継続的運用とは
継続的運用は、DevOps 分類の 8 つの機能の 1 つです。
継続的運用が必要な理由
複雑なシステムではエラーが発生し、コストのかかる停止や中断が発生する可能性があります。 いくつかの例を見てみましょう。
| 企業 | イベント |
|---|---|
デルタ航空 |
2016 年 8 月、機能不良の装置の一部が原因でアトランタのオペレーション センターで停電が発生したときに、デルタは 2,300 のフライトのキャンセルを余儀なくされました。 会社に報告されたコストは 1 億 5,000 万ドルでした。 |
FedEx および英国国民保健サービス |
2017 年 5 月、WannaCry ランサムウェアが原因で FedEx の運用が中断しました。 ある FedEx 子会社は、3 億ドルの損失を報告しました。 英国国民保健サービスもランサムウェアの犠牲となり、コンピューターへのアクセスがブロックされ、重要な医療機器がロックアウトされ、一部の病院は救急車を他の場所に回さざるを得ませんでした。 |
Amazon S3 |
2017 年 2 月、オペレーターのミスが原因で、Amazon のコア ストレージ サービスに 4 時間の中断が発生しました。これにより、Alexa、IFTTT、Quora、Trello などの重要な Web プロパティに複数の影響がありました。 |
| LinkedIn では、開発作業を 2 か月間行うことができなくなる問題が発生しました。 | |
Equifax |
Equifax では、2017 年に侵害が発生し、その結果として 1 億 6,000 万人を超える消費者の個人情報が流出しました。 これについては、「継続的セキュリティ」で詳しく説明しました。 |
侵害のビジネスへの影響とコスト
侵害のコストは、多くの場合、企業内の売上と信頼の損失をはるかに超えるものとなります。 次のようなコストがあります。
- 対応と通知
- 法律の要求に応じて、影響を受けた関係者に通知するための運用およびサービス コストがあります。 多くの場合、これらのコストには、コール センター、PR サポート、与信モニタリング サービス用の追加コストも含まれます。
- 従業員の生産性と売上の損失
- Yahoo の法務責任者は辞任し、CEO には 2016 年の年間ボーナスが支給されませんでした。
- 訴訟と示談
- Target は、米国 47 州に 1,850 万ドルを支払いました。
- 法規制の罰金と対応
- 2018 年以降、欧州連合では新しいデータ保護ポリシーが有効になり、罰金は年間収益の 4% または 2,000 万ユーロのいずれか大きい方になります。
- ブランド回復のコスト
- 採掘技術企業である Codan では、1 年以内に収益が 4,500 万ドルから 920 万ドルに減少しました。
- その他の不利益
- 2 回の大規模なハッキングが行われた後、Verizon は Yahoo に対する支払いを 3 億 5,000 万ドル引き下げました。
追加のセキュリティと監査の要件が必要になる場合もあります。
継続的運用での可用性と復旧
Gartner 社の調査によれば、ビジネスおよび IT のリーダーは、実稼働アプリケーションの 47% ほどが 2020 年までにパブリック クラウドの場所で実行されるようになると予想しています。
1 行のコードでデータセンター全体を破壊できる場合は、I&O のリーダーによる運用環境の可用性と復旧の重視を変更する必要があります。 新しいデプロイ パターンにより、アプリケーションとインフラストラクチャの可用性と復旧の能力を確保する方法が変化しています。

運用環境でのアプリとリリースの数の増加
ソフトウェア配布の主要業績評価指標は次のとおりです。
- 変更のリード タイム
- デプロイの頻度
- 平均復元時間
- 変更の失敗率
速度の向上には取り組むものの、プロセスへの品質の組み込みには十分な投資をしないチームでは、より大きな障害が発生し、サービスの復元にかかる時間が長くなります。 プロセスに品質を組み込むチームは、速度と安定性の両方を実現します。
Web とモバイルのアプリケーションの数、およびアプリケーションのリリース頻度が大幅に増加しています。 コードもますます複雑になっています。

Note
一般的な DevOps の価値の大部分は、イノベーション (速度) とビジネス継続性 (制御) の間の適切なバランスを見つけることです。
継続的運用とは
重要
継続的運用により、予定メンテナンスなどの計画的なダウンタイムまたは中断の必要性が軽減または排除されます。 可能であれば、インフラストラクチャ、アプリケーション、サービスの継続的監視を自動修復に関連付ける必要があります。 更新または増分リリースがいつ行われるかをユーザーが知るべきではありません。

従来のプラクティスと継続的運用のプラクティスを比較する
従来のエンタープライズ モデルでは、IT 部門がリリースするものを決め、固定のプロセスと手順を使用してすべてのユーザーを制御します。
このアプローチでは、開発チームと IT ガバナンスの間に不整合が生じます。 開発チームは主に俊敏で、速度を重視し、希望どおりの頻度でのリリースを期待しています。 彼らにとって、IT ガバナンスは、今日のビジネス ニーズで期待される市場投入までの時間の目標に合致しないボトルネックであるように思えます。

重要
DevOps は、適切に実装されると、イノベーション (速度) とビジネス継続性 (制御) の両方を実現できます。
従来の開発ライフサイクルでは:
- テストは運用開始直前に実行されます。
- 多くの場合、監視は引き継がれます。
- 多くの場合、セキュリティのコンサルティングはテスト段階で行われます。
- 引き継ぎ時に、コードとすべてのサービス管理コントロールのセキュリティ チェックを実行する必要があります。
- 多くの場合、コンプライアンスは引き継ぎに含まれず、サービスが運用状態のときに "不意に" 出現します。
- 回復性/継続性の計画は設計フェーズの一環として行われますが、多くの場合、関連シナリオの実際のテストは運用またはテスト フェーズでのみ行われます。これにより、構成の変更、手直し、無駄な作業が発生する可能性があります。
- 多くの場合、運用、セキュリティとコンプライアンス、および開発者の間のコラボレーションは、インシデント管理と問題管理のプロセスによって事後対応で行われます。
- 自動化を最終段階まで残すと、それを行うためのリソースがわずかしか残っていないことがよくあります。
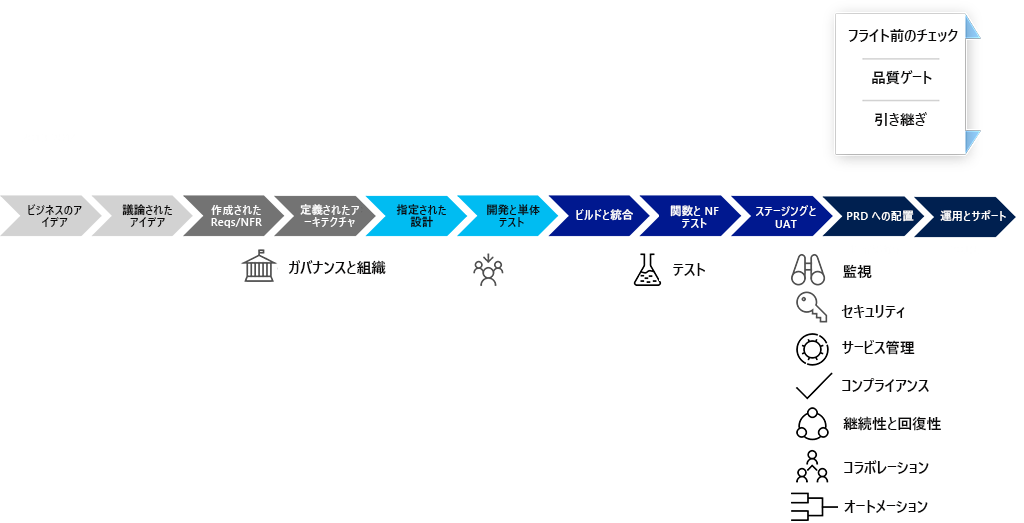
新しい手法、テクノロジ、および作業方法には継続的運用に対する新しいアプローチが必要です。 次の 8 つの主要な継続的運用のプラクティスが登場し、進化を続けています。
- セキュリティとコンプライアンスでは、仕様上、高度に自動化されたクラウド環境向けに設計する際には、特定の標準や法律だけでなく、追跡可能性や監査性などのビジネス要件も考慮する必要があることを受け入れます。
- 継続性と回復性には、ビジネス ニーズが設計と実装に確実に反映されるように、組織との緊密なコラボレーションが必要です。
- テレメトリと監視を使用して、顧客の使用パターン、潜在的な新しいニーズ、およびユーザーがエラーを検出した場所に関する詳細情報を検出できます。 これらのツールは、価値が確実に提供されるようにするためにも役立ちます。
- サービス管理は、DevOps カルチャにおける別の話です。
- 移行すると、自分で所有することになります。 自分で構築して自分で実行し、壊れたら自分で修正します。
- 必要なものに注目します。
- ガバナンスを強化します。
- 透過性を高めます。
- カルチャおよびコラボレーションは、継続的運用に不可欠です。 多くの場合、組織は、DevOps チームへの変革を促進するために作業方法を変更する必要があります。 また、セキュリティと回復性を設計するときは、コラボレーションも不可欠です。
- 自動化と AI/ML Ops は、DevOps (およびクラウド) を従来の運用チームとは異なるものにする重要な要素です。 1 つの領域だけでなく、自動化するシステム全体 (システムの自動化) に重点を置く必要があります。
- 継続なデプロイでは、最新のリリース パイプラインを使用して、開発チームが新機能を迅速かつ安全にデプロイできるようにします。これにより、顧客価値の連続した流れが実現し、問題の修復に要する時間が短縮されます。
- シフトライト テストでは、ダーク ローンチ、機能フラグ、監視、A/B テストなどのプラクティスを使用します。 その後、チームはテストを続行して、アプリケーションが実際に使用されているときの動作、パフォーマンス、可用性の期待事項を満たしていることを確認できます。

DevOps アプローチに進化するには、最新の IT アプローチでビジネス価値を実現するための大きなパラダイム シフトがカルチャに必要になります。
| 従来の IT | 最近の IT | |
|---|---|---|
| DNA | 介入 | 介入の除去 |
| サービスの配信 | ウェーブベース | 継続的イテレーションベース |
| サービスの安定性 | 成功のための設計 (HA/冗長) | 障害のための設計 (回復性) |
| 委任レベル | IT サイロ | エンドツーエンドのサービス |
| 処理 | ドキュメント内、最適化、再設計済み | セルフ サービス、ナレッジ、低摩擦、自動化 |
| Automation | 分離、手動で開始 | 体系的、トリガー、自動 |
| Monitoring | 要素、フォールト重視 | サービス、エンドツーエンドの機能重視 |
| サポート | サービス デスク/連絡先センター | カスタマー ケア/セルフ サービス |
| ライフサイクル | N-1 以前 | N、N+1 |
| 構成/資産管理 | 検出/手動構成 | 規定、宣言型、自動化 |
これらの変更により、簡略化および自動化されたプロセス、調整された結果インセンティブ、リスクの軽減、顧客中心のアプローチが実現されます。