Oracle 移行の SQL 問題を最小限に抑える
この記事は、Oracle から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 5 です。 この記事では、SQL の問題を最小限に抑えるためのベスト プラクティスに焦点を合わせています。
概要
Oracle 環境の特性
1979 年にリリースされた Oracle の初期データベース製品は、オンライン トランザクション処理 (OLTP) アプリケーション用の商用 SQL リレーショナル データベースであり、トランザクション レートは現在よりもはるかに低いものでした。 その最初のリリース以来、Oracle 環境は進化し、はるかに複雑になり、多数の機能を含むようになりました。 それらの機能には、クライアント/サーバー アーキテクチャ、分散データベース、並列処理、データ分析、高可用性、データ ウェアハウス、メモリ内データ手法、さらにクラウドベース インスタンスのサポートが含まれます。
ヒント
Oracle は、2000 年代初頭に「データ ウェアハウス アプライアンス」 コンセプトの先駆者となりました。
レガシのオンプレミス Oracle 環境の保守とアップグレードのコストと複雑さのために、既存の Oracle ユーザーの多くは、クラウド環境によって提供されるイノベーションを活用したいと考えています。 クラウド、IaaS、PaaS などの最新のクラウド環境では、インフラストラクチャのメンテナンスやプラットフォーム開発などのタスクをクラウド プロバイダーに委任できます。
大規模なデータ ボリュームに対する複雑な分析 SQL クエリをサポートする多くのデータ ウェアハウスでは、Oracle テクノロジが使用されています。 一般に、これらのデータ ウェアハウスでは、スター スキーマやスノーフレーク スキーマなどのディメンション データ モデルを使用し、個々の部門にはデータ マートを使用します。
ヒント
既存の Oracle インストール済み環境の多くは、ディメンション データ モデルを使用するデータ ウェアハウスです。
Oracle での SQL データ モデルとディメンション データ モデルの組み合わせにより、Azure Synapse への移行が簡単になります。SQL と基本的なデータ モデルの概念を移行できるためです。 Microsoft では、リスク、労力、移行時間を減らすために、既存のデータ モデルをそのまま Azure に移行することをお勧めしています。 移行計画には、基になるデータ モデルの変更 (たとえば、Inmon モデルからデータ コンテナーへの移行など) が含まれる場合がありますが、最初はそのまま移行するのが適切です。 最初の移行後に Azure クラウド環境内で変更を加え、そのパフォーマンス、柔軟なスケーラビリティ、組み込み機能、コスト面での利点を活用できます。
SQL 言語は標準化されていますが、個々のベンダーが独自の拡張機能を実装している場合があります。 そのため、移行中に、Azure Synapse での対応策が必要となる SQL の違いが見つかる場合があります。
Azure の機能を使用してメタデータに基づく移行を実装する
Azure 環境の機能を使用することで、移行プロセスを自動化し、調整できます。 このアプローチにより、既存の Oracle 環境 (既に能力いっぱいに近い状態で実行されている場合があります) のパフォーマンスへの影響が最小限に抑えられます。
Azure Data Factory は、クラウドベースのデータ統合サービスであり、データの移動と変換を調整および自動化するデータ ドリブン ワークフローのクラウドでの作成をサポートします。 Data Factory を使用して、さまざまなデータ ストアからデータを取り込むデータ ドリブン ワークフロー (パイプライン) を作成し、スケジュールを設定できます。 Data Factory は、Azure HDInsight Hadoop、Spark、Azure Data Lake Analytics、Azure Machine Learning などのコンピューティング サービスを使ってデータを処理し、変換できます。
Azure には、Oracle などの環境からの移行の計画と実行に役立つ Azure Database Migration Services も含まれています。 SQL Server Migration Assistant (SSMA) for Oracle では、Oracle データベースの移行 (場合によっては関数や手続き型コードも含めて) を自動化できます。
ヒント
Azure Data Factory 機能を使用して移行プロセスを自動化します。
Azure 機能 (Data Factory など) を使用した移行プロセスの管理を計画するときは、まず、移行する必要があるすべてのデータ テーブルとその場所を一覧表示するメタデータを作成します。
Oracle と Azure Synapse の SQL DDL の違い
ANSI SQL 標準では、データ定義言語 (DDL) コマンドの基本的な構文を定義しています。 DDL コマンドの中には、CREATE TABLE や CREATE VIEW など、Oracle と Azure Synapse の両方に共通するものがありますが、それらが拡張され、インデックス作成、テーブルの分散、パーティション分割オプションなどの実装固有の機能を提供するようになっています。
ヒント
SQL DDL コマンドCREATE TABLEとCREATE VIEWは、標準のコア要素を持ちますが、実装固有のオプションの定義にも使用します。
以降のセクションでは、Azure Synapse への移行時に考慮する必要がある Oracle 固有のオプションについて説明します。
テーブル/ビューに関する考慮事項
異なる環境間でテーブルを移行するとき、通常は生データと、それを記述するメタデータのみが物理的に移行されます。 インデックスやログ ファイルなどの、ソース システムの他のデータベース要素は、通常は移行されません。新しい環境ではこれらが不要であるか、実装方法が異なる可能性があるためです。 たとえば、Oracle の CREATE TABLE 構文内の TEMPORARY オプションは、Azure Synapse でテーブル名の先頭に # 文字を付けることと同じです。
インデックスなどの、ソース環境でのパフォーマンスの最適化は、新しいターゲット環境でパフォーマンスの最適化を追加することが検討される箇所を示します。 たとえば、ソース Oracle 環境内のクエリでビットマップ インデックスが頻繁に使用される場合、Azure Synapse 内に非クラスター化インデックスを作成する必要があることを示しています。 テーブル レプリケーションなど、他のネイティブ パフォーマンスの最適化手法は、同一条件でインデックスを直接作成するよりも適している場合があります。 SSMA for Oracle により、テーブルの分散とインデックス作成についての移行に関する推奨事項が得られます。
ヒント
既存のインデックスは、移行後のウェアハウスでのインデックス作成の候補を示します。
SQL ビュー定義には、通常は 1 つ以上の SELECT ステートメントを使用してビューを定義する、SQL データ操作言語 (DML) ステートメントが含まれています。 CREATE VIEW ステートメントを移行するときは、Oracle と Azure Synapse の DML の違いを考慮してください。
サポートされていない Oracle データベース オブジェクトの種類
Oracle 固有の機能は、多くの場合、Azure Synapse の機能に置き換えることができます。 ただし、一部の Oracle データベース オブジェクトは、Azure Synapse では直接サポートされません。 サポートされていない Oracle データベース オブジェクトの次の一覧で、Azure Synapse で同等の機能を実現する方法について説明します。
インデックス作成オプション: Oracle のいくつかのインデックス作成オプション (ビットマップインデックス、関数ベースのインデックス、ドメイン インデックスなど) には、Azure Synapse 内に直接相当するものはありません。 Azure Synapse ではこれらのインデックスの種類はサポートされていませんが、ユーザー定義のインデックスの種類やパーティション分割を使用することで、ディスク I/O を同じように削減できます。ディスク I/O を減らすと、クエリのパフォーマンスが向上します。
システム カタログのテーブルとビューに対してクエリを実行する (
ALL_INDEXES、DBA_INDEXES、USER_INDEXES、DBA_IND_COLなど) と、インデックスが作成されている列とそのインデックスの種類を確認できます。 または、監視が有効になっている場合は、dba_index_usageまたはv$object_usageビューに対してクエリを実行できます。並列クエリ処理やデータと結果のメモリ内キャッシュなどの Azure Synapse 機能を使用すると、優れたパフォーマンス目標を達成するためにデータ ウェアハウス アプリケーションに必要なインデックスが少なくなる可能性があります。
クラスター化テーブル: Oracle テーブルは、頻繁に一緒にアクセスされる (共通の値に基づいて) テーブル行が物理的にまとめて格納されるように整理できます。 この方法で、データの取得時にディスク I/O が削減されます。 また、Oracle には、個々のテーブル用のハッシュ クラスター オプションもあります。これより、ハッシュ値がクラスター キーに適用され、同じハッシュ値を持つ行が物理的にまとめて格納されます。
Azure Synapse では、パーティション分割や他のインデックスの使用によって同様の結果を達成できます。
具体化されたビュー: Oracle では、具体化されたビューをサポートしていて、多くの列を持つ大規模なテーブル (クエリで定期的に使用される列はわずかしかない) に対してそのうち 1 つ以上が推奨されています。 具体化されたビューは、ベース テーブルのデータが更新されるとシステムで自動的に更新されます。
2019 年に、Microsoft は、Oracle と同じ機能を持つ具体化されたビューが Azure Synapse でサポートされることを発表しました。 具体化されたビューは現在、Azure Synapse のプレビュー機能です。
データベース内トリガー: Oracle では、トリガー イベントが発生したときに自動的に実行されるようにトリガーを構成できます。 トリガー イベントには、次のものがあります。
DML ステートメント (
INSERT、UPDATE、DELETEなど) が実行される。 顧客テーブルでINSERTステートメントの前に起動するトリガーを定義した場合、このトリガーは新しい行が顧客テーブルに挿入される前に 1 回起動されます。DDL ステートメント (
CREATEやALTERなど) が実行される。 このトリガー イベントは、監査の目的でスキーマの変更を記録するために多く使用されます。システム イベント (Oracle データベースの起動やシャットダウンなど)。
ユーザー イベント (ログインやログアウトなど)。
Azure Synapse では Oracle データベース トリガーをサポートしていません。 ただし、Data Factory を使用すると同等の機能を実現できますが、これを行うには、トリガーを使用するプロセスをリファクタリングする必要があります。
同意語: Oracle では、いくつかのデータベース オブジェクトの種類で代替名として同意語を定義できます。 これらの種類には、テーブル、ビュー、シーケンス、プロシージャ、ストアド関数、パッケージ、具体化されたビュー、Java クラス スキーマ オブジェクト、ユーザー定義オブジェクト、または別の同意語が含まれます。
Azure Synapse では現在、同意語を定義できません。ただし、Oracle の同意語がテーブルまたはビューを参照している場合は、代替名と一致するように Azure Synapse でビューを定義できます。 Oracle の同意語が関数またはストアド プロシージャを参照している場合、Azure Synapse での同意語を、ターゲットを呼び出す別の関数またはストアド プロシージャに置き換えることができます。
ユーザー定義型: Oracle では、一連の個別フィールド (それぞれに独自の定義と既定値を持つ) を含めることができる、ユーザー定義オブジェクトをサポートしています。 それにより、これらのオブジェクトは、組み込みのデータ型 (
NUMBERやVARCHARなど) と同じ方法によってテーブル定義内で参照できます。Azure Synapse では現在、ユーザー定義の種類をサポートしていません。 移行する必要があるデータにユーザー定義のデータ型が含まれている場合は、それらを従来のテーブル定義に "フラット化" するか、データの配列である場合は、別のテーブルで正規化します。
SQL DDL の生成
既存の Oracle の CREATE TABLE と CREATE VIEW スクリプトを編集して、Azure Synapse の同等の定義を実現できます。 これを行うために、変更されたデータ型を使用し、Oracle 固有の句 (TABLESPACE など) を削除または変更する必要が生じる場合があります。
ヒント
既存の Oracle メタデータを使用して、Azure Synapse の CREATE TABLE と CREATE VIEW の DDL の生成を自動化します。
Oracle 環境内では、システム カタログ テーブルが現在のテーブルとビューの定義を指定します。 ユーザーが保守するドキュメントとは異なり、システム カタログ情報は常に完全であり、現在のテーブル定義と同期されます。 システム カタログ情報にアクセスするには、Oracle SQL Developer などのユーティリティを使用します。 次のスクリーンショットに示すように、Oracle SQL Developer では CREATE TABLE DDL ステートメントを生成でき、これを編集して Azure Synapse 内で同等のテーブルに適用できます。

Oracle SQL Developer では次の CREATE TABLE ステートメントを出力します。ここには、削除する必要がある Oracle 固有の句が含まれています。 変更された CREATE TABLE ステートメントを Azure Synapse で実行する前に、サポートされていないデータ型をマップします。
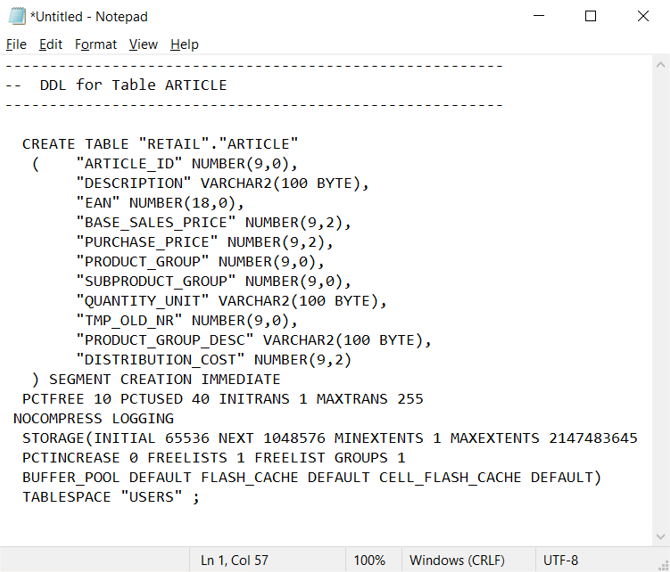
または、SQL クエリ、SSMA、またはサードパーティの移行ツールを使用して、Oracle カタログ テーブル内の情報から CREATE TABLE ステートメントを自動的に生成することもできます。 この方法で、多くのテーブルに対して最も迅速で一貫性の高いやり方で CREATE TABLE ステートメントを生成できます。
ヒント
サードパーティー製のツールやサービスを使用すると、データ マッピング タスクを自動化できます。
サードパーティ ベンダーから、データ型のマッピングなどの、移行を自動化するツールとサービスが提供されています。 サードパーティの ETL ツールが既に Oracle 環境で使用されている場合は、そのツールを使用して、必要なデータ変換を実装します。
Oracle と Azure Synapse の SQL DML の違い
ANSI SQL 標準は、SELECT、INSERT、UPDATE、DELETE などの DML コマンドの基本構文を定義します。 Oracle と Azure Synapse ではどちらも DDL コマンドをサポートしますが、同じコマンドを異なる方法で実装する場合があります。
ヒント
標準の SQL DML コマンド SELECT、INSERT、UPDATE では、さまざまなデータベース環境で追加の構文オプションを使用できます。
以降のセクションでは、Azure Synapse への移行時に考慮する必要がある Oracle 固有の DML コマンドについて説明します。
SQL DML 構文の相違点
Oracle SQL と Azure Synapse T-SQL には、SQL DML 構文に多少の違いがあります。
DUALテーブル: Oracle には、DUALという名前のシステム テーブルがあります。これは、dummyという 1 つの列および値Xを持つ 1 つのレコードのみで構成されます。DUALシステム テーブルは、構文上の理由でクエリにテーブル名が必要ですが、テーブルの内容は必要ない場合に使用されます。DUALテーブルを使用する Oracle クエリの例はSELECT sysdate from dual;です。 Azure Synapse でこれに相当するものはSELECT GETDATE();です。 DML の移行を簡略化するために、次の DDL を使用して、Azure Synapse で同等のDUALテーブルを作成できます。CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GONULL値: Oracle でのNULL値は空の文字列であり、長さ0のCHARまたはVARCHAR文字列型で表されます。 Azure Synapse と他のほとんどのデータベースでは、NULLは別の意味を表します。 データを移行する場合、またはデータを処理または格納するプロセスを移行する場合は、NULL値が一貫した方法で処理されるように注意してください。Oracle 外部結合構文: Oracle のより新しいバージョンでは ANSI 外部結合構文をサポートしますが、以前の Oracle システムでは、外部結合に、SQL ステートメント内でプラス記号 (
+) を使用する独自の構文を使用します。 以前の Oracle 環境を移行する場合、以前の構文が見つかることがあります。 次に例を示します。SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;同等の ANSI 標準構文は次のとおりです。
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;DATEデータ: Oracle では、DATEデータ型に日付と時刻の両方を格納できます。 Azure Synapse では、日付と時刻は個別のDATE、TIME、DATETIMEデータ型に格納します。 Oracle のDATE列を移行する場合は、日付と時刻の両方を格納するか、日付のみを格納するかを確認します。 日付のみを格納する場合は、その列をDATEにマップし、それ以外の場合はDATETIMEにマップします。DATEの算術: Oracle では、ある日付を別の日付から減算できます。たとえばSELECT date '2018-12-31' - date '2018-1201' from dual;です。 Azure Synapse では、日付の減算にはDATEDIFF()関数を使用します。たとえば、SELECT DATEDIFF(day, '2018-12-01', '2018-12-31');です。Oracle では、日付から整数を減算できます。たとえば
SELECT hire_date, (hire_date-1) FROM employees;です。 Azure Synapse は、DATEADD()関数を使用して日付に対して整数を加算または減算できます。ビューを使用した更新: Oracle では、ビューに対して挿入、更新、削除の操作を実行して、基になるテーブルを更新できます。 Azure Synapse では、これらの操作をビューではなくベース テーブルに対して実行します。 Oracle テーブルがビューを使用して更新された場合、ETL 処理のリエンジニアリングが必要になる可能性があります。
組み込み関数: 次の表に、いくつかの組み込み関数の構文と使用方法の違いを示します。
| Oracle 関数 | 説明 | Synapse での同等のもの |
|---|---|---|
| ADD_MONTHS | 指定の月数を追加します | [DATEADD] |
| CAST | 組み込みデータ型を別のデータ型に変換します | CAST |
| DECODE | 条件の一覧を評価します | CASE 式 |
| EMPTY_BLOB | 空の BLOB 値を作成します | 0x 定数 (空のバイナリ文字列) |
| EMPTY_CLOB | 空の CLOB または NCLOB 値を作成します | '' (空の文字列) |
| INITCAP | 各単語の最初の文字を大文字にします | ユーザー定義関数 |
| INSTR | 文字列内の部分文字列の位置を見つけます | CHARINDEX |
| LAST_DAY | 月の最後の日付を取得します | EOMONTH |
| LENGTH | 文字列の長さを文字数で取得します | LEN |
| LPAD | 指定した長さに対する左埋め込み文字列 | REPLICATE、RIGHT、LEFT を使用した式 |
| MOD | ある数値を別の数値で除算した結果の余りを取得します | % 演算子 |
| MONTHS_BETWEEN | 2 つの日付の間の月数を取得します | DATEDIFF |
| NVL | NULL を式で置き換えます |
ISNULL |
| SUBSTR | 文字列の部分文字列を返します | SUBSTRING |
| datetime の TO_CHAR | datetime を文字列に変換します | CONVERT |
| TO_DATE | 文字列を datetime に変換します | CONVERT |
| TRANSLATE | 1 対 1 の 1 文字置換 | REPLACE またはユーザー定義関数を使用した式 |
| TRIM | 先頭または末尾の文字をトリミングします | LTRIM と RTRIM |
| datetime の TRUNC | datetime を切り捨てます | CONVERT を使用した式 |
| UNISTR | Unicode コード ポイントを文字に変換します | NCHAR を使用した式 |
関数、ストアド プロシージャ、シーケンス
Oracle のような成熟した環境からデータ ウェアハウスを移行するときは、単純なテーブルやビュー以外の要素の移行が必要になる可能性があります。 関数、ストアド プロシージャ、シーケンスについて、Azure 環境内のツールがこれらの機能を置き換えることができるかどうかを確認します。通常、組み込みの Azure ツールを使用する方が、Oracle 関数を再コーディングするよりも効率的であるためです。
準備段階の一環として、移行する必要があるオブジェクトのインベントリを作成し、それらを処理する方法を定義して、移行計画に適切なリソースを割り当てます。
SSMA for Oracle や Azure Database Migration Services などの Microsoft ツール、またはサードパーティの移行製品やサービスを使用して、関数、ストアド プロシージャ、シーケンスの移行を自動化できます。
ヒント
サードパーティーの製品やサービスによって、データ以外の要素の移行を自動化します。
以降のセクションでは、関数、ストアド プロシージャ、シーケンスの移行について説明します。
関数
ほとんどのデータベース製品と同様に、Oracle では SQL 実装内で、システムとユーザー定義の関数がサポートされています。 レガシ データベース プラットフォームを Azure Synapse に移行するときに、通常、一般的なシステム機能は変更なしで移行できます。 一部のシステム関数では、構文が若干異なることがありますが、必要な変更は自動化できます。
Azure Synapse に同等のものがない Oracle システム関数または任意のユーザー定義関数については、ターゲット環境言語を使用してそれらの関数を再コーディングします。 Oracle のユーザー定義関数は、PL/SQL、Java、または C 言語でコーディングされています。Azure Synapse では、Transact-SQL 言語を使用してユーザー定義関数を実装します。
ストアド プロシージャ
ほとんどの最新のデータベース製品では、データベース内にプロシージャを格納できます。 Oracle には、この目的のために PL/SQL 言語が用意されています。 ストアド プロシージャには通常、SQL ステートメントと手続き型のロジックの両方が含まれていて、データまたは状態が返されます。
Azure Synapse では T-SQL を使用したストアド プロシージャがサポートされているため、移行されたストアド プロシージャを T-SQL で再コーディングする必要があります。
シーケンス
Oracle では、シーケンスとは、CREATE SEQUENCE を使用して作成される名前付きデータベース オブジェクトのことです。 シーケンスは、CURRVAL および NEXTVAL メソッド経由で一意の数値を提供します。 主キーに対する代理キーの値として、生成された一意の数値を使用できます。 Azure Synapse は CREATE SEQUENCE を実装しませんが、IDENTITY 列または系列内の次のシーケンス番号を生成する SQL コードを使用してシーケンスを実装できます。
EXPLAIN を使用してレガシ SQL を検証
ヒント
既存のシステム クエリ ログから実際のクエリを使用して、移行の潜在的な問題を見つけます。
同じテーブル名と列名を持つ Azure Synapse の同一条件で移行されたデータ モデルを想定する場合、Azure Synapse との互換性についてレガシ Oracle SQL をテストする 1 つの方法を次に示します。
- レガシ システムのクエリ履歴ログから代表的な SQL ステートメントをいくつかキャプチャします。
- これらのクエリの先頭に
EXPLAINステートメントを付けます。 - Azure Synapse で
EXPLAINステートメントを実行します。
互換性のない SQL ではエラーが生成されるので、エラー情報を使用して、再コーディング タスクの規模を特定できます。 この方法では、Azure 環境にデータを読み込む必要はありません。必要なのは、関連するテーブルとビューを作成することだけです。
まとめ
レガシ Oracle の既存のインストールは、通常、Azure Synapse への移行を比較的簡単にする方法で実装されます。 どちらの環境も、大きなデータ ボリュームに対する分析クエリに SQL を使用し、一般に、何らかの形式のディメンション データ モデルを使用します。 これらの要因で、Oracle のインストールは、Azure Synapse への移行対象として適切な候補になります。
要約すると、Oracle から Azure Synapse に SQL コードを移行するタスクを最小限に抑えるための推奨事項は次のようになります。
リスク、労力、移行時間を最小限に抑えるために、データ コンテナーなど、別のデータ モデルが計画されている場合でも、既存のデータ モデルをそのまま移行します。
Oracle SQL の実装と Azure Synapse 実装の違いについて理解します。
既存の Oracle の実装から得たメタデータとクエリ ログを使用して、環境を変更したときの影響を評価します。 違いを抑える方法を計画します。
リスク、労力、移行時間を最小限に抑えるために、移行プロセスを自動化します。 Azure Database Migration Services や SSMA などの Microsoft ツールを使用できます。
スペシャリストであるサードパーティのツールとサービスを使用して移行を合理化することを検討してください。
次のステップ
Microsoft とサード パーティのツールの詳細については、このシリーズの次の記事「Azure Synapse Analytics への Oracle データ ウェアハウス移行用ツール」を参照してください。