Power Query を使用するときのベスト プラクティス
この記事には、Power Query のデータ ラングリング エクスペリエンスを最も効果的に利用するためのヒントとテクニックが含まれます。
適切なコネクタを選択する
Power Query には多数のデータ コネクタが用意されています。 これらのコネクタの範囲は、TXT、CSV、Excel ファイルなどのデータ ソースから、Microsoft SQL Server のようなデータベース、さらには Microsoft Dynamics 365 や Salesforce といった一般的な SaaS サービスにまで及びます。 [データの取得] ウィンドウの一覧に必要なデータ ソースが表示されていない場合は、常に ODBC または OLEDB コネクタを使ってデータ ソースに接続できます。
タスクに最適なコネクタを使う、最適なエクスペリエンスとパフォーマンスが提供されます。 たとえば、SQL Server データベースに接続するときに ODBC コネクタの代わりに SQL Server コネクタを使用すると、[データの取得] のエクスペリエンスが大幅に向上するだけでなく、クエリ フォールディングなどのエクスペリエンスとパフォーマンスを向上できる機能も提供されます。 クエリ フォールディングの詳細については、「Power Query でのクエリ評価とクエリ フォールディングの概要」を参照してください。
各データ コネクタは、「データの取得」で説明されている標準的なエクスペリエンスに従います。 この標準化されたエクスペリエンスには、[データのプレビュー] というステージがあります。 このステージで提供されているユーザー フレンドリなウィンドウを使用すると、データ ソースから取得するデータを選び (コネクタで許可されている場合)、そのデータの簡単なデータ プレビューを見ることができます。 次の図に示すように、[ナビゲーター] ウィンドウを使って、データ ソースから複数のデータ セットを選ぶこともできます。
![[ナビゲーター] ウィンドウの例。](media/best-practices-power-query/navigator.png)
Note
Power Query で使用可能なコネクタの完全な一覧については、「Power Query のコネクタ」を参照してください。
フィルター処理を早期に行う
クエリの初期のステージまたは可能な限り早い段階でデータをフィルター処理することが、常に推奨されます。 「Power Query でのクエリ評価とクエリ フォールディングの概要」で説明されているように、一部のコネクタはクエリ フォールディングでフィルターを利用します。 また、処理に関係のないデータをフィルターで除外するのもベスト プラクティスです。 これにより、データ プレビュー セクションに関連のあるデータのみを表示することで、目の前のタスクに集中できます。
列で見つかった個別の値の一覧を表示する自動フィルター メニューを使用して、保持または除外する値を選べます。検索バーを使って、列内の値を検索することもできます。
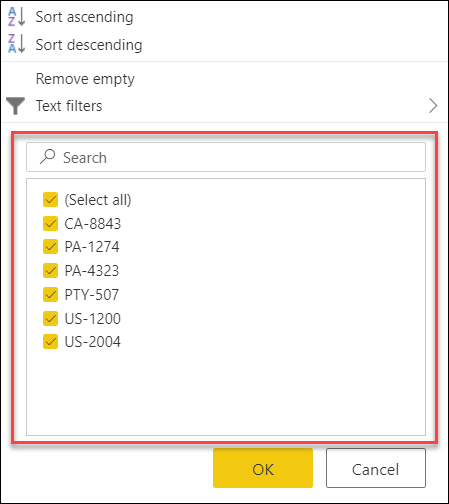
日付、日時、または日付タイムゾーン列の場合の [前の] のような、型固有のフィルターを利用することもできます。
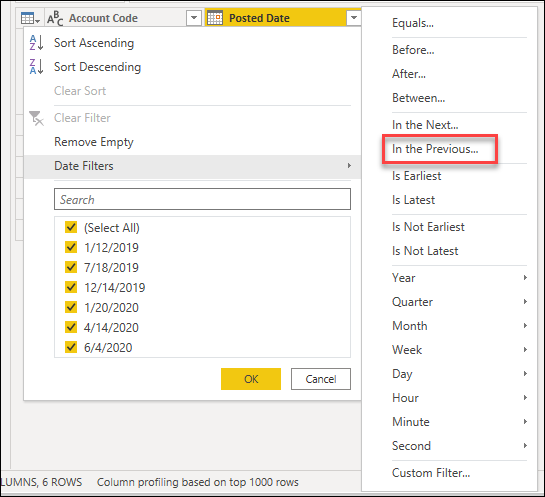
次の図に示すように、これらの型固有のフィルターを使用すると、前の x 秒、分、時間、日、週、月、四半期、または年のデータを常に取得する動的フィルターを作成するのに役立ちます。
![[前の] 日付固有フィルター。](media/best-practices-power-query/is-in-the-previous.png)
Note
列の値に基づいてデータをフィルター処理する方法の詳細については、「値によるフィルター処理」を参照してください。
負荷が大きい操作を最後に行う
操作の中には、何らかの 結果を返すためには完全なデータ ソースを読み取ることが必要なため、Power Query エディターでのプレビューが遅くなるものがあります。 たとえば、並べ替えを実行する場合、並べ替えると最初の方になる行が、ソース データの末尾にある可能性があります。 そのため、並べ替え操作では、何らかの結果を返すためには、最初に すべての 行を読み取る必要があります。
その他の操作 (フィルターなど) では、何らかの結果を返す前に、すべてのデータを読み取る必要はありません。 代わりに、"ストリーミング" と呼ばれる方法でデータを操作します。 データが "流れている" 途中で、結果が返されます。 Power Query エディターの場合、そのような操作では、プレビューを生成するのに十分なソース データだけを読み取る必要があります。
可能であれば、最初にそのようなストリーミング操作を実行し、さらに負荷のかかる操作を最後に実行します。 このようにすると、クエリに新しいステップを追加するたびに、プレビューがレンダリングされるのを待つ時間を、最小限に抑えるのに役立ちます。
データのサブセットを一時的に処理する
Power Query エディターでクエリに新しいステップを追加する処理が遅い場合は、最初に "最初の行を保持する" 操作を実行し、処理する行の数を制限します。 その後、必要なすべてのステップを追加したら、"最初の行を保持する" ステップを削除します。
正しいデータ型を使用する
Power Query の一部の機能は、選ばれている列のデータ型に依存します。 たとえば、日付列を選ぶと、[列の追加] メニューの [日時列] グループのオプションを使用できるようになります。 ただし、列にデータ型が設定されていない場合、これらのオプションはグレー表示されます。
![[列の追加] メニューの型固有のオプション。](media/best-practices-power-query/type-specific-filter-for-date.png)
型固有のフィルターも、特定のデータ型に固有なので、同様の状況が発生します。 列に正しいデータ型が定義されていない場合、これらの型固有のフィルターは使用できません。
列の正しいデータ型を常に使用することが重要です。 データベースなどの構造化データ ソースを処理するときは、データ型の情報は、データベース内のテーブル スキーマから取得されます。 一方、TXT や CSV ファイルなどの非構造化データ ソースの場合は、そのデータ ソースから取得する列に対して正しいデータ型を設定することが重要です。 Power Query では、非構造化データ ソースの自動データ型検出が既定で提供されます。 この機能の詳細と、それがどのように役立つかについては、データ型に関するページをご覧ください。
Note
データ型の重要性とその処理方法について詳しくは、データ型に関するページをご覧ください。
データを調査する
データの準備と新しい変換ステップの追加を始める前に、データに関する情報を簡単に検出できるように Power Query のデータ プロファイル ツールを有効にすることをおすすめします。
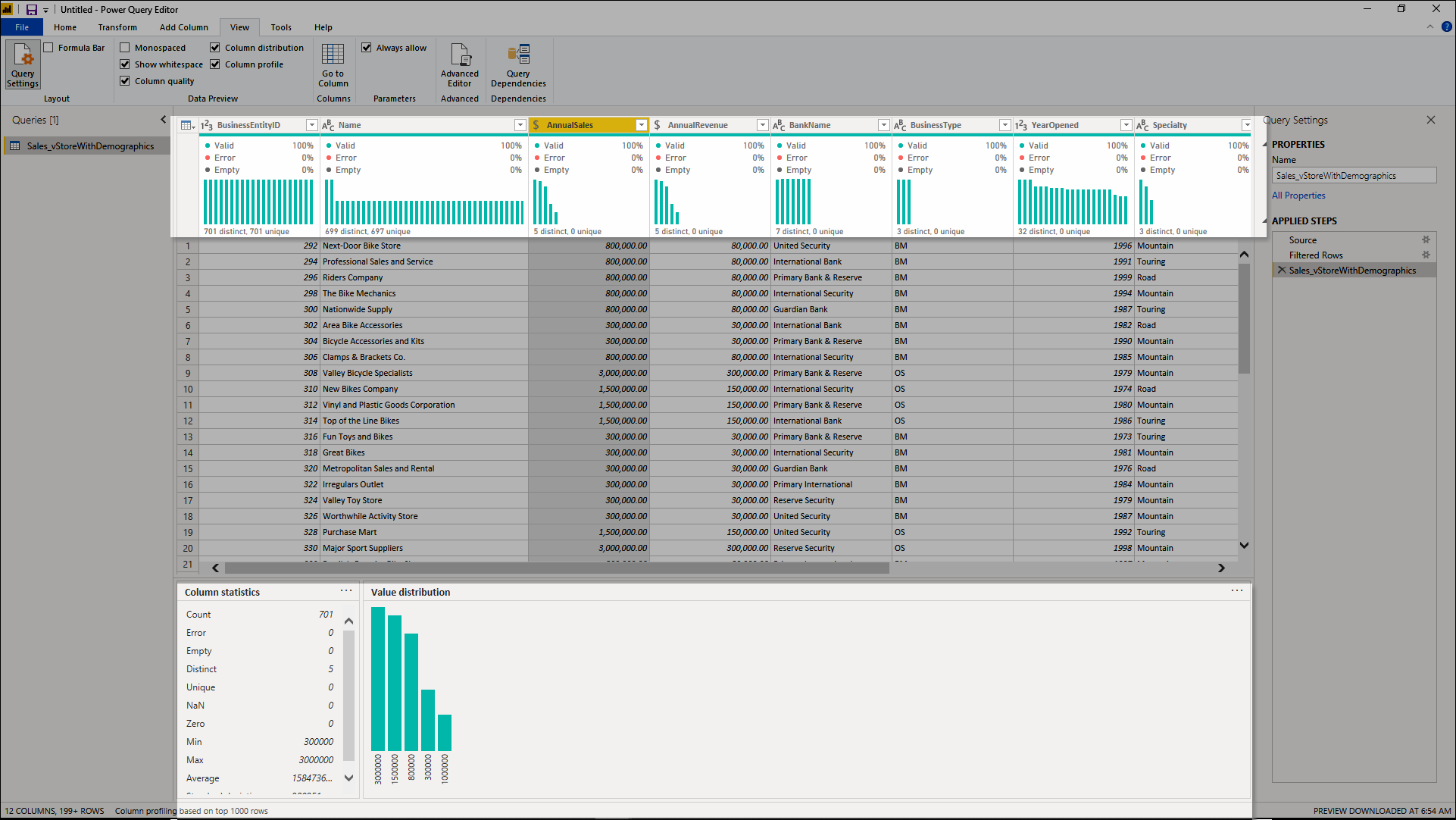
これらのデータ プロファイル ツールは、データをよりよく理解するのに役立ちます。 ツールを使用すると、列ごとに次のような情報を示す小さな視覚エフェクトが表示されます。
- 列の品質 - 小さい棒グラフと 3 つのインジケーターで、有効、エラー、または空の値のカテゴリに該当する列の値の数が示されます。
- 列の分布 - 各列の値の頻度と分布を示す一連のビジュアルが、列の名前の下に表示されます。
- 列プロファイル - 列および列に関連付けられている統計情報の詳細なビューが提供されます。
これらの機能は対話形式で操作することもでき、データの準備に役立ちます。
Note
データ プロファイリング ツールの詳細については、「データ プロファイリング ツール」を参照してください。
作業を文書化する
必要に応じて、ステップ、クエリ、グループの名前を変更するか、説明を追加して、クエリを文書化することをお勧めします。
Power Query の [適用したステップ] ペインではステップの名前が自動的に作成されますが、ステップの名前を変更したり、説明を追加したりすることもできます。
![ステップが文書化されて説明が追加された [適用したステップ] ペイン。](media/best-practices-power-query/documenting.png)
Note
[適用したステップ] ペイン内のすべての使用可能な機能とコンポーネントの詳細については、「適用したステップ リストを使用する」を参照してください。
モジュール方式のアプローチを採用する
必要になる可能性のあるすべての変換と計算を含む 1 つのクエリを作成することは可能です。 しかし、クエリに多数のステップが含まれている場合は、クエリを複数のクエリに分割し、個々のクエリで次のクエリを参照すると便利な場合があります。 このアプローチの目的は、変換フェーズをより小さな部分に単純化して切り離し、理解しやすくすることです。
たとえば、次の図に示すような 9 つのステップを含むクエリがあるとします。
このクエリは、Merge with Prices table ステップで 2 つに分割できます。 そうすることで、マージの前に販売クエリに適用されるステップを理解しやすくなります。 この操作を行うには、Merge with Prices table ステップを右クリックし、[前を抽出] オプションを選びます。
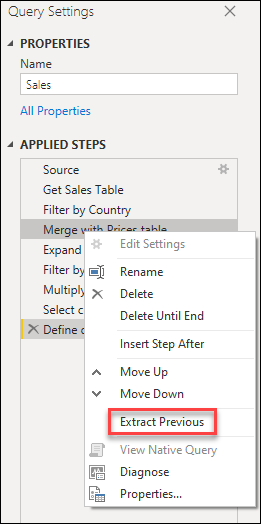
その後、新しいクエリの名前を指定するダイアログが表示されます。 これにより、クエリが実質的に 2 つのクエリに分割されます。 1 つのクエリには、マージの前のすべてのクエリが含まれます。 もう 1 つのクエリには、新しいクエリを参照する最初のステップと、元のクエリの Merge with Prices table ステップ以降にあった残りのステップが含まれます。
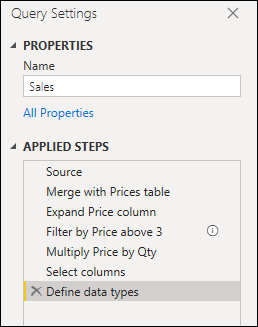
また、必要に応じてクエリ参照の使用を利用することもできます。 ただし、ステップが多いために一見して困難と感じるようなことがないレベルに、クエリを維持することをお勧めします。
Note
クエリ参照の詳細については、「クエリ ペインについて」を参照してください。
グループを作成する
作業の整理された状態を維持する最適な方法は、[クエリ] ペインでグループを使用することです。
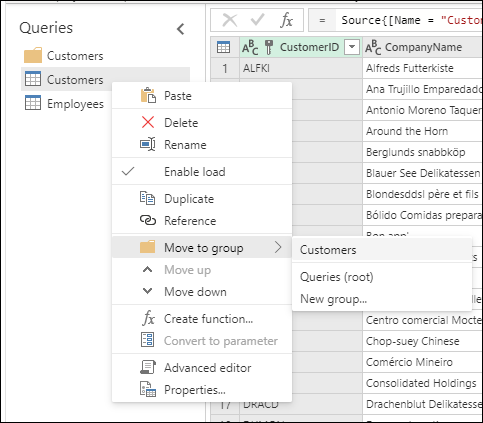
グループの唯一の目的は、クエリのフォルダーとして機能することで作業を整理しておくことです。 必要に応じて、グループ内にグループを作成できます。 ドラッグ アンド ドロップにより、グループ間でクエリを簡単に移動できます。
自分や状況に意味のあるわかりやすい名前をグループに付けてみてください。
Note
[クエリ] ペイン内のすべての使用可能な機能とコンポーネントの詳細については、「クエリ ペインについて」を参照してください。
長く使用できるクエリ
将来更新されても問題が発生しないクエリを作成することが最優先事項です。 Power Query には、変更に対してクエリの回復性を高め、データ ソースの一部のコンポーネントが変更された場合でも更新できるようにする機能がいくつかあります。
クエリのスコープに関連する構造、レイアウト、列名、データ型、その他のコンポーネントについて、クエリの機能と考慮対象のスコープを定義することがベスト プラクティスです。
変更に対して回復性があるクエリにするために役立つ変換の例を次に示します。
クエリのデータの行数が動的であるときに、フッターとして機能する固定数の行を削除する必要がある場合は、下位の行の削除機能を使用できます。
Note
行の位置でデータをフィルター処理する方法の詳細については、「行の位置でテーブルをフィルター処理する」を参照してください。
クエリの列の数が動的であるときに、データ セットから特定の列だけを選ぶ必要がある場合は、列の選択機能を使用できます。
Note
列の選択または削除の詳細については、「列の選択または削除する」を参照してください。
クエリの列の数が動的であるときに、列のサブセットだけピボットを解除する必要がある場合は、選択した列のみのピボット解除機能を使用できます。
Note
列のピボットを解除するオプションの詳細については、「列のピボットを解除する」を参照してください。
クエリに列のデータ型を変更するステップがあり、一部のセルで値が目的のデータ型に準拠していないためにエラーが発生する場合は、エラー値を生成した行を削除することができます。
Note
エラー処理の詳細については、「エラーへの対処」を参照してください。
パラメーターを使用する
動的で柔軟なクエリを作成することがベスト プラクティスです。 Power Query のパラメーターは、クエリをいっそう動的で柔軟にするのに役立ちます。 パラメーターは、さまざまな方法で再利用できる値を簡単に格納および管理する手段として機能します。 ただし、特に一般的な使用シナリオが 2 つあります。
ステップ引数 - パラメーターは、ユーザー インターフェイスからの複数の変換の引数として使用できます。
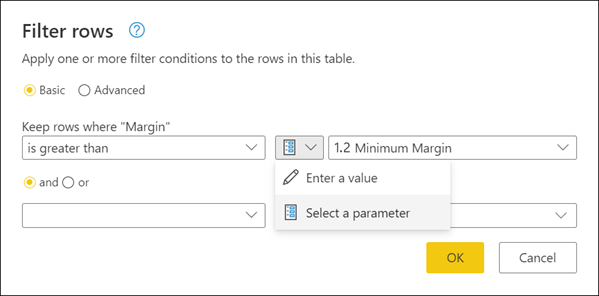
カスタム関数の引数 - クエリから新しい関数を作成し、カスタム関数の引数としてパラメーターを参照できます。
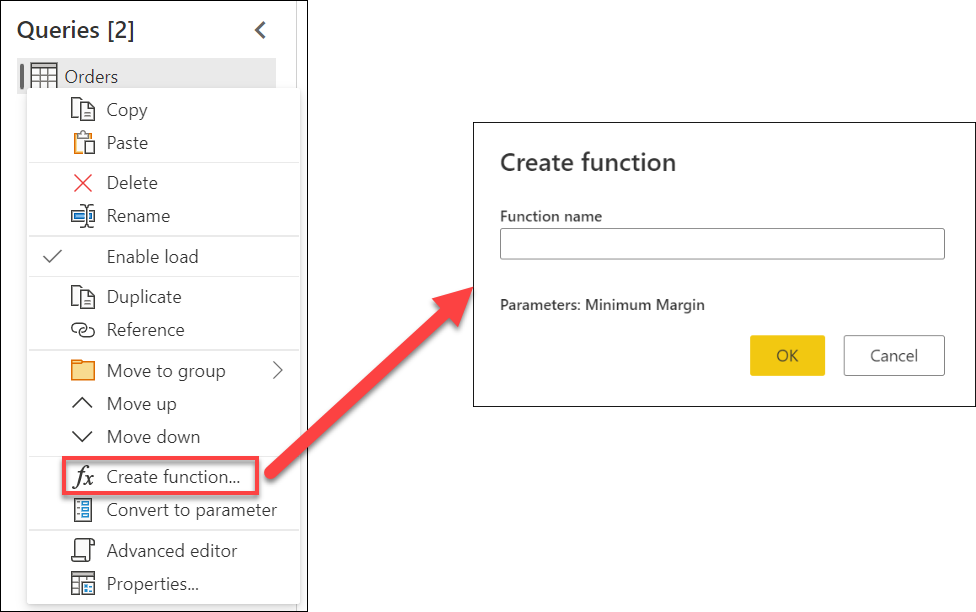
パラメーターを作成して使用する主な利点は次のとおりです。
[パラメーターの管理] ウィンドウによるすべてのパラメーターの一元的な表示。
![[パラメーターの管理] ウィンドウ。](media/best-practices-power-query/parameters-manage-parameters.png)
複数のステップまたはクエリでのパラメーターの再利用性。
カスタム関数の作成をわかりやすく簡単にします。
データ コネクタの引数の一部で、パラメーターを使用することさえできます。 たとえば、SQL Server データベースに接続するときに、サーバー名用のパラメーターを作成できます。 その後、[SQL Server データベース] ダイアログでそのパラメーターを使用できます。
![[SQL Server データベース] ダイアログとサーバー名のパラメーター。](media/best-practices-power-query/sql-server-parameter.png)
サーバーの場所を変更する場合は、サーバー名のパラメーターを更新するだけで、クエリが更新されます。
Note
パラメーターの作成と使用の詳細については、「パラメーターを使用する」を参照してください。
再利用可能な関数を作成する
同じ変換のセットを異なるクエリまたは値に適用する必要がある場合は、必要に応じて何回でも再利用できる Power Query のカスタム関数を作成すると便利です。 Power Query のカスタム関数は、入力値のセットから 1 つの出力値へのマッピングであり、M のネイティブ関数と演算子を使って作成します。
たとえば、同じ変換セットを必要とする複数のクエリまたは値があるとします。 カスタム関数を作成しておき、後で選択したクエリまたは値に対してそれを呼び出すことができます。 このカスタム関数により、時間を節約し、一連の変換を一元的に管理することができ、いつでも変更できます。
Power Query のカスタム関数は、既存のクエリとパラメーターから作成できます。 たとえば、テキスト文字列として複数のコードを含むクエリがあり、それらの値をデコードする関数を作成する必要がある場合を想像してください。
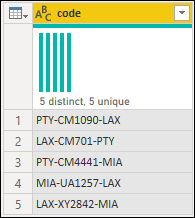
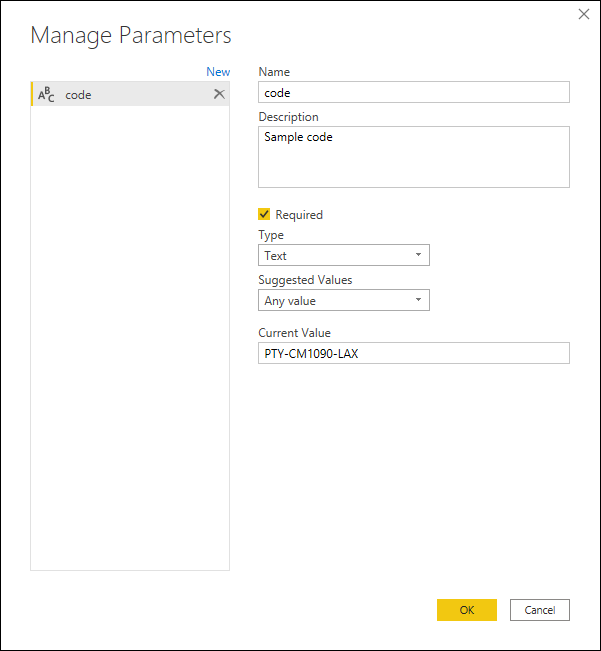
最初に、例として使用できる値を持つパラメーターを作成します。
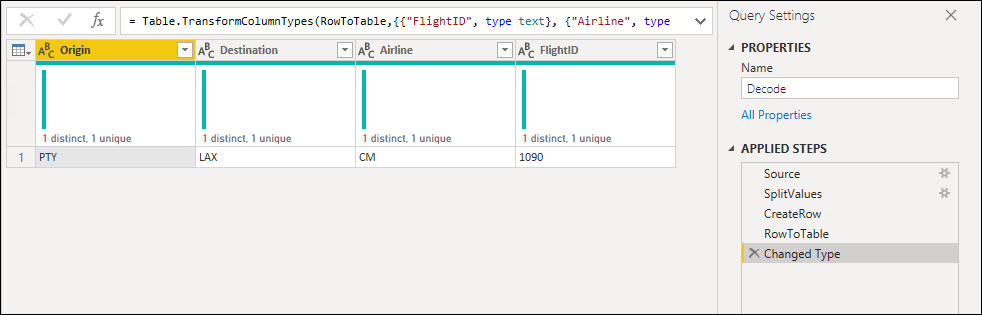
そのパラメーターから、必要な変換を適用する新しいクエリを作成します。 この場合は、コード PTY-CM1090-LAX を複数のコンポーネントに分割する必要があります。
- Origin = PTY
- Destination = LAX
- Airline = CM
- FlightID = 1090
次に、クエリを右クリックして [関数の作成] を選ぶことで、そのクエリを関数に変換できます。 最後に、次の図に示すように、任意のクエリまたは値でカスタム関数を呼び出すことができます。
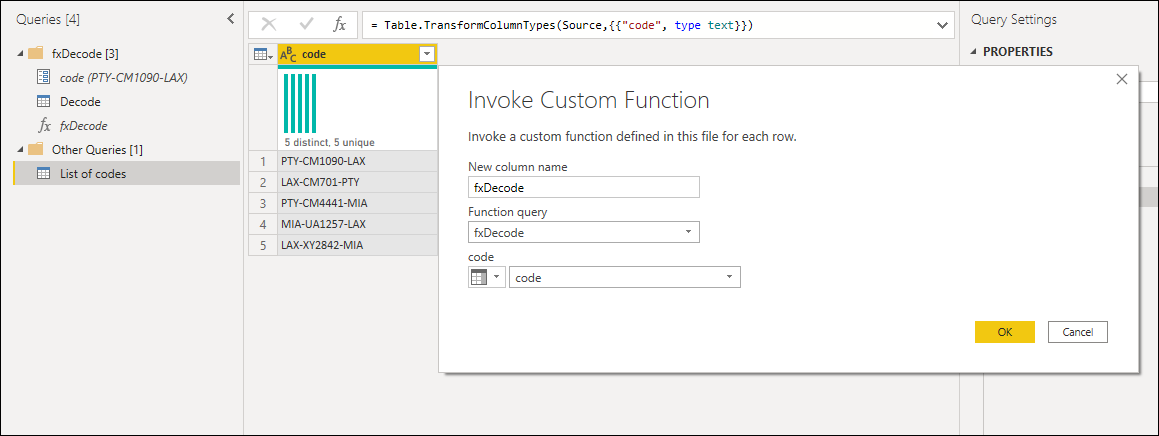
さらにいくつかの変換を行った後、目的の出力が得られ、カスタム関数からのこのような変換のロジックが利用されたことがわかります。

Note
Power Query でカスタム関数を作成して使用する方法について詳しくは、カスタム関数に関するページをご覧ください。