HDInsight クラスターを新しいバージョンに移行する
最新の HDInsight 機能を利用するために、HDInsight クラスターを最新版に定期的に移行することをお勧めします。 HDInsight では、既存のクラスターが新しいコンポーネント バージョンにアップグレードされるインプレース アップグレードがサポートされていません。 希望するコンポーネントとプラットフォーム バージョンで新しいクラスターを作成し、その新しいクラスターを使用するために、お使いのアプリケーションを移行する必要があります。 HDInsight クラスターのバージョンを移行するには、下のガイドラインに従います。
注意
プライマリ ストレージ コンテナーを使用して Hive クラスターを作成している場合は、既存の HDInsight クラスターからコピーします。 コンテンツ全体をコピーしないでください。 構成されるデータ フォルダーのみをコピーします。
移行タスク
HDInsight クラスターをアップグレードするワークフローは次のとおりです。
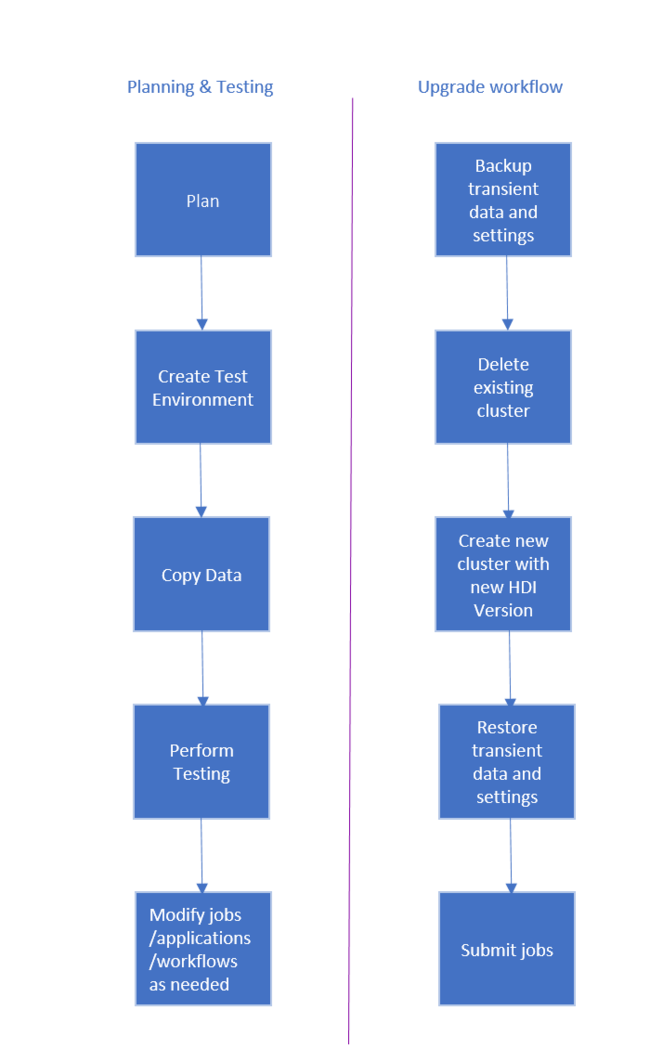
- このドキュメントの各セクションを読んで、HDInsight クラスターに移行するときに必要になる場合がある変更について理解します。
- テスト/品質保証環境として、クラスターを作成します。 クラスターの作成の詳細については、「HDInsight での Linux ベースの Hadoop クラスターの作成」を参照してください。
- 既存のジョブ、データ ソース、およびシンクを新しい環境にコピーします。
- 検証テストを実行し、新しいクラスターで予期したとおりにジョブが動作していることを確認します。
すべて予期したとおりに動作していることを確認したら、移行のダウンタイムをスケジュールします。 このダウンタイム中に、次の操作を実行します。
- クラスター ノードでローカルに格納されている一時的なデータをバックアップします。 たとえば、ヘッド ノードに直接データを格納している場合です。
- 既存のクラスターを削除します。
- 同じ VNET サブネットの中に、前のクラスターで使用していたのと同じ既定のデータ ストアを使用する、最新の (またはサポートされている) バージョンの HDI クラスターを作成します。 これで、新しいクラスターで既存の運用データを引き続き使用できます。
- バックアップしたすべての一時的なデータをインポートします。
- 新しいクラスターを使用して、ジョブを開始または処理を続行します。
ワークロード固有のガイダンス
特定のワークロードを移行する方法については、次のドキュメントにガイドラインが記載されています。
バックアップと復元
データベースのバックアップと復元の詳細については、自動データベース バックアップを使用した Azure SQL Database 内のデータベースの復旧に関する記事を参照してください。
アップグレードのシナリオ
前述のように、新しい機能と修正プログラムを活用するために、HDInsight クラスターを定期的に最新バージョンに移行することをお勧めします。 クラスターを削除して再デプロイすることを要求する理由を次の一覧で確認します。
- クラスターのバージョンが廃棄済みか、新しいバージョンで解決されるクラスターの問題がある場合。
- クラスターの問題の根本原因は、小さな VM に関連していると判断されます。 Microsoft の推奨されるノード構成を表示します。
- お客様がサポートケースを開き、Microsoft のエンジニアリングチームが、新しいクラスター バージョンで既に問題が修正されていることを確認します。
- 既定のメタストア データベース (Ambari、Hive、Oozie、Ranger) が使用率の上限に達しました。 Microsoft から、カスタム メタストア データベースを使用してクラスターを再作成するように求められます。
- クラスターの問題の根本原因は、サポートされていない操作が原因です。 サポートされていない一般的な操作の一部を次に示します。
- Ambari でのサービスの移動または追加。 Ambari のクラスター サービスの情報を参照してください。[サービス アクション] メニューから実行できる操作の 1 つは、[サービス名] の移動です。 別のアクションとして [サービス名] を追加します。 これらのオプションはどちらもサポートされていません。
- Python パッケージが破損しています。 HDInsight クラスターは、組み込みの Python 環境 (Python 2.7 と Python 3.5) に依存しています。 これらの既定の組み込み環境にカスタム パッケージを直接インストールすると、予期しないライブラリ バージョンの変更が発生し、クラスターが壊れる可能性があります。 Spark アプリケーションのカスタム外部 Python パッケージを安全にインストールする方法を参照してください。
- サードパーティ製ソフトウェア。 お客様は、HDInsight クラスターにサードパーティ製ソフトウェアをインストールすることができます。ただし、既存の機能が壊れている場合は、クラスターを再作成することをお勧めします。
- 同じクラスターに複数のワークロードがあります。 HDInsight 4.0 では、Hive Warehouse Connector には、Spark ワークロードと Interactive Query ワークロード用に、個別のクラスターが必要です。 次の手順に従って、Azure HDInsight に両方のクラスターを設定します。 同様に、Spark と HBASE を統合するには、2 つの異なるクラスターが必要です。
- カスタム Ambari DB パスワードが変更されました。 Ambari DB パスワードは、クラスターの作成時に設定され、更新するための現在のメカニズムはありません。 顧客は、カスタム Ambari DB を使用してクラスターをデプロイする場合、SQL DB の DB パスワードを変更することができます。ただし、実行中の HDInsight クラスターに対してこのパスワードを更新する方法はありません。
- HDInsight ロード バランサーの変更。 Ambari と SSH アクセス用に自動的にデプロイされた HDInsight ロード バランサーは、変更または削除しないでください。 HDInsight ロード バランサーを変更してクラスター機能を中断する場合は、クラスターを再デプロイすることをお勧めします。