Azure AI Search でベクトル クエリを作成する
この記事では、Azure AI 検索でベクトル インデックスがある場合の、次の方法について説明します。
この記事では、図示するために REST を使用しています。 他の言語のコード サンプルの場合、ベクトル クエリを含むエンドツーエンドのソリューションについては、azure-search-vector-samples GitHub リポジトリを参照してください。
Azure portal で Search エクスプローラーを使うこともできます。
前提条件
任意のリージョンおよび任意のレベルの Azure AI Search。
Azure AI 検索のベクトル インデックス。 インデックスの
vectorSearchセクションを調べて、ベクトル インデックスを確認します。必要に応じて、クエリ中のテキストからベクトルまたは画像からベクトルへの組み込み変換のために、インデックスにベクトライザーを追加することもできます。
これらの例を自分で実行する場合の REST クライアントとサンプル データを含む Visual Studio Code。 REST クライアントの使用を開始するには、「クイック スタート: REST を使用した Azure AI Search」を参照してください。
クエリ文字列入力をベクトルに変換する
ベクトル フィールドに対してクエリを実行するには、クエリ自体がベクトルである必要があります。
ユーザーのテキスト クエリ文字列をそのベクトル表現に変換するための 1 つのアプローチは、アプリケーション コード内で埋め込みライブラリまたは API を呼び出すことです。 ソース ドキュメントに埋め込みを生成するために使用したのと同じ埋め込みを常に使用することをお勧めします。 azure-search-vector-samples リポジトリで、埋め込みを生成する方法を示すコード サンプルを見つけることができます。
2 番目のアプローチは、(一般提供されるようになった) 垂直統合を使うことです。Azure AI 検索がクエリのベクトル化の入力と出力を処理します。
Azure OpenAI 埋め込みモデルのデプロイに送信されるクエリ文字列の REST API の例を次に示します:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
デプロイされたモデルの呼び出しが成功した場合、予想される応答は 202 です。
応答の本文の "埋め込み" フィールドは、クエリ文字列 "input" のベクトル表現です。 テスト目的で、次のいくつかのセクションで示す構文を使用して、クエリ要求の "embedding" 配列の値を "vectorQueries.vector" にコピーします。
デプロイされたモデルに対するこの POST 呼び出しの実際の応答には、1536 個の埋め込みが含まれています。ここでは、読みやすくするために最初のいくつかのベクトルのみにトリミングされています。
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
このアプローチでは、アプリケーション コードはモデルへの接続、埋め込みデータの生成、応答の処理を担当します。
ベクトル クエリ要求
このセクションでは、ベクトル クエリの基本的な構造を説明します。 Azure portal、REST API、または Azure SDK を使用して、ベクトル クエリを作成できます。 2023-07-01-Preview から移行する場合、重大な変更があります。 詳細については、「最新の REST API にアップグレードする」を参照してください。
2024-07-01 は Search POST の安定バージョンの REST API です。 このバージョンでは次の内容がサポートされます。
vectorQueriesはベクトル検索のコンストラクトです。vectorQueries.kindをベクトル配列のvectorに設定します。または、入力が文字列でありベクトライザーを使用している場合はtextに設定します。vectorQueries.vectorはクエリです (テキストや画像のベクトル表現)。vectorQueries.weight(省略可能) によって、検索操作に含まれる各ベクトル クエリの相対的な重みを指定します (「ベクトルの重み付け」を参照)。exhaustive(省略可能) では、HNSW のフィールドにインデックスを付けた場合でも、クエリ時に完全な KNN を呼び出します。
次の例では、文字列「フル テキスト検索をサポートする Azure サービス」をベクトルで表現しています。 クエリは contentVector フィールドを対象にしています。 クエリでは、k の結果が返されます。 実際のベクトルには 1536 個の埋め込みがあるため、この例では読みやすくするためにトリミングされています。
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
ベクトル クエリ応答
Azure AI Search では、クエリ応答は既定ですべての retrievable フィールドで構成されます。 ただし、retrievable フィールドのサブセットを select ステートメントに一覧表示することで、検索結果を制限することは一般的です。
ベクトル クエリでは、応答のフィールドをベクトル化する必要があるかどうかを注意深く検討してください。 ベクトル フィールドは人間が判読できないので、応答を Web ページにプッシュする場合は、結果を代表する非ベクトル フィールドを選択する必要があります。 たとえば、contentVector に対してクエリが実行された場合、代わりに content を返すことができます。
結果にベクトル フィールドが必要な場合は、ここに応答構造の例を示します。 contentVector は埋め込みの文字列配列で、ここでは簡潔にするために切り捨てています。 検索スコアは関連性を示します。 その他の非ベクトル フィールドもコンテキストのために含まれています。
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
重要なポイント:
kは、返されるニアレストネイバー結果の数を決定します。この場合は 3 です。 ベクター クエリは常にk結果を返します。少なくともkドキュメントが存在すると仮定すると、類似度の低いドキュメントがある場合でも、アルゴリズムはクエリ ベクターに最も近いkを検出します。@search.scoreはベクトル探索アルゴリズムによって決定されます。検索結果のフィールドは、すべての
retrievableフィールド、またはselect句のフィールドです。 ベクトル クエリの実行中は、ベクトル データのみで一致が行われます。 ただし、応答には、インデックスに任意のretrievableフィールドを含めることができます。 ベクトル フィールド結果をデコードする機能はないため、非ベクトル テキスト フィールドを含めることは、人間が値を判読するのに役立ちます。
複数のベクトル フィールド
"vectorQueries.fields" プロパティを複数のベクトル フィールドに設定できます。 ベクトル クエリは fields リストで指定した各ベクトル フィールドに対して実行されます。 複数のベクトル フィールドにクエリを実行する場合、それぞれのベクトル フィールドに同じ埋め込みモデルからの埋め込みが含まれていること、クエリも同じ埋め込みモデルから生成されていることを確認してください。
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
複数のベクトル クエリ
マルチクエリ ベクトル検索では、検索インデックス内の複数のベクトル フィールドに対して複数のクエリが送信されます。 このクエリ要求の一般的な例は、同じモデルが画像とテキストコンテンツをベクトル化できるマルチモーダル ベクトル検索に CLIP などのモデルを使用する場合です。
次のクエリ例では、myImageVector と myTextVector の両方の類似性を検索しますが、それぞれ 2 つの異なるクエリ埋め込みを送信し、それぞれ並列で実行します。 このクエリでは、Reciprocal Rank Fusion (RRF) を使用してスコア付けされた結果が生成されます。
vectorQueriesでベクトル クエリの配列が指定されます。vectorには、検索インデックス内の画像ベクトルとテキスト ベクトルが含まれています。 各インスタンスは個別のクエリです。fieldsでターゲットとなるベクトル フィールドが指定されます。kは、結果に含めるニアレストネイバーの数です。
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
検索インデックスに画像ファイルのフィールドが含まれていると仮定すると、検索結果にはテキストと画像の組み合わせが含まれます (検索インデックスには画像が格納されません)。
垂直統合を使用したクエリ
このセクションでは、テキストまたは画像クエリをベクトルに変換する垂直統合を呼び出すベクトル クエリについて説明します。 この機能には、安定版の 2024-07-01 REST API、Search エクスプローラー、またはそれ以降の Azure SDK パッケージを使うことをお勧めします。
検索インデックスのベクトル フィールドに、ベクトル化が設定されて割り当て済みであることが前提条件です。 ベクトル化では、クエリ時に使用された接続情報が埋め込みモデルに指定されます。
Search エクスプローラーでは、クエリ時の垂直統合がサポートされています。 インデックスにベクトル フィールドが含まれており、ベクトライザーを使用している場合は、テキストからベクトルへの組み込み変換を使用できます。
Azure アカウントを使用して Azure portal にサインインし、Azure AI Search サービスに移動します。
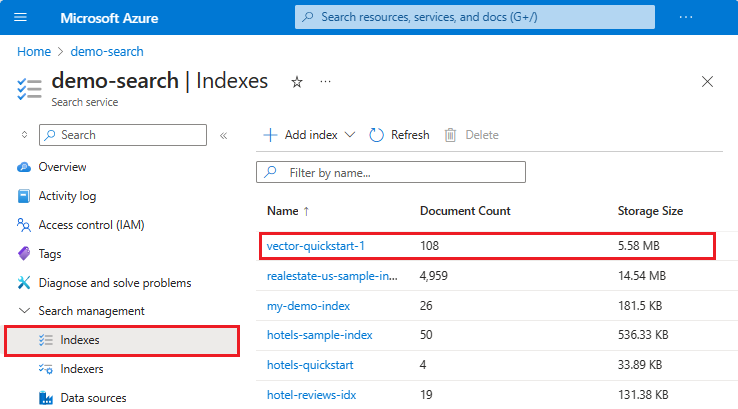
左側のメニューで [検索管理]>[インデックス] を展開し、インデックスを選択します。 Search エクスプローラーは、インデックス ページの最初のタブです。
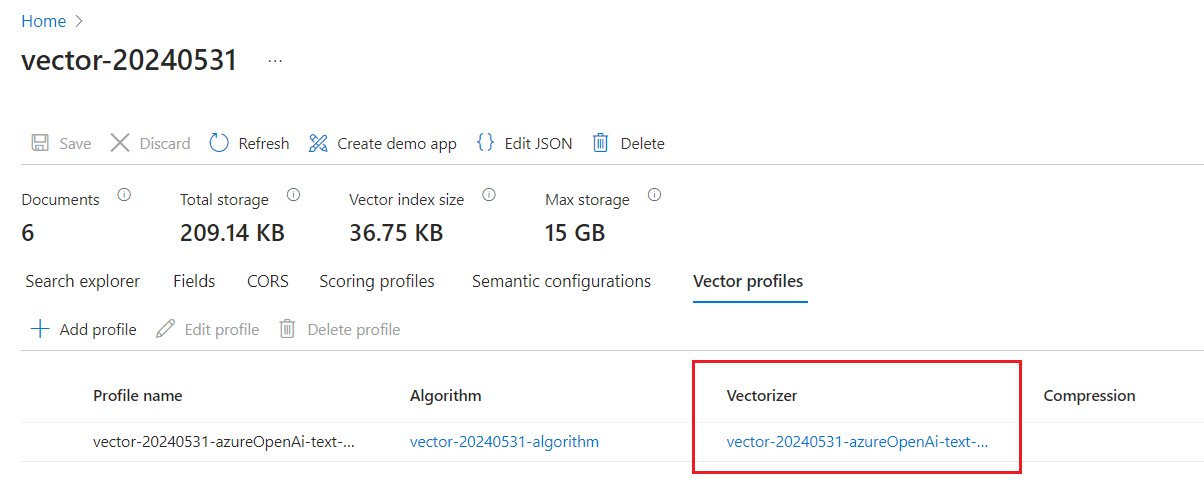
ベクトル プロファイルをチェックして、ベクトライザーがあることを確認します。
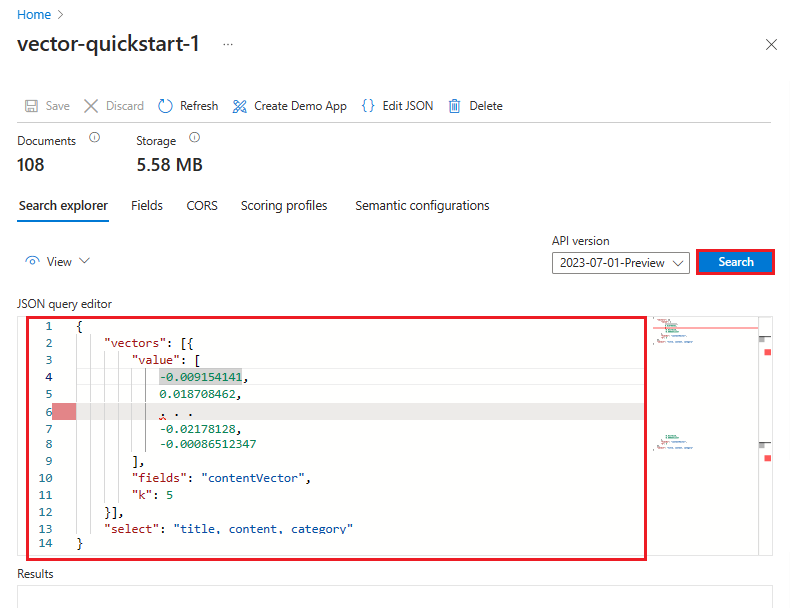
Search エクスプローラーで、クエリ ビューの既定の検索バーにテキスト文字列を入力できます。 組み込みベクトライザーにより、文字列がベクトルに変換され、検索が実行されて、結果が返されます。
または、[表示]>[JSON ビュー] を選択して、クエリを表示または変更することもできます。 ベクトルが存在する場合、Search エクスプローラーによって自動的にベクトル クエリが設定されます。 JSON ビューを使うと、検索や応答で使用されるフィールドを選択したり、フィルターを追加したり、ハイブリッドなどのより高度なクエリを作成したりできます。 JSON の例は、このセクションの [REST API] タブで説明しています。
ベクトル クエリ応答のランク付けされた結果の数
ベクター クエリは、結果で返される一致の数を決定する k パラメーターを指定します。 検索エンジンは常に一致を k 個返します。 k がインデックス内のドキュメントの数より大きい場合は、ドキュメントの数によって返される内容の上限が決まります。
フル テキスト検索に慣れている場合、インデックスに用語または語句が含まれていなければ、結果が 0 になると予想されます。 ただし、ベクター検索では、検索操作は最も近い近傍を識別し、最も近い近隣ノードが類似していない場合でも常に k 個の結果を返します。 そのため、特にプロンプトを使用して境界を設定していない場合は、無意味なクエリやトピック外のクエリの結果を取得できます。 関連性の低い結果は類似度スコアが悪くなりますが、近いものがない場合でも"ニアレスト" ベクトルです。 そのため、意味のある結果のない応答でも k 結果を返すことができますが、各結果の類似性スコアは低くなります。
フルテキスト検索を含むハイブリッド アプローチでは、この問題を軽減できます。 もう 1 つの軽減策は、クエリが純粋な単一ベクター クエリの場合にのみ、検索スコアに最小しきい値を設定することです。 ハイブリッド クエリは、RRF 範囲が非常に小さく揮発性であるため、最小しきい値には役立たない。
結果数に影響するクエリ パラメーターは次のとおりです:
- ベクトルのみのクエリの結果として
"k": n - "search" パラメーターを含むハイブリッド クエリの結果として
"top": n
"k" と "top" はどちらも省略可能です。 指定しない場合、応答の結果の既定の数は 50 です。 "top" と "skip" を設定して、より多くの結果をページングしたり、既定値を変更したりできます。
ベクトル クエリで使用されるランキング アルゴリズム
結果のランク付けは、次のいずれかによって計算されます:
- 類似性メトリック
- 検索結果のセットが複数ある場合の Reciprocal Rank Fusion (RRF)。
類似性メトリック
ベクトルのみのクエリのインデックス vectorSearch セクションで指定された類似性メトリック。 有効な値は、cosine、euclidean、dotProduct です。
Azure OpenAI 埋め込みモデルではコサイン類似性が使用されるため、Azure OpenAI 埋め込みモデルを使用している場合は、cosine が推奨されるメトリックです。 その他のサポートされているランク付けメトリックには、euclidean と dotProduct があります。
RRF の使用
クエリが複数のベクトル フィールドを対象とし、複数のベクトル クエリを並行して実行する場合、またはクエリがベクトル検索とフルテキスト検索のハイブリッドである場合、セマンティック ランク付けの有無にかかわらず、複数のセットが作成されます。
クエリの実行中は、ベクトル クエリは 1 つの内部ベクトル インデックスのみを対象とすることができます。 そのため、ベクトル フィールド と 複数のベクトル クエリの場合、検索エンジンは、各フィールドのそれぞれのベクトル インデックスを対象とする複数のクエリを生成します。 出力は、RRF を使用して融合される各クエリのランク付けされた結果のセットです。 詳細については、「Reciprocal Rank Fusion (RRF) を使用した関連性スコアリング」を参照してください。
ベクトルの重み付け
検索操作に含まれる各ベクトル クエリの相対的な重みを指定するには、weight クエリ パラメーターを追加します。 この値は、同じ要求内の 2 つ以上のベクトル クエリによって、またはハイブリッド クエリのベクトル部分から生成された、複数のランク付けリストの結果を結合するときに使用されます。
既定値は 1.0 で、値は 0 より大きい正の数値である必要があります。
重みは、各ドキュメントの 逆ランク融合 スコアを計算するときに使用されます。 計算は、それぞれの結果セット内のドキュメントのランク スコアに対する weight 値の乗数です。
次の例は、2 つのベクトル クエリ文字列と 1 つのテキスト文字列を含むハイブリッド クエリです。 重みはベクトル クエリに割り当てられます。 最初のクエリは 0.5、つまり半分の重みであり、要求での重要度が低下します。 2 番目のベクトル クエリは重要度が 2 倍になります。
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
ベクトルの重み付けは、ベクトルにのみ適用されます。 この例のテキスト クエリ ("hello world") の暗黙的な重みは、1.0 またはニュートラルな重みです。 ただし、ハイブリッド クエリでは、maxTextRecallSize を設定することで、テキスト フィールドの重要度を増減できます。
しきい値を設定してスコアの低い結果を除外する (プレビュー)
ニアレストネイバー検索では要求された k 個の近傍が常に返されるため、検索結果で k の数の要件を満たす一環として、スコアの低い複数の一致が取得される可能性があります。 スコアの低い検索結果を除外するには、最小スコアに基づいて結果を除外する threshold クエリ パラメーターを追加できます。 フィルター処理は、複数のリコール セットの結果を融合する前に発生します。
このパラメーターはまだプレビュー段階です。 プレビュー バージョンの REST API 2024-05-01-preview を使うことをお勧めします。
この例では、結果の数が k を下回る場合でも、0.8 未満のスコアのすべての一致がベクトル検索結果から除外されます。
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
ハイブリッド検索用の MaxTextSizeRecall (プレビュー)
ベクトル クエリは、非ベクトル フィールドを含むハイブリッド コンストラクトでよく使用されます。 ハイブリッド クエリの結果における BM25 ランクの結果の出現が多すぎる、または少なすぎる場合、maxTextRecallSize を設定して、ハイブリッド ランク付けに対して提供された BM25 ランクの結果を増減させることができます。
このプロパティは、"search" コンポーネントと "vectorQueries" コンポーネントの両方を含むハイブリッド要求でのみ設定できます。
このパラメーターはまだプレビュー段階です。 プレビュー バージョンの REST API 2024-05-01-preview を使うことをお勧めします。
詳細については、maxTextRecallSize の設定 - ハイブリッド クエリの作成に関する記事を参照してください。
次のステップ
次の手順として、Python、C#、JavaScript のベクトル クエリ コードの例を確認してください。