Azure HDInsight の Apache Spark クラスター上の Jupyter Notebook のカーネル
HDInsight Spark クラスターには、アプリケーションをテストするために Apache Spark 上の Jupyter Notebook で使用できるカーネルが用意されています。 カーネルは、コードを実行し、解釈するプログラムです。 次の 3 つのカーネルがあります。
- PySpark - Python2 で記述されたアプリケーション用。 (Spark 2.4 バージョンのクラスターにのみ適用されます)
- PySpark3 - Python3 で記述されたアプリケーション用。
- Spark - Scala で記述されたアプリケーション用。
この記事では、このカーネルの使用方法と、カーネルを使用するメリットについて説明します。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
Spark HDInsight で Jupyter Notebook を作成する
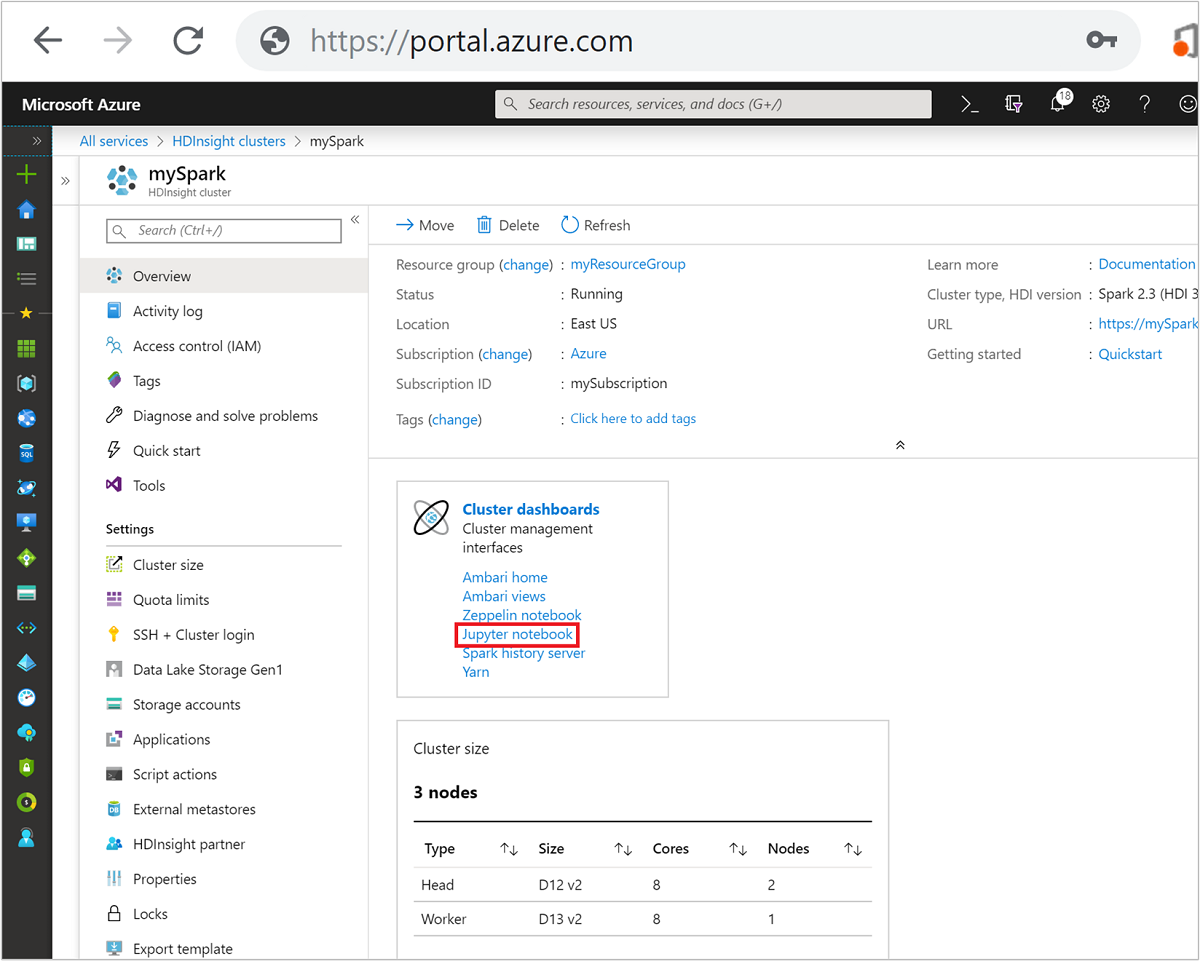
Azure portal で Spark クラスターを選択します。 手順については、「クラスターの一覧と表示」を参照してください。 [概要] ビューが開きます。
[概要] ビューから、 [クラスター ダッシュボード] ボックスの [Jupyter Notebook] を選択します。 入力を求められたら、クラスターの管理者資格情報を入力します。
Note
ブラウザーで次の URL を開き、Spark クラスターの Jupyter Notebook にアクセスすることもできます。 CLUSTERNAME をクラスターの名前に置き換えます。
https://CLUSTERNAME.azurehdinsight.net/jupyter[新規] を選択し、 [Pyspark] 、 [PySpark3] 、または [Spark] を選択して、Notebook を作成します。 Scala アプリケーションには Spark カーネルを、Python2 アプリケーションには PySpark カーネルを、Python3 アプリケーションには PySpark3 カーネルを使用します。
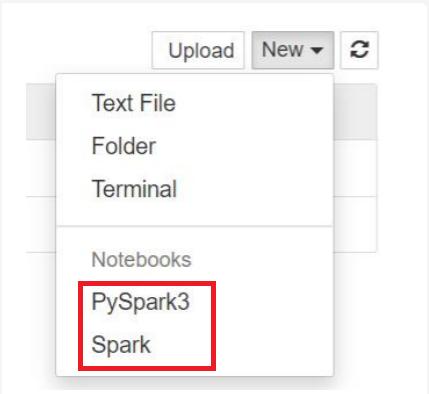
Note
Spark 3.1 の場合は、PySpark3 または Spark のみを使用できます。
- Notebook が、選択したカーネルで開きます。
カーネルを使用する利点
Spark HDInsight クラスター上の Jupyter Notebook で新しいカーネルを使用する利点は次のとおりです。
コンテキストのプリセット。 PySpark、PySpark3、または Spark カーネルでは、アプリケーションの操作を開始する前に、Spark または Hive コンテキストを明示的に設定する必要はありません。 これらのコンテキストは既定で利用できます。 各コンテキストは次のとおりです。
sc : Spark コンテキスト用
sqlContext : Hive コンテキスト用
そのため、コンテキストを設定するための次のようなステートメントを実行する必要はありません。
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)代わりに、事前に設定されたコンテキストをアプリケーションで直接使用できます。
セル マジック。 PySpark カーネルには、"マジック"、つまり、
%%で呼び出すことができる特別なコマンドがいくつか事前定義されています (%%MAGIC<args>など)。 このマジック コマンドはコード セルの最初の単語にする必要があります。また、コンテンツの複数行に対応できる必要があります。 魔法の単語はセルの最初の単語にする必要があります。 その前に他の単語を追加すると、それがコメントであっても、エラーを引き起こします。 マジックの詳細については、こちらをご覧ください。次の表は、カーネルで使用できるさまざまなマジックを一覧にしたものです。
マジック 例 説明 help %%help利用できるすべてのマジック、その例と説明から構成されるテーブルを生成します。 info %%info現在の Livy エンドポイントのセッション情報を出力します。 [構成] %%configure -f{"executorMemory": "1000M","executorCores": 4}セッションを作成するためのパラメーターを構成します。 セッションが既に作成されている場合、強制フラグ ( -f) は必須です。これにより、セッションの破棄と再作成が保証されます。 有効なパラメーターの一覧については、 Livy の「POST /sessions」の「Request Body (要求本文)」 をご覧ください。 例の列で示されているように、パラメーターは JSON 文字列として渡し、マジックの後の次の行に置く必要があります。sql %%sql -o <variable name>
SHOW TABLESsqlContext に対して Hive クエリを実行します。 -oパラメーターが渡される場合、クエリの結果は、 Pandas データフレームとして %%local Python コンテキストで永続化されます。local %%locala=1後続行のすべてのコードがローカルで実行されます。 使用しているカーネルに関係なく、コードは有効な Python2 コードである必要があります。 したがって、Notebook の作成時に PySpark3 または Spark カーネルを選択している場合でも、 %%localマジックをセルで使用する場合、そのセルには、有効な Python2 コードのみが含まれている必要があります。logs %%logs現在の Livy セッションのログを出力します。 delete %%delete -f -s <session number>現在 Livy エンドポイントの特定のセッションを削除します。 カーネル自体に対して開始されているセッションは削除できません。 cleanup %%cleanup -fこのノートブックのセッションを含む、現在 Livy エンドポイントのすべてのセッションを削除します。 強制フラグ -f は必須です。 注意
PySpark カーネルによって追加されるマジックに加えて、
%%shなどの組み込み IPython マジックも使用することができます。%%shマジックは、クラスター ヘッド ノードでスクリプトやコード ブロックを実行する際に使用することができます。自動視覚化。 Pyspark カーネルによって、Hive と SQL のクエリの出力が自動的に視覚化されます。 表、円グラフ、面積グラフ、棒グラフなど、さまざまな種類の視覚化から選択できます。
%%sql マジックでサポートされるパラメーター
%%sql マジックでは、クエリの実行時に受け取る出力の種類の制御に使用できる、さまざまなパラメーターがサポートされます。 次の表に、出力を示します。
| パラメーター | 例 | 説明 |
|---|---|---|
| -o | -o <VARIABLE NAME> |
クエリの結果を Pandas データフレームとして %%local Python コンテキストで永続化するには、このパラメーターを使用します。 データ フレーム変数の名前は、指定した変数の名前です。 |
| -Q | -q |
セルの視覚化をオフにするには、このパラメーターを使用します。 セルのコンテンツを自動的に視覚化せず、単にデータ フレームとしてキャプチャする場合は、-q -o <VARIABLE> を使用します。 (たとえば、CREATE TABLE ステートメントのような、SQL クエリを実行するために) 結果をキャプチャせずに視覚化をオフにする必要がある場合、-o 引数を指定せずに -q を使用します。 |
| -M | -m <METHOD> |
ここで METHOD は take または sample です (既定値は take)。 メソッドが take の場合、カーネルは、(この表で後述する) MAXROWS によって指定された結果データ セットの先頭から要素を取得します。 メソッドが sample の場合、カーネルによって、この表の次に説明する -r パラメーターに従って、データ セットの要素がランダムにサンプリングされます。 |
| -r | -r <FRACTION> |
ここで FRACTION は、0.0 ~ 1.0 の浮動小数点数です。 SQL クエリのサンプル メソッドが sample の場合、カーネルは、結果セットの指定された割合の要素をランダムにサンプリングします。 たとえば、-m sample -r 0.01 引数を使用して SQL クエリを実行した場合、結果の行の 1% がランダムにサンプリングされます。 |
| -n | -n <MAXROWS> |
MAXROWS は整数値です。 カーネルによって、出力行の数が MAXROWS に制限されます。 MAXROWS が -1 などの負数の場合は、結果セット内の行数は制限されません。 |
例:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
上記のステートメントは、次のアクションを実行します。
- hivesampletableからすべてのレコードを選択します。
- -q を使用しているため、自動視覚化がオフになります。
-m sample -r 0.1 -n 500を使用しているため、hivesampletable 内の行の 10% がランダムにサンプリングされ、結果セットのサイズは 500 行に制限されます。- 最後に、
-o query2を使用しているため、 query2という名前のデータフレームにも、その出力が保存されます。
新しいカーネルを使用する場合の考慮事項
どのカーネルを使用する場合でも、Notebook を実行したままにしておくと、クラスターのリソースが消費されます。 これらのカーネルでは、コンテキストが事前設定されているため、Notebook を終了するだけではコンテキストは強制終了されません。 そのため、クラスターのリソースは引き続き使用中のままになります。 Notebook の使用が終了したら、Notebook の [ファイル] メニューから [Close and Halt](閉じて停止する) オプションを使用することをお勧めします。 閉じることにより、コンテキストが強制終了され、Notebook が終了されます。
Notebook の格納場所
クラスターで Azure Storage が既定のストレージ アカウントとして使用されている場合、Jupyter Notebook は /HdiNotebooks フォルダーの下のストレージ アカウントに保存されます。 Notebook、テキスト ファイル、および Jupyter 内から作成したフォルダーには、ストレージ アカウントからアクセスできます。 たとえば、Jupyter を使用して myfolder フォルダーと myfolder/mynotebook.ipynb Notebook を作成する場合、ストレージ アカウント内の /HdiNotebooks/myfolder/mynotebook.ipynb で、その Notebook にアクセスできます。 逆の場合も同様です。つまり、Notebook を 自分のストレージ アカウントの /HdiNotebooks/mynotebook1.ipynb に直接アップロードした場合、Jupyter からも Notebook を表示することができます。 Notebook は、クラスターが削除された後でも、ストレージ アカウントに保持されます。
注意
既定のストレージが Azure Data Lake Storage である HDInsight クラスターの場合、ノートブックは関連するストレージには保存されません。
Notebook がストレージ アカウントに保存される方法は、Apache Hadoop HDFS と互換性があります。 クラスターに SSH で接続している場合、次のようなファイル管理コマンドを使用できます。
| コマンド | 説明 |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# ルート ディレクトリのすべてを一覧表示する - このディレクトリ内のすべてのものが、ホーム ページから Jupyter に表示されます |
hdfs dfs –copyToLocal /HdiNotebooks |
# HdiNotebooks フォルダーの内容をダウンロードする |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# ノートブック example.ipynb をルート フォルダーにアップロードして、Jupyter から表示できるようにする |
クラスターが既定のストレージ アカウントとして使用しているのが Azure Storage か Azure Data Lake Storage かにかかわらず、Notebook は /var/lib/jupyter のクラスター ヘッド ノードにも保存されます。
サポートされているブラウザー
Spark HDInsight クラスター上の Jupyter Notebook は、Google Chrome でのみサポートされます。
検索候補
新しいカーネルは進化の過程にあり、時間の経過と共に成熟するでしょう。 したがって、カーネルが成熟するにつれて、API が変更される可能性があります。 これらの新しいカーネルに関するフィードバックを、ぜひお寄せください。 フィードバックは、これらのカーネルの最終リリースを形作るのに役立ちます。 ご意見やフィードバックは、この記事の下部にある フィードバックのセクションからお寄せください。