スレッドおよびタスクのアーキテクチャ ガイド
適用対象: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
オペレーティング システムのタスクのスケジューリング
スレッドは、オペレーティング システムによって実行される処理の最小単位であり、アプリケーションのロジックを複数の同時実行パスに分離することができます。 スレッドは、複雑なアプリケーションに同時に実行できるタスクが多数ある場合に役立ちます。
オペレーティング システムがアプリケーションのインスタンスを実行するときは、プロセスという単位が作成され、インスタンスを管理します。 プロセスには実行のためのスレッドが 1 つあります。 これは、アプリケーション コードで実行される一連のプログラミング命令です。 たとえば、順番に実行できる 1 つの命令セットで構成される単純なアプリケーションの場合、その命令セットは単一のタスクとして処理され、実行パス (つまりスレッド) はアプリケーション全体で 1 つあるだけです。 より複雑なアプリケーションの場合は、順次ではなく、同時に実行できる複数のタスクで構成されていることがあります。 アプリケーションでは、リソースの消費量が多い操作であるタスクごとに個別のプロセスを開始するか、リソースの消費量が比較的少ない個別のスレッドを開始することによって、これを行うことができます。 また、各スレッドは、プロセスに関連付けられた他のスレッドに依存することなく、その実行スケジュールを設定できます。
プロセッサ (CPU) が 1 つしかないコンピューターであっても、スレッドにより、複雑なアプリケーションで CPU をより効率的に使用できるようになります。 CPU が 1 基の場合、一度に実行できるスレッドは 1 つだけです。 あるスレッドが、ディスクの読み書きなど、CPU を使用しない処理を長時間にわたって実行している場合、この処理が終了するまで他のスレッドを実行できます。 処理の終了を待っている間に他のスレッドを実行できるようにすることで、アプリケーションは CPU を最大限に使用できます。 データベース サーバーなど、ディスク I/O が多発するマルチユーザー アプリケーションの場合、特にそのことが当てはまります。 複数の CPU を備えるコンピューターでは、各 CPU で 1 つのスレッドを同時に実行できます。 たとえば、CPU を 8 基搭載したコンピューターは同時に 8 個のスレッドを実行できます。
SQL Server のタスクのスケジューリング
SQL Server のスコープでは、要求がクエリまたはバッチの論理表現になります。 また、要求では、チェックポイントやログ ライターなどのシステム スレッドに必要な操作も表されます。 要求は有効期間を通してさまざまな状態になり、要求の実行に必要なリソースを使用できないときは待機できます (ロックまたはラッチなど)。 要求の状態の詳細については、「sys.dm_exec_requests」を参照してください。
タスク
タスクは、要求を満たすために完了する必要がある作業の単位を表します。 1 つの要求に 1 つまたは複数のタスクを割り当てることができます。
- 並列要求には、順次ではなく同時に実行される複数のアクティブなタスクがあります (1 つの親タスク (または調整タスク) と複数の子タスクから成る)。 並列要求の実行プランには、プランの直列分岐 (並列で実行されない演算子を持つプランの領域) が含まれている場合があります。 親タスクもそれらの順次演算子を実行します。
- 順次要求では、実行時の特定の時点でアクティブなタスクが 1 つだけ存在します。 タスクは、有効期間全体を通してさまざまな状態になります。 タスクの状態の詳細については、「sys.dm_os_tasks」を参照してください。 SUSPENDED 状態のタスクは、タスクの実行に必要なリソースが使用可能になるのを待機しています。 待機中のタスクの詳細については、「sys.dm_os_waiting_tasks」を参照してください。
作業者
SQL Server のワーカー スレッド (ワーカーまたはスレッドとも呼ばれます) は、オペレーティング システムのスレッドを論理的に表現したものです。 順次要求を実行すると、SQL Server データベース エンジンによってワーカーが生成されて、アクティブなタスクが実行されます (1:1)。 行モードで並列要求を実行すると、SQL Server データベース エンジンによってワーカーが割り当てられ、ワーカーに割り当てられたタスクを実行する子ワーカーが調整されます (この場合も 1:1)。これは親スレッド (または調整スレッド) とも呼ばれます。 親スレッドには、関連付けられている親タスクがあります。 親スレッドとは、エンジンがクエリを解析する前から存在している要求のエントリ ポイントです。 親スレッドの主な役割は次のとおりです。
- 並列スキャンを調整します。
- 並列子ワーカーを開始します。
- 並列スレッドから行を収集し、クライアントに送信します。
- ローカル集計とグローバル集計を実行します。
Note
クエリ プランに直列分岐と並列分岐がある場合、並列タスクの 1 つが直列分岐の実行を担当します。
各タスクに対して生成されるワーカー スレッドの数は、以下に依存します。
クエリ オプティマイザーによって決定された並列処理に対して要求が適格であったかどうか。
現在の負荷に基づいてシステムで実際に使用可能な並列処理の次数 (DOP)。 これは、並列処理の最大限度 (MAXDOP) のサーバー構成に基づく推定 DOP とは異なる場合があります。 たとえば、MAXDOP のサーバー構成が 8 であっても、実行時に使用可能な DOP は 2 しかないことがあり、クエリのパフォーマンスに影響します。 メモリ負荷およびワーカーの不足は、実行時に使用可能な DOP が減る 2 つの条件です。
Note
並列処理の最大限度 (MAXDOP) の制限は、要求ごとではなく、タスクごとに設定されます。 つまり、並列クエリの実行の間に、1 つの要求で複数のタスクを MAXDOP の上限まで生成します。各タスクは 1 つのワーカーを使用します。 MAXDOP の詳細については、「max degree of parallelism サーバー構成オプションの構成」を参照してください。
スケジューラ
スケジューラ (SOS スケジューラとも呼ばれます) では、タスクに代わって作業を実行するために処理時間を必要とするワーカー スレッドが管理されます。 各スケジューラは、個々のプロセッサ (CPU) にマップされます。 ワーカーがスケジューラでアクティブな状態を維持できる時間は、OS クォンタムと呼ばれ、最大 4 ミリ秒です。 クォンタム時間が経過したワーカーは、CPU リソースへのアクセスを必要とする他のワーカーに時間を明け渡し、その状態を変更します。 CPU リソースへのアクセスを最大化するためのワーカー間のこのような連携は、協調スケジューリング (または非プリエンプティブ スケジューリング) と呼ばれます。 その後、ワーカーの状態の変化は、そのワーカーに関連付けられたタスクと、タスクに関連付けられた要求に伝達されます。 ワーカーの状態の詳細については、「sys.dm_os_workers」を参照してください。 スケジューラの詳細については、「sys.dm_os_schedulers」を参照してください。
要約すると、要求によって、作業単位を実行するための 1 つ以上のタスクが生成される場合があります。 各タスクは、タスクを実行するワーカー スレッドに割り当てられます。 タスクをアクティブに実行するために、各ワーカー スレッドをスケジュールする (スケジューラに配置する) 必要があります。
以下のシナリオについて考えてみます。
- ワーカー 1 は長時間実行のタスクです。たとえば、ディスク ベース テーブルで先行読み取りを利用する読み取りクエリです。 ワーカー 1 は、必要なデータ ページがバッファー プールに既にあることを見つけます。そのため、I/O 操作を待つ目的で一時停止する必要があります。一時停止前にそのクォンタムを完全に使用できます。
- ワーカー 2 はミリ秒未満の短時間タスクを行います。そのため、そのクォンタムが完全に使用される前に一時停止する必要があります。
このシナリオおよび SQL Server 2014 (12.x) までは、ワーカー 1 には、全体的クォンタム時間を増やすことで、基本的にスケジューラーを独占することが許可されます。
SQL Server 2016 (13.x) 以降、共同作業スケジューリングには、Large Deficit First (LDF) スケジューリングが含まれます。 LDF スケジューリングにより、クォンタム使用パターンが監視されており、1 つのワーカー スレッドでスケジューラーが独占されることがありません。 同じシナリオで、ワーカー 2 には、ワーカー 1 にクォンタムを増やすことが許可される前に、クォンタムを繰り返し使用することが許可されます。そのため、ワーカー 1 では、好ましくないパターンでスケジューラーを独占することができません。
並列タスクのスケジューリング
SQL Server が MaxDOP 8 で構成され、CPU アフィニティが NUMA ノード 0 と 1 で 24 個の CPU (スケジューラ) 用に構成されているとします。 スケジューラ 0 から 11 は NUMA ノード 0 に属しており、スケジューラ 12 から 23 は NUMA ノード 1 に属しています。 アプリケーションは、次のクエリ (要求) をデータベース エンジンに送信します。
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
ヒント
AdventureWorks2016_EXT サンプル データベースを使用して、この例のクエリを実行できます。 テーブル Sales.SalesOrderHeader および Sales.SalesOrderDetail が 50 回拡大され、Sales.SalesOrderHeaderBulk と Sales.SalesOrderDetailBulk に名前が変更されました。
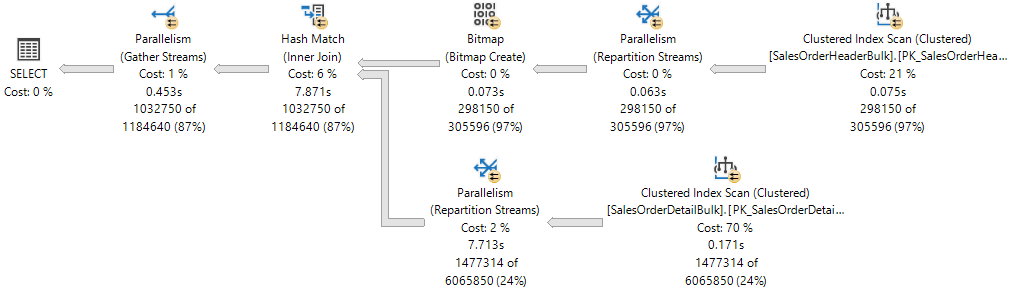
実行プランには、2 つのテーブル間のハッシュ結合と、並列で実行される各演算子 (黄色の円で囲まれた 2 つの矢印で示されています) が示されています。 それぞれの並列処理演算子は、プラン内で別個の分岐になります。 したがって、次の実行プランには 3 つの分岐があります。
Note
実行プランがツリーとして考えられる場合、分岐は、並列処理演算子 (交換反復子とも呼ばれます) の間にある 1 つ以上の演算子をグループ化するプランの領域になります。 プランの演算子の詳細については、「プラン表示の論理操作と物理操作のリファレンス」を参照してください。
実行プランには 3 つの分岐がありますが、実行中の任意の時点で、この実行プランで同時に実行できる分岐は 2 つだけです。
Sales.SalesOrderHeaderBulkでクラスター化インデックス スキャンが使用される分岐 (結合のビルド入力) は、単独で実行されます。- その後、クラスター化インデックス スキャンが
Sales.SalesOrderDetailBulk(結合のプローブ入力) で使用される分岐は、ビットマップが作成され、Hash Match が同時に実行される分岐と同時に実行されます。
次のプラン表示 XML では、16 個のワーカー スレッドが予約され、NUMA ノード 0 で使用されています。
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
スレッド予約により、要求に必要なすべてのタスクを実行するのに十分なワーカー スレッドをデータベース エンジンで確保できます。 スレッドは、数個の NUMA ノードで予約できます。また、1 つの NUMA ノードのみで予約することもできます。 スレッド予約は、実行が開始される前にランタイムで行われ、スケジューラの負荷に依存します。 予約されるワーカー スレッドの数は、concurrent branches * runtime DOP の式で算出され、親ワーカー スレッドは除外されます。 各分岐は、MaxDOP と同じ数のワーカー スレッドに制限されます。 この例では、2 つの同時分岐と MaxDOP が 8 に設定されているため 2 * 8 = 16 となります。
参考までに、「ライブ クエリ統計」のライブ実行プランをご覧ください。ここでは、1 つの分岐が実行された後に、2 つの分岐が同時に実行されています。
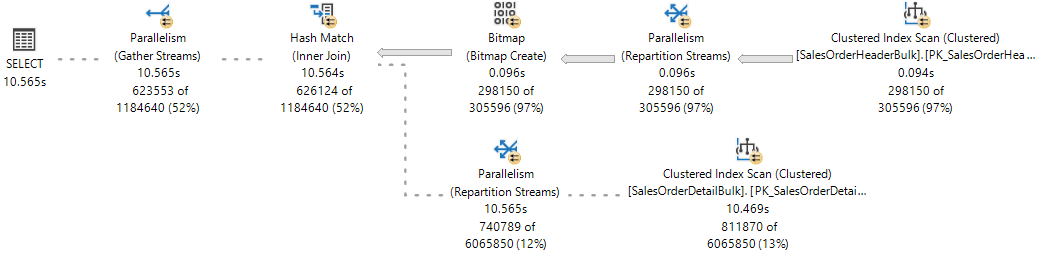
SQL Server データベース エンジンは、アクティブなタスクを実行するためにワーカー スレッドを割り当てます (1:1)。これは、次の例に示すように、sys.dm_os_tasks DMV に対してクエリを実行することで、クエリの実行中に確認できます。
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
ヒント
親タスクの場合、列 parent_task_address は常に NULL になります。
ヒント
非常にビジーな SQL Server データベース エンジンでは、予約されたスレッドによって設定された制限を超えて、アクティブなタスクが多数表示される可能性があります。 これらのタスクは、使用されなくなっていて、過渡的な状態にあり、クリーンアップされるのを待っている分岐に属する場合があります。
結果セットは次のとおりです。 現在実行中のブランチには、17 個のアクティブなタスクがあります。予約済みスレッドに対応する 16 個の子タスクと、親タスクまたは調整タスクです。
| parent_task_address | task_address | task_state | scheduler_id | worker_address |
|---|---|---|---|---|
| NULL | 0x000001EF4758ACA8 |
SUSPENDED | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SUSPENDED | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SUSPENDED | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SUSPENDED | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SUSPENDED | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SUSPENDED | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SUSPENDED | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SUSPENDED | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SUSPENDED | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SUSPENDED | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SUSPENDED | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SUSPENDED | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SUSPENDED | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SUSPENDED | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SUSPENDED | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SUSPENDED | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SUSPENDED | 11 | 0x000001EF6BD72160 |
16 個の子タスクのそれぞれに異なるワーカー スレッドが割り当てられているものの (worker_address 列に表示)、すべてのワーカーが 8 つのスケジューラ (0、5、6、7、8、9、10、11) の同じプールに割り当てられている点に注目してください。また、親タスクはこのプール以外のスケジューラ (3) に割り当てられています。
重要
ある分岐の並列タスクの最初のセットがスケジュールされた後、データベース エンジンは、他の分岐のその他のタスクにもスケジューラのその同じプールを使用します。 これは、実行プラン全体のすべての並列タスクで同じセットのスケジューラが使用されることを意味します。これは MaxDOP によってのみ制限されます。
SQL Server データベース エンジンでは、タスクの実行に常に同じ NUMA ノードからスケジューラを割り当てようとし、スケジューラが利用可能な場合はそれらを (ラウンドロビン方式で) 順番に割り当てます。 ただし、親タスクに割り当てられたワーカー スレッドは、他のタスクとは異なる NUMA ノードに配置される場合があります。
ワーカー スレッドは、スケジューラでクォンタムの期間 (4 ミリ秒) だけアクティブにしておくことができます。また、別のタスクに割り当てられたワーカー スレッドがアクティブになる可能性があるため、そのクォンタムが経過した後にスケジューラを生成する必要があります。 ワーカーのクォンタムの有効期限が切れ、アクティブでなくなった場合、RUNNABLE 状態になるまで、各タスクは RUNNING 状態の FIFO キューに配置されます。これは、ラッチやロックなど、その時点では利用できないリソースへのアクセスをタスクが必要としないことを想定しています。そのような場合、それらのリソースが利用可能になるまで、タスクが RUNNABLE ではなく SUSPENDED の状態になります。
ヒント
上に示した DMV の出力では、すべてのアクティブなタスクが SUSPENDED 状態になっています。 待機中のタスクの詳細を確認するには、sys. dm_os_waiting_tasks DMV に対してクエリを実行してください。
要約すると、並列要求では複数のタスクが生成されます。 各タスクは、単一のワーカー スレッドに割り当てられる必要があります。 各ワーカー スレッドは、単一のスケジューラに割り当てられる必要があります。 そのため、使用中のスケジューラの数は、分岐ごとの並列タスクの数を超えることはできません。この数は、MaxDOP 構成、または MaxDOP クエリ ヒントによって設定されます。 調整スレッドは、MaxDOP の制限に寄与しません。
CPU へのスレッドの割り当て
既定では、SQL Server の各インスタンスによってそれぞれのスレッドが開始され、SQL Server のインスタンスのスレッドは、オペレーティング システムにより、負荷に基づいてコンピューターのプロセッサ (CPU) 間に分散されます。 処理関係がオペレーティング システム レベルで有効な場合、オペレーティング システムによって各スレッドが特定の CPU に割り当てられます。 これに対し、SQL Server データベース エンジンでは、ラウンドロビン方式で CPU 間にワーカー スレッドを均等に分散するスケジューラにスレッドを割り当てます。
マルチタスク処理を実行するため、たとえば複数のアプリケーションが CPU の同じセットにアクセスするときなど、オペレーティング システムによってワーカー スレッドが異なる CPU に移動される場合があります。 オペレーティング システムにとっては効率的であっても、このアクティビティで各プロセッサのキャッシュに繰り返しデータが再読み込みされるため、システムの負荷が高くなり、SQL Server のパフォーマンスが低下する場合があります。 このような状況では、特定のスレッドに CPU を割り当てると、プロセッサのリロードが回避され、CPU 間でのスレッドの移行が減ることにより (それにより、コンテキストの切り替えが減ります)、パフォーマンスを改善できます。このようなスレッドとプロセッサの間の関連付けは、"プロセッサ アフィニティ" と呼ばれます。 関係 (affinity) が有効な場合、オペレーティング システムにより、各スレッドが特定の CPU に割り当てられます。
affinity mask オプションを設定するには、ALTER SERVER CONFIGURATION を使用します。 affinity mask が設定されていない場合、SQL Server のインスタンスでは、マスク オフに指定されていない複数のスケジューラにワーカー スレッドが均等に割り当てられます。
注意事項
オペレーティング システムでの CPU 関係の構成と、 SQL Serverでの関係マスクの構成は、同時に行わないようにしてください。 この 2 つの設定は、同じ効果をねらったものであり、これらの構成間に一貫性がない場合は、予期しない結果を招く可能性があります。 詳細については、affinity mask オプションに関するページを参照してださい。
スレッド プールは、多数のクライアントがサーバーに接続されている場合のパフォーマンスの最適化に役立ちます。 通常、クエリ要求ごとに個別のオペレーティング システム スレッドが作成されます。 ただし、サーバーへの接続が数百にもなる場合、クエリ要求ごとに 1 つのスレッドを使用すると大量のシステム リソースが消費されることがあります。 max worker threads オプションを使用すると、 SQL Server によってワーカー スレッド プールが作成され多数のクエリ要求を処理できるようになります。その結果、パフォーマンスが向上します。
lightweight pooling オプションの使用
スレッド コンテキストの切り替えにかかわるオーバーヘッドは、それほど大きくない可能性があります。 SQL Server のほとんどのインスタンスでは、lightweight pooling オプションを 0 と 1 のどちらに設定してもパフォーマンスに違いはありません。 SQL Server のインスタンスが lightweight pooling の設定から利点を得る唯一の条件は、次の特性を備えたコンピューター上で実行されることです。
- 大規模なマルチ CPU サーバーを備えている
- すべての CPU がほぼ最大容量で稼動している
- 高いレベルのコンテキスト切り替えが行われている
このようなシステムでは、lightweight pooling 値が 1 に設定されていると、パフォーマンスがわずかに向上することがあります。
重要
ルーチン処理にファイバー モード スケジューリングを使用しないでください。 これは、コンテキストの切り替えがもたらす本来の利点が損なわれることでパフォーマンスが低下する場合があり、ファイバー モードでは SQL Server の一部のコンポーネントが正常に機能しないためです。 詳細については、簡易プーリングに関するページを参照してください。
スレッドとファイバーの実行
Microsoft Windows では、1 から 31 までの優先度の数値に基づいてスレッドの実行がスケジュール設定されます。 ゼロは、オペレーティング システム用に予約されています。 複数のスレッドが実行を待機している場合、最も優先度の高いスレッドから先に実行されます。
既定では、SQL Server の各インスタンスの優先度は 7 です。優先度が 7 のスレッドは、優先度が通常のスレッドと見なされます。 この既定値により、SQL Server スレッドには、他のアプリケーションに悪影響を及ぼさずに十分な CPU リソースを得られるだけの高い優先度が与えられます。
重要
この機能は、 SQL Serverの将来のバージョンで削除される予定です。 新規の開発作業ではこの機能を使用しないようにし、現在この機能を使用しているアプリケーションは修正することを検討してください。
priority boost 構成オプションを使用すると、SQL Server インスタンスのスレッドの優先度を 13 まで上げることができます。 優先度が 13 のスレッドは、優先度が高いスレッドと見なされます。 この設定により、SQL Server スレッドには、他の多数のアプリケーションよりも高い優先度が与えられます。 したがって、通常、SQL Server スレッドは、実行可能な状態になると先に実行され、他のアプリケーションのスレッドからの割り込みを受けることはありません。 サーバーで SQL Server のインスタンスだけが実行されていて他のアプリケーションが実行されていない場合は、この方法でパフォーマンスを向上させることができます。 ただし、SQL Server でメモリを集中的に消費する操作が発生した場合は、SQL Server スレッドに割り込みをかけるのに十分な優先度が他のアプリケーションに与えられない可能性が高くなります。
コンピューターで SQL Server の複数のインスタンスを実行していて、一部のインスタンスのみに対して priority boost を有効にしている場合、通常の優先度で実行されているすべてのインスタンスのパフォーマンスに悪影響を及ぼすことがあります。 また、priority boost が有効になっていると、サーバー上の他のアプリケーションやコンポーネントのパフォーマンスが低下することがあります。 したがって、このオプションは厳密に管理された条件下でのみ使用することをお勧めします。
ホット アド CPU
ホット アド CPU とは、実行中のシステムに CPU を動的に追加する機能です。 CPU の追加は、物理的には新しいハードウェアの追加、論理的にはオンライン ハードウェア パーティション分割、仮想的には仮想化レイヤーの利用によって行われます。 SQL Server では、ホット アド CPU がサポートされています。
ホット アド CPU の要件
- ホット アド CPU をサポートするハードウェアが必要です。
- サポートされているバージョンの Windows Server Datacenter または Enterprise Edition が必要です。 Windows Server 2012 以降では、Standard エディションでホット アドがサポートされています。
- SQL Server Enterprise Edition の要否
- SQL Server はソフト NUMA を使用するように構成することはできません。 ソフト NUMA の詳細については、「 ソフト NUMA (SQL Server)」を参照してください。
CPU を追加しても、SQL Server で自動的にその CPU が使用されることはありません。 これにより、別の目的で追加した CPU が SQL Server で使用されるのを防ぐことができます。 CPU の追加後に RECONFIGURE ステートメントを実行して、SQL Server が新しい CPU を使用可能なリソースとして認識するようにします。
Note
affinity64 mask が構成されている場合、新しい CPU を使用するように affinity64 mask を変更する必要があります。
64 基を超える CPU を搭載したコンピューター上で SQL Server を実行する場合のベスト プラクティス
CPU へのハードウェア スレッドの割り当て
プロセッサを特定のスレッドにバインドするために、affinity mask および affinity64 mask サーバー構成オプションを使用しないでください。 これらのオプションは、64 基までの CPU に制限されます。 代わりに、ALTER SERVER CONFIGURATION の SET PROCESS AFFINITY オプションを使用してください。
トランザクション ログ ファイルのサイズの管理
トランザクション ログ ファイルのサイズの拡張に関して、自動拡張に依存しないでください。 トランザクション ログの拡張は、シリアルなプロセスである必要があります。 ログを拡張すると、ログの拡張が完了するまでトランザクションの書き込み操作が実行されなくなる場合があります。 ログ ファイルに対する領域をあらかじめ割り当てるには、その代わりに、環境における一般的なワークロードに十分に対応できる大きさの値にファイル サイズを設定します。
インデックス操作の並列処理の最大限度の設定
多数の CPU を搭載するコンピューター上では、一時的にデータベースの復旧モデルを一括ログ復旧モデルまたは単純復旧モデルに設定することで、インデックスの作成や再構築などのインデックス操作のパフォーマンスを向上させることができます。 これらのインデックス操作では、大量のログ アクティビティが生成されることがあるため、ログの競合によって、SQL Server が選択した最適な並列処理の程度 (DOP) に影響が及ぶおそれがあります。
並列処理の最大限度 (MAXDOP) サーバー構成オプションの調整に加えて、MAXDOP オプションを使用してインデックス操作の並列処理を調整することを検討してください。 詳細については、「 並列インデックス操作の構成」を参照してください。 並列処理の最大限度サーバー構成オプションの調整に関する詳細とガイドラインについては、「max degree of parallelism サーバー構成オプションの構成」をご覧ください。
ワーカー スレッドの最大数オプション
SQL Server では、起動時に、max worker threads サーバー構成オプションが動的に構成されます。 SQL Server では、使用可能な CPU の数とシステム アーキテクチャを使用して、起動時にこのサーバー構成が決定されます。そのときに使用される式についてはこちらを参照してください。
このオプションは詳細設定オプションであるため、熟練したデータベース管理者または認定された SQL Server プロフェッショナルだけが変更するようにしてください。 パフォーマンスの問題が疑われる場合、それはおそらくワーカー スレッドの問題ではありません。 I/O などがワーカー スレッドを待機させている可能性が高いです。 ワーカー スレッドの最大数設定を変更する前に、パフォーマンス問題の根本原因を見つけることが推奨されます。 ただし、ワーカー スレッドの最大数を手動で設定する必要がある場合は、常に、この構成値を、システムに存在する CPU の数の 7 倍以上の値に設定する必要があります。 詳細については、「max worker threads の構成」を参照してください。
SQL トレースと SQL Server Profiler の使用を回避する
SQL トレースおよび SQL Profiler は、運用環境で使用しないことをお勧めします。 CPU 数が増えるに応じて、これらのツールの実行に伴うオーバーヘッドも大きくなります。 SQL トレースを運用環境で使用する必要がある場合は、トレース イベントの数を最小限にしてください。 負荷がある状態で各トレース イベントを慎重にプロファイリングおよびテストし、パフォーマンスに大きな影響を与えるイベントの組み合わせを使用しないように注意してください。
重要
SQL トレースと SQL Server プロファイラー は、非推奨です。 SQL Server の Trace や Replay オブジェクトを含む Microsoft.SqlServer.Management.Trace 名前空間も非推奨とされます。
この機能は、 SQL Serverの将来のバージョンで削除される予定です。 新規の開発作業ではこの機能を使用しないようにし、現在この機能を使用しているアプリケーションは修正することを検討してください。
代わりに拡張イベントを使用します。 拡張イベントについて詳しくは、「クイック スタート:SQL Server 拡張イベント」および SSMS XEvent Profiler に関するページをご覧ください。
Note
Analysis Services のワークロード用の SQL Server プロファイラーは非推奨ではなく、引き続きサポートされます。
tempdb データ ファイルの数を設定します。
ファイルの数は、コンピューター上の (論理) プロセッサの数に依存します。 一般的なルールとして、論理プロセッサの数が 8 以下の場合、論理プロセッサと同じ数のデータ ファイルを使用します。 論理プロセッサの数が 8 より大きい場合、8 つのデータ ファイルを使用し、競合が続く場合、競合が許容できるレベルに減少するまでデータ ファイルの数を 4 の倍数分ずつ増やすか、ワークロード/コードを変更します。 また、「SQL Server の tempdb のパフォーマンスの最適化」で説明されている tempdb に対する他の推奨事項についても留意してください。
ただし、tempdb のコンカレンシーの必要性を慎重に検討することにより、データベース管理のオーバーヘッドを減らすことができます。 たとえば、64 個の CPU が搭載されているシステムにおいて通常 tempdb を使用するクエリの数が 32 個に限られている場合、tempdb ファイルの数を 64 に増やしてもパフォーマンスは改善されません。
64 基を超える CPU を使用できる SQL Server コンポーネント
次の表に、SQL Server の各コンポーネントで 64 基を超える CPU を使用できるかどうかを示します。
| プロセス名 | 実行可能なプログラム | 64 個を超える CPU の使用 |
|---|---|---|
| SQL Server データベース エンジン | Sqlserver.exe | はい |
| Reporting Services | Rs.exe | いいえ |
| Analysis Services | As.exe | いいえ |
| Integration Services | Is.exe | いいえ |
| Service Broker | Sb.exe | いいえ |
| フルテキスト検索 | Fts.exe | いいえ |
| SQL Server エージェント | Sqlagent.exe | いいえ |
| SQL Server Management Studio | Ssms.exe | いいえ |
| SQL Server セットアップ | Setup または Setup.exe | いいえ |