Spark ジョブ定義を Azure Synapse から Fabric に移行
Spark ジョブ定義 (SJD) を Azure Synapse から Fabric に移動するには、次の 2 種類のオプションがあります。
- オプション 1: Fabric で Spark ジョブ定義を手動で作成する。
- オプション 2: スクリプトを使用して Azure Synapse から Spark ジョブ定義をエクスポートし、API を使用して Fabric にインポートする。
Spark ジョブ定義に関する留意事項については、「Azure Synapse Spark と Fabric の違い」を参照してください。
前提条件
まだ 1 つもない場合は、テナントに Fabric ワークスペースを作成します。
オプション 1: Spark ジョブ定義を手動で作成する
Azure Synapse から Spark ジョブ定義をエクスポートするには:
- Synapse Studio を開く: Azure にサインインします。 Azure Synapse ワークスペースに移動し、Synapse Studio を開きます。
- Python/Scala/R Spark ジョブを見つける: 移行する Python/Scala/R Spark ジョブ定義を探して特定します。
- ジョブ定義構成をエクスポート:
- Synapse Studio で、Spark ジョブ定義を開きます。
- スクリプト ファイルの場所、依存関係、パラメータ、その他の関連する詳細など、構成設定をエクスポートまたはメモします。
Fabric でエクスポートされた SJD 情報に基づいて新しい Spark ジョブ定義 (SJD) を作成するには:
- Fabric ワークスペースにアクセス: Fabric にサインインし、ワークスペースにアクセスします。
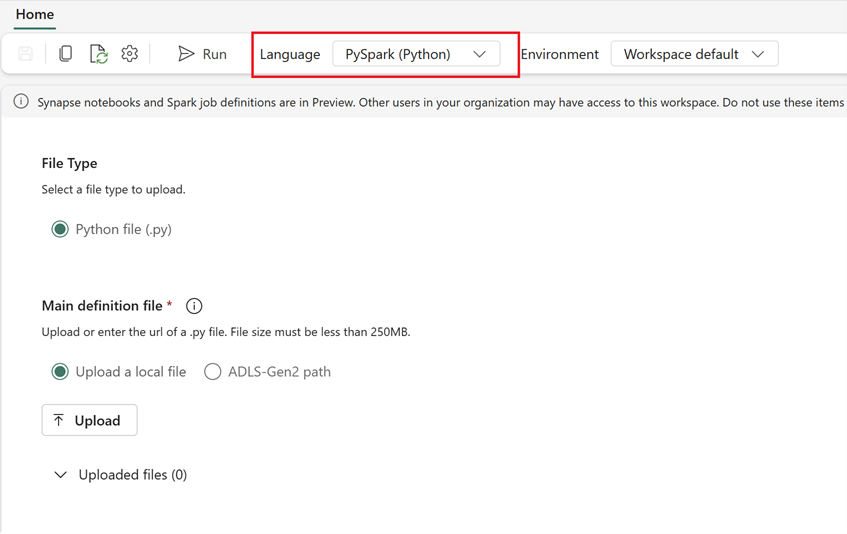
- Fabric で新しい Spark ジョブ定義を作成:
- Fabric で、Data Engineering のホーム ページに移動します。
- [Spark ジョブ定義] を選択します。
- スクリプトの場所、依存関係、パラメータ、クラスター設定など、Synapse からエクスポートした情報を使用してジョブを構成します。
- 適応とテスト: Fabric 環境に合わせてスクリプトまたは構成に必要な適応を施します。 Fabric でジョブをテストして、正しく実行されることを確認します。
Spark ジョブ定義が作成されたら、依存関係を検証します。
- 必ず同じ Spark バージョンを使用してください。
- メイン定義ファイルの存在を検証します。
- 参照されるファイル、依存関係、およびリソースの存在を検証します。
- リンク サービス、データ ソース接続、マウント ポイント。
Fabric で Apache Spark ジョブ定義を作成する方法について説明します。
オプション 2: Fabric API を使用する
移行では、次の主なステップに従います。
- 前提条件。
- ステップ 1: Spark ジョブ定義を Azure Synapse から OneLake (.json) にエクスポートする。
- ステップ 2: Fabric API を使用して Spark ジョブ定義を Fabric に自動的にインポートする。
前提条件
前提条件には、Fabric への Spark ジョブ定義の移行を開始する前に考慮する必要があるアクションが含まれます。
- Fabric ワークスペース。
- まだ 1 つもない場合は、ワークスペースに Fabric レイクハウスを作成します。
ステップ 1: Azure Synapse ワークスペースから Spark ジョブ定義をエクスポートする
ステップ 1 では、Json 形式で Azure Synapse ワークスペースから OneLake に Spark ジョブ定義をエクスポートすることに重点を置いています。 このプロセスは次のとおりです。
- 1.1) Fabric ワークスペースに SJD 移行ノートブックをインポートします。 このノートブック は、対象の Azure Synapse ワークスペースから OneLake の中間ディレクトリにすべての Spark ジョブ定義をエクスポートします。 Synapse API は、SJD のエクスポートに使用されます。
- 1.2) 最初のコマンドでパラメータを構成して、Spark ジョブ定義を中間ストレージ (OneLake) にエクスポートします。 この操作では、json メタデータ ファイルのみがエクスポートされます。 次のスニペットを使用して、ソースとエクスポート先のパラメータを構成します。 これらは実際の値に置き換えてください。
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
- 1.3) エクスポート/インポート ノートブックの最初の 2 つのセルを実行して、Spark ジョブ定義メタデータを OneLake にエクスポートします。 セルが完了すると、中間出力ディレクトリの下にこのフォルダー構造が作成されます。
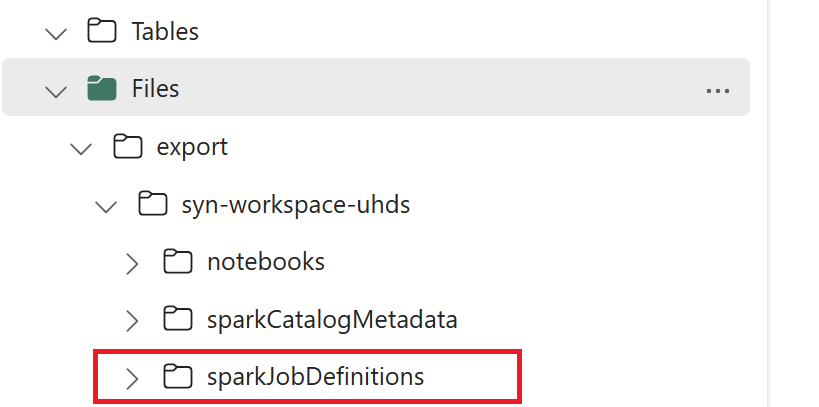
ステップ 2: Spark ジョブ定義を Fabric にインポートする
ステップ 2 は、Spark ジョブ定義が中間ストレージから Fabric ワークスペースにインポートされる場合です。 このプロセスは次のとおりです。
- 2.1) 1.2 で構成を確認し、Spark ジョブ定義をインポートするための適切なワークスペースとプレフィックスが表示されていることを確認します。
- 2.2) エクスポート/インポート ノートブックの 3 番目のセルを実行して、すべての Spark ジョブ定義を中間の場所からインポートします。
Note
エクスポート オプションは、json メタデータ ファイルを出力します。 Spark ジョブ定義の実行可能ファイル、参照ファイル、および引数に Fabric からアクセスできることを確認します。