Microsoft Fabric の Data Factory での Parquet 形式
この記事では、Microsoft Fabric の Data Factory のデータ パイプラインで Parquet 形式を構成する方法の概要を示します。
サポートされる機能
Parquet 形式は、次のアクティビティとコネクタでソースとコピー先としてサポートされています。
| カテゴリ | コネクタ/アクティビティ |
|---|---|
| サポートされているコネクタ | Amazon S3 |
| Amazon S3 互換 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| ファイル システム | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| レイクハウス ファイル | |
| Oracle Cloud Storage | |
| SFTP | |
| サポートされているアクティビティ | Copy アクティビティ (コピー元/コピー先) |
| Lookup アクティビティ | |
| GetMetadata アクティビティ | |
| アクティビティを削除する |
コピー アクティビティの Parquet 形式
Parquet 形式を構成するには、データ パイプラインの Copy アクティビティのソースまたはコピー先で接続を選択し、[ファイル形式] のドロップダウン リストで [Parquet] を選択します。 この形式をさらに構成するには、[設定] を選択します。
ソースとしての Parquet 形式
[ファイル形式] セクションで [設定] を選択すると、ポップアップの [File format settings] (ファイル形式設定) ダイアログ ボックスに以下のプロパティが表示されます。
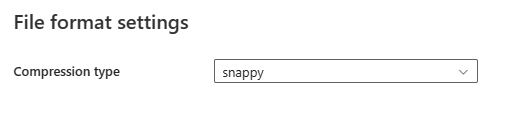
- [圧縮の種類]: ドロップダウン リストで Parquet ファイルの読み取りに使用する圧縮コーデックを選択します。 None、gzip (.gz)、snappy、lzo、Brotli (.br)、Zstandard、lz4、lz4frame、bzip2 (.bz2)、または lz4hadoop から選択できます。
コピー先としての Parquet 形式
[設定] を選択すると、[File format settings] (ファイル形式設定) ダイアログ ボックスに以下のプロパティが表示されます。

[圧縮の種類]: ドロップダウン リストで Parquet ファイルの書き込みに使用する圧縮コーデックを選択します。 None、gzip (.gz)、snappy、lzo、Brotli (.br)、Zstandard、lz4、lz4frame、bzip2 (.bz2)、または lz4hadoop から選択できます。
V オーダーの使用: Parquet ファイル形式に対する書き込み時間の最適化を有効にします。 詳細については、「Delta Lake テーブルの最適化と V オーダー」を参照してください。 共有メモリ プロトコルは既定で有効になっています。
[コピー先] タブの [詳細] 設定に、次の Parquet 形式の関連プロパティが表示されます。
- [ファイルあたりの最大行数]: データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。 ファイルごとに書き込む最大行数を指定します。
- [ファイル名プレフィックス]: [ファイルあたりの最大行数] が構成されている場合に適用されます。 データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に
<fileNamePrefix>_00000.<fileExtension>のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。
表形式の概要
ソースとしての Parquet
Parquet 形式を使用する場合、Copy アクティビティの [ソース] セクションでは、次のプロパティがサポートされます。
| 名前 | Description | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| ファイル形式 | 使用するファイル形式。 | Parquet | はい | type ("datasetSettings の下"):Parquet |
| [圧縮の種類] | Parquet ファイルの読み取りに使用される圧縮コーデックです。 | 次の中から選択します。 なし gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
いいえ | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
コピー先としての Parquet
Parquet 形式を使用する場合、Copy アクティビティの [Destination] (コピー先) セクションでは、次のプロパティがサポートされます。
| 名前 | Description | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| ファイル形式 | 使用するファイル形式。 | Parquet | はい | type ("datasetSettings の下"):Parquet |
| V オーダーの使用 | Parquet ファイル形式に対する書き込み時間の最適化。 | 選択または選択解除 | いいえ | enableVertiParquet |
| [圧縮の種類] | Parquet ファイルの書き込みに使用される圧縮コーデックです。 | 次の中から選択します。 なし gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
いいえ | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| ファイルあたりの最大行数 | データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。 ファイルごとに書き込む最大行数を指定します。 | <ファイルあたりの最大行数> | いいえ | maxRowsPerFile |
| ファイル名プレフィックス | [ファイルあたりの最大行数] が構成されている場合に適用されます。 データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に <fileNamePrefix>_00000.<fileExtension> のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。 |
<実際のファイル名のプレフィックス> | いいえ | fileNamePrefix |