マネージド Feature Store の最上位エンティティについて
このドキュメントでは、マネージド Feature Store の最上位エンティティについて説明します。
マネージド Feature Store の詳細については、「マネージド Feature Store とは」を参照してください
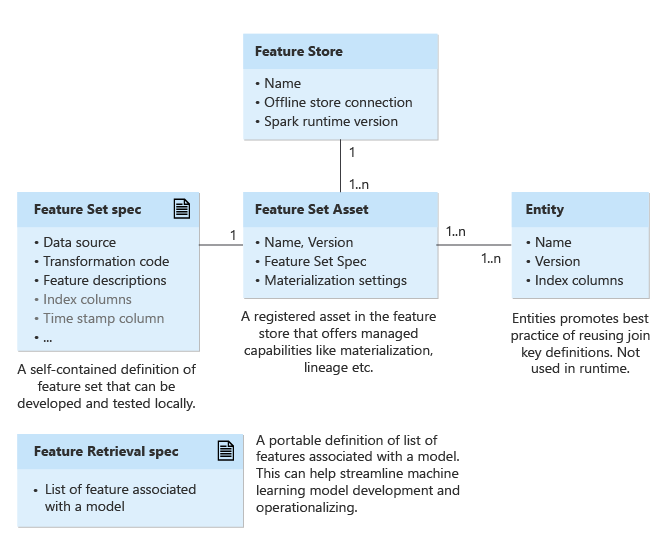
機能ストア
機能セットは機能ストアを使用して作成および管理できます。 機能セットは機能のコレクションです。 必要に応じて、具体化ストアを特徴量ストアに関連付けて (オフライン ストア接続)、定期的に特徴量を事前計算して保持することができます。 これにより、トレーニング中または推論中の特徴量取得の高速化と信頼性を向上させることができます。
構成の詳細については、「CLI (v2) 特徴量ストアの YAML スキーマ」を参照してください
エンティティ
エンティティでは、エンタープライズ内の論理エンティティのインデックス列をカプセル化します。 エンティティの例としては、アカウント エンティティ、顧客エンティティなどがあります。ベスト プラクティスとして、エンティティは、同じ論理エンティティを使用する複数の特徴量セット間で同じインデックス列定義の使用を適用するのに役立ちます。
通常、エンティティは 1 回作成され、特徴量セット間で再利用されます。 エンティティはバージョン管理されます。
構成の詳細については、「CLI (v2) 特徴量エンティティ YAML スキーマ」を参照してください
機能セットの仕様と資産
特徴量セットは、ソース システム データに変換を適用することによって生成される特徴量のコレクションです。 機能セットでは、ソース、変換関数、および具体化設定をカプセル化します。 現在、PySpark 特徴量変換コードがサポートされています。
まず、特徴量セットの仕様を作成します。 特徴量セット仕様は、ローカルで開発してテストできる特徴量セットの自己完結型定義です。
機能セット仕様は、通常、次のパラメーターで構成されます。
source: この機能をどのソースにマップするかtransformation(省略可能): 特徴量を作成するためにソース データに適用される変換ロジック。 ここでは、サポートされているコンピューティングとして Spark を使用します。index_columnsとtimestamp_columnを表す列の名前: ユーザーが特徴量データと観測データを結合しようとしている場合、これらの名前が必須です (これについては後で詳しく説明します)materialization_settings(省略可能): 効率よく取得するために具体化ストアに特徴量の値をキャッシュする場合は必須です。
ローカル/開発環境で特徴量セットの仕様を開発およびテストした後、仕様を特徴量セット資産として特徴量ストアに登録できます。 特徴量セット資産は、バージョン管理や具体化などの管理機能を提供します。
特徴量セット YAML 仕様の詳細については、「CLI (v2) 特徴量セット仕様 YAML スキーマ」を参照してください
機能取得の仕様
特徴量取得仕様は、モデルに関連付けられた特徴量一覧の移植可能な定義です。 これは、機械学習モデルの開発と運用化を効率化するのに役立つ場合があります。 特徴量取得仕様は、通常、トレーニング パイプラインへの入力です。 トレーニング データを生成するのに役立ちます。 これはモデルと共にパッケージ化できます。 さらに、推論ステップではこれを使用して特徴量を検索します。 これは、機械学習ライフサイクルのすべてのフェーズを統合します。 トレーニングと推論パイプラインの変更は、実験とデプロイ時に最小限に抑えることができます。
特徴量取得仕様と組み込みの特徴量取得コンポーネントの使用は任意です。 必要に応じて、get_offline_features() API を直接使用できます。
特徴量取得 YAML 仕様の詳細については、「CLI (v2) 特徴量取得仕様 YAML スキーマ」を参照してください。