データフローの更新について理解し、最適化する
Power BI データフローを使用すると、下流の分析のために、データに接続して、変換、結合、および配布を行うことができます。 データフローの重要な要素は、更新プロセスです。これにより、データフロー内に作成した変換ステップが適用され、項目自体のデータが更新されます。
実行日時、パフォーマンス、最大限にデータフローを活用しているかどうかを把握するため、データフローを更新した後で更新履歴をダウンロードできます。
更新について
データフローに適用できる更新は、2 種類あります。
完全。これは、データの完全なフラッシュと再読み込みを実行します。
増分 (Premium のみ) 。これは、フィルターとして表現される、時間ベースの規則に基づいてデータのサブセットを処理します。この規則は、自分で構成します。 日付列のフィルターは、Power BI サービスでデータを複数の範囲に動的にパーティション分割します。 増分更新を構成すると、データフローによって、日付によるフィルタリングを含むようにクエリが自動的に変更されます。 Power Query の詳細エディターを使用して、自動生成されたクエリを編集し、更新を微調整またはカスタマイズすることができます。 独自の Azure Data Lake Storage を使用する場合は、設定した更新ポリシーに基づいてデータのタイム スライスを表示できます。
注意
増分更新とその動作について詳しくは、「データフローでの増分更新の使用」をご覧ください。
Power BI の大規模なデータフローの増分更新には、次の利点があります。
次の理由で、最初の更新後の更新が高速になる。
- Power BI は、ユーザーが指定した最後の N 個のパーティション (パーティションは日、週、月など) を更新します。または
- Power BI は、更新する必要があるデータのみを更新します。 たとえば、10 年間のセマンティック モデルの最近の 5 日間のみを更新します。
- ユーザーが変更をチェックする列を指定すると、Power BI は変更されたデータのみを更新します。
更新の信頼性が高くなる - 揮発性のソース システムへの長時間の接続を維持する必要がありません。
リソースの使用が減る - 更新するデータが少ないと、メモリや他のリソースの全体的な使用が減少します。
Power BI では可能な限りパーティションに対して並列処理が使用され、更新が高速になる可能性があります。
これらのどの更新シナリオでも、更新が失敗した場合、データは更新されません。 最新の更新が完了するまで、データが古い可能性があります。または、ユーザーは手動で更新でき、その場合はエラーなしで完了できます。 更新はパーティションまたはエンティティで行われるため、増分更新が失敗した場合、またはあるエンティティにエラーがある場合は、更新トランザクション全体が行われません。 つまり、パーティション (増分更新ポリシー) またはエンティティでデータフローが失敗した場合、更新操作全体が失敗し、データは更新されません。
更新を理解して最適化する
データフローの更新操作がどのように実行されるかをより深く理解するには、データフローの 1 つに移動して、データフローの [更新履歴] を確認します。 データフローの [その他のオプション] (...) を選びます。 次に、[設定] > [更新履歴] を選びます。 また、[ワークスペース] でデータフローを選ぶこともできます。 次に、[その他のオプション] (...) > [更新履歴] を選びます。
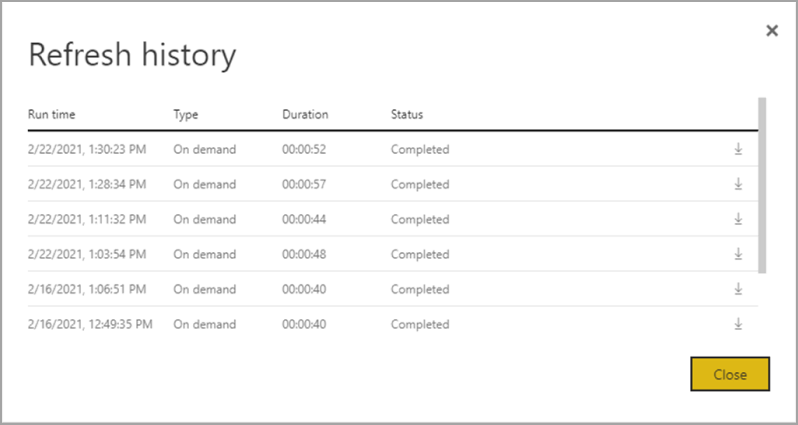
[更新履歴] には、種類 ( [オンデマンド] または [計画済み] )、継続時間、実行状態など、更新の概要が表示されます。 CSV ファイルの形式で詳細を表示するには、更新の説明の行の右端にあるダウンロード アイコンを選択します。 ダウンロードした CSV には、次の表に示す属性が含まれています。 共有容量に存在する Pro ベースのデータフローに対し、Premium の更新では追加のコンピューティングおよびデータフロー機能に基づく詳細な情報が提供されます。 そのため、次のメトリックの一部は Premium でのみ使用できます。
| Item | 説明 | Pro | Premium |
|---|---|---|---|
| 要求日時 | 更新がスケジュールされた、または [今すぐ更新] がクリックされた日時 (ローカル時間)。 | ✔ | ✔ |
| データフロー名 | データフローの名前。 | ✔ | ✔ |
| データフローの更新の状態 | 完了、失敗、またはスキップ (エンティティの場合) の状態があります。 スキップが表示される理由は、リンクされたエンティティなどのユース ケースです。 | ✔ | ✔ |
| エンティティ名 | テーブル名。 | ✔ | ✔ |
| パーティション名 | この項目はデータフローが Premium かどうかによって決まり、Pro の場合は、増分更新をサポートしていないので NA と表示されます。 Premium では、FullRefreshPolicyPartition または IncrementalRefreshPolicyPartition-[DateRange] が表示されます。 | ✔ | |
| 更新の状態 | 個々のエンティティまたはパーティションの更新の状態。更新されたデータのそのタイム スライスの状態が示されます。 | ✔ | ✔ |
| 開始時刻 | Premium では、この項目は、エンティティまたはパーティションでの処理のためにデータフローがキューに登録された日時です。 データフローに依存関係があり、上流のデータフローの結果セットが処理を開始するまで待機する必要がある場合、この日時は異なることがあります。 | ✔ | ✔ |
| 終了時刻 | 終了日時は、データフローのエンティティまたはパーティションが完了した日時です (該当する場合)。 | ✔ | ✔ |
| Duration | データフローが更新されるまでの合計経過時間 (HH:MM:SS)。 | ✔ | ✔ |
| 処理された行数 | 特定のエンティティまたはパーティションに対してデータフロー エンジンによってスキャンまたは書き込まれた行数。 実行した操作によっては、この項目にデータが含まれないことがあります。 コンピューティング エンジンが使われていない場合、またはデータが処理される場所としてゲートウェイを使用する場合は、データが省略されることがあります。 | ✔ | |
| Bytes processed (処理済みバイト数) | 特定のエンティティまたはパーティションに対してデータフロー エンジンによって書き込まれたデータ (バイト単位)。 この特定のデータフローでゲートウェイを使用している場合、この情報は提供されません。 |
✔ | |
| 最大コミット (KB) | 最大コミットは、M クエリが最適化されていない場合に、メモリ不足のエラーの診断に役立つ最大コミット メモリです。 この特定のデータフローでゲートウェイを使用している場合、この情報は提供されません。 |
✔ | |
| Processor Time | 特定のエンティティまたはパーティションに対して、データフロー エンジンによる変換の実行にかかった時間 (HH:MM:SS)。 この特定のデータフローでゲートウェイを使用している場合、この情報は提供されません。 |
✔ | |
| 待機時間 | 特定のエンティティまたはパーティションに対し、Premium 容量のワークロードに基づいて、エンティティが待機状態であった時間。 | ✔ | |
| コンピューティング エンジン | 特定のエンティティまたはパーティションについて、更新操作でコンピューティング エンジンがどのように使用されたかに関する詳細。 値は次のとおりです。 - NA - 折りたたみ済み - キャッシュ済み - キャッシュ済み + 折りたたみ済み これらの要素については、この記事で後ほど詳しく説明します。 |
✔ | |
| エラー | 該当する場合、詳細なエラー メッセージがエンティティまたはパーティションごとに記述されます。 | ✔ | ✔ |
データフローの更新に関するガイダンス
更新統計情報は、データフローのパフォーマンスの最適化と高速化に使用できる貴重な情報を提供します。 以降のセクションでは、いくつかのシナリオと、注意点、提供される情報に基づいて最適化する方法について説明します。
オーケストレーション
同じワークスペースでデータフローを使用すると、簡単なオーケストレーションを実現できます。 たとえば、1 つのワークスペースにデータフロー A、B、C があり、A > B > C のようにチェーンしているとします。ソース (A) を更新した場合、下流のエンティティも更新されます。 一方、C を更新した場合は、他のものを個別に更新する必要があります。 また、データフロー B に新しい (A には含まれていない) データ ソースを追加した場合、そのデータはオーケストレーションの一部として更新されません。
Power BI で実行されている管理されたオーケストレーションに適合しない項目をまとめて連結したい場合があります。 このようなシナリオでは、API と Power Automate の一方または両方を使用できます。 プログラムによる更新については、API のドキュメントと PowerShell スクリプトを参照してください。 コードを記述せずにこの手順を実行できるようにする Power Automate コネクタがあります。 順次更新に関する特定のチュートリアルと合わせて、詳細なサンプルを確認できます。
監視
この記事で前述した高度な更新統計情報を使用すると、データフローごとの詳細な更新情報を取得できます。 ただし、テナント全体またはワークスペース全体の更新の概要を含めてデータフローを表示する (おそらく監視ダッシュボードを作成する) 場合は、API または Power Automate テンプレートを使用できます。 同様に、単純または複雑な通知の送信などのユース ケースでは、Power Automate コネクタを使うか、API を使って独自のカスタム アプリケーションを作成することができます。
タイムアウト エラー
抽出、変換、読み込み (ETL) のシナリオを実行するためにかかる時間を最適化することが理想的です。 Power BI では、次の状況が当てはまります。
- 一部のコネクタには、構成できる明示的なタイムアウト設定があります。 詳しくは、「Power Query のコネクタ」をご覧ください。
- Power BI Pro を使用する Power BI データフローでは、エンティティまたはデータフロー自体の中で実行時間の長いクエリのタイムアウトが発生することもあります。 その制限は、Power BI Premium ワークスペースにはありません。
タイムアウトに関するガイダンス
Power BI Pro データフローのタイムアウトしきい値は次のとおりです。
- 個々のエンティティのレベルで 2 時間。
- データフロー全体のレベルで 3 時間。
たとえば、3 つのテーブルを含むデータフローがある場合、各テーブルに 2 時間を超える時間がかかることはなく、継続時間が 3 時間を超えると、データフロー全体がタイムアウトになります。
タイムアウトが発生している場合は、データフロー クエリを最適化することを検討し、ソース システムでクエリ フォールディングを使用することを検討してください。
これとは別に、Premium Per User にアップグレードすることを検討してください。これには、これらのタイムアウトは適用されず、多くの Power BI Premium Per User の機能のおかげでパフォーマンスが向上します。
長い継続時間
複雑であるか、大規模なデータフローは、最適化が不十分なデータフローのように、更新に時間がかかることがあります。 次のセクションでは、長い更新時間を軽減する方法について説明します。
長い更新時間に関するガイダンス
データフローの長い更新時間を改善するための最初のステップは、ベスト プラクティスに従ってデータフローを構築することです。 重要なパターンは次のとおりです。
- 後で他の変換において使用できるデータに、リンクされたエンティティを使います。
- 計算されたエンティティを使用してデータをキャッシュし、ソース システムでのデータの読み込みとデータ インジェストの負荷を減らします。
- データをステージング データフローと変換データフローに分割し、ETL を別々のデータフローに分離します。
- テーブル拡張操作を最適化します。
- 複雑なデータフローに関するガイダンスに従います。
次に、これは、増分更新を使用できるかどうかを評価するために役立てることができます。
増分更新を使用すると、パフォーマンスを向上させることができます。 更新操作のためにクエリが送信されるときに、パーティション フィルターがソース システムにプッシュされることが重要です。 フィルタリングをプッシュ ダウンすることは、データ ソースでクエリ フォールディングがサポートされている必要があることを意味します。または、Power Query によるファイルまたはフォルダーの除外やフィルター処理に役立つビジネス ロジックを、関数またはその他の方法を使用して表現できます。 SQL クエリをサポートするほとんどのデータ ソースでは、クエリ フォールディングがサポートされており、一部の OData フィードではフィルタリングもサポートされています。
ただし、フラット ファイル、BLOB、API などのデータ ソースでは通常、フィルタリングはサポートされていません。 データ ソース バックエンドがフィルターをサポートしていない場合は、プッシュダウンできません。 そのような場合、フィルターはマッシュアップ エンジンによってローカルで補正および適用されます。これには、データ ソースから完全なセマンティック モデルを取得することが必要な場合があります。 この操作により、増分更新が低速になり、Power BI サービスまたはオンプレミスのデータ ゲートウェイ (使用されている場合) でプロセスがリソース不足になる可能性があります。
各データ ソースでさまざまなレベルのクエリ フォールディングがサポートされている場合は、検証を実行して、ソースのクエリにフィルター ロジックが含まれていることを確認する必要があります。 これを簡単にするために、Power BI では、Power Query Online のステップ フォールディング インジケーターを使用して、この検証の実行が試行されます。 これらの最適化の多くは設計時に行われますが、更新が行われた後、更新のパフォーマンスを分析して最適化する機会があります。
最後に、環境を最適化することを検討します。 次の最適化を行って、容量のスケール アップ、データ ゲートウェイの適切なサイズ設定、ネットワーク待機時間の短縮を行うことで、Power BI 環境を最適化できます。
Power BI Premium または Premium Per User で使用可能な容量を使用する場合は、Premium インスタンスを増やすか、その中身を別の容量に割り当てることで、パフォーマンスを向上させることができます。
インターネット経由で直接利用できないデータに Power BI がアクセスする必要がある場合は、必ずゲートウェイが必要です。 オンプレミスのサーバーまたは仮想マシンにオンプレミス データ ゲートウェイをインストールできます。
- ゲートウェイのワークロードとサイズ設定の推奨事項について理解するには、「オンプレミス データ ゲートウェイのサイズ設定」をご覧ください。
- また、データを最初にステージング データフローに取り込むことと、リンクおよび計算されたエンティティを使用して下流で参照することも評価します。
ネットワーク待機時間は、要求が Power BI サービスに到達するまでに要する時間と、応答の配信に要する時間が増えることで、更新のパフォーマンスに影響を及ぼす可能性があります。 Power BI のテナントは、特定のリージョンに割り当てられています。 テナントの場所を確認するには、「組織の既定のリージョンを確認する」をご覧ください。 テナントのユーザーが Power BI サービスにアクセスすると、彼らの要求は常にそのリージョンにルーティングされます。 要求が Power BI サービスに到達したときに、サービスから追加の要求が送信されることがあります (たとえば、基になるデータ ソースやデータ ゲートウェイに対して)。これもネットワーク待機時間の影響を受けます。
- Azure Speed Test などのツールによって、クライアントと Azure リージョン間のネットワーク待機時間の表示が提供されます。 一般に、ネットワーク待機時間の影響を最小限に抑えるには、データ ソース、ゲートウェイ、および Power BI クラスターをできるだけ近くに配置するようにします。 同じリージョンに置くことをお勧めします。 ネットワーク待機時間が問題になっている場合は、ゲートウェイとデータ ソースをクラウドでホストされる仮想マシン内に配置することで、Power BI クラスターにより近い位置に配置してみてください。
長いプロセッサ時間
プロセッサ時間が長い場合は、コストのかかる変換がフォールディングされていない可能性があります。 長いプロセッサ時間の原因は、適用されているステップの数または行っている変換の種類です。 どちらの場合も、更新時間が長くなる可能性があります。
長いプロセッサ時間に関するガイダンス
長いプロセッサ時間を最適化するための 2 つのオプションがあります。
まず、データ ソース自体の中でクエリ フォールディングを使用します。これにより、データフロー コンピューティング エンジンの負荷が直接軽減されます。 データ ソース内でのクエリ フォールディングにより、ソース システムでほとんどの作業を実行できます。 その場合、データフローは、最初のクエリの後にメモリ内ですべての計算を実行する必要がなく、ソースのネイティブ言語でクエリをパス スルーできます。
すべてのデータ ソースでクエリ フォールディングを実行できるわけではありません。また、クエリ フォールディングが可能な場合でも、ソースにフォールドできない特定の変換を実行するデータフローが存在する可能性があります。 このような場合、Power BI によって導入された拡張コンピューティング エンジン機能を使うと、特に変換のパフォーマンスが場合によっては最大 25 倍に向上する可能性があります。
コンピューティング エンジンを使用してパフォーマンスを最大限に高める
Power Query では、設計時にクエリ フォールディングが表示されますが、コンピューティング エンジンの列には、内部エンジン自体が使用されているかどうかの詳細が表示されます。 コンピューティング エンジンは、複雑なデータフローが存在し、メモリ内で変換を実行している場合に便利です。 このような状況では、エンジン自体が使われたかどうかの詳細がコンピューティング エンジンの列に表示されるので、高度な更新統計情報が役立つ可能性があります。
以降のセクションでは、コンピューティング エンジンとその統計情報の使用に関するガイダンスを提供します。
警告
デザイン時に、エディターのフォールディング インジケーターで、別のデータフローからのデータを使用するときにクエリでフォールディングが行われないことが示される場合があります。 拡張コンピューティングが有効になっている場合はソース データフローを確認し、ソース データフローの折りたたみが有効になっていることを確認します。
コンピューティング エンジンの状態に関するガイダンス
拡張コンピューティング エンジンをオンにし、さまざまな状態を理解すると、役に立ちます。 内部的には、拡張コンピューティング エンジンは SQL データベースを使ってデータの読み取りと格納を行います。 ここでクエリ エンジンに対して変換を実行することをお勧めします。 以下の段落では、さまざまな状況と、それぞれの場合にすべきことについてのガイダンスを示します。
NA - この状態は、次のいずれかの理由でコンピューティング エンジンが使われなかったことを意味します。
- Power BI Pro のデータフローを使っています。
- コンピューティング エンジンを明示的にオフにしました。
- データ ソースでクエリ フォールディングを使っています。
- クエリの高速化に使われる SQL エンジンを使用できない複雑な変換を実行しています。
継続時間が長いのに状態が [NA] である場合は、オンになっていて、誤ってオフになっていないことを確認してください。 推奨されるパターンの 1 つは、ステージング データフローを使って最初にデータを Power BI サービスに取リ込み、それがステージング データフローに入った後、このデータを基にしてデータフローを構築することです。 このパターンにより、ソース システムの負荷が軽減され、コンピューティング エンジンと共に、変換の速度を上げ、パフォーマンスを向上させることができます。
キャッシュ済み - キャッシュ済みの状態が表示される場合、データフロー データはコンピューティング エンジンに格納されたので、別のクエリの一部として参照できます。 この状況は、リンクされたエンティティとしてそれを使っている場合に理想的です。これは、コンピューティング エンジンによってダウンストリームで使用するためにそのデータがキャッシュされるためです。 キャッシュされたデータを同じデータフローで複数回更新する必要はありません。 この状況は、DirectQuery にそれを使用する場合にも最適である可能性があります。
キャッシュされた場合、初期インジェストでのパフォーマンスの影響は、後で同じデータフローまたは同じワークスペース内の異なるデータフローで良い結果をもたらします。
エンティティの継続時間が長い場合は、コンピューティング エンジンをオフにすることを検討します。 Power BI は、エンティティをキャッシュするために、ストレージおよび SQL に書き込みます。 単一使用エンティティの場合、ユーザーにとってのパフォーマンス上の利点は、二重インジェストのデメリットに見合わない可能性があります。
フォールディング済み - フォールディング済みは、データフローでデータの読み込みに SQL コンピューティングを使用できたことを意味します。 計算されたエンティティは SQL のテーブルを使用してデータを読み取ったので、使用された SQL はクエリの構造に関連付けられています。
折りたたみ済み状態が表示されるのは、オンプレミスまたはクラウドのデータ ソースを使用しているときに、最初にデータをステージング データフローに読み込んで、このデータフローで参照した場合です。 この状態は、別のエンティティを参照するエンティティにのみ適用されます。 これは、クエリが SQL エンジンの上で実行されたことを意味し、SQL コンピューティングを使用すると改善される可能性があります。 変換が SQL エンジンによって処理されるようにするには、クエリ エディターでマージ (結合)、グループ化 (集計)、追加 (和集合) アクションなど、SQL フォールディングをサポートする変換を使用します。
キャッシュ済み + フォールディング済み - キャッシュ済み + フォールディング済みが表示される場合は、別のエンティティを参照し、かつ別のエンティティの上流によって参照されているエンティティがあるため、データ更新が最適化されている可能性があります。 この操作は、SQL の上でも実行されます。そのため、SQL コンピューティングを使用すると、改善される可能性もあります。 実現可能である最適なパフォーマンスが得られるようにするには、クエリ エディターでマージ (結合)、グループ化 (集計)、追加 (和集合) アクションなど、SQL フォールディングをサポートする変換を使用します。
コンピューティング エンジンのパフォーマンスの最適化に関するガイダンス
次の手順では、ワークロードでコンピューティング エンジンをトリガーできるため、常にパフォーマンスが向上します。
計算されたエンティティとリンクされたエンティティが同じワークスペース内にある場合:
インジェストに関しては、セマンティック モデル全体のサイズを小さくする場合にのみフィルターを使用して、できるだけ早くストレージにデータを取り込むことに注目します。 変換ロジックはこの手順とは別に保持します。 次に、変換とビジネス ロジックを、同じワークスペース内の別のデータフローに分けます。 リンクまたは計算されたエンティティを使います。 このようにすると、エンジンは計算をアクティブ化して高速化できます。 簡単な例えでは、厨房での食品の準備のようなものです。通常、食品の準備は素材を集めることとは異なる別の手順であり、食品をオーブンに入れるための前提条件となります。 同様に、コンピューティング エンジンを利用する前に、ロジックを個別に準備する必要があります。
フォールドする操作 (結合、結合、変換、およびその他の操作など) を確実に実行してください。
また、公開されているガイドラインと制限事項の範囲内でデータフローを構築します。
コンピューティング エンジンはオンになっているがパフォーマンスが低下している場合:
コンピューティング エンジンがオンになっていても、パフォーマンスの低下が見られるシナリオについて調べる場合は、次の手順を行います。
- ワークスペース全体に存在する計算されたエンティティおよびリンクされたエンティティを制限します。
- コンピューティング エンジンをオンにして最初の更新を行うと、データはレイクとキャッシュの "両方" に書き込まれます。 この二重書き込みにより、更新が遅くなります。
- 複数のデータフローにリンクされているデータフローがある場合は、すべての更新が同時に行われないように、必ずソース データフローの更新をスケジューリングしてください。
考慮事項と制限事項
Power BI Pro ライセンスでは、データフローの更新は 1 日あたり 8 回に制限されます。