Microsoft Fabric でメダリオン Lakehouse アーキテクチャを実装
この記事では、メダリオン レイク アーキテクチャについて説明し、Microsoft Fabric でレイクハウスを実装する方法について説明します。 これは複数のユーザーを対象としています。
- データ エンジニア: 組織が大量のデータを収集、保存、処理、分析できるようにするインフラストラクチャとシステムを設計、構築、および管理する技術スタッフ。
- センター オブ エクセレンス、IT、および BI チーム: 組織全体の分析を監督する責任を担うチーム。
- Fabric 管理者: 組織の Fabric 監視を担当する管理者。
メダリオン レイクハウス アーキテクチャ (一般に"メダリオン アーキテクチャ" と呼ばれます) は、組織がレイクハウス内のデータを論理的に整理するために使用する設計パターンです。 これは Fabric に推奨される設計アプローチです。
メダリオン アーキテクチャは、3 つの異なるレイヤー (ゾーン) で構成されています。 各レイヤーは、レイクハウスに保存されているデータの品質を示し、高いレベルは高い品質を表します。 この多層アプローチは、エンタープライズ データ製品にとっての信頼できる唯一のソースを構築するのに役立ちます。
重要なことは、メダリオンアーキテクチャは、データがレイヤーを通過する際に、原子性、一貫性、分離、耐久性(ACID)を保証することです。 生データから始まり、一連の検証と変換により、効率的な分析用に最適化されたデータが作られます。 メダリオン ステージには、ブロンズ (生)、シルバー (検証済み)、ゴールド (強化) の 3 つのステージがあります。
詳細については、「メダリオン レイクハウス アーキテクチャとは」を参照してください。
Fabric の OneLake とレイクハウス
最新のデータ ウェアハウスの基礎は、データ レイクです。 Microsoft OneLake は、組織全体のための、統合された単一論理データ レイクです。 これは、すべての Fabric テナントに自動的にプロビジョニングされており、すべての分析データのための単一の場所として設計されています。
OneLake を使用すると、次のことができます。
- サイロを削除し、管理作業を減らします。 すべての組織データは、単一のデータ レイク リソース内で保存、管理、およびセキュリティ保護されます。 OneLake は Fabric テナントにプロビジョニングされているため、さらにプロビジョニングまたは管理するリソースはありません。
- データの移動と重複を減らします。 OneLake の目的は、データのコピーを 1 個だけ保存することです。 データのコピーが少ないほどデータ移動プロセスが少なくなり、効率の向上と複雑さの削減につながります。 必要に応じて、OneLake にコピーするのではなく、ショートカットを作成して他の場所に保存されているデータを参照できます。
- 複数の分析エンジンを使用します。 OneLake のデータは、オープン形式で保存されます。 こうすることで、Analysis Services (Power BI で使用)、T-SQL、Apache Spark など、さまざまな分析エンジンでデータを照会できます。 Fabric 以外の他のアプリケーションも、API と SDK を使用して OneLake にアクセスできます。
詳細については、「OneLake、データ用の OneDrive」を参照してください。
OneLake にデータを保存するには、Fabric に"レイクハウス" を作成します。 レイクハウスは、構造化データと非構造化データを 1 か所に保存、管理、分析するためのデータ アーキテクチャ プラットフォームです。 あらゆるファイルの種類とサイズで大量データ ボリュームに簡単にスケーリングでき、また、それが 1 か所に保存されているため、組織全体で簡単に共有および再利用できます。
各レイクハウス には、データを移動することなくデータ ウェアハウス機能が利用できる SQL 分析エンドポイントが組み込まれています。 つまり、特別なセットアップを行わなくても、SQL クエリを使用して、レイクハウス内のデータに対してクエリを実行できます。
詳細については、「Microsoft Fabric のレイクハウスとは」を参照してください。
テーブルとファイル
Fabric でレイクハウスを作成すると、テーブルとファイルに対して 2 か所の物理ストレージが自動的にプロビジョニングされます。
- テーブルは、Apache Spark (CSV、Parquet、または Delta) のすべての形式のテーブルをホストするためのマネージド領域です。 自動的に作成されたか明示的に作成されたかに関係なく、すべてのテーブルはレイクハウス内のテーブルとして認識されます。 また、ファイル ベースのトランザクション ログを含む Parquet データ ファイルである Delta テーブルもテーブルとして認識されます。
- ファイル は、任意のファイル形式でデータを保存するためのアンマネージド領域です。 この領域に保存されているデルタ ファイルは、テーブルとして自動的に認識されません。 アンマネージド領域の Delta Lake フォルダー上にテーブルを作成する場合は、Apache Spark の Delta Lake ファイルを含むアンマネージド フォルダーを指す場所を持つショートカットまたは外部テーブルを明示的に作成する必要があります。
マネージド領域 (テーブル) とアンマネージド領域 (ファイル) の主な違いは、テーブルの自動検出と登録プロセスです。 このプロセスは、マネージド領域で作成されたフォルダーに対してのみ実行されますが、アンマネージド領域では実行されません。
Microsoft Fabric のレイクハウス エクスプローラーでは、ユーザーがデータのナビゲーション、アクセス、更新を行うための、レイクハウス全体で統一されたグラフィカル表現が提供されます。
テーブルの自動検出の詳細については、「テーブルの自動検出と登録」を参照してください。
Delta Lake ストレージ
Delta Lake は、データとテーブルを保存するための基盤を提供する最適化されたストレージ レイヤーです。 ビッグ データ ワークロードに対する ACID トランザクションがサポートされており、このため Fabric レイクハウスの既定のストレージ形式となっています。
重要なのは、Delta Lake は、ストリーミング操作とバッチ操作の両方に対して、レイクハウスの信頼性、セキュリティ、パフォーマンスを提供することです。 内部的には Parquet ファイル形式でデータを保存しますが、トランザクション ログと統計も保持することで標準の Parquet 形式に勝る機能とパフォーマンス向上を提供します。
Delta Lake 形式では、一般的なファイル形式に比べて次の主な利点があります。
- ACID プロパティのサポート、特にデータ破損を防ぐための持続性。
- 読み取りクエリの高速化。
- データ鮮度の向上。
- バッチ ワークロードとストリーミング ワークロードの両方に対するサポート。
- Delta Lake タイム トラベルを使用したデータロールバックのサポート。
- Delta Lake テーブル履歴を使用した規制コンプライアンスと監査の強化。
Fabric は Delta Lake を使用してストレージ ファイル形式を標準化します。既定では、Fabric 内のすべてのワークロード エンジンにおいて、新しいテーブルへのデータ書き込み時に Delta テーブルが作成されます。 詳細については、「レイクハウスと Delta Lake テーブル」を参照してください。
Fabric のメダリオン アーキテクチャ
メダリオン アーキテクチャの目標は、各段階を進むにつれて、データの構造と品質を段階的に向上させることです。
メダリオン アーキテクチャは、3 つの異なるレイヤー (またはゾーン) で構成されています。
- ブロンズ: "生ゾーン" とも呼ばれるこの最初のレイヤーは、元の形式でソース データを保存します。 このレイヤーのデータは通常、追加専用で変更不可です。
- シルバー: "エンリッチド ゾーン" とも呼ばれるこのレイヤーには、ブロンズ レイヤーを元とするデータが保存されます。 生データはクレンジングおよび標準化され、テーブル (行と列) として構造化されるようになりました。 また、他のデータと統合して、顧客、製品などのすべてのビジネス エンティティのエンタープライズ ビューを提供することもできます。
- ゴールド: "キュレーション ゾーン" とも呼ばれるこの最終レイヤーには、シルバー レイヤーを元とするデータが保存されます。 データは、特定のダウンストリーム ビジネスと分析の要件を満たすように調整されます。 テーブルは通常、パフォーマンスと使いやすさのために最適化されたデータ モデルの開発をサポートするスター スキーマ設計に準拠します。
重要
Fabric レイクハウスは単一ゾーンを代表するため、3 つのゾーンのそれぞれについて 1 個のレイクハウスを作成します。
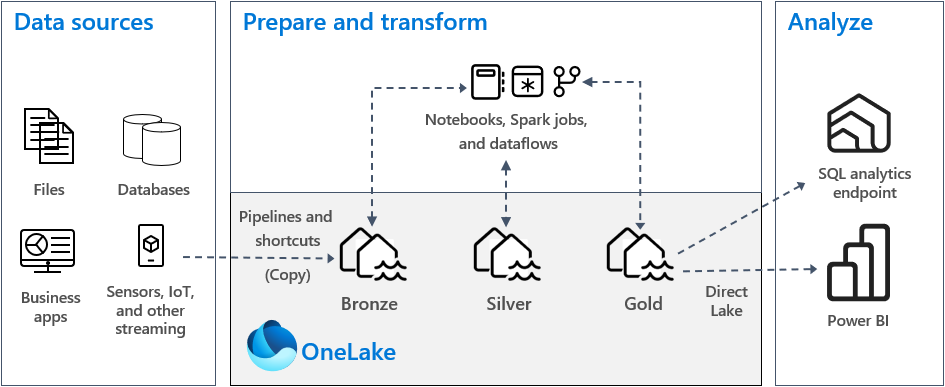
Fabric の一般的なメダリオン アーキテクチャの実装では、ブロンズ ゾーンはデータ ソースと同じ形式でデータを保存します。 データ ソースがリレーショナル データベースの場合は、Delta テーブルが適しています。 シルバーゾーンとゴールドゾーンには Delta テーブルが含まれています。
ヒント
レイクハウスを作成する方法については、「レイクハウス のエンドツーエンド シナリオ」チュートリアルを参照してください。
Fabric レイクハウスのガイダンス
このセクションでは、メダリオン アーキテクチャを使用した Fabric レイクハウスの実装に関連するガイダンスを提供します。
デプロイメント モデル
Fabric でメダリオン アーキテクチャを実装するには、レイクハウス (ゾーンごとに 1 個)、データ ウェアハウス、またはその両方の組み合わせを使用できます。 自分の好みとチームの専門知識に基づいて判断する必要があります。 Fabric には柔軟性があることに注意してください。OneLake のデータの単一のコピーで動作するさまざまな分析エンジンを使用できます。
考慮すべき 2 つのパターンを次に示します。
- パターン 1: 各ゾーンをレイクハウスとして作成します。 この場合、ビジネス ユーザーは SQL 分析エンドポイントを使用してデータにアクセスします。
- パターン 2: ブロンズ ゾーンとシルバー ゾーンをレイクハウスとして作成し、ゴールド ゾーンをデータ ウェアハウスとして作成します。 この場合、ビジネス ユーザーはデータ ウェアハウス エンドポイントを使用してデータにアクセスします。
1 つの Fabric ワークスペースにすべての レイクハウス を作成できますが、各レイクハウスをそれぞれ個別の Fabric ワークスペースに作成することをお勧めします。 このアプローチにより、ゾーン レベルで制御が強化され、ガバナンスが向上します。
ブロンズ ゾーンでは、元の形式でデータを保存するか、Parquet または Delta Lake を使用することをお勧めします。 可能な限り、データを元の形式に保つようにします。 ソース データが OneLake、Azure Data Lake Store Gen2 (ADLS Gen2)、Amazon S3、または Google からのデータである場合は、データをコピーするのではなく、ブロンズ ゾーンにショートカットを作成します。
シルバー ゾーンとゴールド ゾーンでは、追加の機能とパフォーマンス強化が提供されているため、Delta テーブルを使用することをお勧めします。 Fabric は Delta Lake 形式で標準化されており、既定では Fabric のすべてのエンジンがこの形式でデータを書き込みます。 さらに、これらのエンジンでは、Parquet ファイル形式に対する V オーダー書き込み時間の最適化が使用されます。 この最適化により、Power BI、SQL、Apache Spark などの Fabric コンピューティング エンジンでの非常に高速な読み取りが可能になります。 詳細については、「Delta Lake テーブルの最適化と V オーダー」を参照してください。
最後に、今日、多くの組織は、データ量の大幅な増加に直面しており、また、そのデータを論理的な方法で整理および管理する必要性が高まっています。一方で、よりターゲットを絞った効率的な使用とガバナンスが促進されています。 このため、ガバナンスによる分散型またはフェデレーションデータ組織を確立して管理することが求められる場合があります。
この目的を達成するには、"データ メッシュ アーキテクチャ" の実装を検討してください。 "データ メッシュ" は、製品としてデータを提供するデータ ドメインの作成に重点を置くアーキテクチャ パターンです。
データ ドメインを作成することで、Fabric でデータ資産のデータ メッシュ アーキテクチャを作成できます。 マーケティング、販売、在庫、人事などのビジネス ドメインにマップするドメインを作成できます。 その後、各ドメイン内にデータ ゾーンを設定することで、メダリオン アーキテクチャを実装できます。
ドメインの詳細については、「ドメイン」を参照してください。
Delta テーブル データ ストレージについて
このセクションでは、Fabric でのメダリオン レイクハウス アーキテクチャの実装に関連するその他のガイダンス トピックについて説明します。
ファイル サイズ
一般に、ビッグ データ プラットフォームは、多数の小さなファイルではなく、少数の大きなファイルがある場合にパフォーマンスが向上します。 これは、コンピューティング エンジンが多数のメタデータとファイル操作を管理する必要がある場合に、パフォーマンスの低下が発生するためです。 クエリのパフォーマンス向上のために、サイズが約 1 GB のデータ ファイルを目指することをお勧めします。
Delta Lake には、"予測最適化"と呼ばれる機能があります。 予測最適化により、差分テーブルのメンテナンス操作を手動で管理する必要がなくなります。 この機能を有効にすると、Delta Lake は、メンテナンス操作の恩恵を受けるテーブルを自動的に識別し、そのストレージを最適化します。 データの他のリーダーやライターに影響を与えることなく、多数の小さなファイルを大きなファイルに透過的に結合できます。 この機能はオペレーショナル エクセレンスとデータ準備作業の一部となるべきですが、Fabric には、データ書き込み中にこれらのデータ ファイルを最適化する機能もあります。 詳細については、「Delta Lake の予測最適化」を参照してください。
履歴のリテンション期間
既定では、Delta Lake は加えられたすべての変更の履歴を保持します。つまり、履歴メタデータのサイズは時間の経過と同時に大きくなります。 ビジネス要件に基づいて、ストレージ コストを削減するために履歴データを一定期間のみ保持することを目指す必要があります。 過去 1 か月のみ、またはその他の適切な期間のみ履歴データを保持することを検討してください。
VACUUM コマンドを使用して、Delta テーブルから古い履歴データを削除できます。 ただし、既定では過去 7 日以内の履歴データを削除することはできません。これは、データの一貫性を維持するためです。 この既定の日数は、table プロパティ delta.deletedFileRetentionDuration = "interval <interval>" によって制御されています。 これは、バキューム操作の候補と見なされる前に、ファイルを削除する必要がある期間を決定します。
テーブルのパーティション
各ゾーンにデータを保存する際には、必要に応じてパーティション分割されたフォルダー構造を使用することをお勧めします。 この手法は、データの管理容易性とクエリのパフォーマンスを向上させるために役立ちます。 一般に、フォルダー構造内にあるパーティション分割されたデータでは、パーティションの排除/除去により、特定のデータ エントリの検索が高速になります。
通常は、新しいデータが生じると、その都度ターゲット テーブルにデータを追加します。 ただし、場合によっては、既存のデータを同時に更新するために、データをマージすることがあります。 その場合は、MERGE コマンドを使用して "アップサート" 操作を実行できます。 ターゲット テーブルがパーティション分割されている場合は、パーティション フィルターを使用して操作を高速化するようにしてください。 これにより、エンジンは更新を必要としないパーティションを排除できます。
データ アクセス
最後に、レイクハウス内の特定のデータにアクセスする必要があるユーザーを計画し、制御する必要があります。 また、このデータへのアクセス中に使用されるさまざまなトランザクション パターンについても理解する必要があります。 その上で、Delta Lake の Z オーダー インデックスを使用して、適切なテーブル パーティション分割スキームとデータ コロケーションを定義できます。
関連するコンテンツ
Fabric レイクハウスの実装の詳細については、次のリソースを参照してください。
- チュートリアル: レイクハウスのエンドツーエンド シナリオ
- レイクハウスと Delta Lake テーブル
- Microsoft Fabric 決定ガイド: データ ストアを選択する
- Delta Lake テーブルの最適化と V オーダー
- Apache Spark における書き込みの最適化の必要性について
- 疑問がある場合 Fabric コミュニティに質問してみましょう。
- Power BI チームへのご提案は、 Fabric 改善のアイデアを投稿してください。