SQL Server での実行速度の遅いクエリのトラブルシューティング
元の製品バージョン: SQL Server
元の KB 番号: 243589
はじめに
この記事では、SQL Server の使用時にデータベース アプリケーションで発生する可能性があるパフォーマンスの問題 (特定のクエリまたはクエリのグループの低パフォーマンス) に対処する方法について説明します。 次の手法は、低速なクエリの問題の原因を絞り込み、解決に向けて導くのに役立ちます。
低速なクエリを検索する
SQL Server インスタンスでクエリパフォーマンスの問題があることを確認するには、まずクエリの実行時間 (経過時間) を調べることから始めます。 確立されたパフォーマンス ベースラインに基づいて、設定したしきい値 (ミリ秒) を超えているかどうかを確認します。 たとえば、ストレス テスト環境では、ワークロードのしきい値を 300 ミリ秒以下に設定し、このしきい値を使用できます。 その後、個々のクエリとその事前に確立されたパフォーマンス ベースライン期間に焦点を当てて、そのしきい値を超えるすべてのクエリを特定できます。 最終的には、ビジネス ユーザーはデータベース クエリの全体的な期間を考慮します。そのため、主な焦点は実行時間です。 CPU 時間や論理読み取りなどの他のメトリックが収集され、調査の絞り込みに役立ちます。
現在実行中のステートメントについては、sys.dm_exec_requestsのtotal_elapsed_time列とcpu_time列を確認します。 次のクエリを実行してデータを取得します。
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;クエリの過去の実行については、sys.dm_exec_query_statsのlast_elapsed_time列とlast_worker_time列を確認します。 次のクエリを実行してデータを取得します。
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNote
avg_wait_timeに負の値が示されている場合は、パラメーター クエリです。SQL Server Management Studio (SSMS) または Azure Data Studio でオンデマンドでクエリを実行できる場合は、 SET STATISTICS TIME
ONと SET STATISTICS IOONを使用してクエリを実行します。SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF次に、 Messages から、CPU 時間、経過時間、および次のような論理読み取りが表示されます。
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.クエリ プランを収集できる場合は、 Execution プランのプロパティからデータを確認。
Include Actual Execution Plan on でクエリを実行します。
Execution プランから左端の演算子を選択します。
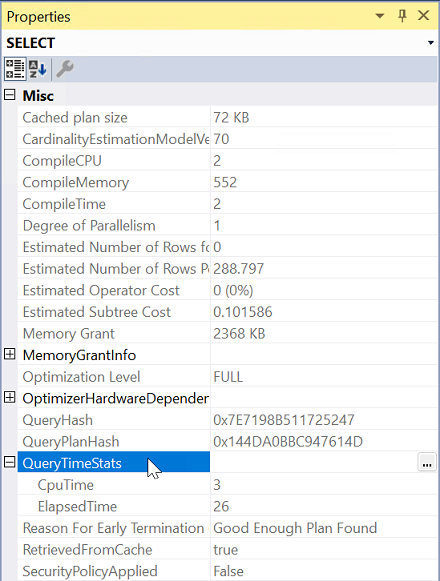
Properties から、QueryTimeStats プロパティを展開します。
ElapsedTime と CpuTime を確認します。
実行中と待機中: クエリが遅くなる理由
定義済みのしきい値を超えるクエリが見つかる場合は、低速になる可能性がある理由を調べます。 パフォーマンスの問題の原因は、実行中または待機中の 2 つのカテゴリにグループ化できます。
WAITING: クエリはボトルネックを長時間待機しているため、低速になる可能性があります。 waits のタイプのボトルネックの詳細な一覧を参照してください。
RUNNING: クエリは長時間実行 (実行中) しているため、低速になる可能性があります。 つまり、これらのクエリは CPU リソースを積極的に使用しています。
クエリの有効期間 (持続時間) の中で、そのクエリが実行されている時間と待機している時間が発生することはありえることです。 ただし、長い経過時間に影響を与える主要なカテゴリはどれであるかを判断することに重点を置いています。 そのため、最初のタスクは、そのクエリがどのカテゴリに分類されるかを確認することです。 これは簡単です。クエリが実行されていない場合は待機しています。 理想的には、クエリは経過時間の大部分を実行中の状態に費やし、リソースの待機にほとんど時間を費やしません。 また、最良のシナリオでは、クエリは事前に定義されたベースライン内または下で実行されます。 クエリの経過時間と CPU 時間を比較して、問題の種類を特定します。
型 1: CPU バインド (ランナー)
CPU 時間が経過時間に近い、等しい、またはそれより長い場合は、CPU バインド クエリとして扱うことができます。 たとえば、経過時間が 3000 ミリ秒 (ミリ秒) で、CPU 時間が 2900 ミリ秒の場合、ほとんどの経過時間が CPU に費やされます。 その後、CPU にバインドされたクエリであると言うことができます。
実行 (CPU バインド) クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
論理読み取り (キャッシュ内のデータ/インデックス ページの読み取り) は、SQL Server の CPU 使用率の要因として最も頻繁に使用されます。 CPU の使用が他のソース (T-SQL または XProcs や SQL CRL オブジェクトなどの他のコード) である while ループから取得されるシナリオが考えられます。 この表の 2 番目の例は、CPU の大部分が読み取りからのものではありません。このようなシナリオを示しています。
Note
CPU 時間が期間を超える場合は、並列クエリが実行されていることを示します。複数のスレッドが同時に CPU を使用しています。 詳細については、「 パラメーター クエリ - ランナーまたはウェイター」を参照してください。
タイプ 2: ボトルネックを待機している (待機者)
経過時間が CPU 時間を大幅に超える場合、クエリはボトルネックを待機しています。 経過時間には、CPU でクエリを実行する時間 (CPU 時間) と、リソースが解放されるのを待つ時間 (待機時間) が含まれます。 たとえば、経過時間が 2000 ミリ秒で CPU 時間が 300 ミリ秒の場合、待機時間は 1700 ミリ秒 (2000 - 300 = 1700) です。 詳細については、「 待機の種類」を参照してください。
待機クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
並列クエリ - ランナーまたはウェイター
並列クエリでは、全体的な期間よりも多くの CPU 時間が使用される場合があります。 並列処理の目的は、複数のスレッドがクエリの一部を同時に実行できるようにすることです。 1 秒のクロック時間では、8 つの並列スレッドを実行することで、クエリで 8 秒の CPU 時間を使用できます。 そのため、経過時間と CPU 時間の差に基づいて、CPU バインドまたは待機クエリを決定することが困難になります。 ただし、一般的なルールとして、上記の 2 つのセクションに記載されている原則に従ってください。 概要は次のとおりです。
- 経過時間が CPU 時間よりもはるかに長い場合は、待機者と見なします。
- CPU 時間が経過時間よりもはるかに長い場合は、ランナーと考えてください。
並列クエリの例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 読み取り (論理) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
手法の高度な視覚的表現

待機中のクエリを診断して解決する
関心のあるクエリが待機者であることが確認された場合、次の手順はボトルネックの問題の解決に集中することです。 それ以外の場合は、手順 4: Diagnose に進み、実行中のクエリを解決します。
ボトルネックを待機しているクエリを最適化するには、待機の長さとボトルネックの場所 (待機の種類) を特定します。 待機の種類が確認されたら待機時間を短縮するか、完全に待機を排除します。
おおよその待機時間を計算するには、クエリの経過時間から CPU 時間 (ワーカー時間) を減算します。 通常、CPU 時間は実際の実行時間であり、クエリの有効期間の残りの部分は待機しています。
おおよその待機時間を計算する方法の例:
| 経過時間 (ミリ秒) | CPU 時間 (ms) | 待機時間 (ミリ秒) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
ボトルネックまたは待機を特定する
待機時間の長い履歴クエリ (全体の経過時間の >20% が待機時間など) を特定するには、次のクエリを実行します。 このクエリでは、SQL Server の開始以降にキャッシュされたクエリ プランのパフォーマンス統計が使用されます。
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC待機時間が 500 ミリ秒を超える現在実行中のクエリを特定するには、次のクエリを実行します。
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1クエリ プランを収集できる場合は、SSMS の実行プランのプロパティからWaitStats を確認します。
- Include Actual Execution Plan on を使用してクエリを実行します。
- [実行プラン]タブで、左端の演算子右クリックします。
- Propertiesを選択しWaitStatsプロパティを選択します。
- WaitTimeMs と WaitType を確認します。
PSSDiag/SQLdiag または SQL LogScout LightPerf/GeneralPerf シナリオに慣れている場合は、いずれかのシナリオを使用してパフォーマンス統計を収集し、SQL Server インスタンスで待機中のクエリを特定することを検討してください。 収集したデータ ファイルをインポートし、 SQL Nexus を使用してパフォーマンス データを分析できます。
待機の排除または削減に役立つ参照
各待機の種類の原因と解決策は異なります。 すべての待機の種類を解決する一般的な方法は 1 つもありません。 待機の種類に関する一般的な問題のトラブルシューティングと解決に関する記事を次に示します。
- ブロックの問題を理解して解決する (LCK_M_*)
- Azure SQL Database のブロックの問題の概要と解決策
- I/O の問題 (PAGEIOLATCH_*、WRITELOG、IO_COMPLETION、BACKUPIO) による SQL Server のパフォーマンス低下のトラブルシューティング
- SQL Server での最終ページ挿入PAGELATCH_EX 競合を解決する
- メモリ許可の説明と解決策 (RESOURCE_SEMAPHORE)
- 待機の種類に起因する低速クエリASYNC_NETWORK_IOトラブルシューティングする
- Always On 可用性グループを使用した高HADR_SYNC_COMMIT待機の種類のトラブルシューティング
- しくみ: CMEMTHREAD とデバッグ
- 並列処理待機を実行可能にする (CXPACKET と CXCONSUMER)
- THREADPOOL 待機
多くの待機の種類とそれらが示す内容の説明については、「待機の種類の表を参照してください。
実行中のクエリを診断して解決する
CPU (ワーカー) 時間が全体的な経過時間に非常に近い場合、クエリは有効期間の大部分を実行に費やします。 通常、SQL Server エンジンが高い CPU 使用率を駆動する場合、CPU 使用率が高いのは、多数の論理読み取りを実行するクエリ (最も一般的な理由) です。
現在 CPU 使用率の高いアクティビティを担当するクエリを特定するには、次のステートメントを実行します。
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
現時点でクエリが CPU を駆動していない場合は、次のステートメントを実行して、CPU バインドクエリの履歴を検索できます。
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
長時間実行されている CPU バインド クエリを解決するための一般的な手法
- クエリのクエリ プランを調べる
- 統計の更新
- 不足しているインデックスを特定して適用します。 不足しているインデックスを識別する方法の詳細については、「インデックス候補のない非クラスター化インデックスを調整する を参照してください。
- クエリの再設計または書き換え
- パラメーターに依存するプランを特定して解決する
- SARG 機能の問題を特定して解決する
- top、EXISTS、IN、FAST、SET ROWCOUNT、OPTION (FAST N) によって、実行時間の長い入れ子になったループが発生する可能性がある Row の目標 問題を特定して解決します。 詳細については、「 Row Goal Gone Rogue および Showplan の機能強化 - Row Goal EstimateRowsWithoutRowGoal」を参照してください。
- カーディナリティ推定の問題を評価して解決します。 詳細については、「 SQL Server 2012 以前から 2014 以降へのアップグレード後のDecreased クエリのパフォーマンス」を参照してください。
- 完了していないと思われる量子を特定して解決する方法については、「 SQL Server で終わっていないように見えるクエリをトラブルシューティングする」を参照してください
- オプティマイザーのタイムアウトの影響 低いクエリを特定して解決する
- CPU パフォーマンスの高い問題を特定します。 詳細については、「 SQL Server での CPU 使用率の高い問題をトラブルシューティングする」を参照してください。
- 2 つのサーバーで顕著なパフォーマンスの違いが見られるクエリに関するトラブルシューティング
- システムのコンピューティング リソースを増やす (CPU)
- 幅の狭いプランとワイド プランでの UPDATE のパフォーマンスに関する問題のトラブルシューティング