Hive Metastore メタデータを Azure Synapse から Fabric に移行する
Hive Metastore (HMS) 移行の最初の手順では、転送するデータベース、テーブル、パーティションを決定する必要があります。 すべてを移行する必要はありません。特定のデータベースを選択できます。 移行用のデータベースを識別する場合は、必ず、マネージドまたは外部 Spark テーブルがあるかどうかを確認してください。
HMS の考慮事項については、Azure Synapse Spark と Fabric の違いに関するページを参照してください。
Note
または、ADLS Gen2 に Delta テーブルが含まれている場合は、ADLS Gen2 の Delta テーブルへの OneLake ショートカットを作成できます。
前提条件
- まだ持っていない場合は、テナントに Fabric ワークスペースを作成します。
- まだ持っていない場合は、ワークスペースに Fabric レイクハウスを作成します。
オプション 1: HMS をレイクハウス メタストアにエクスポートおよびインポートする
移行には、次の主な手順に従います。
- 手順 1: ソース HMS からメタデータをエクスポートする
- 手順 2: Fabric レイクハウスにメタデータをインポートする
- 移行後の手順: コンテンツを検証する
Note
スクリプトは、Spark カタログ オブジェクトのみを Fabric レイクハウスにコピーします。 データが既に (たとえば、ウェアハウスの場所から ADLS Gen2 に) コピーされているか、またはマネージド テーブルと外部テーブルで使用でき (たとえば、ショートカット - 推奨を使用して)、Fabric レイクハウスにコピーされていることを前提としています。
手順 1: ソース HMS からメタデータをエクスポートする
手順 1 では、ソース HMS から Fabric レイクハウスの [ファイル] セクションにメタデータをエクスポートすることに重点を置いています。 このプロセスは次のとおりです。
1.1) HMS メタデータ エクスポート ノートブックを Azure Synapse ワークスペースにインポートします。 このノートブックでは、データベース、テーブル、パーティションの HMS メタデータをクエリし、OneLake の中間ディレクトリにエクスポートします (機能はまだ組み込まれていません)。 このスクリプトでは、Spark 内部カタログ API を使用してカタログ オブジェクトを読み取ります。
1.2) 最初のコマンドでパラメーターを構成して、メタデータ情報を中間ストレージ (OneLake) にエクスポートします。 次のスニペットを使用して、ソースと宛先のパラメーターを構成します。 これらの値は実際の値に置き換えてください。
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) すべてのノートブック コマンドを実行して、カタログ オブジェクトを OneLake にエクスポートします。 セルが完了すると、中間出力ディレクトリの下にこのフォルダー構造が作成されます。
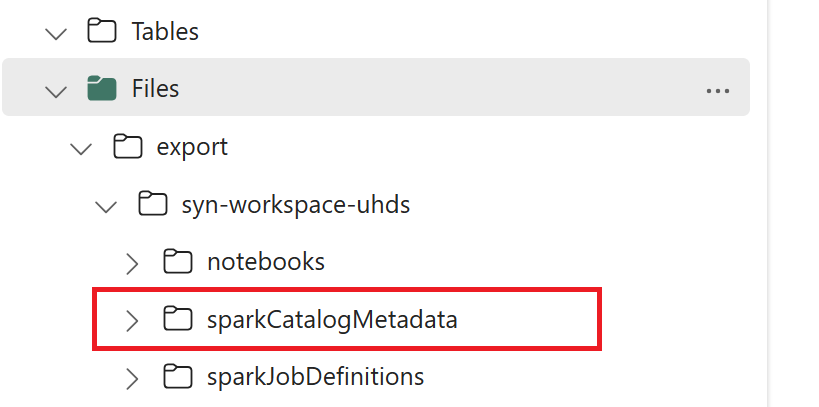
手順 2: Fabric レイクハウスにメタデータをインポートする
手順 2 では、実際のメタデータが中間ストレージから Fabric レイクハウスにインポートされます。 この手順の出力では、すべての HMS メタデータ (データベース、テーブル、パーティション) が移行されます。 このプロセスは次のとおりです。
2.1) レイクハウスの [ファイル] セクション内にショートカットを作成します。 このショートカットは、ソースの Spark ウェアハウス ディレクトリを指す必要があり、後で Spark マネージド テーブルの置き換えを行うために使用されます。 Spark ウェアハウス ディレクトリを指すショートカットの例を参照してください。
- Azure Synapse Spark ウェアハウス ディレクトリへのショートカット パス:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Azure Databricks ウェアハウス ディレクトリへのショートカット パス:
dbfs:/mnt/<warehouse_dir> - HDInsight Spark ウェアハウス ディレクトリへのショートカット パス:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Azure Synapse Spark ウェアハウス ディレクトリへのショートカット パス:
2.2) HMS メタデータ インポート ノートブックを Fabric ワークスペースにインポートします。 このノートブックをインポートして、中間ストレージからデータベース、テーブル、パーティション オブジェクトをインポートします。 このスクリプトでは、Spark 内部カタログ API を使用して Fabric でカタログ オブジェクトを作成します。
2.3) 最初のコマンドでパラメーターを構成します。 Apache Spark では、マネージド テーブルを作成すると、そのテーブルのデータは Spark 自体によって管理される場所 (通常は Spark のウェアハウス ディレクトリ内) に格納されます。 正確な場所は Spark によって決定されます。 これは、場所を指定し、基になるデータを管理する外部テーブルとは対照的です。 (実際のデータを移動せずに) マネージド テーブルのメタデータを移行する場合でも、メタデータには古い Spark ウェアハウス ディレクトリを指す元の場所情報が含まれます。 そのため、マネージド テーブルの場合は、手順 2.1 で作成したショートカットを使用した置き換えのために
WarehouseMappingsを使用します。 すべてのソース マネージド テーブルは、このスクリプトを使用して外部テーブルとして変換されます。LakehouseIdは、手順 2.1 で作成した、ショートカットを含むレイクハウスを指します。// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) すべてのノートブック コマンドを実行して、中間パスからカタログ オブジェクトをインポートします。
Note
複数のデータベースをインポートする場合、(i) データベースごとに 1 つのレイクハウスを作成するか (ここで使用するアプローチ)、または (ii) 異なるデータベースから 1 つのレイクハウスにすべてのテーブルを移動することができます。 後者の場合、移行されたすべてのテーブルは <lakehouse>.<db_name>_<table_name> であり、それに応じてインポート ノートブックを調整する必要があります。
手順 3: コンテンツを検証する
手順 3 では、メタデータが正常に移行されたことを検証します。 さまざまな例を参照してください。
以下を実行することで、インポートされたデータベースを確認できます。
%%sql
SHOW DATABASES
以下を実行することで、レイクハウス (データベース) 内のすべてのテーブルを確認できます。
%%sql
SHOW TABLES IN <lakehouse_name>
以下を実行することで、特定のテーブルの詳細を確認できます。
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
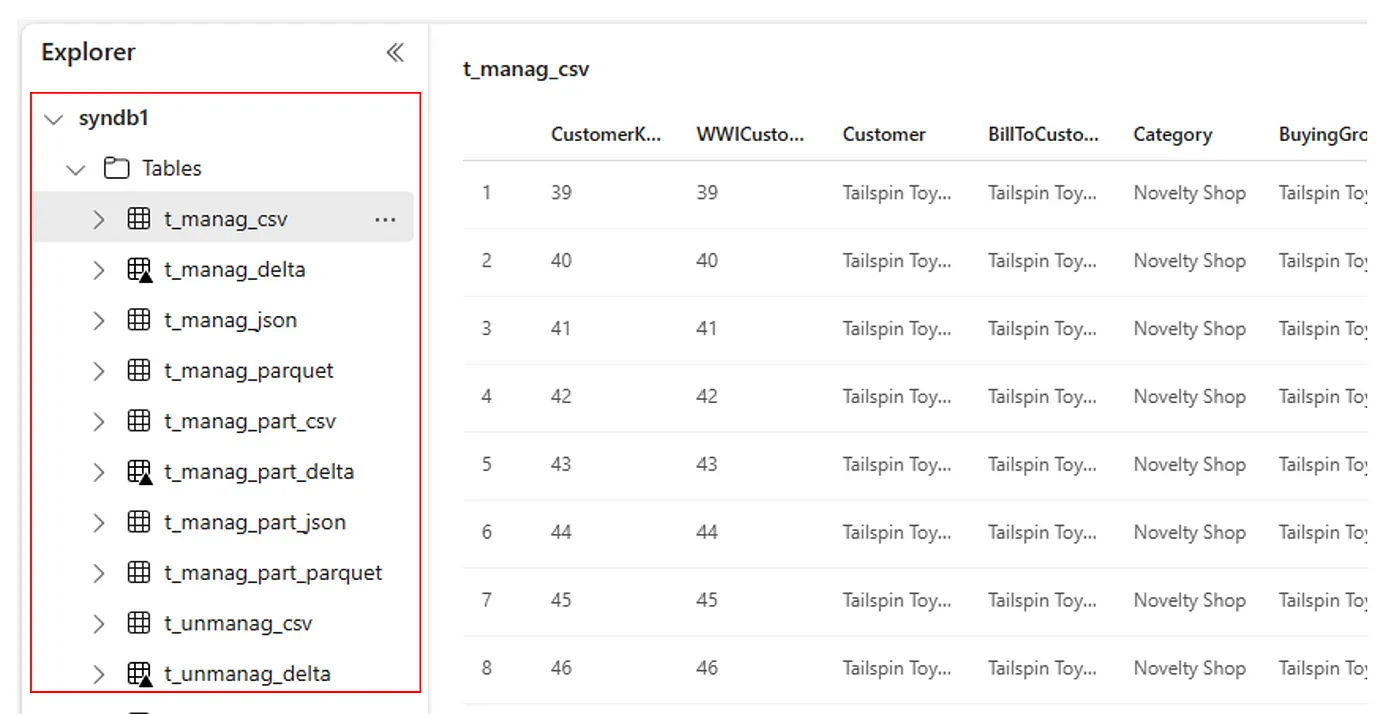
または、インポートされたすべてのテーブルは、レイクハウスごとに Lakehouse エクスプローラー UI のテーブル セクション内に表示されます。
その他の考慮事項
- スケーラビリティ: このソリューションでは内部 Spark カタログ API を使用してインポート/エクスポートを行いますが、カタログ オブジェクトを取得するために HMS に直接接続されていないため、カタログが大きい場合はソリューションを適切にスケーリングできません。 HMS DB を使用してエクスポート ロジックを変更する必要があります。
- データの精度: 分離の保証はありません。つまり、移行ノートブックの実行中に Spark コンピューティング エンジンがメタストアに対して同時変更を行っている場合、一貫性のないデータが Fabric レイクハウスに導入される可能性があります。
関連するコンテンツ
- Fabric とAzure Synapse Spark
- 詳細については、Spark プール、構成、ライブラリ、ノートブック、および Spark ジョブ定義の移行オプションを参照してください