Azure Service Fabric を監視する
この記事では、次の内容について説明します。
- このサービスに対して収集できる監視データの種類。
- そのデータを分析する方法。
Note
このサービスや Azure Monitor を既に使い慣れていて、監視データの分析方法だけを確認したい場合は、この記事で後述する分析に関するセクションをご覧ください。
Azure リソースに依存するクリティカルなアプリケーションやビジネス プロセスがある場合は、システムを監視し、そのアラートを受け取る必要があります。 Azure Monitor サービスでは、システムのすべてのコンポーネントからメトリックとログを収集して集計します。 Azure Monitor を使用すると、可用性、パフォーマンス、回復性を視覚化し、問題に関する通知を受け取ることができます。 Azure portal、PowerShell、Azure CLI、REST API、またはクライアント ライブラリは、監視データの設定および表示に使用できます。
- Azure Monitor の詳細については、「Azure Monitor の概要」を参照してください。
- Azure リソース全般の監視方法の詳細については、「Azure Monitor を使用した Azure リソースの監視」をご覧ください。
Azure Service Fabric の監視
Azure Service Fabric には、監視できる次のレイヤーがあります。
- アプリケーション監視: ノード上で実行される "アプリケーション"。 Application Insights キー、SDK、EventStore、または ASP.NET Core ログを使用してアプリケーションを監視できます。
- プラットフォーム (クラスター) 監視: "プラットフォーム" または "クラスター" ノードのクライアント メトリック、ログ、イベント (コンテナー メトリックを含む)。 メトリックとログは、Linux または Windows ノードで異なります。
- インフラストラクチャ (パフォーマンス) 監視: サービス "インフラストラクチャ" のサービス正常性およびパフォーマンス カウンター。
アプリケーションの使われ方、Service Fabric プラットフォームによって実行されたアクション、パフォーマンス カウンターでのリソース使用率、クラスターの全体的な正常性を監視できます。 Azure Monitor ログと Application Insights には、Service Fabric との統合が組み込まれています。
- ベスト プラクティスについては、「Azure Service Fabric の監視と診断のベスト プラクティス」を参照してください。
- Service Fabric のイベントと正常性レポートを表示する方法、EventStore API に対するクエリを実行する方法、パフォーマンス カウンターを監視する方法を示すチュートリアルについては、「チュートリアル: Azure 内で Service Fabric クラスターを監視する」を参照してください。
- Service Fabric でオーケストレーションされた Windows コンテナーを監視するように Azure Monitor ログを構成する方法については、「チュートリアル: Azure Monitor ログを使用して Service Fabric 上の Windows コンテナーを監視する」を参照してください。
Service Fabric Explorer
Windows、macOS、Linux 用のデスクトップ アプリケーションである Service Fabric Explorer は、Azure Service Fabric クラスターを検査および管理するためのオープンソース ツールです。 自動化を有効にするために、Service Fabric Explorer を使用して実行できるアクションはすべて、PowerShell または REST API を使用して実行することもできます。
アプリケーションの監視
アプリケーションの監視は、アプリケーションの機能やコンポーネントがどのように使用されているかを追跡します。 お客様は、アプリケーションを監視して、ユーザーに影響が及ぶ問題を把握したいと考えます。 ビジネス ロジックはアプリケーションごとに固有なので、アプリケーションとそのサービスを開発するユーザーに、アプリケーションを監視する責任があります。 アプリケーションの監視は、次のシナリオで役立ちます。
- アプリケーションで発生しているトラフィックの量を知りたい。 - ユーザーのニーズを満たすために、またはアプリケーションの潜在的なボトルネックに対処するために、サービスを拡張する必要があるかどうかを判断できます。
- サービス間の呼び出しが成功して追跡されているかどうか知りたい。
- アプリケーションのユーザーによって実行されたアクションを知りたい。 - テレメトリを収集すると、将来機能を開発したり、アプリケーション エラーを適切に診断したりするときに参考になります
- アプリケーションでハンドルされない例外がスローされているか知りたい。
- コンテナーの内部で実行されているサービス内で起きていることを知りたい。
アプリケーション監視のすばらしい点は、アプリケーションのコンテキスト内で動作するため、開発者は好みのツールやフレームワークを何でも使用できることです。 Azure Monitor Application Insights を使用したアプリケーション監視の Azure ソリューションに関して詳しくは、Application Insights によるイベント分析に関する記事をご覧ください。
.NET アプリケーション用にこれを設定する方法についてのチュートリアルもあります。 このチュートリアルでは、適切なツールをインストールする方法、アプリケーションでカスタム テレメトリを記述する例、Azure portal でのアプリケーションの診断とテレメトリの表示について説明されています。
アプリケーションのログ記録
コードのインストルメント化は、ユーザーに関する分析情報を得る方法であるだけでなく、アプリケーションに異常があるかどうかを把握し、必要な修正を診断できる唯一の方法でもあります。 運用環境のサービスへのデバッガーの接続は技術的には可能ですが、一般的な方法ではありません。 そのため、詳細なインストルメンテーション データを入手することが重要です。
コードを自動的にインストルメント化する製品もあります。 これらのソリューションでうまくいくこともありますが、ほとんどの場合、ビジネス ロジックに固有の手動インストルメント化が必要になります。 最終的には、アプリケーションのフォレンジックなデバッグを実行できるだけの十分な情報が必要です。 任意のログ記録フレームワークで、Service Fabric アプリケーションをインストルメント化することができます。 このセクションでは、コードをインストルメント化するためのいくつかの方法と、それぞれを選択するべきタイミングについて説明します。
Application Insights SDK: Application Insights にはすぐに利用できる Service Fabric とのリッチな統合が用意されています。 ユーザーは、AI Service Fabric NuGet パッケージを追加したり、作成および収集された、Azure Portal で表示可能なデータとログを受信したりできます。 また、アプリケーションを診断およびデバッグするためと、どのサービスとアプリケーションのどの部分が最も使用されているかを追跡するために、独自の利用統計情報を追加することが推奨されます。 SDK の TelemetryClient クラスには、アプリケーションの利用統計情報を追跡するためのさまざまな方法が用意されています。 詳細については、「Application Insights を使用したイベント分析と視覚化」を参照してください。
.NET アプリケーションの監視と診断に関するチュートリアルで、Application Insights をインストルメント化してアプリケーションに追加する方法の例を確認してください。
EventSource: Visual Studio でテンプレートから Service Fabric ソリューションを作成すると、EventSource 派生クラス (ServiceEventSource または ActorEventSource) が生成されます。 アプリケーションまたはサービスのイベントを追加できるテンプレートが作成されます。 EventSource の名前は一意である必要があり、MyCompany-<solution>-<project> という既定のテンプレート文字列から名前を変更する必要があります。 同じ名前を使用する複数の EventSource 定義があると、実行時に問題が発生します。 定義済みの各イベントには一意の識別子が必要です。 識別子が一意でない場合、ランタイム エラーが発生します。 個々の開発チーム間での競合を回避するために、識別子の値の範囲を事前に割り当てている組織もあります。 詳細については、Vance のブログまたは MSDN ドキュメントをご覧ください。
ASP.NET Core ログ: コードをインストルメント化する方法を入念に計画することが重要です。 適切なインストルメンテーション計画により、コード ベースの安定性が失われ、コードの再インストルメント化が必要になる状況を回避できます。 リスクを軽減するために、Microsoft ASP.NET Core の一部である Microsoft.Extensions.Logging などのインストルメンテーション ライブラリを選択できます。 ASP.NET Core には、既存のコードへの影響を最小限に抑えながら、選択したプロバイダーで使用できる ILogger インターフェイスがあります。 Windows および Linux 上の ASP.NET Core 内と完全な .NET Framework 内でコードを使用できるので、インストルメンテーション コードが標準化されます。
これらの提案の使用方法の例については、「Service Fabric アプリケーションにログ記録を追加する」をご覧ください。
プラットフォーム (クラスター) 監視
アプリケーションから送られてくるテレメトリはユーザーが自分でコードを書くのでユーザーの制御下にありますが、Service Fabric プラットフォームからの診断はどうでしょうか。 Service Fabric の目標の 1 つは、ハードウェア障害に対するアプリケーションの回復力を維持することです。 この目標を実現するには、プラットフォームのシステム サービスの機能を利用します。この機能は、インフラストラクチャの問題を特定し、ワークロードをクラスター内の別のノードにすばやくフェールオーバーします。 しかし、このようなケースで、もしシステム サービス自体に問題があるとしたらどうなるでしょうか。 または、ワークロードのデプロイまたは移動でサービス配置のルールに違反したらどうなるでしょうか。 Service Fabric ではこれらやその他についての診断が提供され、ユーザーはクラスターで発生しているアクティビティについての情報を得られます。 クラスター監視のシナリオの例を次に示します。
プラットフォーム (クラスター) 監視の詳細については、「クラスターの監視」を参照してください。
Service Fabric イベント
Service Fabric には、すぐに使用できる診断イベントの包括的なセットが用意されており、EventStore か、プラットフォームで公開される運用イベント チャネルを介してアクセスできます。 これらの Service Fabric イベントでは、ノード、アプリケーション、サービス、パーティションなどのさまざまなエンティティ上で、プラットフォームによって実行されたアクションが示されています。 同じイベントを、Windows と Linux 両方のクラスターで利用できます。
Service Fabric イベント チャンネル: Windows では、Operational および Data & Messaging チャンネルを選択するために使用される関連性のある
logLevelKeywordFiltersのセットを持つ単一の ETW プロバイダーからの Service Fabric イベントが利用できます。 これは、必要に応じてフィルター処理する送信 Service Fabric イベントを分離する方法です。 Linux では、Service Fabric イベントは LTTng 経由で到着し、1 つの Storage テーブルに格納されます。ここで、必要に応じてイベントをフィルター処理できます。 これらのチャネルには、選別され、構造化されたイベントが含まれ、これを使用してクラスターの状態をより詳細に把握できます。 クラスターの作成時には、既定で診断が有効になります。それにより、Azure Storage テーブルが作成され、後でクエリを実行できるように、そこにこれらのチャネルからのイベントが送信されます。EventStore は、Service Fabric Explorer で Service Fabric プラットフォーム イベントを表示し、Service Fabric クライアント ライブラリ REST API を使用してプログラムで表示する機能です。 イベントの時刻に基づいて、ノード、サービス、アプリケーション、クエリごとにクラスター内で行われていることのスナップショット ビューを表示できます。 EventStore API は、Azure 上で実行されている Windows クラスターに対してのみ使用できます。 Windows マシンでは、これらのイベントはイベント ログにフィードされるので、イベント ビューアーで Service Fabric イベントを確認できます。
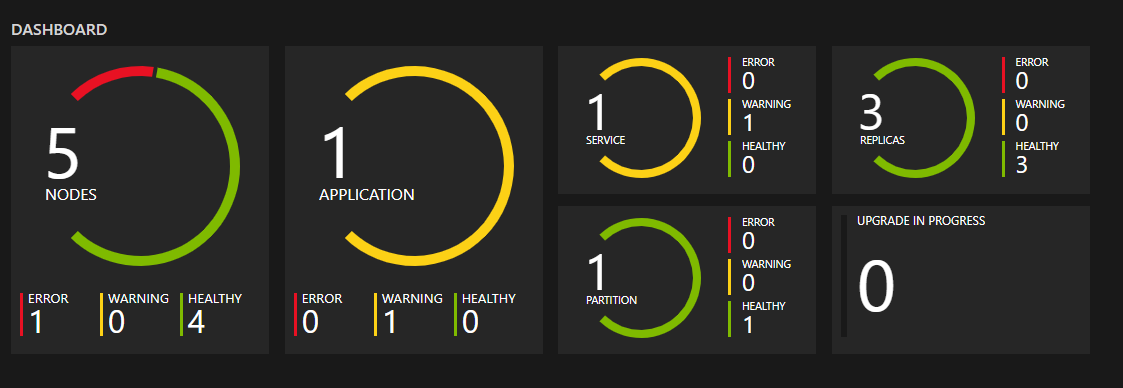
![[ノード] ペインの [イベント] タブに NodeDown イベントなどのいくつかのイベントが表示さているスクリーンショット。](media/service-fabric-diagnostics-overview/eventstore.png)
提供される診断は、既定のイベントの包括的なセットの形式になっています。 これらの Service Fabric イベントでは、ノード、アプリケーション、サービス、パーティションなどのさまざまなエンティティ上で、プラットフォームによって実行されたアクションが示されています。上記の最後のシナリオでは、ノードがダウンした場合、プラットフォームは NodeDown イベントを生成し、ユーザーは自分が選択した監視ツールによってすぐに通知されます。 他の一般的な例としては、フェールオーバーの間の ApplicationUpgradeRollbackStarted や PartitionReconfigured などがあります。 同じイベントを、Windows と Linux 両方のクラスターで利用できます。
イベントは、Windows でも Linux でも標準チャンネル経由で送信され、これらをサポートする任意の監視ツールで読み取ることができます。 Azure Monitor ソリューションは Azure Monitor ログです。 Azure Monitor ログの統合に関する詳細をご覧ください。これには、クラスター用のカスタム操作ダッシュボードと、アラートの作成に使用できるサンプル クエリが含まれています。 クラスター監視の概念について詳しくは、「プラットフォーム レベルのイベントとログの生成」をご覧ください。
正常性の監視
Service Fabric プラットフォームには正常性モデルが組み込まれており、これがクラスター内のエンティティの状態に関する拡張可能な正常性レポートを提供します。 各ノード、アプリケーション、サービス、パーティション、レプリカ、またはインスタンスには、継続的に更新可能な正常性状態が存在します。 正常性状態は、"OK"、"警告"、"エラー" のいずれかになります。 Service Fabric のイベントはさまざまなエンティティに対してクラスターによって実行された動詞として、正常性は各エンティティの形容詞として、考えることができます。 特定のエンティティの正常性が変化するたびに、イベントも生成されます。 これにより、他のイベントと同様に、任意の監視ツールで正常性イベントに対するクエリとアラートを設定できます。
さらに、ユーザーがエンティティの正常性をオーバーライドすることさえできるようになっています。 アプリケーションをアップグレードしようとしていて検証テストが失敗している場合は、アプリケーションが正常でなくなったことを示す Health API を使用して、Service Fabric Health に書き込みを行うと、Service Fabric はアップグレードを自動的にロールバックします。 正常性モデルについて詳しくは、「Service Fabric の正常性モニタリングの概要」をご覧ください
ウォッチドッグ
一般的に、ウォッチドッグとは、複数のサービスにわたって正常性と負荷を監視し、エンドポイントに ping を送信し、クラスター内の予期しない正常性イベントを報告する個別のサービスを指します。 これは、1 つのサービスのパフォーマンスのみに基づくと検出されない可能性があるエラーを防ぐために役立ちます。 またウォッチドッグは、ユーザー操作を必要としない修復アクションを実行するコードをホストする場所としても適しています。たとえば、特定の時間間隔でのストレージ内のログ ファイル クリーンアップなどです。 使いやすいウォッチドッグ拡張モデルを含み、Windows と Linux の両方のクラスターで動作する、完全に実装されたオープン ソースの SF ウォッチドッグ サービスが必要な場合は、FabricObserver プロジェクトを参照してください。 FabricObserver は、実稼働可能なソフトウェアです。 テストおよび運用クラスターに FabricObserver をデプロイし、そのプラグイン モデルを使用してニーズに合わせて拡張するか、またはフォークして独自の組み込みのオブザーバーを作成することをお勧めします。 前者 (プラグイン) が推奨される方法です。
インフラストラクチャ (パフォーマンス) の監視
これまではアプリケーションとプラットフォームでの診断について説明してきましたが、ハードウェアが期待どおりに機能していることを知るにはどうすればよいでしょう。 基盤となるインフラストラクチャを監視することは、クラスターやリソース使用率の状態を把握する上で重要です。 システム パフォーマンスの測定は、ワークロードに応じて影響を受ける可能性がある多くの要因に依存します。 これらの要因は通常、パフォーマンス カウンターによって測定されます。 これらのパフォーマンス カウンターは、オペレーティング システム、.NET フレームワーク、Service Fabric プラットフォーム自体など、さまざまなソースから送られてきます。 次のようなシナリオで役に立ちます
- ハードウェアが効率的に利用されているか知りたい。 CPU 90% または CPU 10% のどちらで、ハードウェアを使いたいですか。 これは、クラスターをスケーリングするとき、またはアプリケーションのプロセスを最適化するときに役に立ちます。
- インフラストラクチャの問題を事前に予測したい。 多くの問題では、発生前にパフォーマンスの急激な変化 (低下) があるため、ネットワーク I/O や CPU 使用率などのパフォーマンス カウンターを使用して、問題を事前に予測および診断できます。
インフラストラクチャ レベルで収集されるパフォーマンス カウンターの一覧は、「パフォーマンス メトリック」でご覧いただけます。
クラスター レベルのイベントを監視するには、Azure Monitor ログをお勧めします。 ワークスペースで Log Analytics エージェントを構成したら、次を収集できます。
- CPU 使用率などのパフォーマンス メトリック。
- プロセス レベルの CPU 使用率などの .NET パフォーマンス カウンター。
- 信頼性の高いサービスからの例外の数などの Service Fabric パフォーマンス カウンター。
- CPU 使用率などのコンテナー メトリック。
リソースの種類
Azure では、リソースの種類と ID の概念を使用して、サブスクリプション内のすべてを識別します。 リソースの種類は、Azure で実行されているすべてのリソースのリソース ID の一部でもあります。 たとえば、Microsoft.Compute/virtualMachines は、仮想マシンのリソースの種類の 1 つです。 サービスとそれに関連付けられるリソースの種類の一覧については、リソース プロバイダーに関するページをご覧ください。
同様に、Azure Monitor では、コア監視データがリソースの種類 (名前空間とも呼ばれます) に基づいてメトリックとログに整理されます。 リソースの種類に応じてさまざまなメトリックとログが使用できます。 サービスは、複数のリソースの種類に関連付けられる可能性があります。
Azure Service Fabric のリソースの種類の詳細については、Service Fabric 監視データのリファレンスに関する記事を参照してください。
データ ストレージ
Azure Monitor の場合:
- メトリック データは、Azure Monitor メトリック データベースに保存されます。
- ログ データは、Azure Monitor ログ ストアに保存されます。 Log Analytics は、Azure portal のツールの 1 つであり、このストアに対してクエリを実行することができます。
- Azure アクティビティ ログは、Azure Portal 内の独自のインターフェイスを持つ別のストアです。
必要に応じて、メトリックおよびアクティビティ ログ データを Azure Monitor ログ ストアにルーティングできます。 次に、Log Analytics を使用してデータのクエリを実行し、他のログ データと関連付けることができます。
多くのサービスで診断設定を使用して、メトリックとログ データを Azure Monitor の外部の他のストレージの場所に送信できます。 たとえば、Azure Storage、ホステッド パートナー システム、Event Hubs を使用する Azure 以外のパートナー システムなどがあります。
Azure Monitor によるデータの保存方法の詳細については、「Azure Monitor データ プラットフォーム」を参照してください。
Azure Monitor プラットフォームのメトリック
Azure Monitor により、多くのサービスに関するプラットフォーム メトリックが提供されます。 Azure Monitor ですべてのリソースに対して収集できるすべてのメトリックの一覧については、Azure Monitor でサポートされるメトリックに関する記事を参照してください。
このサービスでは、プラットフォーム メトリックは収集されません。
Azure Monitor ベース以外のメトリック
このサービスは、Azure Monitor メトリック データベースに含まれていない他のメトリックを提供します。
ゲスト OS メトリック
Service Fabric クラスター ノードで実行されるゲスト オペレーティング システム (OS) のメトリックは、ゲスト OS で実行される 1 つ以上のエージェントを通じて収集する必要があります。 ゲスト OS メトリックには、ゲストの CPU 使用率またはメモリ使用量を追跡するパフォーマンス カウンターが含まれます。これらは、どちらも自動スケーリングまたはアラートに頻繁に使用されます。
ベスト プラクティスは、カスタム メトリック API を介してゲスト OS パフォーマンス メトリックを Azure Monitor メトリック データベースに送信するように Azure Monitor エージェントを使用して構成することです。 ゲスト OS メトリックは、同じエージェントを使用して Azure Monitor ログに送信できます。 その後、Log Analytics を使用して、これらのメトリックとログに対してクエリを実行できます。
Note
ゲスト OS のルーティングのための Azure Diagnostics 拡張機能と Log Analytics エージェントは、Azure Monitor エージェントによって置き換えられます。 詳細については、「Azure Monitor エージェントの概要」を参照してください。
Azure Monitor リソース ログ
リソース ログでは、Azure リソースによって実行された操作に関する分析情報を提供します。 ログは自動的に生成されますが、保存するかクエリを実行するには、Azure Monitor ログにルーティングする必要があります。 ログは、カテゴリに分類されます。 特定の名前空間には、収集できる複数のリソース ログ カテゴリを含めることができます。
このサービスではリソース ログは収集されませんが、Azure リソースのデータの監視に関する記事で情報を見つけることができます。
Service Fabric のログとイベント
Service Fabric では、次のログを収集できます。
- Windows クラスターの場合は、診断エージェントと Azure Monitor ログを使用してクラスターの監視を設定できます。
- Linux クラスターの場合、Azure Monitor ログは Azure プラットフォームとインフラストラクチャの監視にも推奨されるツールです。 Linux プラットフォームの診断には、異なる構成が必要です。 詳細については、「Syslog 内の Service Fabric Linux クラスター イベント」を参照してください。
- ゲスト OS ログを Azure Monitor ログに送信するように Azure Monitor エージェントを構成し、Log Analytics を使用してクエリを実行できます。
- Service Fabric コンテナー ログを stdout または stderr に書き込んで、Azure Monitor ログで使用できるようにします。
- Azure Monitor ログ用のコンテナー監視ソリューションを設定することで、コンテナー イベントを表示することができます。
その他のログ記録ソリューション
Microsoft が推奨する Azure Monitor ログと Application Insights という 2 つのソリューションには Service Fabric との統合が組み込まれていますが、多くのイベントは ETW プロバイダーを通して書き出されるため、他のログ ソリューションを使用して拡張することができます。 また、Elastic Stack (特に、オフライン環境でクラスターの実行を検討している場合)、Dynatrace、またはその他の好みのプラットフォームを検討する必要もあります。 統合パートナーの一覧については、「Azure Service Fabric 監視パートナー」を参照してください。
プラットフォーム選択の重要なポイントは、ユーザー インターフェイスの使いやすさ、クエリの機能、使用できるカスタム視覚化とダッシュボード、監視エクスペリエンスを強化するために提供される追加ツールなどです。
Azure activity log
アクティビティ ログには、Azure リソースごとに操作を追跡する、そのリソースの外から見たサブスクリプションレベルのイベント (新しいリソースの作成や仮想マシンの起動など) が含まれます。
収集: アクティビティ ログ イベントは、Azure portal で表示するために、個別のストアに自動的に生成および収集されます。
ルート指定: アクティビティ ログ データを Azure Monitor ログに送信して、他のログ データと共に分析できます。 Azure Storage、Azure Event Hubs、特定の Microsoft 監視パートナーなど、その他の場所も利用できます。 アクティビティ ログをルーティングする方法の詳細については、Azure アクティビティ ログの概要に関するページをご覧ください。
監視データを分析する
監視データを分析するためのツールは多数あります。
Azure Monitor ツール
Azure Monitor は、次の基本的なツールをサポートします。
メトリックス エクスプローラー。Azure リソースのメトリックを表示および分析できる Azure portal のツール。 詳細については、「Azure Monitor メトリック ス エクスプローラーを使用したメトリックの分析」を参照してください。
Log Analytics は、Kusto クエリ言語 (KQL) を使用して、ログ データのクエリと分析を可能にする Azure Portal のツールです。 詳細については、「Azure Monitor でログ クエリの使用を開始する」を参照してください。
アクティビティ ログ。表示および基本的な検索用のユーザー インターフェイスが Azure portal に用意されています。 より詳細な分析を行うには、データを Azure Monitor ログにルーティングし、Log Analytics でより複雑なクエリを実行する必要があります。
より複雑な視覚化を可能にするツールは次のとおりです。
- ダッシュボードを使用すると、さまざまな種類のデータを組み合わせて、Azure portal 内の 1 つのペインに表示できます。
- ブック。Azure portal で作成できるカスタマイズ可能なレポート。 ブックには、テキスト、メトリック、ログ クエリを含めることができます。
- Grafana。運用ダッシュボードに優れたオープン プラットフォーム ツール。 Grafana を使用して、Azure Monitor 以外の複数のソースからのデータを含むダッシュボードを作成できます。
- Power BI。さまざまなデータ ソースにわたって対話型の視覚化を提供するビジネス分析サービス。 Azure Monitor からログ データを自動的にインポートするように Power BI を構成して、これらの視覚化を利用できます。
一般的な Service Fabric 監視分析シナリオの概要については、「Service Fabric で一般的なシナリオを診断する」を参照してください。
Azure Monitor エクスポート ツール
次の方法を使用して、Azure Monitor から他のツールにデータを取得できます。
メトリック: メトリック用 REST API を使用して、Azure Monitor メトリック データベースからメトリック データを抽出します。 この API では、取得したデータを絞り込むためのフィルター式がサポートされています。 詳細については、Azure Monitor REST API のリファレンスをご覧ください。
ログ: REST API または関連するクライアント ライブラリを使用します。
もう 1 つのオプションは、ワークスペース データのエクスポートです。
Azure Monitor 用 REST API の使用を開始するには、「Azure 監視 REST API のチュートリアル」を参照してください。
Kusto クエリ
Kusto クエリ言語 (KQL) を使用して、Azure Monitor ログ/Log Analytics ストアの監視データを分析できます。
重要
ポータルでサービスのメニューから [ログ] を選択すると、クエリ スコープが現在のサービスに設定された状態で Log Analytics が開きます。 このスコープは、ログ クエリにその種類のリソースのデータのみが含まれることを意味します。 他の Azure サービスのデータを含むクエリを実行する場合は、[Azure Monitor] メニューから [ログ] を選択します。 詳細については、「Azure Monitor Log Analytics のログ クエリのスコープと時間範囲」を参照してください。
いずれかのサービスに関する一般的なクエリの一覧については、Log Analytics クエリ インターフェイスに関するページを参照してください。
サンプル クエリ
次のクエリでは、ノード上のアクションを含む Service Fabric イベントを返します。 その他の便利なクエリについては、Service Fabric イベントに関する記事を参照してください。
過去 1 時間に記録された操作イベントを返します。
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
HealthState == 3 (エラー) の正常性レポートを返し、EventMessage フィールドから追加のプロパティを抽出します。
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
特定のサービスとノードで集計された Service Fabric の操作イベントを取得します。
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
警告
Azure Monitor のアラートにより、監視データで特定の状態が見つかったときに事前に通知を受け取ります。 アラートにより、ユーザーが気付く前に、管理者が問題を識別して対処できます。 詳細については、Azure Monitor アラートに関するページを参照してください。
Azure リソースに関する一般的なアラートのソースは数多くあります。 Azure リソースに関する一般的なアラートの例については、ログ アラート クエリのサンプルに関するページをご覧ください。 Azure Monitor ベースライン アラート (AMBA) サイトには、重要なプラットフォーム メトリック アラート、ダッシュボード、ガイドラインを実装するための半自動化された方法が用意されています。 このサイトは、Azure ランディング ゾーン (ALZ) の一部であるすべてのサービスを含む、Azure サービスの継続的に拡張されるサブセットに適用されます。
共通アラート スキーマを使用すると、Azure Monitor のアラート通知の使用を標準化できます。 詳細については、「共通アラート スキーマ」をご覧ください。
アラートの種類
Azure Monitor データ プラットフォームでは、任意のメトリックまたはログ データ ソースに対してアラートを生成できます。 監視するサービスと収集する監視データに応じて、さまざまな種類のアラートがあります。 アラートの種類に応じて、さまざまな利点と欠点があります。 詳細については、適切な種類の監視アラートの選択に関するページをご覧ください。
次の一覧では、作成できる Azure Monitor アラートの種類について説明します。
- メトリック アラートでは、リソース メトリックを定期的に評価します。 メトリックはプラットフォーム メトリック、カスタム メトリック、メトリックに変換された Azure Monitor からのログまたは Application Insights メトリックにすることができます。 メトリック警告では、複数の条件と動的しきい値を適用することもできます。
- ログ アラートでは、ユーザーは Log Analytics クエリを使用して、定義済みの頻度でリソース ログを評価できます。
- アクティビティ ログ アラートは、定義された条件と一致する新しいアクティビティ ログ イベントが発生したときにトリガーされます。 Resource Health アラートと Service Health アラートは、サービスとリソースの正常性を報告するアクティビティ ログ アラートです。
一部の Azure サービスでは、スマート検出アラート、Prometheus アラート、推奨されるアラート ルールもサポートされています。
一部のサービスでは、同じ Azure リージョン内に存在する同じ種類の複数のリソースに同じメトリック警告ルールを適用することで、大規模に監視することができます。 監視対象リソースごとに個別の通知が送信されます。 サポートされている Azure サービスとクラウドについては、「1 つのアラート ルールで複数のリソースを監視する」をご覧ください。
Service Fabric 警告ルール
次の表に、Service Fabric のいくつかの警告ルールを示します。 これらのアラートは例に過ぎません。 Service Fabric 監視データのリファレンスに関する記事または「Service Fabric イベントの一覧」に記載されている任意のメトリック、ログ エントリ、またはアクティビティ ログ エントリのアラートを設定できます。
| アラートの種類 | 条件 | 説明 |
|---|---|---|
| ノード イベント | ノードがダウンする | EventID >= 25622 および EventID <= 25626 の ServiceFabricOperationalEvent。 これらのイベント ID は、ノード イベントのリファレンスで確認できます。 |
| アプリケーション イベント | アプリケーションのアップグレードがロールバックする | EventID == 29623 または EventID == 29624 の ServiceFabricOperationalEvent。 これらのイベント ID は、アプリケーション イベントのリファレンスで確認できます。 |
| リソース ヘルス | アップグレード サービスに到達できない/利用できない | クラスターが UpgradeServiceUnreachable 状態になります。 |
Advisor の推奨事項
一部のサービスでは、リソースの操作中にクリティカルな条件や差し迫った変更が発生した場合は、ポータルのサービス [概要] ページにアラートが表示されます。 アラートの詳細と推奨される修正は、左側のメニューの [監視] の下の [アドバイザーのレコメンデーション] に表示されます。 通常の操作中、アドバイザーのレコメンデーションは表示されません。
Azure Advisor の詳細については、Azure Advisor の概要に関するページをご覧ください。
推奨されるセットアップ
監視の各領域とシナリオの例を説明したので、ここでは上記のすべての領域を監視するために必要な Azure 監視ツールと設定の概要を説明します。
- Application Insights によるアプリケーションの監視
- 診断エージェントと Azure Monitor ログによるクラスターの監視
- Azure Monitor ログによるインフラストラクチャーの監視
サンプル ARM テンプレートを使用および変更することで、すべての必要なリソースとエージェントのデプロイを自動化することもできます。
関連するコンテンツ
- Service Fabric 用に作成されるメトリック、ログ、その他の重要な値のリファレンスについては、Service Fabric 監視データのリファレンスに関する記事を参照してください。
- Azure リソースの監視に関する一般的な詳細情報については、「Azure Monitor を使用した Azure リソースの監視」を参照してください。
- 「Service Fabric イベントの一覧」を参照してください。