Jupyter Notebook をコンピューターにインストールして HDInsight の Apache Spark に接続する
この記事では、カスタム PySpark カーネル (Python の場合)、Apache Spark カーネル (Scala の場合) および Spark マジックと共に Jupyter Notebook をインストールする方法について説明します。 その後、そのノートブックを HDInsight クラスターに接続します。
Jupyter をインストールして HDInsight の Apache Spark に接続するには、4 つの主要手順があります。
- Spark クラスターを構成する。
- Jupyter Notebook をインストールする。
- PySpark カーネルと Spark カーネルおよび Spark マジックをインストールする。
- HDInsight 上の Spark クラスターにアクセスするように Spark マジックを構成する。
カスタム カーネルと Spark マジックの詳細については、HDInsight 上の Jupyter Notebook と Apache Spark Linux クラスターで使用可能なカーネルに関するページを参照してください。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。 ローカル ノートブックは HDInsight クラスターに接続します。
HDInsight の Spark での Jupyter Notebook の使用方法を熟知していること。
Jupyter Notebook をコンピューターにインストールする
Jupyter Notebook をインストールする前に Python をインストールします。 Anaconda ディストリビューションでは、Python と Jupyter Notebook の両方がインストールされます。
ご使用のプラットフォーム用の Anaconda インストーラー をダウンロードし、セットアップ プログラムを実行します。 セットアップ ウィザードを実行する過程で、Anaconda を PATH 変数に追加するためのオプションを忘れずに選択してください。 Anaconda を使用した Jupyter のインストールについての記事も参照してください。
Spark マジックをインストールする
HDInsight クラスター バージョン 3.6 および 4.0 用の Spark マジックをインストールするには、
pip install sparkmagic==0.13.1コマンドを入力します。 sparkmagic のドキュメントも参照してください。次のコマンドを実行して、
ipywidgetsが適切にインストールされていることを確認します。jupyter nbextension enable --py --sys-prefix widgetsnbextension
PySpark と Spark カーネルをインストールする
次のコマンドを入力して、
sparkmagicがインストールされている場所を識別します。pip show sparkmagic次に、上のコマンドで識別された場所に作業ディレクトリを変更します。
新しい作業ディレクトリから、次のコマンドを 1 つ以上入力して目的のカーネルをインストールします。
カーネル command Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel省略可能。 次のコマンドを入力して、サーバーの拡張機能を有効にします。
jupyter serverextension enable --py sparkmagic
HDInsight の Spark クラスターに接続するように Spark マジックを構成する
このセクションでは、先ほどインストールした Spark マジックを、Apache Spark クラスターに接続するように構成します。
次のコマンドを使用して Python シェルを起動します。
pythonJupyter の構成情報は通常、ユーザーの home ディレクトリに格納されます。 次のコマンドを入力してホーム ディレクトリを識別し、.sparkmagic という名前のフォルダーを作成します。 完全なパスが出力されます。
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()フォルダー
.sparkmagicに config.json というファイルを作成し、次の JSON スニペットを追加します。{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }ファイルに次の編集を行います。
テンプレート値 新しい値 {USERNAME} クラスター ログイン。既定値は admin。{CLUSTERDNSNAME} クラスター名 {BASE64ENCODEDPASSWORD} 実際のパスワードの Base64 でエンコードされたパスワード。 Base64 のパスワードは https://www.url-encode-decode.com/base64-encode-decode/ で生成できます。 "livy_server_heartbeat_timeout_seconds": 60sparkmagic 0.12.7(クラスター v3.5 と v3.6) を使用している場合、保持します。sparkmagic 0.2.3(クラスター v3.4) を使用している場合は、"should_heartbeat": trueに置き換えます。完全なサンプル ファイルは sample config.json で確認できます。
ヒント
ハートビートが送信され、セッションがリークしないことが確認されます。 コンピューターがスリープ状態になるかシャットダウンすると、ハートビートは送信されず、セッションがクリーンアップされます。 クラスター v3.4 の場合、この動作を無効にするには、Ambari UI から Livy config
livy.server.interactive.heartbeat.timeoutを0に設定します。 クラスター v3.5 の場合、上記の 3.5 構成を設定しないと、セッションは削除されません。Jupyter を起動します。 コマンド プロンプトから次のコマンドを使用します。
jupyter notebookカーネルで使用可能な Spark マジックを使用できることを確認します。 次の手順のようにします。
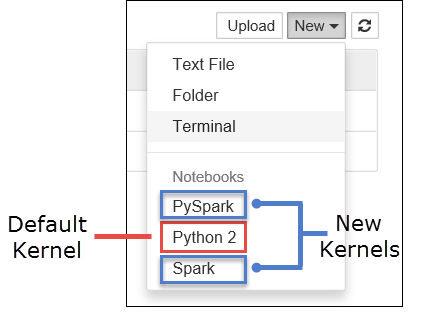
a. 新しい Notebook を作成します。 右隅から [新規] を選択します。 既定のカーネル Python 2 または Python 3 と、インストールしたカーネルが表示されるはずです。 実際の値は、インストールの選択に応じて異なる場合があります。 PySpark を選択します。
重要
[新規] を選択したら、エラーがないかシェルを確認します。 エラー
TypeError: __init__() got an unexpected keyword argument 'io_loop'が表示される場合は、Tornado の特定のバージョンで既知の問題が発生している可能性があります。 その場合はカーネルを停止し、次のコマンドを使用して Tornado のインストールをダウン グレードします:pip install tornado==4.5.3。b. 次のコード スニペットを実行します。
%%sql SELECT * FROM hivesampletable LIMIT 5出力結果が正しく得られた場合、HDInsight クラスターへの接続テストは完了です。
別のクラスターに接続するようにノートブックの構成を更新する場合は、前の手順 3. を参照して、config.json を新しい値セットで更新してください。
Jupyter をローカル コンピューターにインストールする理由
Jupyter をコンピューターにインストールしてから HDInsight 上の Apache Spark クラスターに接続する理由は次のとおりです。
- ノートブックをローカルに作成し、アプリケーションを実行中のクラスターに対してテストしてから、そのノートブックをクラスターにアップロードするオプションが提供されます。 ノートブックをクラスターにアップロードするには、クラスターで実行されている Jupyter Notebook を使用してアップロードするか、またはクラスターに関連付けられているストレージ アカウント内の
/HdiNotebooksフォルダーに保存するかのどちらかの方法を使用できます。 クラスターにノートブックを保存する方法の詳細については、Jupyter Notebook の格納場所に関するセクションを参照してください。 - ノートブックがローカルで利用できると、アプリケーションの要件に応じて異なる Spark クラスターに接続することができます。
- GitHub を使用してソース管理システムを導入し、ノートブックのバージョン管理を行うことができます。 複数のユーザーが同じノートブックで作業するコラボレーション環境を実現することもできます。
- クラスターをセットアップしなくてもローカルでノートブックを使用できます。 クラスターは、クラスターとの間でノートブックをテストする目的でのみ必要となります。ノートブックや開発環境を手動で管理するうえでクラスターは必要ありません。
- 独自のローカル開発環境の方が、クラスター上の Jupyter 環境よりも構成しやすい場合があります。 リモートのクラスターを構成しなくても、ローカルにインストールされているすべてのソフトウェアを有効活用することができます。
警告
Jupyter がローカル コンピューターにインストールされている場合、同じ Spark クラスター上で複数のユーザーが同時に同じノートブックを実行できます。 そのような状況では、複数の Livy セッションが作成されます。 問題が発生してデバッグが必要となった場合、それは Livy セッションとユーザーの対応関係を追跡する複雑な作業となります。