Azure Stream Analytics でのノーコード ストリーム処理
ノーコード エディターを使用すると、コードを 1 行も記述することなく、ドラッグ アンド ドロップ機能を使用して、リアルタイム ストリーミング データを処理する Stream Analytics ジョブを簡単に開発できます。 このエクスペリエンスでは、入力ソースに接続してストリーミング データをすばやく確認できるキャンバスが提供されます。 その後、宛先に書き込む前に変換できます。
ノーコード エディターを使用すると、次のことが簡単に行えます。
- 入力スキーマを変更する。
- 結合やフィルターなどのデータ準備操作を実行する。
- グループ化操作のためのタイム ウィンドウ集計 (タンブリング ウィンドウ、ホッピング ウィンドウ、セッション ウィンドウ) などの高度なシナリオに取り組む。
Stream Analytics ジョブを作成して実行すると、運用ワークロードを簡単に運用化できます。 監視とトラブルシューティングのために適切な組み込みメトリックのセットを使用します。 Stream Analytics ジョブは、実行中の価格モデルに従って課金されます。
前提条件
ノーコード エディターを使用することによって Stream Analytics ジョブを開発する前に、以下の要件を満たす必要があります。
- Stream Analytics ジョブのストリーミング入力ソースとターゲット宛先リソースは、パブリックにアクセスできる必要があり、Azure 仮想ネットワーク内にすることはできません。
- ストリーミング入力リソースおよび出力リソースにアクセスするには、必要なアクセス許可がなければなりません。
- Azure Stream Analytics リソースを作成および変更するには、アクセス許可を維持する必要があります。
注意
現在、ノーコード エディターは中国リージョンでは使用できません。
Azure Stream Analytics ジョブ
Stream Analytics ジョブは、ストリーミング入力、変換、出力の 3 つの主要コンポーネントに基づいて構築されています。 複数の入力、複数の変換を使用した並列分岐、複数の出力など、必要な数のコンポーネントを含めることができます。 詳細については、Azure Stream Analytics のドキュメントを参照してください。
注意
ノーコード エディターを使用する場合、次の機能と出力の種類は使用できません。
- ユーザー定義関数。
- Azure Stream Analytics クエリ ブレードでのクエリ編集。 ただし、ノーコード エディターによって生成されたクエリは、クエリ ブレードで表示できます。
- Azure Stream Analytics の入出力ブレードでの入出力の追加。 ただし、ノーコード エディターによって生成された入出力は、入出力ブレードで表示できます。
- 次の出力の種類は使用できません: Azure Function、ADLS Gen1、PostgreSQL DB、Service Bus キュー/トピック、Table Storage。
ストリーム分析ジョブをビルドするためのノーコード エディターにアクセスするには、次の 2 つの方法があります。
Azure Stream Analytics ポータル (プレビュー) を使用する: Stream Analytics ジョブを作成し、[概要] ページの [作業の開始] タブでノーコード エディターを選択するか、左側のパネルで [ノーコード エディター] を選択します。

Azure Event Hubs ポータルを使用する: Event Hubs インスタンスを開きます。 [データの処理] を選択してから、任意の定義済みテンプレートを選択します。
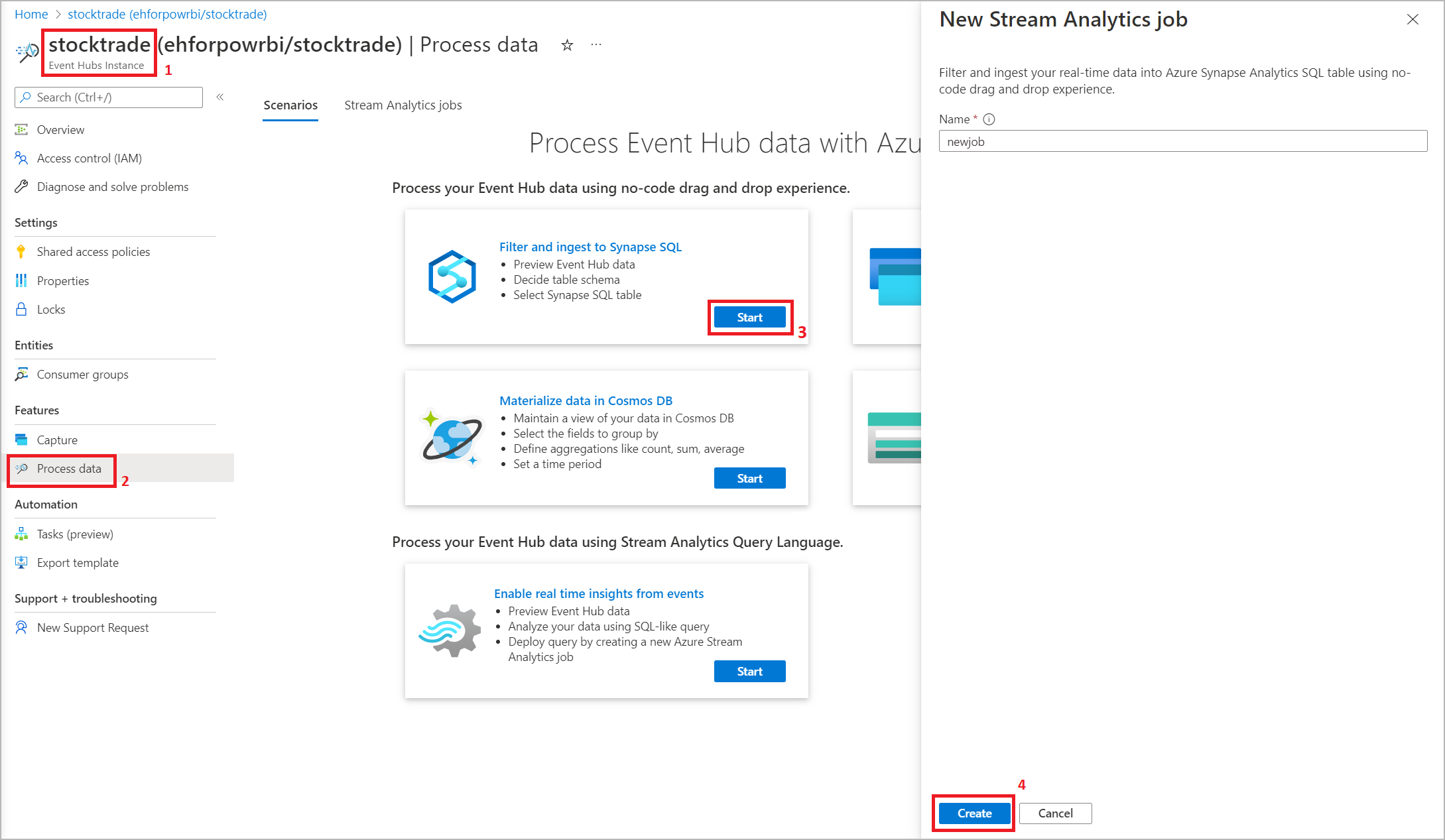
定義済みテンプレートは、次のようなさまざまなシナリオに対処するためのジョブの開発と実行に役立つ可能性があります。
- Power BI データセットを使用してリアルタイム ダッシュボードを構築する
- Delta Lake 形式で Event Hubs からデータをキャプチャする (プレビュー)
- Azure Synapse SQL へのフィルター処理と取り込み
- Azure Data Lake Storage Gen2 での Parquet 形式での Event Hubs データのキャプチャ
- Azure Cosmos DB でのデータの具体化
- Data Lake Storage Gen2 へのフィルター処理と取り込み
- データをエンリッチしてイベント ハブに取り込む
- データの変換および Azure SQL データベースへの保存
- フィルター処理して Azure Data Explorer に取り込む


次のスクリーンショットは、完了済みの Stream Analytics ジョブを示しています。 作成中に使用できるすべてのセクションが強調表示されます。

- リボン: リボンでは、セクションがクラシック分析プロセスの順序に従います (入力としてのイベント ハブ (データソースとも呼ばれる)、変換 (ストリーミングの抽出、変換、読み込み操作)、出力、進行状況を保存するためのボタン、およびジョブを開始するためのボタン)。
- ダイアグラム ビュー: これは、入力から操作を経て出力までの、Stream Analytics ジョブのグラフィカル表現です。
- 作業ウィンドウ: ダイアグラム ビューで選択されたコンポーネントに応じて、入力、変換、または出力を変更するための設定が表示されます。
- データ プレビュー、作成エラー、ランタイム ログ、およびメトリックに関するタブ: タイルごとに、データ プレビューに、そのステップの結果が表示されます (入力の場合はライブ、変換と出力の場合はオンデマンド)。 このセクションでは、開発中のジョブで発生するおそれのある作成エラーまたは警告の概要も表示されます。 各エラーまたは警告を選択すると、その変換が選択されます。 実行中のジョブの正常性を監視するためのジョブ メトリックスも提供されます。
ストリーミング データ入力
ノーコード エディターでは、次の 3 種類のリソースからのストリーミング データ入力がサポートされています。
- Azure Event Hubs
- Azure IoT Hub
- Azure Data Lake Storage Gen2
ストリーミング データ入力の詳細については、「Stream Analytics に入力としてデータをストリーム配信する」を参照してください
注意
Azure Event Hubs ポータルのノーコード エディターには、入力オプションとして Event Hub のみがあります。

ストリーミング入力としての Azure Event Hubs
Azure Event Hubs は、ビッグ データのストリーミング プラットフォームであり、イベント インジェスト サービスです。 1 秒間に何百万ものイベントを受信して処理することができます。 イベント ハブに送信されたデータは、任意のリアルタイム分析プロバイダーまたはバッチ処理およびストレージ アダプターを介して変換して保存できます。
イベント ハブをジョブの入力として構成するには、[イベント ハブ] アイコンを選択します。 構成および接続用の作業ウィンドウを含むタイルが [ダイアグラム] ビューに表示されます。
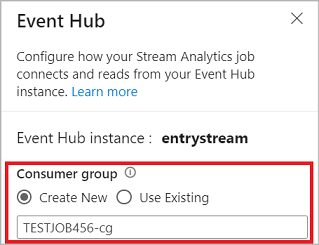
ノーコード エディターでイベント ハブに接続する場合は、新しいコンシューマー グループを作成する (既定のオプション) ことをお勧めします。 このアプローチは、イベント ハブが同時リーダー数の上限に達するのを防ぐのに役立ちます。 コンシューマー グループの詳細と、既存のコンシューマー グループを選択すべきか、新しいコンシューマー グループを作成すべきかを理解するには、コンシューマー グループに関する記事を参照してください。
イベント ハブが Basic レベルの場合は、既存の $Default コンシューマー グループしか使用できません。 イベント ハブが Standard または Premium レベルの場合は、新しいコンシューマー グループを作成できます。
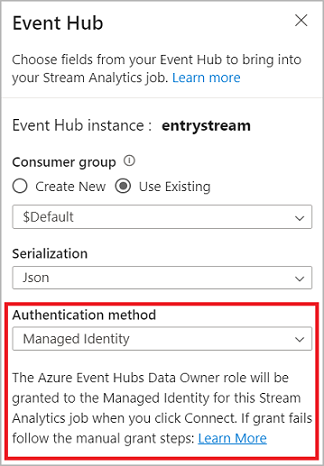
イベント ハブに接続するときに、認証モードとして [マネージド ID] を選択した場合は、Azure Event Hubs データ所有者ロールが Stream Analytics ジョブのマネージド ID に付与されます。 イベント ハブのマネージド ID の詳細については、「Azure Stream Analytics ジョブからマネージド ID を使用してイベント ハブにアクセスする」を参照してください。
マネージド ID では、ユーザーベースの認証方法の制限が排除されます。 このような制限には、90 日ごとに発生するパスワードの変更やユーザー トークンの期限切れによる再認証の必要性が含まれます。
イベント ハブの詳細を設定し、[接続] を選択した後、フィールド名がわかっていれば、[+ フィールドの追加] を使用することによって手動でフィールドを追加することができます。 代わりに受信メッセージのサンプルに基づいてフィールドとデータ型を自動的に検出するには、 [フィールドの自動検出] を選択します。 必要に応じて、歯車記号を選択して、資格情報を編集できます。
Stream Analytics ジョブでフィールドが検出されると、それらがリストに表示されます。 また、ダイアグラム ビューの下の [データ プレビュー] テーブルに受信メッセージのライブ プレビューが表示されます。
入力データを変更する
各フィールドの横にある 3 点記号を選択することによって、フィールド名を編集したり、フィールドを削除したり、データ型を変更したり、イベント時刻を変更したり (イベント時刻としてマーク: datetime 型フィールドの場合は TIMESTAMP BY 句) することができます。 さらに、次の図に示すように、受信メッセージから、入れ子になったフィールドを展開、選択、および編集することもできます。
ヒント
これは、Azure IoT Hub および Azure Data Lake Storage Gen2 からの入力データにも適用されます。

使用できるデータの種類は次のとおりです。
- DateTime: ISO 形式の日付と時刻フィールド。
- Float: 10 進数。
- Int: 整数。
- Record: 複数のレコードを含む入れ子になったオブジェクト。
- String: テキスト。
ストリーミング入力としての Azure IoT Hub
Azure IoT Hub は、クラウドでホストされる管理サービスです。IoT アプリケーションとそこに接続されたデバイスとの間における通信において、中央のメッセージ ハブとしての役割を担います。 IoT ハブに送信された IoT デバイス データは、Stream Analytics ジョブの入力として使用できます。
注意
Azure IoT Hub 入力は、Azure Stream Analytics ポータルのノーコード エディターで使用できます。
ジョブのストリーミング入力として IoT ハブを追加するには、リボンの [入力] の下にある [IoT Hub] を選択します。 次に、右側のパネルに必要な情報を入力して、IoT ハブをジョブに接続します。 各フィールドの詳細については、IoT Hub から Stream Analytics ジョブへのデータのストリーム配信に関する記事を参照してください。

ストリーミング入力としての Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (ADLS Gen2) は、クラウドベースのエンタープライズ データ レイク ソリューションです。 これは、任意の形式の大量のデータを保存し、ビッグ データ分析ワークロードに対応するように設計されています。 ADLS Gen2 に保存されているデータは、Stream Analytics でデータ ストリームとして処理できます。 この入力の種類の詳細については、ADLS Gen2 から Stream Analytics ジョブへのデータのストリーム配信に関する記事を参照してください。
注意
Azure Data Lake Storage Gen2 入力は、Azure Stream Analytics ポータルのノーコード エディターで使用できます。
ジョブのストリーミング入力として ADLS Gen2 を追加するには、リボンの [入力] の下にある [ADLS Gen2] を選択します。 次に、右側のパネルに必要な情報を入力して、ADLS Gen2 をジョブに接続します。 各フィールドの詳細については、ADLS Gen2 から Stream Analytics ジョブへのデータのストリーム配信に関する記事を参照してください

参照データ入力
参照データは、静的な場合と時間の経過とともにゆっくり変化する場合があります。 多くの場合、ジョブで受信ストリームを強化したり、検索を実行したりするために使用されます。 たとえば、SQL 結合を実行して静的な値を検索する場合と同様に、データ ストリーム入力を参照データのデータに結合できます。 参照データ入力の詳細については、「Stream Analytics での参照に参照データを使用する」を参照してください。
ノーコード エディターは、次の 2 つの参照データ ソースをサポートするようになりました。
- Azure Data Lake Storage Gen2
- Azure SQL データベース

参照データとしての Azure Data Lake Storage Gen2
参照データは、BLOB 名で指定された日付と時刻の組み合わせの昇順での BLOB のシーケンスとしてモデル化されます。 BLOB をシーケンスの最後に追加するには、シーケンス内で最後の BLOB で指定された日付/時刻より後の日付/時刻を使用する必要があります。 BLOB は入力構成で定義されます。
まず、リボンの [入力] セクションで、[Reference ADLS Gen2](参照 ADLS Gen2) を選択します。 各フィールドの詳細については、「Stream Analytics での参照に参照データを使用する」の Azure Blob Storage に関するセクションを参照してください。
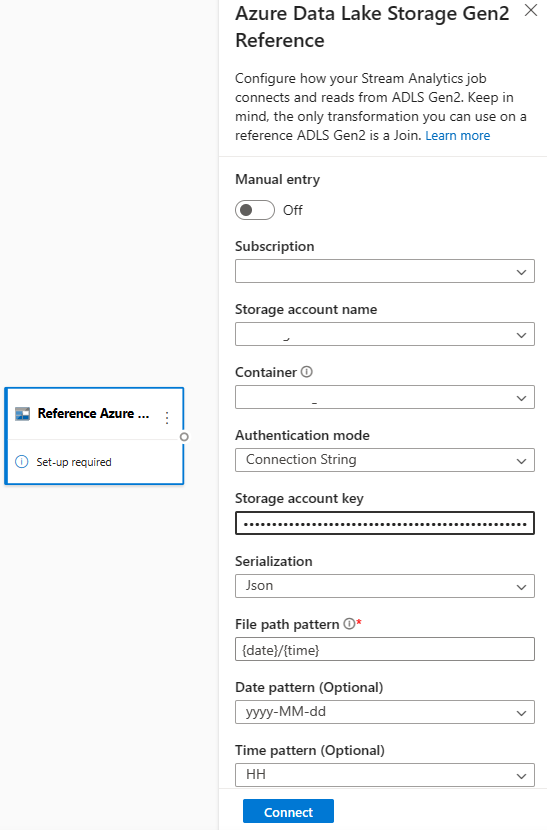
次に、JSON 配列ファイルをアップロードします。 ファイル内のフィールドが検出されます。 この参照データを使用して、Event Hubs からのストリーミング入力データを使用した変換を実行します。

参照データとしての Azure SQL Database
ノーコード エディターでは、Stream Analytics ジョブ用の参照データとして Azure SQL Database を使用できます。 詳細については、「Stream Analytics での参照に参照データを使用する」の SQL Database に関するセクションを参照してください。
SQL Database を参照データ入力として構成するには、リボンの [入力] セクションで [Reference SQL Database](参照 SQL Database) を選択します。 次に、参照データベースを接続するための情報を入力し、必要な列を含むテーブルを選択します。 SQL クエリを手動で編集することによって、テーブルから参照データをフェッチすることもできます。

変換
ストリーミング データの変換はバッチ データの変換とは本質的に異なります。 ほとんどすべてのストリーミング データに、関連するデータ準備タスクに影響を与える時間コンポーネントが含まれています。
ストリーミング データ変換をジョブに追加するには、その変換用のリボンにある [操作] セクションで変換記号を選択します。 それぞれのタイルがダイアグラム ビューにドロップされます。 それを選択すると、その変換用の作業ウィンドウが表示され、構成することができます。

Assert
フィルター変換を使用して、入力のフィールドの値に基づいてイベントをフィルター処理します。 データ型 (数値またはテキスト) によっては、変換で、選択された条件に一致する値が保持されます。

Note
すべてのタイル内に、変換の準備に他に何が必要かに関する情報が表示されます。 たとえば、新しいタイルを追加すると、[セットアップが必要です] というメッセージが表示されます。 ノード コネクタがない場合は、エラー メッセージか警告メッセージのどちらかが表示されます。
フィールドの管理
フィールドの管理変換では、入力または別の変換から受信するフィールドの追加、削除、または名前の変更を行うことができます。 作業ウィンドウの設定で、 [フィールドの追加] を選択して新しいフィールドを追加するか、またはすべてのフィールドを一度に追加するかを選択できます。

また、組み込み関数を使用して新しいフィールドを追加し、アップストリームからのデータを集計することもできます。 現在、サポートされている組み込み関数は、文字列関数、日付と時刻関数、数学関数の一部の関数です。 これらの関数の定義の詳細については、「組み込み関数 (Azure Stream Analytics)」を参照してください。

ヒント
タイルを構成したら、ダイアグラム ビューで、タイル内の設定を簡単に確認できます。 たとえば、前の画像の [フィールドの管理] 領域では、最初の 3 つのフィールドが管理されており、それらに新しい名前が割り当てられているのがわかります。 各タイルには、それに関連する情報が含まれています。
Aggregate
集計変換を使用すると、一定期間に新しいイベントが発生するたびに、集計 ( [合計] 、 [最小] 、 [最大] 、または [平均] ) を計算できます。 この操作により、データ内の他のディメンションに基づいて集計のフィルター処理またはスライスを行うこともできます。 同じ変換に 1 つ以上の集計を含めることができます。
集計を追加するには、変換記号を選択します。 次に、入力を接続し、集計を選択して、フィルターまたはスライス ディメンションを追加し、集計を計算する期間を選択します。 この例では、過去 10 秒間の通行料金の合計を、車両の出発地の州別に計算します。

同じ変換に別の集計を追加するには、 [集計関数の追加] を選択します。 フィルターまたはスライスは、変換内のすべての集計に適用されることに注意してください。
Join
結合変換を使用することにより、選択したフィールドのペアに基づいて、2 つの入力からのイベントを組み合わせます。 フィールドのペアを選択しない場合、結合は、既定で時間に基づきます。 この既定によって、この変換をバッチ変換とは異なるものにしています。
通常の結合と同様に、結合ロジック用のオプションがあります。
- 内部結合: ペアが一致する両方のテーブルからのレコードのみが含まれます。 この例では、それはライセンス プレートが両方の入力と一致している場所になります。
- 左外部結合: 左側 (最初) のテーブルからのすべてのレコードと、フィールドのペアと一致する、2 番目のテーブルからのレコードのみが含まれます。 一致するものがない場合、2 番目の入力からのフィールドは空白になります。
結合の種類を選択するには、作業ウィンドウで、優先する種類の記号を選択します。
最後に、結合を計算する期間を選択します。 この例では、結合は、過去 10 秒間を対象とします。 期間が長くなるほど、出力の頻度が少なくなり、変換に使用される処理リソースが増えることに注意してください。
既定では、両方のテーブルのすべてのフィールドが含まれます。 出力でプレフィックスの left (最初のノード) と right (2 番目のノード) は、ソースを区別するのに役立ちます。

グループ化
グループ化変換を使用して、特定の時間ウィンドウ内のすべてのイベントの集計を計算します。 1 つまたは複数のフィールドの値でグループ化することができます。 これは、集計変換に似ていますが、より多くの集計のためのオプションが用意されています。 また、時間ウィンドウ用のより複雑なオプションも含まれています。 さらに、集計と同様に、変換あたり複数の集計を追加できます。
変換で使用できる集計は次のとおりです。
- Average
- Count
- [最大]
- 最小
- パーセンタイル (連続および不連続)
- Standard Deviation
- Sum
- Variance
この変換を構成するには:
- 優先する集計を選択します。
- 集計するフィールドを選択します。
- 別のディメンションまたはカテゴリに対する集計計算を取得する場合は、オプションのグループ化フィールドを選択します。 たとえば、[状態] です。
- 時間ウィンドウの関数を選択します。
同じ変換に別の集計を追加するには、 [集計関数の追加] を選択します。 [グループ化] フィールドとウィンドウ関数は、変換内のすべての集計に適用されることに注意してください。

時間ウィンドウの終了時点のタイム スタンプが、参考のために変換出力の一部として表示されます。 Stream Analytics ジョブでサポートされる時間ウィンドウの詳細については、「ウィンドウ関数 (Azure Stream Analytics)」を参照してください。
Union
和集合変換は、2 つ以上の入力を接続し、共有フィールド (名前とデータ型が同じ) を含むイベントを 1 つのテーブルに追加する場合に使用します。 一致しないフィールドは削除され、出力に含まれません。
配列の拡張
配列の拡張変換は、配列内の値ごとに新しい行を作成する場合に使用します。

ストリーミング出力
現時点で、ノーコード ドラッグ アンド ドロップ エクスペリエンスは、処理されたリアルタイム データを格納するための出力シンクを複数サポートしています。

Azure Data Lake Storage Gen2
Data Lake Storage Gen2 によって、Azure Storage は、Azure 上にエンタープライズ データ レイクを構築するための基盤となります。 それは、数百ギガビットのスループットを維持しながら、数ペタバイトの情報を提供するように設計されています。 これにより、大量のデータを簡単に管理できます。 Azure Blob Storage は、大量の非構造化データをクラウドに保存するためのコスト効率の良いスケーラブルなソリューションを提供します。
リボン上の [出力] セクションで、Stream Analytics ジョブの出力として [ADLS Gen2] を選択します。 次に、ジョブの出力を送信するコンテナーを選択します。 Stream Analytics ジョブの Azure Data Lake Gen2 出力の詳細については、「Azure Stream Analytics からの Blob Storage と Azure Data Lake Gen2 出力」を参照してください。
Azure Data Lake Storage Gen2 に接続するときに、認証モードとして [マネージド ID] を選択すると、Stream Analytics ジョブのマネージド ID にストレージ BLOB データ共同作成者ロールが付与されます。 Azure Data Lake Storage Gen2 のマネージド ID の詳細については、「マネージド ID を使用して、Azure Blob Storage に対して Azure Stream Analytics ジョブを認証する」を参照してください。
マネージド ID では、ユーザーベースの認証方法の制限が排除されます。 このような制限には、90 日ごとに発生するパスワードの変更やユーザー トークンの期限切れによる再認証の必要性が含まれます。
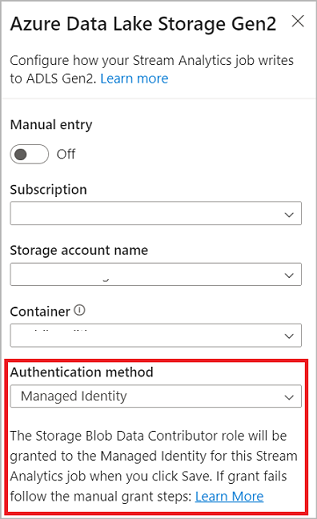
ADLS Gen2 では、ノー コード エディター出力として、厳密に 1 回の配信 (プレビュー) がサポートされています。 これは、ADLS Gen2 構成の [書き込みモード] セクションで有効にすることができます。 この機能の詳細については、Azure Data Lake Gen2 での厳密に 1 回の配信 (プレビュー) に関する記事を参照してください

ADLS Gen2 では、ノー コード エディター出力として Delta Lake テーブルへの書き込み (プレビュー) がサポートされています。 このオプションは、ADLS Gen2 構成の [シリアル化] セクションにあります。 この機能の詳細については、Delta Lake テーブルへの書き込みに関する記事を参照してください。

Azure Synapse Analytics
Azure Stream Analytics ジョブは、Azure Synapse Analytics 内の専用 SQL プール テーブルに出力を送信し、1 秒あたり最大 200 MB のスループット レートを処理できます。 Stream Analytics は、レポートやダッシュボードなどのワークロードの最も要求の厳しいリアルタイム分析とホットパス データ処理のニーズをサポートします。
重要
Stream Analytics ジョブに出力として専用 SQL プール テーブルを追加するには、事前にそれが存在している必要があります。 テーブルのスキーマを、使用するジョブの出力内のフィールドとその型と一致させる必要があります。
リボン上の [出力] セクションで、Stream Analytics ジョブの出力として [Synapse] を選択します。 次に、ジョブの出力を送信する SQL プール テーブルを選択します。 Stream Analytics ジョブの Azure Synapse 出力の詳細については、「Azure Stream Analytics からの Azure Synapse Analytics 出力」を参照してください。
Azure Cosmos DB
Azure Cosmos DB は、世界中で弾力性のある無制限のスケーリングを提供するグローバル分散型データベース サービスです。 また、スキーマに依存しないデータ モデルを介して豊富なクエリと自動インデックス作成も提供します。
リボン上の [出力] セクションで、Stream Analytics ジョブの出力として [CosmosDB] を選択します。 Stream Analytics ジョブの Azure Cosmos DB 出力の詳細については、「Azure Stream Analytics からの Azure Cosmos DB 出力」を参照してください。
Azure Cosmos DB に接続するときに、認証モードとして [マネージド ID] を選択すると、Stream Analytics ジョブのマネージド ID に共同作成者ロールが付与されます。 Azure Cosmos DB のマネージド ID の詳細については、「マネージド ID を使用して Azure Stream Analytics ジョブから Cosmos DB にアクセスする (プレビュー)」を参照してください。
マネージド ID 認証方法は、上記の ADLS Gen2 出力と同じメリットがあるノーコード エディターの Azure Cosmos DB 出力でもサポートされます。
Azure SQL データベース
Azure SQL Database は、Azure でアプリケーションとソリューション用の高可用で高性能なデータ ストレージ レイヤーを作成するのに役立つ、フル マネージドのサービスとしてのプラットフォーム (PaaS) データベース エンジンです。 ノーコード エディターを使用すると、処理されたデータを SQL Database 内の既存のテーブルに書き込むよう Azure Stream Analytics ジョブを構成できます。
Azure SQL Database を出力として構成するには、リボン上の [出力] セクションで [SQL Database] を選択します。 次に、SQL データベースを接続するために必要な情報を入力し、データを書き込むテーブルを選択します。
重要
Azure SQL Database テーブルは、Stream Analytics ジョブに出力として追加する前に、存在している必要があります。 テーブルのスキーマを、使用するジョブの出力内のフィールドとその型と一致させる必要があります。
Stream Analytics ジョブの Azure SQL Database 出力の詳細については、「Azure Stream Analytics からの Azure SQL Database 出力」を参照してください。
Event Hubs
リアルタイム データが ASA に送信されたら、ノーコード エディターでそのデータを変換して強化してから、別のイベント ハブに出力することもできます。 Azure Stream Analytics ジョブを構成するときに、[イベント ハブ] 出力を選択できます。
Event Hubs を出力として構成するには、リボン上の [出力] セクションで [イベント ハブ] を選択します。 次に、データを書き込むイベント ハブを接続するために必要な情報を入力します。
Stream Analytics ジョブの Event Hubs 出力の詳細については、「Azure Stream Analytics からの Event Hubs 出力」を参照してください。
Azure Data Explorer
Azure Data Explorer は、大量のデータを簡単に分析できるようにする、フル マネージドで高性能なビッグ データ分析プラットフォームです。 ノーコード エディターを使用することによって、Azure Stream Analytics ジョブの出力として Azure Data Explorer を使用することもできます。
Azure Data Explorer を出力として構成するには、リボン上の [出力] セクションで [Azure Data Explorer] を選択します。 次に、Azure Data Explorer データベースを接続するために必要な情報を入力し、データを書き込むテーブルを選択します。
重要
テーブルは選択したデータベース内に存在する必要があり、テーブルのスキーマはジョブの出力内のフィールドおよびその型と正確に一致する必要があります。
Stream Analytics ジョブの Azure Data Explorer 出力の詳細については、「Azure Stream Analytics からの Azure Data Explorer 出力 (プレビュー)」を参照してください。
Power BI
Power BI では、データ分析結果に対する包括的な視覚化エクスペリエンスが提供されます。 Stream Analytics への Power BI 出力では、処理されたストリーミング データが Power BI ストリーミング データセットに書き込まれます。その後、それを使用して、準リアルタイムの Power BI ダッシュボードを構築できます。 準リアルタイムのダッシュボードを構築する方法の詳細については、「Stream Analytics ノー コード エディターから生成された Power BI データセットを使用してリアルタイム ダッシュボードを構築する」を参照してください。
Power BI を出力として構成するには、リボンの [出力] セクションで [Power BI] を選択します。 次に、Power BI ワークスペースを接続するために必要な情報を入力し、データを書き込むストリーミング データセットとテーブルの名前を指定します。 各フィールドの詳細については、「Azure Stream Analytics からの Power BI 出力」を参照してください。
データ プレビュー、作成エラー、ランタイム ログ、およびメトリック
ノーコード ドラッグ アンド ドロップ エクスペリエンスは、ストリーミング データの分析パイプラインの作成、トラブルシューティング、およびパフォーマンス評価を行うのに役立つツールを提供します。
入力のライブ データ プレビュー
入力ソース (例: イベント ハブ) に接続し、ダイアグラム ビュー ([データのプレビュー] タブ) でそのタイルを選択すると、次のすべての条件が当てはまる場合に、受信するデータのライブ プレビューが表示されます。
- データがプッシュされている。
- 入力が正しく構成されている。
- フィールドが追加された。
次のスクリーンショットに示すように、特定のものを表示またはドリルダウンする場合は、プレビューを一時停止することができます (1)。 または、完了したら、再度開始できます。
また、特定のレコード (テーブル内の セル) の詳細を、それを選択し、[詳細の表示]/[詳細の非表示] を選択して表示することもできます (2)。 スクリーンショットに、レコードの入れ子になったオブジェクトの詳細ビューが示されています。
![[データ プレビュー] タブが表示されたスクリーンショット。このタブでは、ストリーミング プレビューを一時停止し、詳細を表示または非表示にすることができます。](media/no-code-stream-processing/data-preview.png#lightbox)
変換および出力の静的プレビュー
ダイアグラム ビューでステップを追加して設定したら、[静的プレビューの取得] を選択して、それらの動作をテストできます。

その後、Stream Analytics ジョブはすべての変換と出力を評価して、それらが正しく構成されていることを確認します。 次に、Stream Analytics により、次の図に示すように、結果が静的データ プレビューに表示されます。
![静的プレビューを更新できる [データ プレビュー] タブが表示されたスクリーンショット。](media/no-code-stream-processing/refresh-static-preview.png#lightbox)
プレビューを更新するには、 [静的プレビューの更新] を選択します (1)。 プレビューを更新すると、Stream Analytics ジョブは入力から新しいデータを受け取り、すべての変換を評価します。 その後で、実行された可能性のある更新を含む出力を再度送信します。 [詳細の表示]/[詳細の非表示] オプションも使用できます (2)。
作成エラー
作成エラーや警告がある場合は、次のスクリーンショットに示すように、[作成エラー] タブにそれらが一覧表示されます。 この一覧には、エラーや警告の詳細、カードの種類 (入力、変換、または出力)、エラー レベル、エラーまたは警告の説明が含まれます。

ランタイム ログ
ランタイム ログは、ジョブの実行中に警告、エラー、または情報レベルで表示されます。 このログは、トラブルシューティングのために Stream Analytics ジョブ トポロジまたは構成を編集するときに役立ちます。 診断ログをオンにして、それらを [設定] で Log Analytics ワークスペースに送信し、デバッグのために実行中のジョブに関するより多くの分析情報を得ることを強くお勧めします。

次のスクリーンショットの例では、ユーザーがジョブ出力のフィールドと一致しないテーブル スキーマを使用して SQL Database 出力を構成しています。

メトリック
ジョブが実行されている場合は、[メトリック] タブでジョブの正常性を監視できます。既定で表示される 4 つのメトリックは、ウォーターマークの遅延、入力イベント、バックログされた入力イベント、および出力イベントです。 これらのメトリックを使用すると、入力バックログなしで、イベントがジョブに流入しているのか、ジョブから流出しているのかを判断できます。

リストからさらにメトリックを選択できます。 すべてのメトリックの詳細を理解するには、「Azure Stream Analytics のジョブ メトリック」を参照してください。
Stream Analytics ジョブの開始
ジョブの作成中はいつでもジョブを保存できます。 ジョブのストリーミング入力、変換、およびストリーミング出力を構成したら、ジョブを開始できます。
注意
Azure Stream Analytics ポータルのノーコード エディターはプレビュー段階ですが、Azure Stream Analytics サービスは一般公開されています。
![[保存] ボタンと [スタート] ボタンが表示されたスクリーンショット。](media/no-code-stream-processing/no-code-save-start.png#lightbox)
以下のオプションを構成できます。
- [出力の開始時刻]: ジョブを開始するときは、ジョブが出力の作成を開始する時刻を選択します。
- [今すぐ]: このオプションは、出力イベント ストリームの開始点をジョブの開始時刻と同じにします。
- [カスタム] : 出力の開始点を選択できます。
- [最終停止時刻]: このオプションは、以前にジョブが開始されたが、手動で停止されたか失敗した場合に使用できます。 このオプションを選択すると、データが失われないように、最後の出力時刻を使用してジョブが再開されます。
- [ストリーミング ユニット]: ストリーミング ユニット (SU) は、実行中にジョブに割り当てられたコンピューティングとメモリの量を表します。 選択する SU の数が不明な場合は、3 つから始めて、必要に応じて調整することをお勧めします。
- [出力データ エラー処理]: 出力データ エラー処理に関するポリシーは、Stream Analytics ジョブで生成された出力イベントがターゲット シンクのスキーマに準拠していない場合にのみ適用されます。 [再試行] か [ドロップ] を選択することでこのポリシーを構成できます。 詳細については、「Azure Stream Analytics の出力エラー ポリシー」を参照してください。
- [スタート]: このボタンは Stream Analytics ジョブを開始します。

Azure Event Hubs ポータルの Stream Analytics ジョブ リスト
Azure Event Hubs ポータルのノーコード ドラッグ アンド ドロップ エクスペリエンスを使用して作成したすべての Stream Analytics ジョブの一覧を表示するには、[データの処理]>[Stream Analytics ジョブ] を選択します。

[Stream Analytics ジョブ] タブの要素は次のとおりです。
- [フィルター]: ジョブ名でリストをフィルター処理できます。
- [更新]: 現在、リスト自体は自動的に更新されません。 リストを更新して、最新の状態を表示する場合に、[更新] ボタンを使用します。
- [ジョブ名]: この領域内の名前は、ジョブ作成の最初のステップで指定されたものです。 編集することはできません。 ジョブ名を選択して、ジョブをノーコード ドラッグ アンド ドロップ エクスペリエンスで開きます。このエクスペリエンスでは、ジョブを停止して、編集し、再開できます。
- [状態]: この領域にはジョブの状態が表示されます。 リストの上部にある [更新] を選択すると、最新の状態が表示されます。
- [ストリーミング ユニット]: この領域には、ジョブの開始時に選択されたストリーミング ユニットの数が表示されます。
- [出力のウォーターマーク]: この領域は、ジョブが生成したデータの活動状態のインジケーターを提供します。 タイムスタンプより前のすべてのイベントは既に計算されています。
- [ジョブの監視]: [オープン メトリック] を選択して、この Stream Analytics ジョブに関連するメトリックを表示します。 Stream Analytics ジョブの監視に使用できるメトリックの詳細については、「Azure Stream Analytics のジョブ メトリック」を参照してください。
- [操作]: ジョブを開始、停止、または削除します。
次の手順
事前定義されたテンプレートを使用することによって一般的なシナリオに対処するためにノーコード エディターを使用する方法について説明します。