Azure AI Search でのセマンティック ランク付け
Azure AI 検索では、"セマンティック ランカー" は、検索結果を再ランク付けするために Microsoft の言語理解モデルを使用して検索の関連性をある程度高める機能です。 この記事は、セマンティック ランカーの動作と利点を理解するのに役立つ概要です。
セマンティック ランカーはプレミアム機能であり、使用量に基づいて課金されます。 最初にこの記事を読んで基礎知識を得ることをお勧めしますが、すぐに始める場合は、こちらの手順に従ってください。
Note
セマンティック ランカーは、生成 AI やベクトルを使用しません。 ベクトルのサポートと類似性検索をお探しの場合は、詳細について、Azure AI 検索のベクトル検索に関するページを参照してください。
セマンティック ランク付けとは
セマンティック ランカーは、テキストベースのクエリ、ベクトル クエリ、ハイブリッド クエリに対する最初の BM25 ランク付けまたは RRF ランク付け検索結果の品質を高めるクエリ側機能のコレクションです。 これを検索サービスで有効にすると、セマンティック ランク付けによってクエリの実行パイプラインに 2 つの機能が追加されます。
1 つ目として、BM25 または Reciprocal Rank Fusion (RRF) を使用してスコア付けされた最初の結果セットに対する二次ランク付けが追加されます。 この二次ランク付けでは多言語の、Microsoft Bing から変化したディープ ラーニング モデルが使用されて、セマンティック的に最も関連性の高い結果が奨励されます。
2 つ目として、キャプションと回答が抽出されて応答で返されます。これを検索ページにレンダリングして、ユーザーの検索エクスペリエンスを向上させることができます。
セマンティック リランカーの機能を次に示します。
| 機能 | 説明 |
|---|---|
| L2 ランク付け | クエリのコンテキストまたはセマンティックの意味を利用して、事前にランク付けされた結果に対して新しい関連スコアを計算します。 |
| セマンティック キャプションとハイライト | コンテンツを最もよく要約している逐語的な文やフレーズをフィールドから抽出し、簡単にスキャンできるように重要な文節を強調表示します。 結果を要約するキャプションは、個々のコンテンツ フィールドが検索結果ページに対して高密度である場合に便利です。 強調表示されたテキストにより、最も関連性の高い用語とフレーズが目立つため、ユーザーはその一致が関連していると見なされた理由を迅速に判断できます。 |
| セマンティック回答 | セマンティック クエリから返される省略可能な追加のサブ構造体。 これにより、質問のようなクエリに直接回答することができます。 ドキュメントには、回答の特性を持つテキストが含まれている必要があります。 |
セマンティック ランカーのしくみ
セマンティック ランカーは、Microsoft がホストする言語理解モデルにクエリと結果をフィードし、より適切な一致をスキャンします。
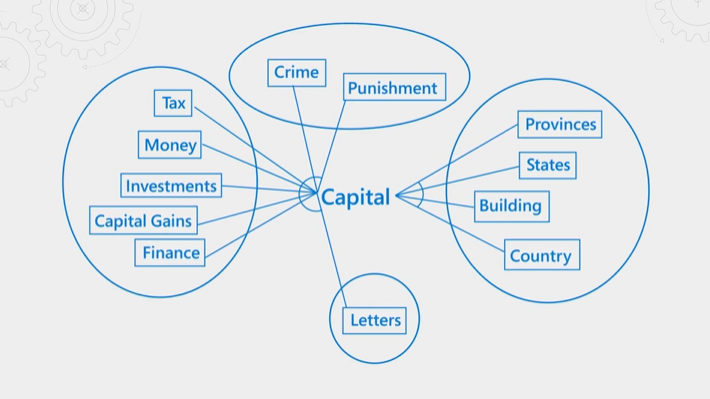
コンセプトを次の図で説明します。 "capital" という用語を考えてみましょう。 これは、コンテキストが財務、法律、地理、文法なのかによって意味が異なります。 言語理解では、セマンティックのランカーによってコンテキストが検出され、クエリの意図に沿う結果が昇格されます。
セマンティックの順位付けは、リソースと時間の両方を消費します。 クエリ操作の予想待機時間内に処理を完了するために、セマンティック ランク付けへの入力が統合され、削減されるため、再ランク付けの手順をできるだけ早く完了できます。
セマンティック ランク付けには、次の 3 つの手順があります。
- 入力を収集して要約する
- セマンティック ランカーを使用して結果をスコア付けする
- 再スコア付けされた結果、キャプション、回答を出力する
入力が収集されて要約されるしくみ
セマンティック ランク付けでは、クエリのサブシステムからサマライゼーション モデルとランク付けモデルに検索結果が入力として渡されます。 ランク付けモデルには入力サイズに制約があり、集中的に処理されるため、検索結果は効率的に処理できるようなサイズで構造化 (要約) されている必要があります。
セマンティック ランカーは、テキスト クエリの BM25 ランク付け結果、またはベクトル クエリまたはハイブリッド クエリの RRF ランク付け結果から開始します。 テキスト フィールドのみが再ランク付け実行で使用され、結果の数が 50 個を超える場合でも、セマンティック ランク付けが行われるのは上位 50 個の結果のみです。 通常、セマンティック ランク付けで使用されるフィールドは、情報を提供する説明的なものです。
検索結果の中の各ドキュメントで、サマライゼーション モデルが受け入れるのは 2,000 トークンまでで、この場合、1 トークンはおよそ 10 文字です。 入力がセマンティック構成の一覧にある "title"、"keyword"、および "content" フィールドからアセンブルされます。
長さが非常に長い文字列は、全体の長さが概要作成手順の入力要件を満たすようにトリミングされます。 優先順位の高い順序でセマンティック構成にフィールドを追加することが重要なのは、このトリミングの実行があるためです。 テキストを多用するフィールドを持つ非常に大きいドキュメントがある場合は、最大値制限を超えたテキストは無視されます。
セマンティック フィールド トークンの限度 「タイトル」 128 トークン "keywords 128 トークン "content" 残りのトークン サマライゼーション出力は各ドキュメントの要約文字列であり、各フィールドの中の最も関連した情報で構成されます。 要約文字列がスコアリングのためランカーへ送られて、キャプションと回答を求めて機械読み取り理解モデルへ送られます。
セマンティック ランカーへ渡されるそれぞれの生成後の要約文字列の最大長さは、256 トークンです。
ランク付けにスコア付けする方法
スコアリングは、キャプションと、256 のトークン長を埋める要約文字列の中の他のあらゆるコンテンツに対して行われます。
キャプションは、指定されたクエリに対して相対的な概念とセマンティックの関連性に対して評価されます。
@search.rerankerScore が各ドキュメントに、指定のクエリのドキュメントのセマンティック関連性に基づいて割り当てられます。 スコアの範囲は 4 から 0 (高から低) です。スコアが高いほど関連性が高いことを示します。
スコア 意味 4.0 ドキュメントは関連性が高く、質問に完全に回答しますが、文節には、質問と関係のない追加のテキストが含まれている可能性があります。 3.0 ドキュメントは、関連性はありますが、完全なものにする詳細は含まれていません。 2.0 ドキュメントは、ある程度関連性があり、質問に部分的に回答するか、質問の一部の側面にのみ対処します。 1.0 ドキュメントは質問に関連しており、質問のほんの一部に回答します。 0.0 ドキュメントは関連性がありません。 一致は、スコア順に一覧表示され、クエリ応答ペイロードに含められます。 ペイロードには、回答、プレーンテキスト、強調表示されたキャプション、select 句で取得または指定されたフィールドが含まれます。
Note
特定のクエリでは、@search.rerankerScore のディストリビューションが、インフラストラクチャ レベルの条件により、若干異なる場合があります。 ランク付けモデルの更新もディストリビューションに影響することがわかっています。 これらの理由から、最小しきい値のカスタム コードを記述する場合や、ベクトル クエリとハイブリッド クエリにしきい値プロパティを設定する場合は、制限を細かくしすぎないでください。
セマンティック ランカーの出力
各要約文字列から、機械読み取り理解モデルは最も代表的な一節を見つけ出します。
出力は次のようになります:
ドキュメントのセマンティック キャプション。 各キャプションは、プレーン テキスト バージョンと強調表示バージョンで使用できます。また、多くの場合、ドキュメントあたり 200 語未満です。
answersパラメーターを指定した場合、クエリが質問として提示された場合、その質問に対して適していそうな回答を提供する長い文字列で文節が見つかる場合を想定し、オプションのセマンティック回答が返されます。
キャプションと回答は、常にインデックスからの逐語的なテキストです。 このワークフローには、新しいコンテンツを作成または構成する生成 AI モデルはありません。
セマンティック機能と制限
セマンティック ランカーは新しいテクノロジなので、実行できることとできないことについての期待値を設定することが重要です。 "できること" は、次のようなことです。
セマンティック的に元のクエリの意図に近い一致を昇格させます。
キャプションおよび回答として使用できる文字列を見つけ出します。 キャプションと回答は応答で返され、検索結果ページに表示できる文字列が検出されます。
セマンティック ランカーで "できない" ことは、コーパス全体に対してクエリを再実行し、意味的に関連性がある結果を検出することです。 セマンティック ランク付けでは、既定のランク付けアルゴリズムによってスコアリングされた上位 50 個の結果で構成される既存の結果セットが再ランク付けされます。 さらに、セマンティック ランカーで新しい情報や文字列を作成することもできません。 キャプションと回答は、コンテンツから逐語的に抽出されるので、結果に回答のようなテキストが含まれていない場合、その言語モデルではキャプションや回答は生成されません。
セマンティック ランク付けはすべてのシナリオで有益なわけではありませんが、特定のコンテンツではその機能から多くのメリットが得られます。 セマンティック ランカーの言語モデルは、情報が豊富で、散文として構造化された検索可能なコンテンツに最適です。 ナレッジ ベース、オンライン ドキュメント、または説明的なコンテンツを含むドキュメントでは、セマンティック ランカー機能から最も多くのメリットが得られます。
テクノロジは Bing と Microsoft Research が基になっており、Azure AI Search インフラストラクチャにアドオン機能として統合されます。 セマンティック ランカーを支える研究と AI 投資に関する詳細については、「Bing の AI が Azure AI 検索にパワーを与えるしくみ (Microsoft Research ブログ)」を参照してください。
次の動画では、機能の概要について説明しています。
可用性と料金
セマンティック ランカーは、利用可能なリージョンにおいて、Basic レベル以上の検索サービスで使用できます。
セマンティック ランカーを有効にする場合は、機能に対応する価格プランを選択します。
- クエリ ボリュームが低い場合 (月間 1000 件未満)、セマンティック ランク付けは無料です。
- クエリのボリュームが大きい場合、標準価格プランを選択します。
Azure AI Search の価格ページでは、さまざまな通貨とサイクル間隔での課金レートが表示されます。
セマンティック ランカーの料金は、クエリ要求に queryType=semantic が含まれ、検索文字列が空ではない場合 (例: search=pet friendly hotels in New York) に課されます。 検索文字が空の場合 (search=*)、queryType が semantic に設定されていても課金されません。
セマンティック ランカーの使用を開始する方法
Azure portal にサインインして、検索サービスが Basic 以上であることを確認します。