Zalecenia dotyczące reagowania na zdarzenia zabezpieczeń
Dotyczy rekomendacji listy kontrolnej dotyczącej zabezpieczeń platformy Azure Well-Architected Framework:
| SE:12 | Zdefiniuj i przetestuj skuteczne procedury reagowania na zdarzenia, które obejmują spektrum zdarzeń, od zlokalizowanych problemów po odzyskiwanie po awarię. Jasno określ, który zespół lub osoba uruchamia procedurę. |
|---|
W tym przewodniku opisano zalecenia dotyczące implementowania reagowania na zdarzenia zabezpieczeń dla obciążenia. W przypadku naruszenia zabezpieczeń systemu systematyczne podejście reagowania na zdarzenia pomaga skrócić czas potrzebny na identyfikowanie zdarzeń, zarządzanie nimi i eliminowanie zdarzeń zabezpieczeń. Te zdarzenia mogą zagrażać poufności, integralności i dostępności systemów i danych oprogramowania.
Większość przedsiębiorstw ma centralny zespół ds. operacji zabezpieczeń (znany również jako Security Operations Center (SOC) lub SecOps. Obowiązkiem zespołu ds. operacji zabezpieczeń jest szybkie wykrywanie, określanie priorytetów i klasyfikacja potencjalnych ataków. Zespół monitoruje również dane telemetryczne związane z zabezpieczeniami i bada naruszenia zabezpieczeń.
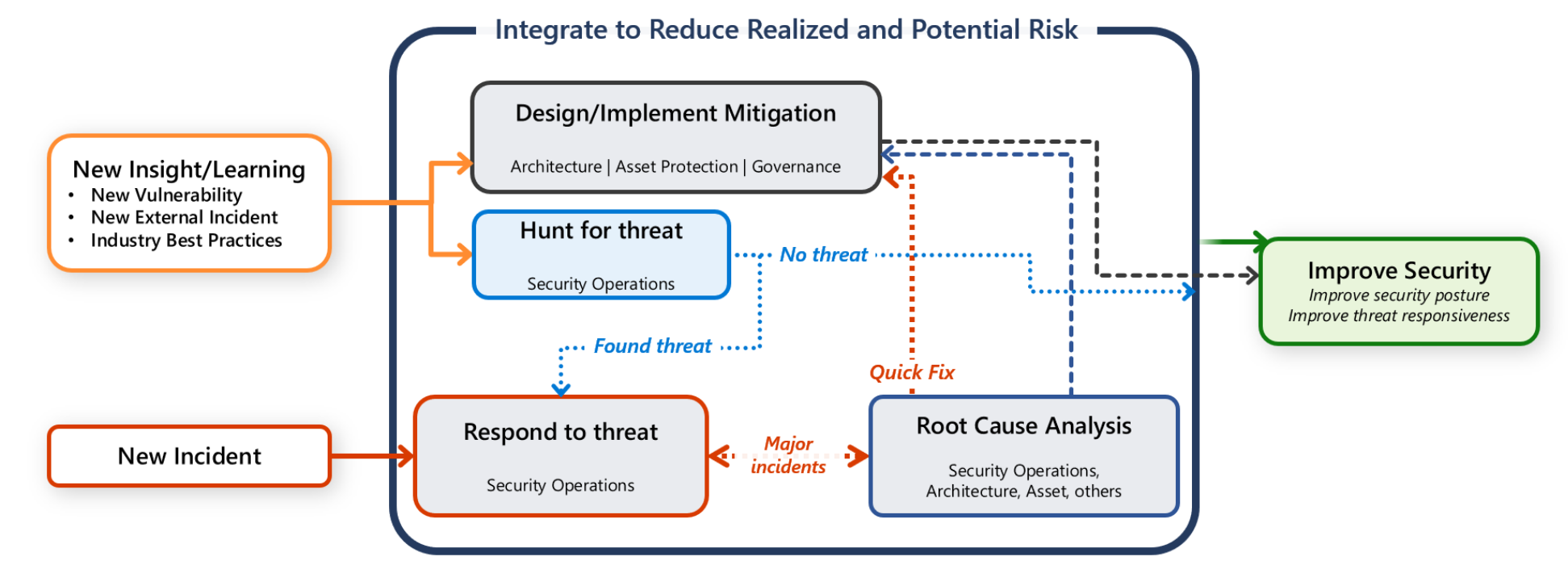
Jednak ponosisz również odpowiedzialność za ochronę obciążenia. Ważne jest, aby każda komunikacja, badanie i działania wyszukiwania zagrożeń to współpraca między zespołem obciążeń a zespołem SecOps.
Ten przewodnik zawiera zalecenia dla Ciebie i twojego zespołu ds. obciążeń, które ułatwiają szybkie wykrywanie, klasyfikowanie i badanie ataków.
Definicje
| Okres | Definicja |
|---|---|
| Alerty | Powiadomienie zawierające informacje o zdarzeniu. |
| Wierność alertu | Dokładność danych określających alert. Alerty o wysokiej wierności zawierają kontekst zabezpieczeń potrzebny do podjęcia natychmiastowych działań. Alerty o niskiej wierności nie zawierają informacji lub zawierają szum. |
| Wyniki fałszywie dodatnie | Alert wskazujący zdarzenie, które nie miało miejsce. |
| Incident | Zdarzenie wskazujące nieautoryzowany dostęp do systemu. |
| Reagowanie na zdarzenia | Proces, który wykrywa, reaguje i zmniejsza ryzyko związane ze zdarzeniem. |
| Triage (klasyfikacja) | Operacja reagowania na zdarzenia, która analizuje problemy z zabezpieczeniami i określa priorytety ich ograniczania ryzyka. |
Kluczowe strategie projektowania
Ty i Twój zespół wykonują operacje reagowania na zdarzenia, gdy istnieje sygnał lub alert dotyczący potencjalnego naruszenia zabezpieczeń. Alerty o wysokiej wierności zawierają duży kontekst zabezpieczeń, który ułatwia analitykom podejmowanie decyzji. Alerty o wysokiej wierności powodują niską liczbę wyników fałszywie dodatnich. W tym przewodniku założono, że system alertów filtruje sygnały o niskiej wierności i koncentruje się na alertach o wysokiej wierności, które mogą wskazywać na rzeczywiste zdarzenie.
Wyznaczanie kontaktów powiadomień o zdarzeniu
Alerty zabezpieczeń muszą skontaktować się z odpowiednimi osobami w zespole i w organizacji. Ustanów wyznaczony punkt kontaktu w zespole ds. obciążeń, aby otrzymywać powiadomienia o zdarzeniach. Powiadomienia te powinny zawierać jak najwięcej informacji o zasobie, który został naruszony i system. Alert musi zawierać kolejne kroki, aby twój zespół mógł przyspieszyć działania.
Zalecamy rejestrowanie powiadomień i akcji dotyczących zdarzeń oraz zarządzanie nimi przy użyciu wyspecjalizowanych narzędzi, które przechowuje dziennik inspekcji. Korzystając ze standardowych narzędzi, można zachować dowody, które mogą być wymagane w przypadku potencjalnych dochodzeń prawnych. Poszukaj możliwości wdrożenia automatyzacji, która może wysyłać powiadomienia na podstawie obowiązków stron odpowiedzialnych. Zachowaj jasny łańcuch komunikacji i raportowania podczas zdarzenia.
Korzystaj z rozwiązań do zarządzania zdarzeniami zabezpieczeń (SIEM) i rozwiązań automatycznego reagowania na orkiestrację zabezpieczeń (SOAR) zapewnianych przez organizację. Alternatywnie możesz uzyskać narzędzia do zarządzania incydentami i zachęcić organizację do standaryzacji ich dla wszystkich zespołów obciążeń.
Badanie z zespołem klasyfikacji
Członek zespołu, który otrzymuje powiadomienie o zdarzeniu, jest odpowiedzialny za skonfigurowanie procesu klasyfikacji obejmującego odpowiednie osoby na podstawie dostępnych danych. Zespół klasyfikacji, często nazywany zespołem mostka, musi uzgodnić tryb i proces komunikacji. Czy to zdarzenie wymaga asynchronicznych dyskusji lub wywołań mostka? Jak zespół powinien śledzić i komunikować postępy w badaniach? Gdzie zespół może uzyskać dostęp do zasobów zdarzeń?
Reagowanie na zdarzenia to kluczowy powód, aby zapewnić aktualność dokumentacji, na przykład układ architektury systemu, informacje na poziomie składnika, prywatność lub klasyfikacja zabezpieczeń, właściciele i kluczowe punkty kontaktowe. Jeśli informacje są niedokładne lub nieaktualne, zespół mostu traci cenny czas, próbując zrozumieć, jak działa system, kto jest odpowiedzialny za poszczególne obszary i jaki może być wpływ zdarzenia.
W celu przeprowadzenia dalszych dochodzeń należy zaangażować odpowiednie osoby. Możesz uwzględnić menedżera zdarzeń, oficera zabezpieczeń lub potencjalnych klientów skoncentrowanych na obciążeniach. Aby zachować fokus klasyfikacji, wyklucz osoby, które znajdują się poza zakresem problemu. Czasami oddzielne zespoły badają incydent. Może istnieć zespół, który początkowo bada ten problem i próbuje rozwiązać ten problem, oraz inny wyspecjalizowany zespół, który może wykonywać kryminalistyki w celu przeprowadzenia głębokiego badania w celu ustalenia szerokich problemów. Możesz poddać kwarantannie środowisko obciążenia, aby umożliwić zespołowi kryminalistycznemu przeprowadzenie badań. W niektórych przypadkach ten sam zespół może obsłużyć całe dochodzenie.
W początkowej fazie zespół klasyfikacji jest odpowiedzialny za określenie potencjalnego wektora i jego wpływu na poufność, integralność i dostępność (zwaną również CIA) systemu.
W kategoriach CIA przypisz początkowy poziom ważności, który wskazuje głębokość uszkodzenia i pilność korygowania. Oczekuje się, że ten poziom zmieni się wraz z upływem czasu, ponieważ więcej informacji zostanie odnalezionych na poziomie klasyfikacji.
W fazie odnajdywania ważne jest, aby określić natychmiastowy przebieg działań i planów komunikacyjnych. Czy istnieją jakieś zmiany w stanie uruchomienia systemu? Jak można powstrzymać atak, aby zatrzymać dalsze wykorzystywanie? Czy zespół musi wysłać wewnętrzną lub zewnętrzną komunikację, taką jak odpowiedzialne ujawnienie? Rozważ wykrywanie i czas odpowiedzi. Użytkownik może być prawnie zobowiązany do zgłaszania niektórych rodzajów naruszeń do organu regulacyjnego w określonym przedziale czasu, który jest często godzinami lub dniami.
Jeśli zdecydujesz się zamknąć system, następne kroki prowadzą do procesu odzyskiwania po awarii (DR) obciążenia.
Jeśli system nie zostanie zamknięty, ustal, jak skorygować zdarzenie bez wpływu na funkcjonalność systemu.
Odzyskiwanie po zdarzeniu
Traktuj zdarzenie zabezpieczeń, takie jak awaria. Jeśli korygowanie wymaga ukończenia odzyskiwania, należy użyć odpowiednich mechanizmów odzyskiwania po awarii z perspektywy zabezpieczeń. Proces odzyskiwania musi zapobiegać prawdopodobieństwu cyklu. W przeciwnym razie odzyskiwanie z uszkodzonej kopii zapasowej ponownie wprowadza problem. Ponowne wdrożenie systemu z tą samą luką w zabezpieczeniach prowadzi do tego samego zdarzenia. Zweryfikuj kroki i procesy przejścia w tryb failover i powrotu po awarii.
Jeśli system nadal działa, oceń wpływ na uruchomione części systemu. Kontynuuj monitorowanie systemu, aby upewnić się, że inne cele dotyczące niezawodności i wydajności zostały spełnione lub zostały ponownie spełnione przez zaimplementowanie odpowiednich procesów degradacji. Nie naruszaj prywatności ze względu na środki zaradcze.
Diagnostyka jest procesem interaktywnym do momentu zidentyfikowania wektora i potencjalnej poprawki i powrotu. Po zdiagnozowaniu zespół pracuje nad korygowaniem, który identyfikuje i stosuje wymaganą poprawkę w akceptowalnym okresie.
Metryki odzyskiwania mierzą czas rozwiązania problemu. W przypadku zamknięcia może wystąpić pilna potrzeba rozwiązania problemu. Aby ustabilizować system, zastosowanie poprawek, poprawek i testów oraz wdrożenie aktualizacji zajmuje trochę czasu. Określ strategie powstrzymywania, aby zapobiec dalszym uszkodzeniom i rozprzestrzenianiu się incydentu. Opracowanie procedur zwalczania w celu całkowitego usunięcia zagrożenia ze środowiska.
Kompromis: Istnieje kompromis między celami niezawodności a czasem korygowania. Podczas zdarzenia prawdopodobnie nie spełniasz innych wymagań niefunkcjonalnych ani funkcjonalnych. Na przykład może być konieczne wyłączenie części systemu podczas badania zdarzenia lub może być konieczne przełączenie całego systemu w tryb offline do momentu określenia zakresu zdarzenia. Osoby podejmujące decyzje biznesowe muszą jawnie zdecydować, jakie są dopuszczalne cele podczas zdarzenia. Jasno określ osobę, która jest odpowiedzialny za daną decyzję.
Nauka na podstawie zdarzenia
Zdarzenie ujawnia luki lub punkty podatne na zagrożenia w projekcie lub implementacji. Jest to szansa na poprawę, która jest oparta na lekcjach aspektów projektowania technicznego, automatyzacji, procesów tworzenia produktów, które obejmują testowanie i skuteczność procesu reagowania na zdarzenia. Zachowaj szczegółowe rekordy zdarzeń, w tym akcje podjęte, osie czasu i wyniki.
Zdecydowanie zalecamy przeprowadzenie strukturalnych przeglądów po zdarzeniu, takich jak analiza głównej przyczyny i retrospektywy. Śledź i ustalaj priorytety wyników tych przeglądów i rozważ użycie tego, czego nauczysz się w przyszłych projektach obciążeń.
Plany poprawy powinny obejmować aktualizacje próbnych i testowania zabezpieczeń, takie jak ciągłość działania i próbne odzyskiwanie po awarii (BCDR). Użyj kompromisu zabezpieczeń jako scenariusza przeprowadzania przechodzenia do szczegółów BCDR. Przechodzenie do szczegółów może sprawdzić, jak działają udokumentowane procesy. Nie powinno istnieć wiele podręczników reagowania na zdarzenia. Użyj pojedynczego źródła, które można dostosować na podstawie rozmiaru zdarzenia i jak powszechny lub zlokalizowany jest efekt. Ćwiczenia są oparte na hipotetycznych sytuacjach. Przeprowadź ćwiczenia w środowisku o niskim ryzyku i uwzględnij fazę nauki w ćwiczeniach.
Przeprowadzanie przeglądów po zdarzeniu lub pośmiertnych w celu zidentyfikowania słabych stron w procesie reagowania i obszarach poprawy. Na podstawie lekcji uzyskanych na podstawie zdarzenia zaktualizuj plan reagowania na zdarzenia (IRP) i mechanizmy kontroli zabezpieczeń.
Definiowanie planu komunikacji
Zaimplementuj plan komunikacji, aby powiadomić użytkowników o zakłóceniach oraz poinformować zainteresowanych stron o korygowaniu i ulepszeniach. Inne osoby w organizacji muszą otrzymywać powiadomienia o wszelkich zmianach w punkcie odniesienia zabezpieczeń obciążenia, aby zapobiec przyszłym zdarzeniom.
Generowanie raportów dotyczących zdarzeń do użytku wewnętrznego i, w razie potrzeby, w celu zapewnienia zgodności z przepisami lub celów prawnych. Ponadto należy przyjąć standardowy raport formatu (szablon dokumentu ze zdefiniowanymi sekcjami), którego zespół SOC używa dla wszystkich zdarzeń. Przed zamknięciem badania upewnij się, że każde zdarzenie ma skojarzony z nim raport.
Ułatwienia platformy Azure
Microsoft Sentinel to rozwiązanie SIEM i SOAR. Jest to pojedyncze rozwiązanie do wykrywania alertów, widoczności zagrożeń, proaktywnego wyszukiwania zagrożeń i reagowania na zagrożenia. Aby uzyskać więcej informacji, zobacz Co to jest usługa Microsoft Sentinel?
Upewnij się, że portal rejestracji platformy Azure zawiera informacje kontaktowe administratora, dzięki czemu operacje zabezpieczeń mogą być powiadamiane bezpośrednio za pośrednictwem procesu wewnętrznego. Aby uzyskać więcej informacji, zobacz Aktualizowanie ustawień powiadomień.
Aby dowiedzieć się więcej na temat ustanawiania wyznaczonego punktu kontaktu, który odbiera powiadomienia o zdarzeniach platformy Azure z Microsoft Defender dla Chmury, zobacz Konfigurowanie powiadomień e-mail dotyczących alertów zabezpieczeń.
Dopasowanie organizacji
Przewodnik Cloud Adoption Framework dla platformy Azure zawiera wskazówki dotyczące planowania reagowania na zdarzenia i operacji zabezpieczeń. Aby uzyskać więcej informacji, zobacz Operacje zabezpieczeń.
Pokrewne łącza
- Automatyczne tworzenie zdarzeń na podstawie alertów zabezpieczeń firmy Microsoft
- Przeprowadzanie kompleksowego wyszukiwania zagrożeń za pomocą funkcji polowania
- Konfigurowanie powiadomień e-mail na potrzeby alertów zabezpieczeń
- Omówienie reagowania na zdarzenia
- Gotowość zdarzenia platformy Microsoft Azure
- Nawigowanie po zdarzeniach i badanie ich w usłudze Microsoft Sentinel
- Kontrola zabezpieczeń: reagowanie na zdarzenia
- Rozwiązania SOAR w usłudze Microsoft Sentinel
- Szkolenie: wprowadzenie do gotowości zdarzeń platformy Azure
- Aktualizowanie ustawień powiadomień w witrynie Azure Portal
- Co to jest SOC?
- Co to jest usługa Microsoft Sentinel?
Lista kontrolna zabezpieczeń
Zapoznaj się z pełnym zestawem zaleceń.