HDInsight on AKS の Apache Spark™ クラスターでジョブを送信および管理する
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 ワークロードの突然の終了を回避するには、2025 年 1 月 31 日より前にそのワークロードを Microsoft Fabric または同等の Azure 製品に移行する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティをフォローしてください。
クラスターが作成されると、ユーザーはさまざまなインターフェイスを使用して、次の方法でジョブを送信および管理できます
- Jupyter の使用
- Zeppelin の使用
- SSH の使用 (spark-submit)
Jupyter の使用
前提条件
HDInsight on AKS の Apache Spark™ クラスター。 詳細については、Apache Spark クラスターの作成に関する記事を参照してください。
Jupyter Notebook は、さまざまなプログラミング言語をサポートする対話型のノートブック環境です。
Jupyter Notebook の作成
Apache Spark™ クラスターのページに移動し、[概要] タブを開きます。[Jupyter] をクリックすると、Jupyter Web ページを認証して開くように求められます。

Jupyter の Web ページで [New] (新規) > [PySpark] の順に選択して、ノートブックを作成します。
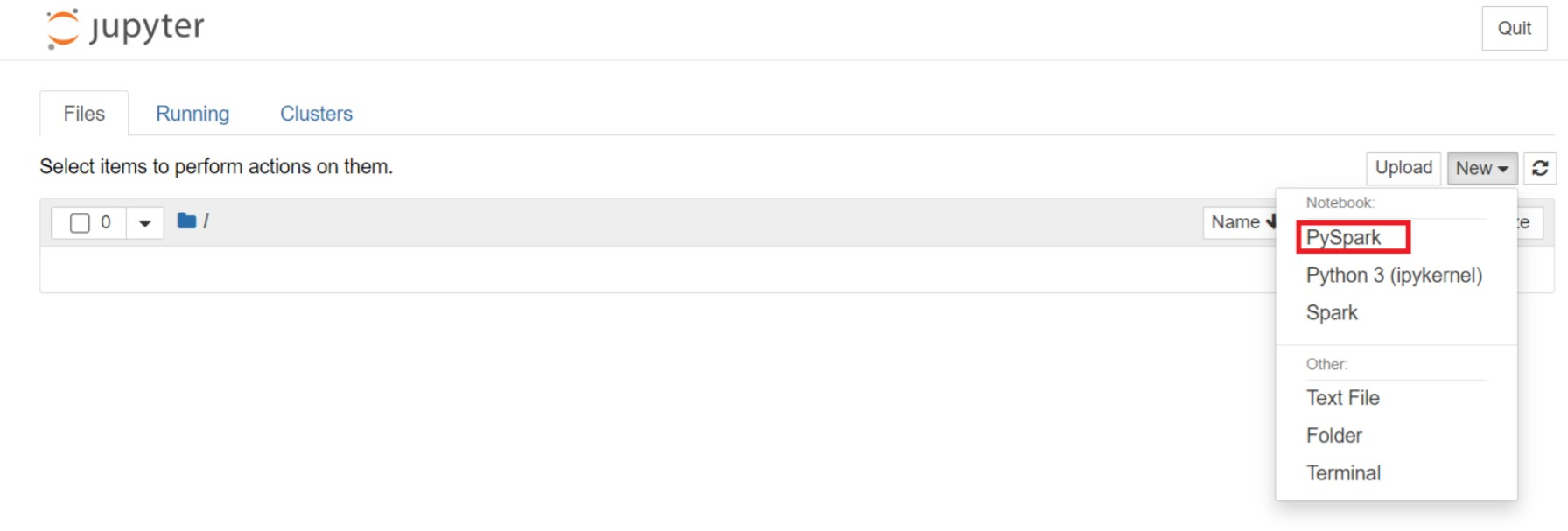
Untitled(Untitled.ipynb)という名で新しいノートブックが作成されて開かれます。Note
PySpark または Python 3 カーネルを使用してノートブックを作成すると、最初のコード セルを実行するときに Spark セッションが自動的に作成されます。 セッションを明示的に作成する必要はありません。
次のコードを Jupyter Notebook の空のセルに貼り付け、Shift + Enter キーを押してコードを実行します。 Jupyter の詳細な操作については、こちらを参照してください。

%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])給与と年齢を X 軸と Y 軸としてグラフをプロットします
同じノートブックで、次のコードを Jupyter Notebook の空のセルに貼り付け、Shift + Enter キーを押してコードを実行します。
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()




Notebook を保存する
ノートブックのメニュー バーから [ファイル] > [Save and Checkpoint] (保存とチェックポイント) に移動します。
ノートブックのメニュー バーから [ファイル] > [Close and Halt] (閉じて停止) に移動して、ノートブックをシャットダウンしてクラスター リソースを解放します。 [examples] フォルダーの下にある任意のノートブックを実行することもできます。


Apache Zeppelin ノートブックの使用
HDInsight on AKS の Apache Spark クラスターには、Apache Zeppelin ノートブックが含まれています。 Notebook を使用して、Apache Spark ジョブを実行します。 この記事では、HDInsight on AKS クラスターで Zeppelin ノートブックを使用する方法について説明します。
前提条件
HDInsight on AKS での Apache Spark クラスター。 手順については、Apache Spark クラスターの作成に関するページを参照してください。
Apache Zeppelin Notebook を起動する
Apache Spark クラスターの [概要] ページに移動し、クラスター ダッシュボードから [Zeppelin] ノートブックを選択します。 Zeppelin のページを認証して開くように求められます。

新しいノートブックを作成します。 ヘッダー ウィンドウから、[Notebook] > [Create new note] (新しいメモを作成する) の順に移動します。 Notebook のヘッダーに [接続] というステータスが表示されることを確認します。 右上隅に緑色の点が表示されます。

Zeppelin Notebook で次のコードを実行します。
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])[再生] ボタンを選択して、スニペットを実行します。 段落の右上隅にあるステータスが、[準備完了]、[保留中]、[実行中]、[完了] の順に進行します。 出力が同じ段落の下に表示されます。 スクリーンショットは次の図のようになります。

出力:





Spark を使用してジョブを送信する
次のコマンド '#vim samplefile.py' を使用してファイルを作成します
このコマンドを実行すると、vim ファイルが開きます
以下のコードを vim ファイルに貼り付けます
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])次の方法でファイルを保存します。
- Escape ボタンを押します
- コマンド
:wqを入力します
次のコマンドを実行してジョブを実行します。
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

HDInsight on AKS の Apache Spark クラスターでクエリを監視する
Spark 履歴 UI
[概要] タブで Spark 履歴サーバー UI をクリックします。

同じアプリケーション ID を使用して、UI から最近実行したものを選択します。

Spark 履歴サーバー UI で、有向非循環グラフのサイクルとジョブのステージを表示します。
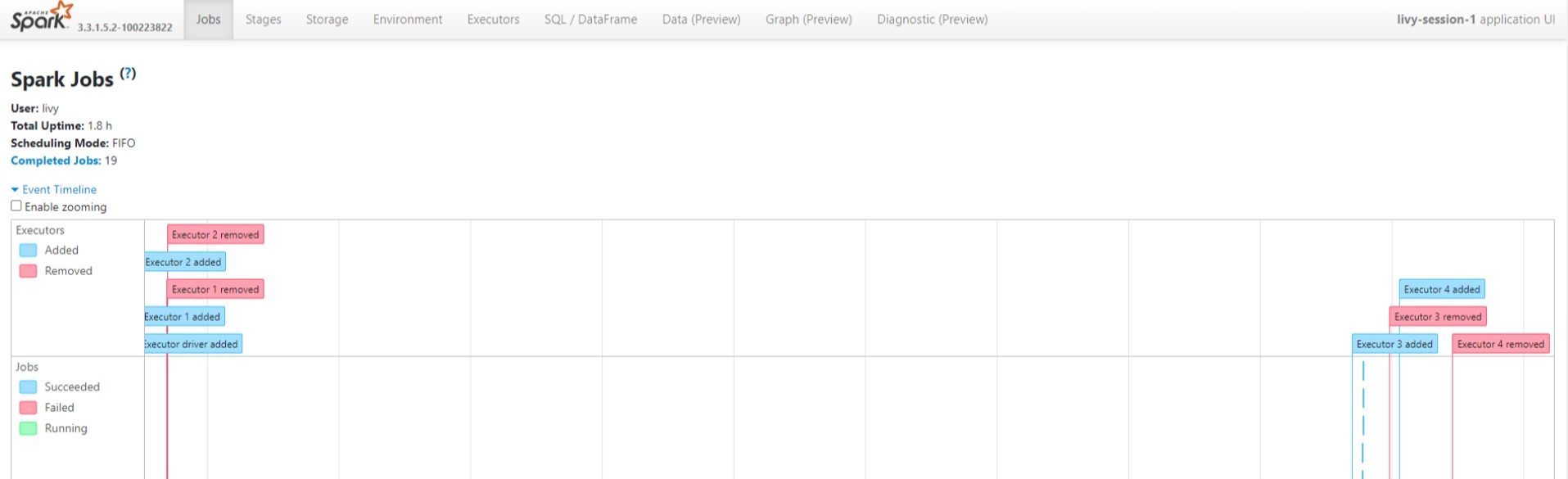



Livy セッション UI
Livy セッション UI を開くには、ブラウザーにコマンド
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/uiを入力します
[ログ] の下にあるドライバー オプションをクリックして、ドライバー ログを表示します。

Yarn UI
[概要] タブで [Yarn] をクリックし、Yarn UI を開きます。
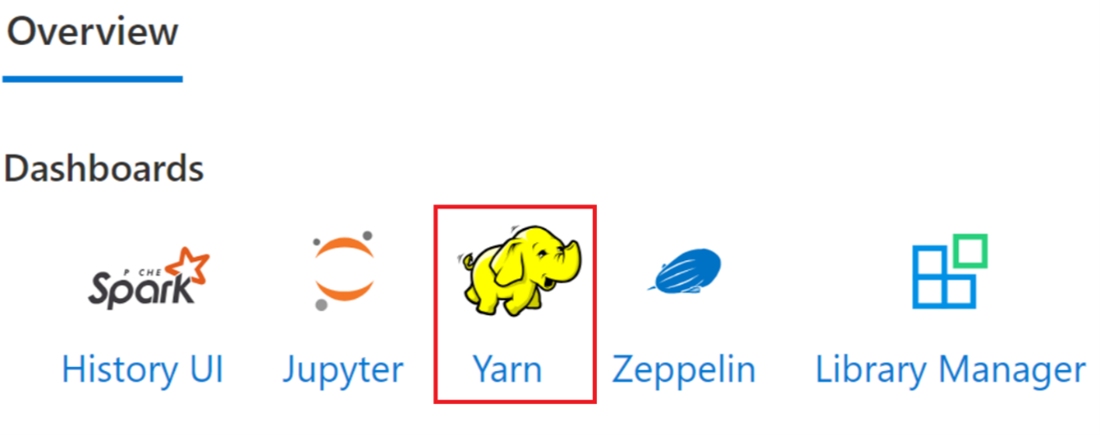
同じアプリケーション ID で最近実行したジョブを追跡できます。
Yarn のアプリケーション ID をクリックして、ジョブの詳細なログを表示します。



リファレンス
- Apache、Apache Spark、Spark、および関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。