カスタム関数の使用
同じ変換のセットを異なるクエリまたは値に適用する必要がある場合は、必要に応じて何回でも再利用できる Power Query のカスタム関数を作成すると便利です。 Power Query のカスタム関数は、入力値のセットから 1 つの出力値へのマッピングであり、M のネイティブ関数と演算子を使って作成します。
「Power Query M 関数について」で説明されているように、コードを使用して手作業で Power Query の独自のカスタム関数を作成することもできますが、Power Query のユーザー インターフェイスには、カスタム関数を作成および管理するプロセスを高速化、簡素化、拡張する機能が用意されています。
この記事では、Power Query のユーザー インターフェイスでのみ提供されるこのエクスペリエンスに焦点を当て、それを最大限に活用する方法について説明します。
重要
この記事では、Power Query のユーザー インターフェイスでアクセスできる一般的な変換を使用して、カスタム関数を作成する方法について説明します。 カスタム関数を作成するための主要な概念に焦点を当てて説明します。Power Query のドキュメントに含まれる他の記事へのリンクも記載しますので、この記事で取り上げるそれぞれの変換について詳しくは、それらのリンクを参照してください。
テーブル参照からカスタム関数を作成する
Note
次の例は、Power BI Desktop のデスクトップ エクスペリエンスを使用して作成されていますが、Excel for Windows に含まれる Power Query を使用して作成することもできます。
この記事で使用されているサンプル ファイルを次のダウンロード リンクからダウンロードすると、この例に沿って進めることができます。 わかりやすくするために、この記事ではフォルダー コネクタを使用します。 フォルダー コネクタの詳細については、フォルダーを参照してください。 この例の目的は、すべてのファイルのすべてのデータを 1 つのテーブルに結合する前に、そのフォルダー内のすべてのファイルに適用できるカスタム関数を作成することです。
最初に、フォルダー コネクタ エクスペリエンスを使用して、ファイルがあるフォルダーに移動し、[データの変換] または [編集] を選びます。 これらの手順により、Power Query のエクスペリエンスが表示されます。 [コンテンツ] フィールドで任意のバイナリ値を右クリックし、[新しいクエリとして追加] オプションを選びます。 この例では、リストの最初のファイルが選択されています。これは、April 2019.csv ファイルです。

このオプションにより、バイナリとしてそのファイルに直接アクセスするナビゲーション ステップを含む新しいクエリが作成されます。この新しいクエリの名前は、選択したファイルのファイル パスになります。 このクエリの名前を Sample File に変更します。

File Parameter という名前および Binary の種類で、新しいパラメーターを作成します。 既定値および現在の値としてサンプル ファイル クエリを使用します。
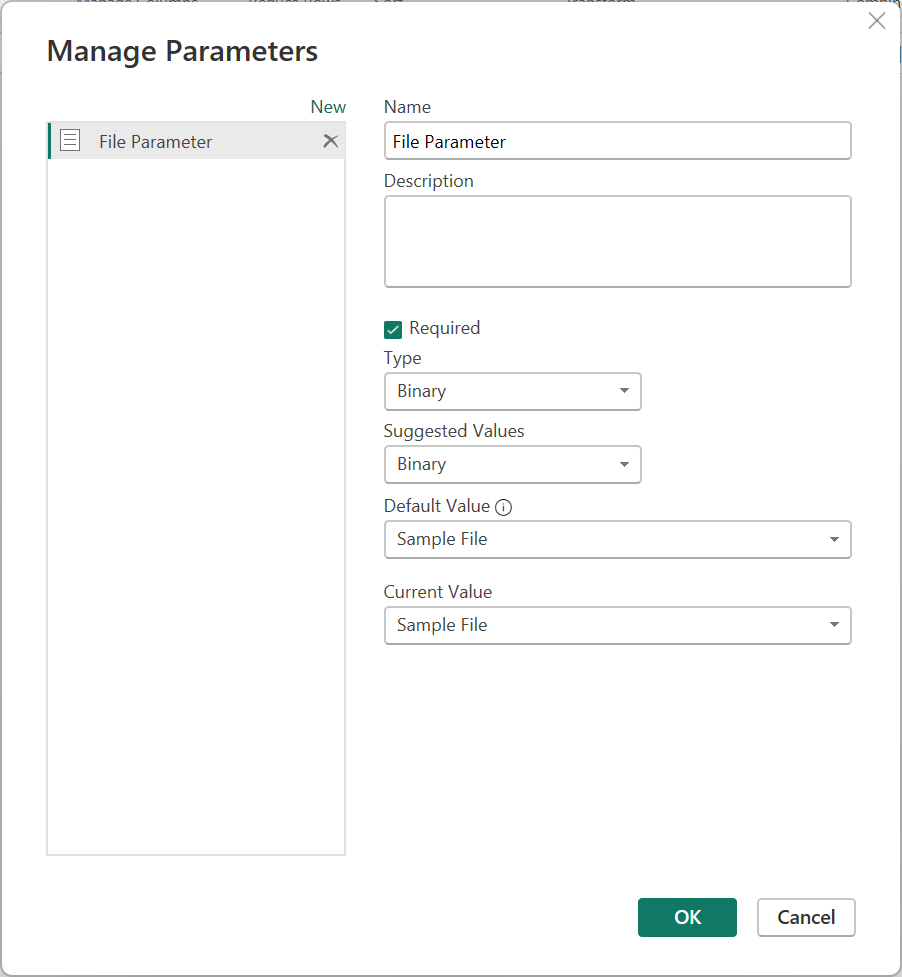
Note
パラメーターに関する記事を読み、Power Query でパラメーターを作成および管理する方法をよく理解することをお勧めします。
カスタム関数は、任意のパラメーター型を使用して作成できます。 カスタム関数にパラメーターとしてバイナリを使用するという要件はありません。
バイナリ パラメーターの種類は、バイナリに評価されるクエリがある場合に限り、パラメーター ダイアログの種類ドロップダウン メニュー内に表示されます。
パラメーターのないカスタム関数を作成することもできます。 これは、関数が呼び出されている環境から入力を推論できるシナリオでよく見られることです。 たとえば、環境の現在の日付と時刻を取得し、それらの値から特定のテキスト文字列を作成する関数などです。
[クエリ] ペインで File Parameter を右クリックします。 [参照] オプションを選びます。
![[ファイル パラメーター] で [参照] オプションが選択されているスクリーンショット。](media/custom-function/reference-file-parameter.png)
新しく作成されたクエリの名前を、File Parameter (2) から Transform Sample file に変更します。

この新しい Transform Sample file クエリを右クリックし、[関数の作成] を選びます。
![Transform Sample file クエリに使用される [関数の作成] オプションのスクリーンショット。](media/custom-function/transform-sample-file-function.png)
この操作により、Transform Sample file クエリにリンクされる新しい関数が効率的に作成されます。 Transform Sample file クエリに行った変更は、カスタム関数に自動的にレプリケートされます。 この新しい関数の作成では、[関数名] として Transform file を使用します。
![Transform file の [関数の作成] ウィンドウのスクリーンショット。](media/custom-function/transform-sample-file-function-window.png)
関数を作成すると、関数の名前で新しいグループが自動的に作成されることがわかります。 この新しいグループには次のものが含まれます。
- Transform Sample file クエリで参照されたすべてのパラメーター。
- 一般に サンプル クエリ と呼ばれる Transform Sample file クエリ。
- 新しく作成された関数 (この場合は Transform file)。
![[クエリ] ペインの関数グループのスクリーンショット。](media/custom-function/custom-function-group.png)
サンプル クエリへの変換の適用
新しい関数が作成されたら、Transform Sample file という名前のクエリを選びます。 このクエリは Transform file 関数とリンクされているため、このクエリに行った変更は関数に反映されます。 この接続は、関数にリンクされたサンプル クエリの概念として知られています。
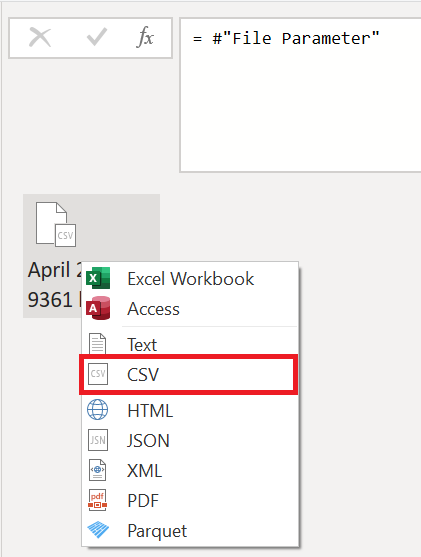
このクエリで最初に行う必要がある変換は、バイナリを解釈することです。 プレビュー ウィンドウでバイナリを右クリックし、[CSV] オプションを選んで、バイナリを CSV ファイルとして解釈することができます。
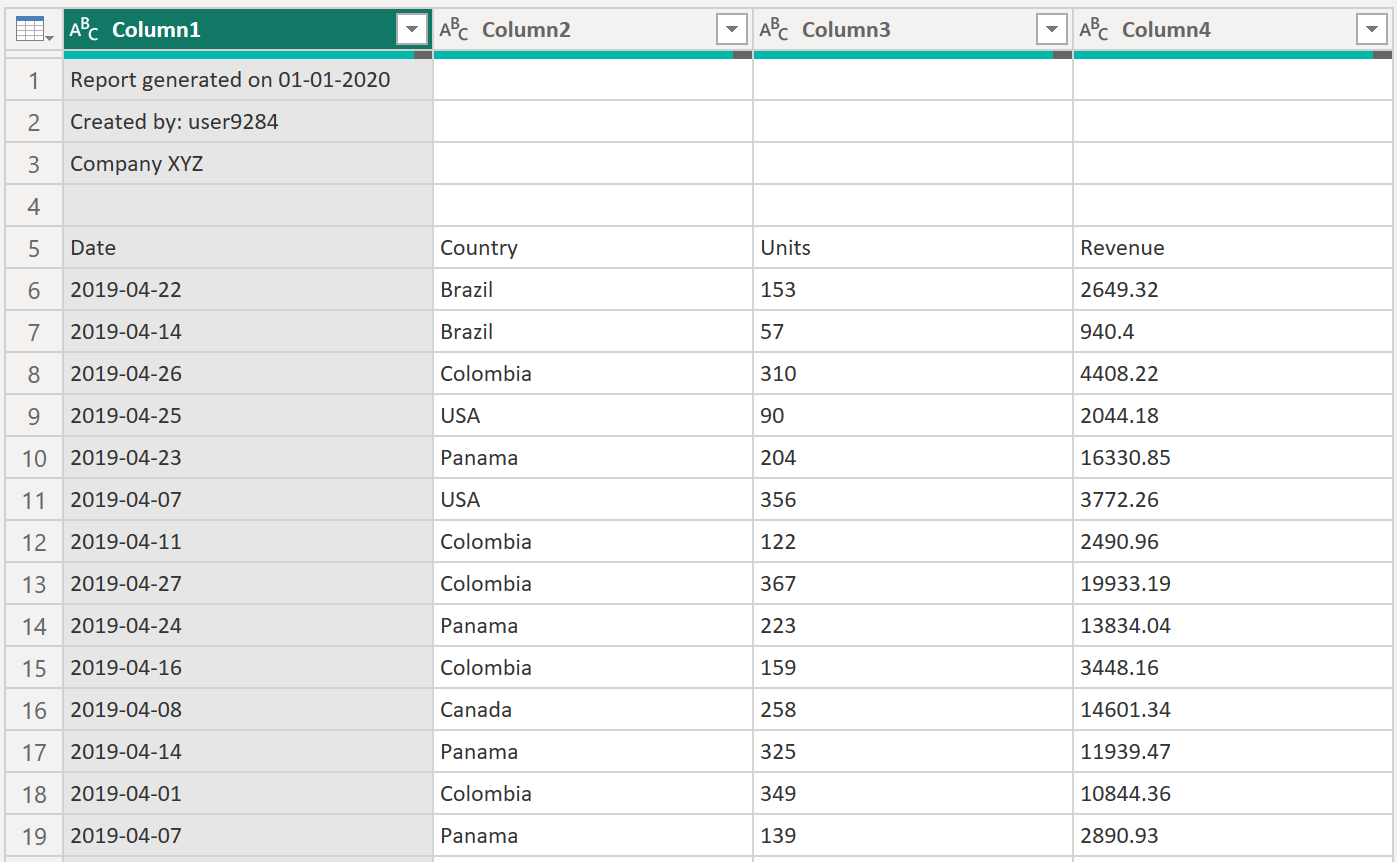
フォルダー内のすべての CSV ファイルの形式は同じです。 すべてに、先頭の 4 行にまたがるヘッダーがあります。 次の図に示すように、5 行目には列ヘッダーがあり、6 行目以降がデータです。
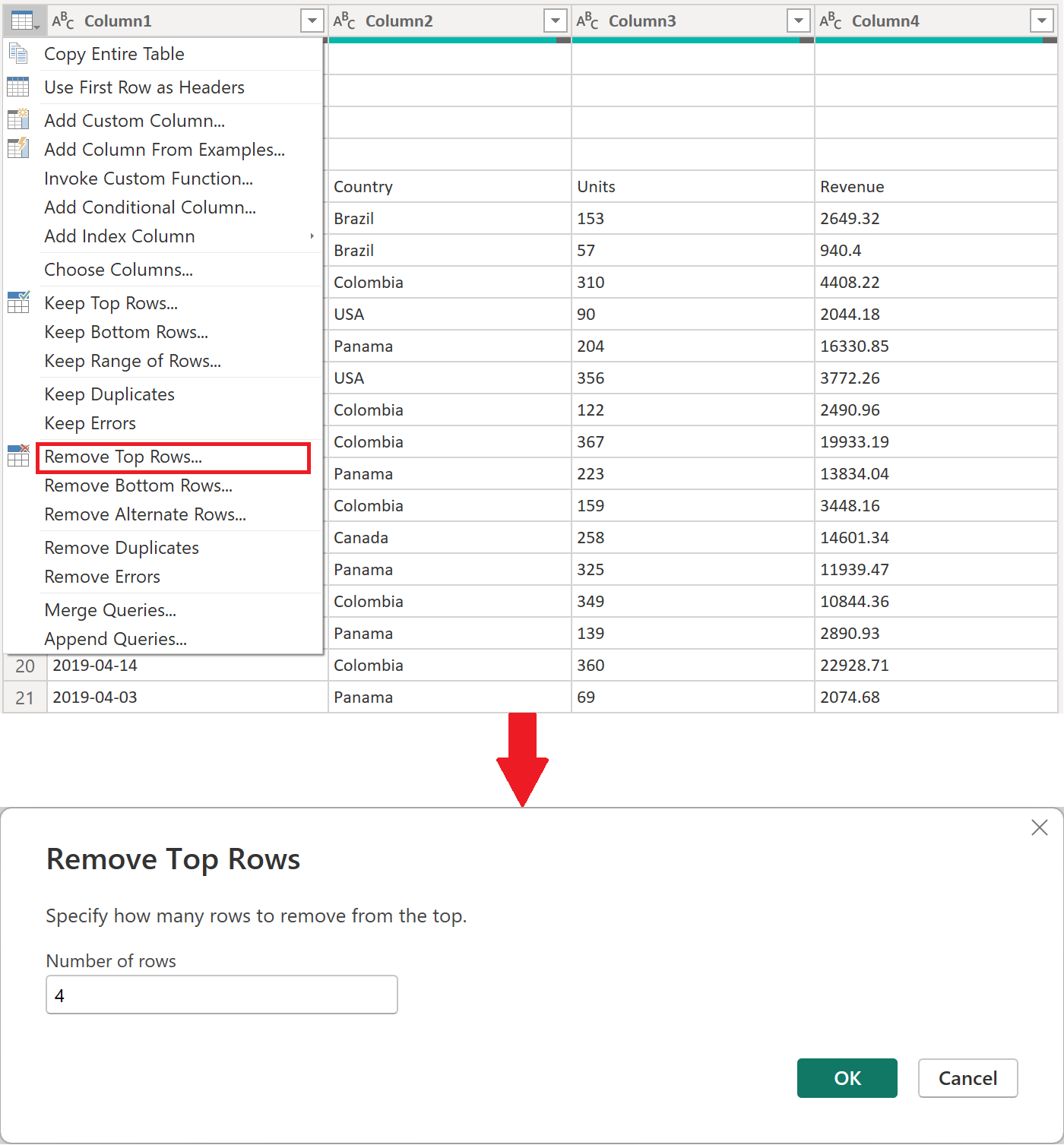
Transform Sample file に適用する必要がある次の変換ステップのセットは、以下のようなものです。
先頭の 4 行を削除する—この操作により、ファイルのヘッダー セクションの一部と見なされる行が除去されます。
Note
行を削除する方法や、行の位置でテーブルをフィルター処理する方法の詳細については、行の位置でテーブルをフィルター処理するを参照してください。
ヘッダーのレベル上げ—テーブルの 1 行目が最終的なテーブルのヘッダーになります。 次の図に示すように、これらを昇格させることができます。
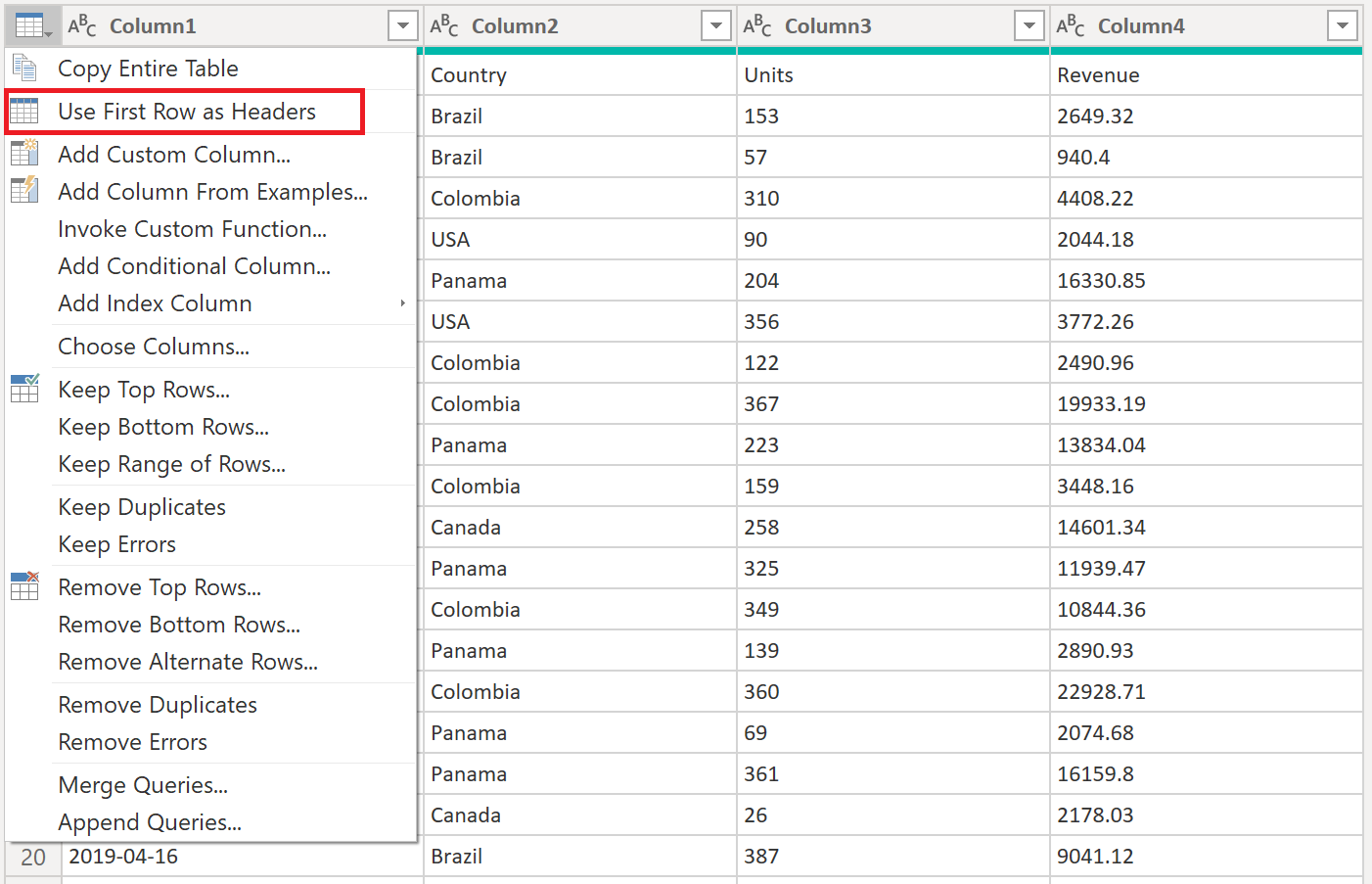
列ヘッダーの昇格の後に、Power Query によって既定で新しい [変更された型] ステップが自動的に追加され、各列のデータ型が自動的に検出されます。 Transform Sample file クエリは次の画像のようになります。
Note
ヘッダーのレベルを上げ下げする方法の詳細については、列ヘッダーのレベル上げ/下げを参照してください。

注意事項
Transform file 関数は、Transform Sample file クエリで実行される手順に依存します。 ただし、Transform file 関数のコードを手動で変更しようとすると、次のような警告が表示されます: The definition of the function 'Transform file' is updated whenever query 'Transform Sample file' is updated. However, updates will stop if you directly modify function 'Transform file'.
カスタム関数を新しい列として呼び出す
カスタム関数が作成され、すべての変換手順が組み込まれたので、フォルダーのファイル (この例では CSV ファイル) の一覧がある元のクエリに戻ることができます。 リボンの [列の追加] タブで、[全般] グループから [カスタム関数の呼び出し] を選びます。 [カスタム関数の呼び出し] ウィンドウで、[新しい列名] として「Output Table」と入力します。 [関数クエリ] ドロップダウンから、関数の名前 Transform file を選びます。 ドロップダウン メニューから関数を選ぶと、関数のパラメーターが表示され、この関数の引数として使用する列をテーブルから選ぶことができます。 File Parameter に渡す値または引数として、[コンテンツ] 列を選びます。
![[カスタム関数の呼び出し] ダイアログ セットの設定が強調された [カスタム関数の呼び出し] ボタンのスクリーンショット。](media/custom-function/custom-invoke-custom-function.png)
[OK] を選ぶと、Output Table という名前の新しい列が作成されます。 次の図に示すように、この列のセルの値は Table です。 単純にするため、[名前] と [Output Table] を除くすべての列をこのテーブルから削除します。
![カスタム関数が呼び出され、[名前] 列および [Output Table] 列のみが残っているスクリーンショット。](media/custom-function/custom-invoked-custom-function.png#lightbox)
Note
テーブルの列を選択または削除する方法の詳細については、列を選択または削除するを参照してください。
[コンテンツ] 列の値を関数の引数として使用して、テーブルのすべての行に関数が適用されました。 探している図形にデータが変換されたので、[展開] アイコンを 選択して [Output Table] 列を展開できます。 展開された列にはプレフィックスを使用しないでください。
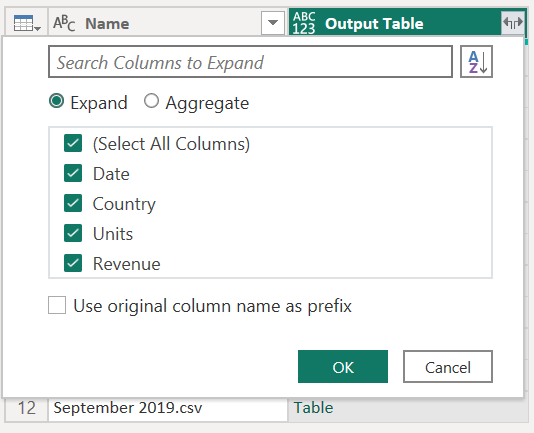
[名前] 列または [日付] 列の値を調べることで、フォルダー内のすべてのファイルのデータがあることを確認できます。 この場合、各ファイルには特定の年の 1 か月のデータのみが含まれているため、[日付] 列の値を確認できます。 複数のファイルが表示されている場合は、複数のファイルのデータが 1 つのテーブルに正常に結合されていることを意味します。

Note
これまでに説明してきたことは、基本的に [ファイルの結合] エクスペリエンスで行われるプロセスと同じですが、手動で行っています。
「ファイルの結合の概要」 と「CSV ファイルを結合する」の記事も読んで、Power Query でのファイルの結合エクスペリエンスのしくみと、カスタム関数が果たす役割についてさらに理解しておくことをお勧めします。
既存のカスタム関数に新しいパラメーターを追加する
現在作成しているものに加えて新しい要件があるものとします。 新しい要件では、ファイルを結合する前に、ファイル内のデータをフィルター処理して、Country が Panama と等しい行のみを取得する必要があります。
この要件を実現するには、テキスト データ型で Market という名前の新しいパラメーターを作成します。 [現在の値] として、「Panama」と入力します。
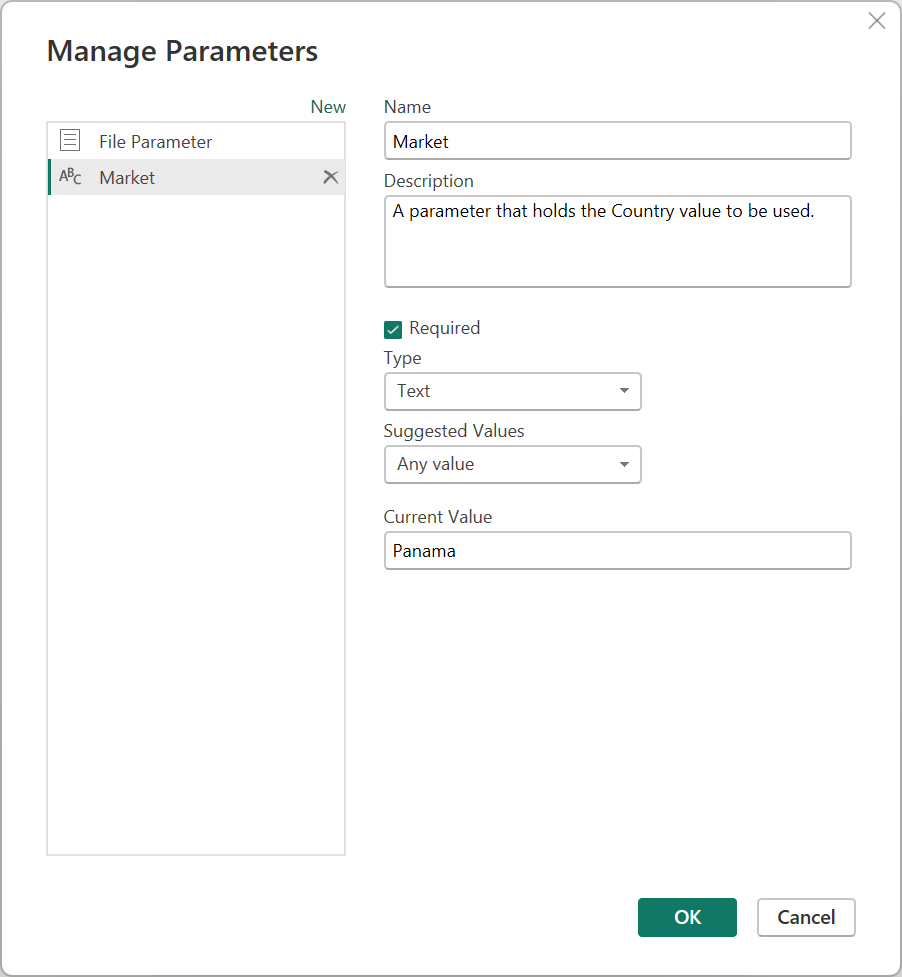
この新しいパラメーターを使用して、Transform Sample file クエリを選び、Market パラメーターの値を使用して Country フィールドをフィルター処理します。
![新しい Market パラメーターを使用した [Country 列をフィルター処理] を含むフィルター行ダイアログのスクリーンショット。](media/custom-function/filter-using-second-parameter.png)
Note
値で列をフィルター処理する方法の詳細については、値のフィルター処理を参照してください。
この新しいステップをクエリに適用すると、Transform file 関数が自動的に更新されて、Transform Sample file で使用される 2 つのパラメーターに基づく 2 つのパラメーターが必要になります。

ただし、CSV ファイルのクエリの横には警告記号があります。 関数が更新されたので、2 つのパラメーターが必要です。 したがって、関数を呼び出す [呼び出されたカスタム関数] ステップで、Transform file 関数に引数が 1 つしか渡されていないため、エラー値が返されます。

エラーを修正するには、[適用したステップ] で [呼び出されたカスタム関数] をダブルクリックして、[カスタム関数の呼び出し] ウィンドウを開きます。 Market パラメーターに、値「Panama」を手動で入力します。
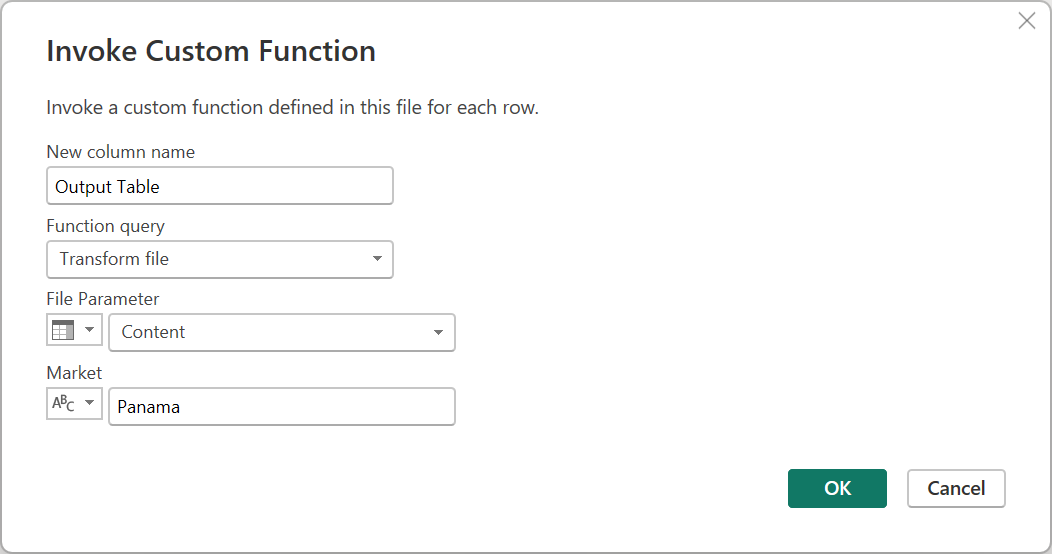
これで、適用されたステップの展開された出力テーブルに戻ることができます。 クエリをチェックして、Country が Panama と等しい行だけが CSV ファイル クエリの最終的な結果セットに表示されることを確認します。

再利用可能なロジックからカスタム関数を作成する
同じ変換セットを必要とする複数のクエリまたは値がある場合は、再利用可能なロジックとして機能するカスタム関数を作成できます。 後で、選択したクエリまたは値に対して、このカスタム関数を呼び出すことができます。 このカスタム関数により、時間を節約し、一連の変換を一元的に管理することができ、いつでも変更できます。
たとえば、次のサンプル テーブルのようにテキスト文字列として複数のコードを含むクエリがあり、それらの値をデコードする関数を作成する必要がある場合を想像してください。
| code |
|---|
| PTY-CM1090-LAX |
| LAX-CM701-PTY |
| PTY-CM4441-MIA |
| MIA-UA1257-LAX |
| LAX-XY2842-MIA |
最初に、例として使用できる値を持つパラメーターを作成します。 この場合は、値 PTY-CM1090-LAX を使用します。
![サンプル パラメーター コード値が入力された [パラメーターの管理] ダイアログのスクリーンショット。](media/custom-function/sample-parameter-code.png)
そのパラメーターから、必要な変換を適用する新しいクエリを作成します。 この場合は、コード PTY-CM1090-LAX を複数のコンポーネントに分割する必要があります。
- Origin = PTY
- Destination = LAX
- Airline = CM
- FlightID = 1090

次の M コードは、その一連の変換を示しています。
let
Source = code,
SplitValues = Text.Split( Source, "-"),
CreateRow = [Origin= SplitValues{0}, Destination= SplitValues{2}, Airline=Text.Start( SplitValues{1},2), FlightID= Text.End( SplitValues{1}, Text.Length( SplitValues{1} ) - 2) ],
RowToTable = Table.FromRecords( { CreateRow } ),
#"Changed Type" = Table.TransformColumnTypes(RowToTable,{{"Origin", type text}, {"Destination", type text}, {"Airline", type text}, {"FlightID", type text}})
in
#"Changed Type"
Note
Power Query M 式言語の詳細については、Power Query M式言語を参照してください。
次に、クエリを右クリックして [関数の作成] を選ぶことで、そのクエリを関数に変換できます。 最後に、次の図に示すように、任意のクエリまたは値でカスタム関数を呼び出すことができます。
![[カスタム関数の呼び出し] の値が入力されているコードの一覧のスクリーンショット。](media/custom-function/invoke-custom-function.png#lightbox)
さらにいくつかの変換を行った後、目的の出力が得られ、カスタム関数からのこのような変換のロジックが適用されたことがわかります。
