MLflow モデルのログ、読み込み、登録、デプロイ
MLflow モデルは、Apache Spark でのバッチ推論や、REST API を介したリアルタイムのサービスなどのさまざまなダウンストリーム ツールで使用できる機械学習モデルをパッケージ化するための標準形式です。 この形式では、さまざまなフレーバー (python 関数、pytorch、sklearn など) でモデルを保存できる規則が定義されています。これは、さまざまなモデル サービングと推論プラットフォームで解釈できます。
ストリーミング モデルのログ記録とスコア付けの方法については、ストリーミング モデルの保存と読み込みに関する説明をご覧ください。
モデルのログ記録と読み込み
モデルをログに記録すると、MLflow によって自動的に requirements.txt と conda.yaml の各ファイルがログに記録されます。 これらのファイルを使用して、モデルの開発環境を再作成し、virtualenv (推奨) または conda を使用して依存関係を再インストールできます。
重要
Anaconda Inc. は、anaconda.org チャネルのサービス利用規約を更新しました。 Anaconda のパッケージ化と配布に依存している場合は、新しいサービス利用規約に基づいて商用ライセンスが必要になることがあります。 詳細については、「Anaconda Commercial Edition の FAQ」を参照してください。 Anaconda チャネルの使用には、同社のサービス使用条件が適用されます。
v1.18 (Databricks Runtime 8.3 ML 以前) より前にログに記録された MLflow モデルは既定で、conda defaults チャネル (https://repo.anaconda.com/pkgs/) を依存関係としてログに記録されていました。 このライセンスの変更により、Databricks は MLflow v1.18 以降を使用してログに記録されたモデルの defaults チャネルの使用を停止しました。 ログに記録された既定のチャネルは現在、conda-forge であり、これはコミュニティで管理されている https://conda-forge.org/ を指しています。
モデルの conda 環境から defaults チャネルを除外 せずに MLflow v1.18 より前にモデルをログに記録した場合、そのモデルは意図していない defaults チャネルに依存している可能性があります。
モデルにこの依存関係があるかどうかを手動で確認するには、ログに記録されたモデルと共にパッケージ化された conda.yaml ファイル内での channel 値を調べることができます。 たとえば、defaults チャネルの依存関係を持つモデルの conda.yaml は次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks では、Anaconda リポジトリを使用してモデルを操作することが、Anaconda との関係の下で許可されているかどうか判断できないため、Databricks のお客様に変更を強制していません。 Databricks の使用を通じた Anaconda.com リポジトリの使用が、Anaconda の条件下で許可されている場合は、何も行う必要はありません。
モデルの環境で使用されるチャネルを変更する場合は、新しい conda.yaml でモデル レジストリにモデルを再登録できます。 これを行うには、log_model() の conda_env パラメーターでチャネルを指定します。
log_model() API の詳細については、使用しているモデル フレーバー (scikit-learn の log_model など) の MLflow ドキュメントを参照してください。
conda.yaml ファイルの詳細については、MLflow のドキュメントを参照してください。
API コマンド
モデルを MLflow 追跡サーバーにログ記録するには、mlflow.<model-type>.log_model(model, ...) を使用します。
推論またはさらなる開発のために以前ログに記録されたモデルを読み込むには、mlflow.<model-type>.load_model(modelpath) を使用します。ここで modelpath は、次のいずれかです。
- 実行相対パス (例:
runs:/{run_id}/{model-path}) - Unity カタログ ボリューム パス (
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}など) - で始まる MLflow で管理されるアーティファクト ストレージ パス
dbfs:/databricks/mlflow-tracking/ - 登録済みモデル パス (例:
models:/{model_name}/{model_stage})。
MLflow モデルを読み込むオプションの完全な一覧については、MLflow ドキュメントの「成果物の参照」を参照してください。
Python MLflow モデルの場合、Python 汎用関数としてモデルを読み込むために mlflow.pyfunc.load_model() を使用することもできます。
次のコード スニペットを使用して、モデルを読み込み、データ ポイントをスコア付けできます。
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
別の方法として、モデルを Apache Spark UDF としてエクスポートし、バッチ ジョブまたはリアルタイム Spark ストリーミング ジョブのいずれかとして Spark クラスターでのスコアリングに使用できます。
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
ログ モデルの依存関係
モデルを正確に読み込むには、モデルの依存関係が正しいバージョンでノートブック環境に読み込まれていることを確認する必要があります。 Databricks Runtime 10.5 ML 以降では、現在の環境とモデルの依存関係の間で不一致が検出された場合、MLflow によって警告が表示されます。
モデルの依存関係の復元を簡素化するための追加機能は、Databricks Runtime 11.0 ML 以上に含まれています。 Databricks Runtime 11.0 ML 以上では、pyfunc フレーバー モデルの場合、mlflow.pyfunc.get_model_dependencies を呼び出してモデルの依存関係を取得およびダウンロードできます。 この関数は、依存関係ファイルへのパスを返します。これは %pip install <file-path> を使用してインストールできます。 PySpark UDF としてモデルを読み込む場合は、mlflow.pyfunc.spark_udf 呼び出しで env_manager="virtualenv" を指定します。 これにより、PySpark UDF のコンテキストでモデルの依存関係が復元されます。外部環境には影響しません。
MLflow バージョン 1.25.0 以上を手動でインストールすることで、Databricks Runtime 10.5 以下でもこの機能を使用できます。
%pip install "mlflow>=1.25.0"
モデルの依存関係 (Python と Python 以外) と成果物をログに記録する方法の詳細については、「モデルの依存関係をログに記録する」を参照してください。
モデルの依存関係とモデル提供のためのカスタム成果物をログに記録する方法については、以下を参照してください。
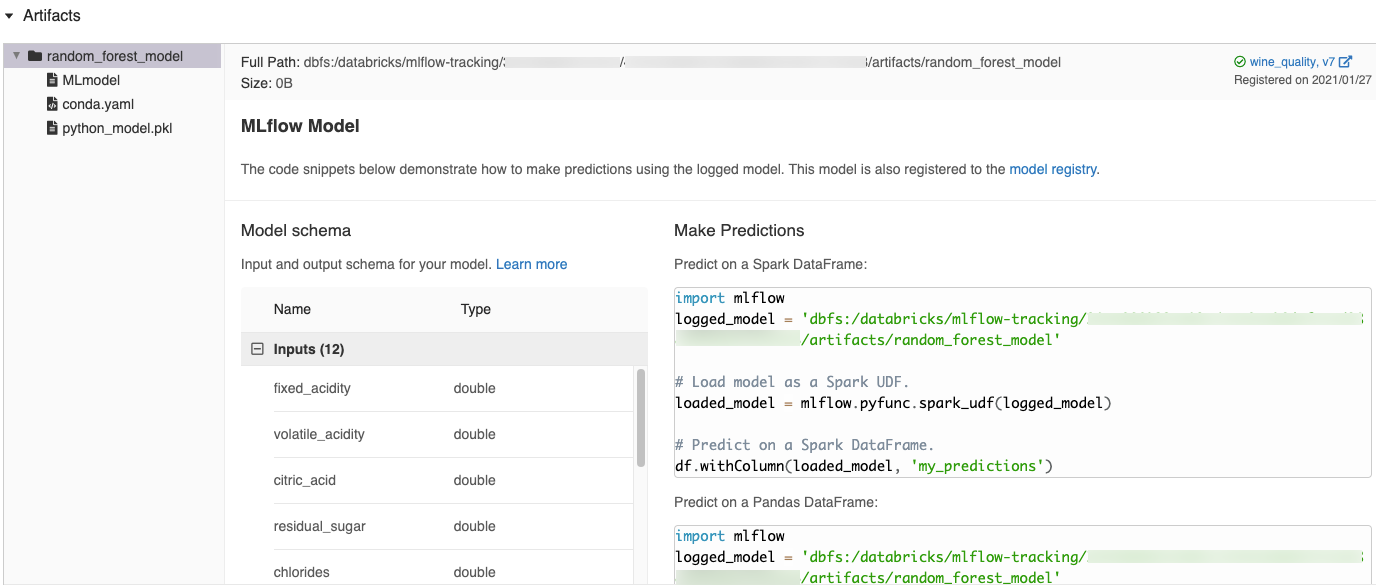
MLflow UI で自動的に生成されたコード スニペット
Azure Databricks ノートブックでモデルをログに記録すると、Azure Databricks は自動的にコード スニペットを生成します。このスニペットをコピーして使用することで、モデルを読み込み実行できます。 これらのコード スニペットを表示するには以下を実行します。
- モデルを生成した実行の [実行] 画面に移動します。 ([実行] 画面を表示する方法については、「ノートブックの実験を表示する」を参照してください。)
- [成果物] セクションまでスクロールします。
- ログに記録されたモデルの名前をクリックします。 右側にパネルが開き、ログに記録されたモデルを読み込んだり、Spark または pandas DataFrames で予測を行うコードが表示されます。
例
ログ モデルの例については、「機械学習トレーニングの実行を追跡する例」の例を参照してください。 推論のためにログされたモデルを読み込む例については、「モデル推論の例」を参照してください。
モデル レジストリにモデルを登録する
MLflow モデル レジストリにモデルを登録できます。MLflow モデル レジストリは、MLflow モデルのライフサイクル全体を管理するための UI と API のセットを提供する一元化されたモデル ストアです。 Databricks Unity Catalog でモデル レジストリを使用してモデルを管理する方法の手順については、「Unity Catalog 内でモデル ライフサイクルを管理する」を参照してください。 ワークスペース モデル レジストリを使用するには、「ワークスペース モデル レジストリを使用してモデルのライフサイクルを管理する」を参照してください。
API を使用してモデルを登録するには、mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}") を使用します。
モデルを Unity カタログ ボリュームに保存する
モデルをローカルに保存するには、mlflow.<model-type>.save_model(model, modelpath) を使用します。 modelpath は、 Unity カタログ ボリューム パスである必要があります。 たとえば、プロジェクトの作業を格納 dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models Unity カタログ ボリュームの場所を使用する場合は、モデル パス /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelsを使用する必要があります。
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
MLlib モデルの場合は、ML パイプラインを使用します。
モデル成果物をダウンロードする
さまざまな API を使用して、登録されたモデルのログに記録されたモデル成果物 (モデル ファイル、プロット、メトリックなど) をダウンロードできます。
Python API の例:
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
Java API の例:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI コマンド の例:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
オンライン サービング用にモデルをデプロイする
Mosaic AI Model Serving を使用して、Unity カタログ モデル レジストリに REST エンドポイントとして登録された機械学習モデルをホストできます。 これらのエンドポイントは、モデル バージョンとそのステージの可用性に基づいて自動的に更新されます。
MLflow の組み込みデプロイ ツールを使用して、サードパーティのサービング フレームワークにモデルをデプロイすることもできます。