データフローを使用してソリューションを開発する
Power BI "データフロー" はエンタープライズに重点を置いたデータ準備ソリューションであり、使用、再利用、統合の準備が整ったデータのエコシステムを可能にします。 この記事では、一般的なシナリオや記事へのリンクに加え、データフローを理解して最大限に活用するために役立つその他の情報を提供します。
データフローの Premium 機能にアクセスする
Premium 容量の Power BI データフローには、次のように、データフローのスケールとパフォーマンスの向上に役立つ多くの重要な機能があります。
- 高度なコンピューティング。ETL パフォーマンスを高速化し、DirectQuery 機能を提供します。
- 増分更新。ソースから変更されたデータを読み込むことができます。
- リンクされたエンティティ。他のデータフローを参照するために使用できます。
- 計算済みエンティティ。より多くのビジネス ロジックを含むデータフローのコンポーザブルな構成要素の作成に使用できます。
このような理由から、可能な限り Premium 容量でデータフローを使用することが推奨されます。 Power BI Pro ライセンスで使用されるデータフローは、シンプルで小規模なユースケースに使用できます。
解決策
これらのデータフローの Premium 機能にアクセスするには、次の 2 つの方法があります。
- 特定のワークスペースに Premium 容量を指定し、ここでデータフローを作成するための独自の Pro ライセンスを用意する。
- 独自の Premium Per User (PPU) ライセンスを用意する。この場合、ワークスペースの他のメンバーも PPU ライセンスを所有している必要があります。
PPU 環境 (Premium やその他の SKU やライセンスなどの) の外部で PPU データフロー (またはその他の任意のコンテンツ) を使用することはできません。
Premium 容量の場合、Power BI Desktop のデータフローのコンシューマーには、使用と Power BI への発行のために明示的なライセンスは必要ありません。 ただし、ワークスペースに発行したり、結果のセマンティック モデルを共有したりするには、少なくとも Pro ライセンスが必要です。
PPU の場合、PPU コンテンツを作成または使用するすべてのユーザーは、PPU ライセンスを持っている必要があります。 この要件は、すべてのユーザーに PPU のライセンスを明示的に付与する必要があるという点でその他の Power BI とは異なります。 ワークスペースを Premium 容量に移行しない限り、PPU コンテンツで Free、Pro、または Premium 容量を混在させることはできません。
通常、どのモデルを選択するかは組織の規模と目標によって異なりますが、次のガイドラインが当てはまります。
| チームの種類 | Premium Per Capacity | Premium Per User |
|---|---|---|
| >5,000 ユーザー | ✔ | |
| <5,000 ユーザー | ✔ |
小規模なチームの場合、PPU によって Free、Pro、Premium Per Capacity 間のギャップを埋めることができます。 より大きなニーズがある場合は、Pro ライセンスを持つユーザーと共に Premium 容量を使用するのが最善の方法になります。
セキュリティが適用されたユーザー データフローを作成する
使用のためのデータフローを作成する必要がありますが、セキュリティ上の要件があるとします。
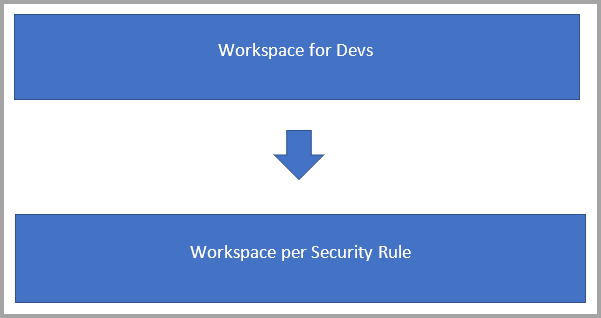
このシナリオでは、次の 2 種類のワークスペースがある可能性があります。
データフローを開発し、ビジネス ロジックを構築するバックエンド ワークスペース。
一部のデータフローまたはテーブルを、使用のために特定のユーザーのグループに公開するユーザー ワークスペース。
- ユーザー ワークスペースには、バックエンド ワークスペースのデータフローを参照するリンク テーブルが含まれます。
- ユーザーは、コンシューマー ワークスペースに閲覧者としてアクセスでき、バックエンド ワークスペースにはアクセスできません。
- ユーザーが Power BI Desktop を使用してユーザー ワークスペースのデータフローにアクセスする場合、そのデータフローを表示できます。 ただし、ナビゲーターではデータフローは空として表示されるため、リンク テーブルは表示されません。
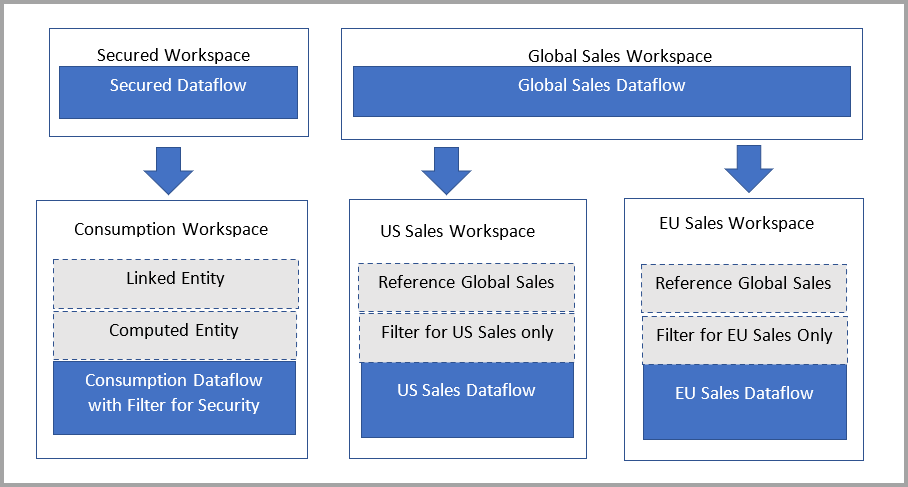
リンク テーブルについて
リンク テーブルは、単に元のデータフロー テーブルへのポインターにすぎず、ソースの権限が継承されます。 Power BI で、リンク テーブルによる宛先のアクセス許可の使用が許可されている場合、宛先にソースを参照するリンク テーブルを作成することによって、すべてのユーザーがソースのアクセス許可を回避できます。
解決策: 計算テーブルを使用する
Power BI Premium へのアクセス権がある場合は、宛先に、リンク テーブルを参照する計算テーブルを作成できます。これにはリンク テーブルのデータのコピーが含まれます。 プロジェクションを使用して列を削除したり、フィルターを使用して行を削除したりできます。 宛先のワークスペースに対するアクセス許可を持つユーザーは、このテーブル経由でデータにアクセスできます。
権限のある個人の系列には参照されているワークスペースも表示されるので、ユーザーは親データフローを完全に理解するためにリンクで戻ることができます。 権限のないユーザーについては、プライバシーは引き続き尊重されます。 ワークスペースの名前だけが表示されます。
次の図は、この設定を示しています。 左側はアーキテクチャ パターンです。 右側は、リージョンによって分割されセキュリティで保護された売上データを示す例です。
データフローの更新時間を短縮する
大規模なデータフローがありますが、そのデータフローからセマンティック モデルを構築し、その更新に必要な時間を短縮する必要があるとします。 通常、更新は、データ ソースからデータフロー、さらにセマンティック モデルまで、完了するのに長い時間がかかります。 時間のかかる更新は、管理や保守が難しくなります。
解決策: 参照されているテーブルに対して [読み込みを有効にする] が明示的に構成されたテーブルを使用し、読み込みを無効にしない
データフローの更新の理解および最適化に関する記事で定義されているように、Power BI ではデータフローのシンプルなオーケストレーションがサポートされています。 オーケストレーションを利用するには、ダウンストリーム データフローを明示的に [読み込みを有効にする] に構成する必要があります。
読み込みを無効にすることは、通常、大量のクエリを読み込むオーバーヘッドによって、開発中のエンティティの利点が相殺される場合にのみ適しています。
読み込みを無効にすることは、その特定のクエリが構成要素として使用される (つまり、他のデータフローで参照される) 場合に、Power BI によって評価されないことを意味します。また、ポインターを提供したり、フォールディングやクエリの最適化を実行したりできる既存のテーブルとして、Power BI によって扱われないことも意味します。 この意味では、結合やマージなどの変換を実行することは、単に 2 つのデータ ソース クエリの結合やマージにすぎません。 このような操作は、パフォーマンスに悪影響を及ぼす可能性があります。計算済みのロジックを Power BI を使用してもう一度完全に読み込んでから、追加のロジックを適用する必要があるためです。
データフローのクエリ処理を簡素化し、エンジンの最適化が確実に行われるようにするには、読み込みを有効にし、Power BI Premium データフローのコンピューティング エンジンが、最適化の既定の設定で設定されていることを確認します。
Power BI では、読み込みが有効になっていないデータフローが新しい項目と見なされるため、読み込みを有効にすることで、系列の完全なビューを維持することもできます。 系列が重要な場合は、他のデータフローに接続されているエンティティまたはデータフローの読み込みを無効にしないでください。
セマンティック モデルの更新時間を短縮する
大規模なデータフローがありますが、それからセマンティック モデルを構築し、オーケストレーションを削減する必要があるとします。 更新は、データ ソースからデータフロー、さらにセマンティック モデルまで、完了するのに長い時間がかかり、待機時間が増加します。
解決策: DirectQuery データフローを使用する
DirectQuery は、ワークスペースの拡張コンピューティング エンジン (ECE) 設定が明示的に [オン] に構成されていれば、いつでも使用できます。 この設定は、Power BI モデルに直接読み込む必要のないデータがある場合に便利です。 ECE を初めて [オン] に構成する場合は、次の更新時に DirectQuery を許可する変更が行われます。 変更をすぐに行えるようにするには、更新する必要があります。 Power BI によってストレージとマネージド SQL エンジンの両方にデータが書き込まれるため、最初のデータフロー読み込みの更新は遅くなることがあります。
まとめると、データフローで DirectQuery を使用すると、Power BI とデータフローのプロセスに対して次の機能強化が可能になります。
- 個別の更新スケジュールを回避する: DirectQuery では、データフローに直接接続するため、インポートされたセマンティック モデルを作成する必要がなくなります。 そのため、データフローに DirectQuery を使用することで、データフローとセマンティック モデル用の個別の更新スケジュールが不要になり、データの同期が保証されます。
- データのフィルター処理: DirectQuery は、データフロー内のデータのフィルター処理されたビューを操作する場合に便利です。 データをフィルター処理することでデータフロー内のデータの小さなサブセットを処理したい場合は、DirectQuery (および ECE) を使用してデータフローのデータをフィルター処理し、目的のフィルター処理されたサブセットを操作できます。
一般に、DirectQuery を使用すると、セマンティック モデル内のデータは最新の状態になりますが、レポートのパフォーマンスはインポート モードと比較して低くなります。 次の場合にのみ、この方法を検討してください。
- ユースケースでデータフローから受信するデータの待機時間を短くする必要がある。
- データフローのデータが大きい。
- インポートでは時間がかかりすぎる。
- キャッシュ パフォーマンスと引き換えに最新データを得ることを望む。
解決策: データフロー コネクタを使用して、クエリ フォールディングとインポートの増分更新を有効にする
統合データフロー コネクタにより、join、distinct、filter、group by 操作の実行などの計算されたエンティティに対して実行されるステップの評価時間を大幅に短縮できます。 次の 2 つの具体的な利点があります。
- Power BI Desktop のデータフロー コネクタに接続しているダウンストリーム ユーザーは、新しいコネクタでクエリ フォールディングがサポートされているため、作成シナリオで優れたパフォーマンスを活かすことができます。
- セマンティック モデル更新操作は、拡張コンピューティング エンジンにもフォールディングできます。つまり、セマンティック モデルからの増分更新もデータフローにフォールディングできます。 この機能により、更新のパフォーマンスが向上し、更新サイクル間の待機時間が短縮される可能性があります。
任意の Premium データフローに対してこの機能を有効にするには、コンピューティング エンジンが明示的に [オン] に設定されていることを確認します。 次に、Power BI Desktop でデータフロー コネクタを使用します。 この機能を利用するには、2021 年 8 月以降のバージョンの Power BI Desktop を使用する必要があります。
既存のソリューションでこの機能を使用するには、Premium または Premium Per User サブスクリプションである必要があります。 また、「拡張コンピューティング エンジンの使用」の説明に従って、データフローにいくつかの変更を加える必要がある場合もあります。 Source セクションの PowerBI.Dataflows を PowerPlatform.Dataflows に置き換えることで、新しいコネクタを使用するように既存の Power Query クエリを更新する必要があります。
Power Query での複雑なデータフローの作成
数百万行のデータのデータフローがありますが、複雑なビジネス ロジックとそれによる変換を構築する必要があるとします。 大規模なデータフローを操作するためのベスト プラクティスに従う必要があります。 また、データフローのプレビューを迅速に実行する必要があります。 しかし、数十の列と数百万行のデータがあります。
解決策: スキーマ ビューを使用する
スキーマ ビューを使用できます。これは、クエリの列情報を前面および中央に配置することにより、スキーマ レベルの操作に取り組む際にフローを最適化するように設計されています。 スキーマ ビューでは、データ構造を形成するためのコンテキストの対話が提供されます。 また、スキーマ ビューでは、列のメタデータを計算する必要があるだけで、完全なデータ結果を必要としないため、待機時間が短い操作も提供されます。
大規模なデータ ソースを操作する
ソース システムでクエリを実行しますが、システムへの直接アクセスを提供したり、アクセスを民主化したりしないものとします。 これをデータフローに配置することを計画しています。
解決策 1: クエリのビューを使用するか、クエリを最適化する
最適化されたデータ ソースとクエリを使用することが最善のオプションです。 多くの場合、データ ソースは、それを目的としたクエリで最適に動作します。 Power Query では、クエリ フォールディング機能が強化され、これらのワークロードが委任されます。 また、Power BI でも、Power Query Online にステップ フォールディング インジケーターが提供されています。 インジケーターの種類の詳細については、ステップ フォールディング インジケーターのドキュメントを参照してください。
解決方法 2: ネイティブ クエリを使用する
Value.NativeQuery() M 関数を使用することもできます。 3 番目のパラメーターで EnableFolding=true を設定します。 ネイティブ クエリについては、Postgres コネクタの場合はこちらの Web サイトでドキュメント化されています。 これは SQL Server コネクタでも機能します。
解決策 3: データフローを取り込みデータフローと消費データフローに分割し、ECE とリンクされたエンティティを活用する
データフローを別々の取り込みデータフローと消費データフローに分割することで、ECE とリンクされたエンティティを活用できます。 このパターンやその他の詳細については、ベスト プラクティスに関するドキュメントを参照してください。
可能な限り顧客がデータフローを使用するようにする
最適化されたディメンション (例: 顧客、データ テーブル、製品、地域) など、一般的な目的を果たす多くのデータフローがあるとします。 データフローは、Power BI のリボンで既に使用できます。 お客様が作成したデータフローを主に使用するのが理想的です。
解決策: 承認を使用してデータフローを認定し、昇格させる
承認のしくみについて詳しくは、「承認 - Power BI コンテンツの昇格と認定」を参照してください。
Power BI データフローのプログラミングと自動化
インポート、エクスポート、または更新を自動化するビジネス要件と、Power BI の外部で追加のオーケストレーションとアクションがあるとします。 次の表で説明するように、その実行を可能にするためにいくつかのオプションがあります。
| Type | メカニズム |
|---|---|
| PowerAutomate テンプレートを使用する。 | コードなし |
| PowerShell の自動化スクリプトを使用する。 | 自動化スクリプト |
| API を使用して、独自のビジネス ロジックを構築する。 | Rest API |
更新の詳細については、「データフローの更新の理解および最適化」を参照してください。
ダウンストリームのデータ資産を確実に保護する
秘密度ラベルを使用して、データフローに接続するダウンストリーム項目に対して、構成したデータ分類とルールを適用できます。 秘密度ラベルの詳細については、Power BI の秘密度ラベルに関する説明を参照してください。 継承について確認するには、Power BI での秘密度ラベルの下流への継承に関する記事を参照してください。
Multi-Geo のサポート
現在、多くのお客様が、データ主権とデータ所在地の要件を満たすニーズを抱えています。 データフロー ワークスペースを Multi-Geo にする手動の構成を実行できます。
データフローでは、独自のストレージ アカウントの取り込み機能が使用される場合に Multi-Geo がサポートされます。 この機能は、「Azure Data Lake Gen 2 を使用するようにデータフロー ストレージを構成する」で説明されています。 この機能にアタッチする前に、ワークスペースを空にする必要があります。 この特定の構成により、選択した特定の地理的領域にデータフロー データを格納できます。
仮想ネットワークの背後のデータ資産を確実に保護する
現在、多くのお客様が、プライベート エンドポイントの背後のデータ資産をセキュリティで保護するニーズを抱えています。 そうするには、仮想ネットワークとゲートウェイを使用して準拠を維持します。 次の表では、現在の仮想ネットワークのサポートについて説明し、またデータフローを使用してデータ資産の準拠を維持し、保護する方法について説明します。
| シナリオ | 状態 |
|---|---|
| オンプレミス ゲートウェイを介して仮想ネットワーク データ ソースを読み取る。 | オンプレミス ゲートウェイを介してサポートされます |
| オンプレミス ゲートウェイを使用して、仮想ネットワークの背後にある秘密度ラベル アカウントにデータを書き込む。 | まだサポートされていません |
関連するコンテンツ
データフローと Power BI の詳細については、以下の記事を参照してください。