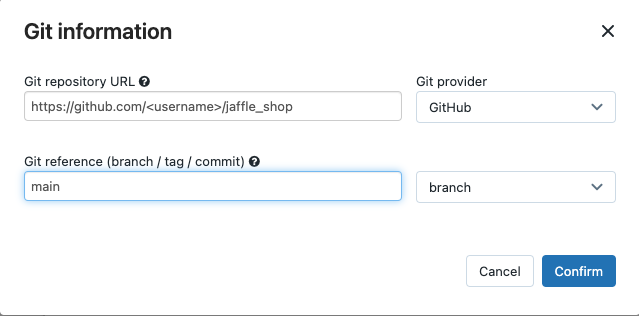
[SQL ウェアハウス] で [なし (手動)] を選択します。
[プロファイル ディレクトリ] に
profiles.ymlファイルを含むディレクトリへの相対パスを入力します。 パス値を空白のままにして、リポジトリ ルートの既定値を使用します。
(上級) ワークフローで dbt Python モデルを使用する
Note
Python モデルの dbt サポートはベータ版であり、dbt 1.3 以上が必要です。
dbt では、Databricks を含む特定のデータ ウェアハウスの Python モデルがサポートされるようになりました。 dbt Python モデルを使用すると、SQL では実装が困難な変換を、Python エコシステムのツールを使用して実装できます。 Azure Databricks ジョブを作成して、dbt Python モデルで 1 つのタスクを実行することも、複数のタスクを含むワークフローの一部として dbt タスクを含めることもできます。
SQL ウェアハウスを使用して dbt タスクで Python モデルを実行することはできません。 Azure Databricks で dbt Python モデルを使用する方法の詳細については、dbt ドキュメントの特定のデータ ウェアハウスに関するページを参照してください。
エラーとトラブルシューティング
"プロファイル ファイルが存在しない" エラー
エラー メッセージ:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
考えられる原因:
profiles.yml ファイルが指定された $PATH ファイルに見つかりませんでした。 dbt プロジェクトのルートに profiles.yml ファイルが含まれていることを確認します。