Zagadnienia dotyczące projektowania dla samoobsługowych platform danych
Siatka danych to ekscytujące nowe podejście do projektowania i opracowywania architektury danych. W przeciwieństwie do tradycyjnej architektury danych siatka danych oddziela odpowiedzialność między funkcjonalnymi domenami danych, które koncentrują się na tworzeniu produktów danych i zespole platformy, który koncentruje się na możliwościach technicznych. To rozdzielenie obowiązków musi być odzwierciedlone na platformie. Musisz zrównoważyć możliwości niezależne od domeny i umożliwić zespołom domeny modelowanie, przetwarzanie i dystrybuowanie ich danych w całej organizacji.
Wybór odpowiedniego poziomu szczegółowości domeny i reguł dotyczących oddzielenia od platform nie jest łatwy. Ten artykuł zawiera kilka scenariuszy, które zawierają szczegółowe wskazówki.
Analiza w skali chmury
Jeśli chcesz utworzyć siatkę danych za pomocą platformy Azure, zalecamy wdrożenie analizy w skali chmury. Ta struktura jest wdrażalną architekturą referencyjną i jest dostarczana z szablonami open source i najlepszymi rozwiązaniami. Architektura analizy w skali chmury ma dwa główne bloki konstrukcyjne, które są podstawowe dla wszystkich opcji wdrażania:
- Strefa docelowa zarządzania danymi: podstawa architektury danych. Zawiera wszystkie krytyczne możliwości zarządzania danymi, takie jak wykaz danych, pochodzenie danych, wykaz interfejsów API, zarządzanie danymi głównymi itd.
- Strefy docelowe danych: subskrypcje hostujące rozwiązania analityczne i sztucznej inteligencji. Obejmują one kluczowe możliwości hostingu platformy analitycznej.
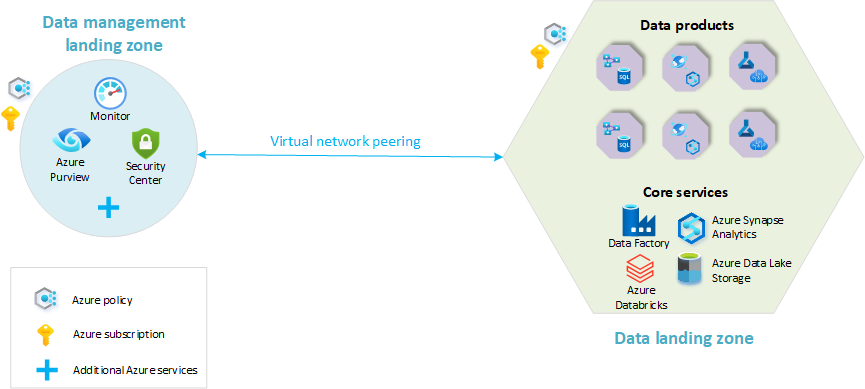
Poniższy diagram zawiera omówienie platformy analitycznej w skali chmury ze strefą docelową zarządzania danymi i pojedynczą strefą docelową danych. Nie wszystkie usługi platformy Azure są reprezentowane na diagramie. Uproszczono wyróżnianie podstawowych koncepcji organizacji zasobów w ramach tej architektury.
Struktura analizy opartej na chmurze nie jest jawna na temat dokładnego typu architektury danych, którą należy aprowizować. Można jej używać w przypadku wielu typowych rozwiązań analitycznych w skali chmury, w tym magazynów danych (przedsiębiorstwa), magazynów danych, magazynów typu data lake, domów typu data lake i siatk danych. Wszystkie przykładowe rozwiązania w tym artykule używają architektury siatki danych.
Dowiedz się, że wszystkie architektury są zgodne z zasadami siatki danych: własnością domeny, danymi jako produktem, samoobsługową platformą danych i federacyjnym ładem obliczeniowym. Wszystkie różne ścieżki mogą prowadzić do siatki danych. Nie ma jednej właściwej ani złej odpowiedzi. Musisz dokonać odpowiednich kompromisów dla potrzeb organizacji.
Strefa docelowa pojedynczej danych
Najprostszy wzorzec wdrażania do tworzenia architektury siatki danych obejmuje jedną strefę docelową zarządzania danymi i jedną strefę docelową danych. Architektura danych w takim scenariuszu wygląda następująco:

W tym modelu wszystkie domeny danych funkcjonalnych znajdują się w tej samej strefie docelowej danych. Pojedyncza subskrypcja zawiera standardowy zestaw usług. Grupy zasobów segregują różne domeny danych i produkty danych. Standardowe usługi danych, takie jak Azure Data Lake Store, Azure Logic Apps i Azure Synapse Analytics, mają zastosowanie do wszystkich domen.
Wszystkie domeny danych są zgodne z zasadami siatki danych: dane są zgodne z własnością domeny, a dane są traktowane jak produkty. Platforma jest w pełni samoobsługowa, chociaż istnieją ograniczone odmiany usług. Wszystkie domeny powinny być ściśle zgodne z tymi samymi zasadami zarządzania danymi.
Ta opcja wdrożenia może być przydatna w przypadku mniejszych firm lub projektów z polami zielonymi, które chcą objąć siatkę danych, ale nie zbyt komplikują rzeczy. To wdrożenie może być również punktem wyjścia dla organizacji, która planuje utworzyć coś bardziej złożonego. W takim przypadku zaplanuj rozszerzenie na wiele stref docelowych w późniejszym czasie.
Wyrównane systemy źródłowe i strefy docelowe wyrównane dla konsumentów
W poprzednim modelu nie uwzględniliśmy innych subskrypcji ani aplikacji lokalnych. Poprzedni model można nieco zmienić, dodając strefę docelową wyrównaną do systemu źródłowego, aby zarządzać wszystkimi danymi przychodzącymi. Dołączanie danych jest trudnym procesem, więc posiadanie dwóch stref docelowych danych jest przydatne. Dołączanie pozostaje jedną z najtrudniejszych części korzystania z danych. Dołączanie często wymaga również dodatkowych narzędzi do rozwiązania problemów z integracją, ponieważ jej wyzwania różnią się od tych integracji. Ułatwia to rozróżnienie między dostarczaniem danych i używaniem danych.

W architekturze po lewej stronie tego diagramu usługi ułatwiają dołączanie wszystkich danych, takich jak CDC, usługi do ściągania interfejsów API lub usługi data lake na potrzeby dynamicznego tworzenia zestawów danych. Usługi na tej platformie mogą pobierać dane ze środowisk lokalnych, środowisk w chmurze lub dostawców SaaS. Ten typ platformy zwykle ma również większe obciążenie, ponieważ istnieje większe sprzężenie z podstawowymi aplikacjami operacyjnymi. Możesz chcieć traktować to inaczej niż w przypadku użycia danych.
W architekturze po prawej stronie diagramu organizacja optymalizuje zużycie i ma usługi skoncentrowane na przekształcaniu danych w wartość. Te usługi mogą obejmować uczenie maszynowe, raportowanie itd.
Te domeny architektury są zgodne ze wszystkimi zasadami siatki danych. Domeny przejmują własność danych i mogą bezpośrednio dystrybuować dane do innych domen.
Strefy docelowe centrów, ogólnych i specjalnych danych
Kolejną opcją wdrożenia jest kolejna iteracja poprzedniego projektu. To wdrożenie jest zgodne z topologią sieci zarządzanej: dane są dystrybuowane za pośrednictwem centralnego centrum, w którym dane są partycjonowane na domenę, logicznie izolowane i nie są zintegrowane. Centrum tego modelu używa własnej strefy docelowej danych (niezależnej od domeny) i może być własnością centralnego zespołu ds. ładu danych, który nadzoruje, które dane są dystrybuowane do innych domen. Centrum prowadzi również usługi, które ułatwiają dołączanie danych.

W przypadku domen, które wymagają standardowych usług do używania, używania, analizowania i tworzenia nowych danych, użyj ogólnej strefy docelowej danych. Ta pojedyncza subskrypcja zawiera standardowy zestaw usług. Zastosuj również wirtualizację danych, ponieważ większość produktów danych jest już utrwalone w centrum i nie potrzebujesz więcej duplikacji danych.
To wdrożenie umożliwia "specjalne": dodatkowe strefy docelowe, które można aprowizować, gdy nie jest możliwe logiczne grupowanie domen. Mogą one być potrzebne, gdy obowiązują granice regionalne lub prawne lub gdy domeny mają unikatowe i kontrastujące wymagania. Mogą być one również potrzebne w sytuacjach, gdy silny globalny nadzór zależny jest stosowany z wyjątkami dla działalności zagranicznej.
Jeśli Twoja organizacja musi kontrolować, które dane są dystrybuowane i używane przez jakie domeny, wdrożenie centrum jest dobrym rozwiązaniem. Jest to również opcja, jeśli zajmujesz się wariantem czasu i nietrwałymi problemami dla dużych użytkowników danych. Można zdecydowanie standandaryzować projekt produktu danych, który umożliwia domenom przechodzenie w czasie i wykonywanie ponownych prób. Ten model jest szczególnie powszechny w branży finansowej.
Funkcjonalne i regionalne strefy docelowe danych
Aprowizowanie wielu stref docelowych danych może ułatwić grupowanie domen funkcjonalnych na podstawie spójności i wydajności pracy i udostępniania danych. Wszystkie strefy docelowe danych są zgodne z tą samą inspekcją i mechanizmami kontroli, ale nadal można mieć elastyczność i zmiany projektowe między różnymi strefami docelowymi danych.

Określ funkcjonalne domeny danych, które mają być logicznie zgrupowane dla udostępnionej strefy docelowej danych. Na przykład możesz zaimplementować te same szablony, jeśli masz granice regionalne. Własność, zabezpieczenia lub granice prawne mogą wymusić segregowanie domen. Elastyczność, tempo zmian i separacja lub sprzedaż możliwości są również ważnymi czynnikami, które należy wziąć pod uwagę.
Dalsze wskazówki i najlepsze rozwiązania można znaleźć w domenach danych.
Różne strefy docelowe nie są autonomiczne. Mogą łączyć się z magazynami data lake hostowanymi w innych strefach. Dzięki temu domeny mogą współpracować w przedsiębiorstwie. Można również zastosować trwałość wielolotową w celu łączenia różnych technologii magazynu danych. Trwałość wielolotowa umożliwia domenom bezpośrednie odczytywanie danych z innych domen bez duplikowania danych.
Podczas wdrażania wielu stref docelowych danych należy wiedzieć, że obciążenie związane z zarządzaniem jest dołączone do każdej strefy docelowej danych. Należy zastosować komunikację równorzędną sieci wirtualnych między wszystkimi strefami docelowymi danych, musisz zarządzać dodatkowymi prywatnymi punktami końcowymi itd.
Wdrażanie wielu stref docelowych danych jest dobrym rozwiązaniem, jeśli architektura danych jest duża. Do architektury można dodać więcej stref docelowych, aby zaspokoić typowe potrzeby różnych domen. Te dodatkowe strefy docelowe używają komunikacji równorzędnej sieci wirtualnych do łączenia się zarówno ze strefą docelową zarządzania danymi, jak i ze wszystkimi innymi strefami docelowymi. Komunikacja równorzędna umożliwia udostępnianie zestawów danych i zasobów w strefach docelowych. Dzielenie danych między oddzielne strefy umożliwia rozłożenie obciążeń między subskrypcje i zasoby platformy Azure. Takie podejście pomaga w sposób organiczny implementować siatkę danych.
Duże przedsiębiorstwo wymagające różnych stref zarządzania danymi
Duże przedsiębiorstwa działające w skali globalnej mogą mieć sprzeczne wymagania dotyczące zarządzania danymi między różnymi częściami organizacji. Aby rozwiązać ten problem, można wdrożyć wiele stref zarządzania danymi i stref docelowych danych. Na poniższym diagramie przedstawiono przykład architektury tego typu:

Wiele stref docelowych zarządzania danymi powinno uzasadniać nakład pracy i złożoność integracji. Na przykład inna strefa docelowa zarządzania danymi może mieć sens w sytuacjach, w których dane organizacji (meta)nie mogą być widoczne przez nikogo spoza organizacji.
Podsumowanie
Przejście do siatki danych to zmiana kulturowa obejmująca niuanse, kompromisy i zagadnienia. Aby uzyskać najlepsze rozwiązania i zasoby wykonywalne, możesz użyć analizy w skali chmury. Architektury referencyjne w tym artykule oferują punkty wyjścia, aby rozpocząć implementację.